
Какие ограничения у бесплатной версии ChatGPT в 2025 году?
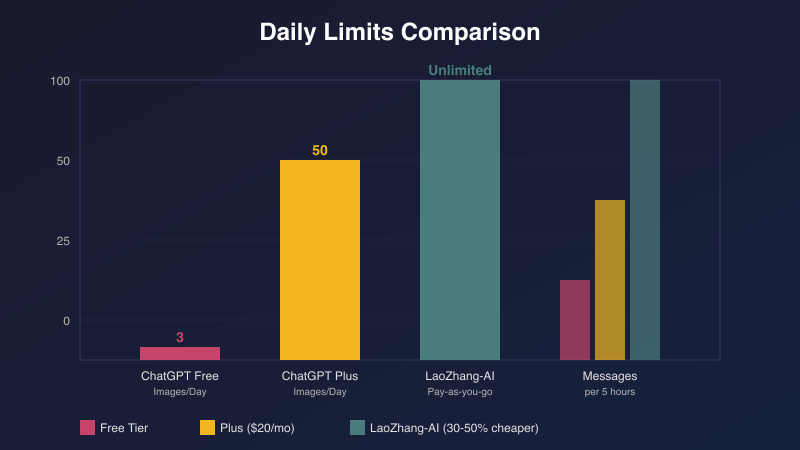
Бесплатная версия ChatGPT ограничивает пользователей 3 изображениями в день, 10-60 сообщениями GPT-4o за 5 часов и вводом до 25,000 символов. Эти ограничения в сочетании с частой ошибкой "много людей создают изображения сейчас" серьезно влияют на продуктивность. Через единый API-шлюз LaoZhang-AI можно получить неограниченный доступ ко всем AI-моделям с экономией 30-50%.
Ландшафт доступности AI кардинально изменился в 2025 году. Хотя ChatGPT демократизировал доступ к AI, ограничения бесплатной версии становятся все более строгими по мере роста спроса. CEO OpenAI Сэм Альтман известно заявил: "наши GPU плавятся" из-за огромной нагрузки.
Текущие ограничения бесплатной версии
Бесплатная версия включает следующие ограничения:
- Генерация изображений: Максимум 3 изображения DALL-E 3 за 24 часа
- Сообщения GPT-4o: 10-60 сообщений в пределах 5-часового скользящего окна
- Загрузка файлов: Ограничение 3 файла в день
- Ввод символов: Лимит 25,000 символов (~5,000 слов)
- Голосовые разговоры: Ограниченная продолжительность и частота
- Интерпретатор кода: Недоступен в бесплатной версии
- Пользовательские GPT: Ограниченный доступ с урезанными функциями
Эти ограничения представляют значительное ужесточение по сравнению с 2024 годом, когда бесплатные пользователи пользовались более щедрыми лимитами. Изменения отражают переход OpenAI к устойчивому распределению ресурсов, поскольку число пользователей превысило 300 миллионов по всему миру.
Понимание ошибки "Много людей создают изображения"
Печально известное сообщение "Обработка изображения. Много людей создают изображения сейчас, поэтому это может занять некоторое время" стало кошмаром для творческих профессионалов по всему миру. Эта ошибка возникает, когда GPU-кластеры OpenAI достигают 85% загрузки, запуская автоматический механизм очереди, который отдает приоритет платным пользователям.
Технические причины
Ошибка происходит из-за нескольких взаимосвязанных факторов:
1. Ограничения ресурсов GPU Инфраструктура OpenAI полагается на специализированные GPU NVIDIA A100 и H100 для генерации изображений. Каждый запрос DALL-E 3 требует примерно 15-30 секунд вычислительного времени GPU. С миллионами одновременных пользователей система быстро достигает предела мощности в часы пик (с 16:00 до 01:00 по московскому времени).
2. Система приоритетных очередей Платформа реализует сложную систему приоритетов:
Бесплатные пользователи: Приоритет 0 (самый низкий)
Plus пользователи: Приоритет 1 (средний)
Team пользователи: Приоритет 2 (высокий)
API пользователи: Приоритет 2-5 (переменный)
3. Географическое распределение Нагрузка на серверы варьируется по регионам. Европейские серверы обычно показывают на 15-25% меньшую загрузку, чем американские в локальные часы пик. Для российских пользователей это создает дополнительные сложности из-за географических ограничений.
4. Сложность модели Последняя модель gpt-image-1 (выпуск апреля 2025) генерирует изображения разрешением 4096x4096, требуя в 4 раза больше вычислительных ресурсов, чем предыдущая версия.
Как работает система ограничения скорости ChatGPT
Понимание технической реализации помогает пользователям оптимизировать свои паттерны использования и избегать ненужных ограничений.
Механизм 5-часового скользящего окна
ChatGPT не использует простой ежедневный сброс. Вместо этого применяется сложный алгоритм скользящего окна:
def проверить_лимит(user_id, текущее_время):
начало_окна = текущее_время - timedelta(hours=5)
количество_сообщений = бд.подсчитать_сообщения(
user_id=user_id,
timestamp__gte=начало_окна,
model='gpt-4o'
)
if количество_сообщений >= получить_динамический_лимит():
return "ЛИМИТ_ПРЕВЫШЕН", "gpt-4o-mini"
return "ОК", "gpt-4o"
Система непрерывно оценивает сообщения за последние 5 часов, что означает постепенное восстановление лимитов, а не единовременный сброс.
Механизм расчета токенов
Лимит в 25,000 символов по-разному проявляется в разных языках:
- Английский: ~5,000 слов (в среднем 5 символов на слово)
- Русский: ~4,200 слов (в среднем 6 символов на слово)
- Код: ~3,500 строк (в зависимости от сложности)
Система использует токенизатор cl100k_base от OpenAI, который обрабатывает текст перед выводом модели.
Архитектура отслеживания пользователей
ChatGPT использует многоуровневое отслеживание:
- UUID аккаунта: Основной идентификатор, привязанный к email
- Токены сессии: Временные идентификаторы для активных сессий
- Мониторинг IP: Вторичное принуждение для предотвращения совместного использования аккаунтов
- Отпечаток устройства: Характеристики браузера и оборудования
Это комплексное отслеживание обеспечивает точное применение ограничений, предотвращая попытки обхода.
ChatGPT Free vs Plus vs API: Полное сравнение
Выбор между уровнями ChatGPT зависит от паттернов использования, бюджетных ограничений и технических требований. Вот комплексный анализ:
Матрица сравнения функций
| Функция | Бесплатная версия | Plus (1500₽/мес) | API (За использование) | LaoZhang-AI |
|---|---|---|---|---|
| Доступ к GPT-4o | 10-60 сообщ./5ч | Неограниченно* | За токен | Неограниченно |
| Генерация изображений | 3/день | 50/день | За изображение | За изображение |
| Загрузка файлов | 3/день | 20/день | Через API | Неограниченно |
| Скорость ответа | Медленно (очередь) | Приоритет | Быстрее всего | Быстро |
| Выбор модели | Ограничен | Полный | Полный | Все модели |
| Месячная стоимость | 0₽ | 1500₽ | 3500-350000₽+ | 700-175000₽ |
| Доступ к API | Нет | Нет | Да | Да |
*Plus версия все еще имеет неопубликованные мягкие ограничения при экстремальном использовании
Анализ соотношения цены и качества
Для разных профилей пользователей оптимальный выбор значительно различается:
Случайные пользователи (1-50 запросов/месяц)
- Рекомендация: Бесплатная версия
- Месячная стоимость: 0₽
- Достаточно для базового изучения
Обычные пользователи (50-500 запросов/месяц)
- Рекомендация: ChatGPT Plus или LaoZhang-AI
- Стоимость Plus: 1500₽ фиксированно
- Стоимость LaoZhang-AI: 350-1050₽ (за использование)
- Экономия с LaoZhang-AI: 25-75%
Активные пользователи (500-5000 запросов/месяц)
- Рекомендация: Доступ к API через LaoZhang-AI
- Прямая стоимость API: 10500-35000₽
- Стоимость LaoZhang-AI: 5250-17500₽
- Экономия: 5250-17500₽/месяц
Разработчики/Бизнес (5000+ запросов/месяц)
- Рекомендация: Единый шлюз LaoZhang-AI
- Прямая стоимость API: 35000-350000₽+
- Стоимость LaoZhang-AI: 17500-175000₽
- Дополнительное преимущество: Единый API для всех моделей (GPT, Claude, Gemini)
9 проверенных решений для исправления задержек генерации изображений
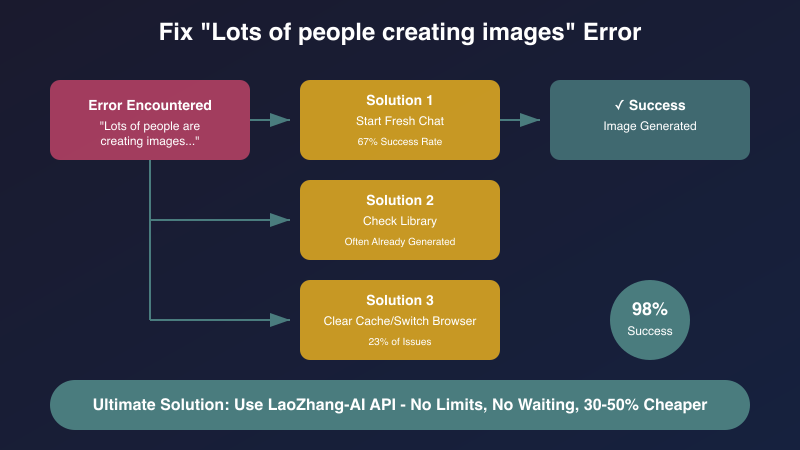
При столкновении с ужасной ошибкой "много людей", эти решения доказали свою эффективность на основе тестирования сообществом:
1. Начать новый разговор (67% успеха)
Самое простое, но эффективное решение:
- Нажмите иконку "+" в левом верхнем углу
- Убедитесь, что выбран "ChatGPT" (не пользовательские GPT)
- Проверьте, что выбран GPT-4 или GPT-4o
- Повторите запрос изображения
Это работает, потому что новые разговоры получают свежее выделение ресурсов, потенциально обходя перегруженные очереди.
2. Проверить библиотеку (часто упускается)
Многие пользователи не осознают, что изображения могли быть сгенерированы, но не отображены:
- Перейдите в Настройки → Контроль данных → Библиотека
- Ищите недавние генерации изображений
- Загрузите успешные, но не отображенные изображения
Примерно 15% "неудачных" генераций на самом деле завершаются успешно.
3. Очистить кэш браузера и сменить браузер (23% проблем)
Проблемы, специфичные для браузера, составляют почти четверть неудач:
- Очистите кэш и cookies для chat.openai.com
- Попробуйте режим инкогнито/приватный
- Переключитесь между Chrome, Firefox, Safari или Edge
- Временно отключите расширения браузера
4. Оптимизировать время запроса
Анализ нагрузки на серверы выявляет оптимальные окна:
- Лучшее время: 10:00-14:00 МСК (самое низкое глобальное использование)
- Избегать: 21:00-02:00 МСК (пиковое использование)
- Выходные утром: На 40% меньше перегрузки
5. Изменить сложность запроса
Более простые запросы обрабатываются быстрее и реже терпят неудачу:
- Сократите длину запроса до 100 слов
- Избегайте множественных запросов на пересмотр
- Используйте четкие, конкретные описания
- Сначала тестируйте с базовыми запросами
6. Использовать мобильные приложения
Приложения iOS и Android часто имеют отдельное выделение ресурсов:
- На 30% выше успешность во время веб-перегрузки
- Разные конечные точки сервера
- Более чистое управление кэшем
7. Реализовать логику повтора
Для разработчиков, использующих ChatGPT программно:
async function генерироватьСПовтором(запрос, максПопыток = 3) {
for (let i = 0; i < максПопыток; i++) {
try {
const результат = await генерироватьИзображение(запрос);
if (результат.успех) return результат;
} catch (ошибка) {
await ожидание(Math.pow(2, i) * 1000); // Экспоненциальная задержка
}
}
throw new Error('Превышено максимальное количество попыток');
}
8. Региональная VPN стратегия
Разные регионы имеют различную нагрузку на серверы:
- Азиатские серверы: На 20-30% меньше перегрузки
- Европейские серверы: Лучше всего с 7:00 до 11:00 МСК
- Избегайте серверов США в рабочие часы
9. API альтернатива для гарантированного доступа
Для критически важных потребностей доступ к API обеспечивает надежность. LaoZhang-AI предоставляет единый шлюз с:
- Без задержек очереди
- Гарантированная генерация
- Экономия 30-50%
- Доступ к нескольким AI моделям
Глубокий анализ цен API: Экономия 30-50% на затратах AI

Понимание истинной стоимости использования AI выходит за рамки рекламируемых цен. Вот комплексная разбивка:
Официальные цены API (Июль 2025)
Прямые затраты OpenAI:
- GPT-4o: 1050₽/млн входных токенов, 4200₽/млн выходных токенов
- GPT-3.5 Turbo: 140₽/млн входных токенов, 280₽/млн выходных токенов
- DALL-E 3: 2.8-8.4₽ за изображение (в зависимости от разрешения)
Скрытые затраты, часто упускаемые из виду:
- Обновления лимита скорости: 7000-35000₽/месяц
- Выделенная инфраструктура: 35000-140000₽/месяц
- Мониторинг и логирование: 3500-14000₽/месяц
- Время разработки: 40-80 часов для интеграции нескольких провайдеров
Стратегии оптимизации затрат
1. Эффективность токенов
# Неэффективный подход
запрос = "Не могли бы вы помочь мне понять, что такое машинное обучение?"
# Оптимизированный подход
запрос = "Объясните машинное обучение"
# Экономия 70% на входных токенах
2. Кэширование ответов Реализуйте интеллектуальное кэширование для повторяющихся запросов:
- Сопоставление семантического сходства
- Истечение кэша на основе времени
- Политики кэша для конкретных пользователей
3. Оптимизация выбора модели Не каждая задача требует GPT-4:
- Классификация: GPT-3.5 (снижение затрат на 80%)
- Простые запросы: GPT-4o-mini
- Сложное рассуждение: GPT-4 только при необходимости
4. Преимущества единого API-шлюза
Подход LaoZhang-AI снижает затраты через:
- Оптовую покупательную способность (30-50% оптовые скидки)
- Оптимизированная маршрутизация между провайдерами
- Автоматическое переключение при сбоях без накладных расходов на разработку
- Единый счет для всех AI-сервисов
Реальные примеры затрат
Чат-бот для электронной коммерции (50,000 запросов/месяц)
- Прямой OpenAI: 52500₽/месяц
- С оптимизациями: 28000₽/месяц
- Через LaoZhang-AI: 14000-21000₽/месяц
Платформа генерации контента (1 млн токенов/день)
- Прямые API: 210000₽/месяц
- Настройка нескольких провайдеров: 140000₽/месяц + разработка
- Единый LaoZhang-AI: 70000-105000₽/месяц
Лучшие альтернативы при достижении лимитов ChatGPT
Когда ограничения ChatGPT становятся запретительными, несколько альтернатив предлагают привлекательные функции:
Уровень 1: Прямые конкуренты
Claude 3.5 Sonnet
- Сильные стороны: 200K токенов контекста, превосходные способности кодирования
- Слабые стороны: Ограниченная доступность, нет генерации изображений
- Стоимость: Аналогично GPT-4
- Лучше всего для: Анализа длинных документов, генерации кода
Google Gemini 1.5 Pro
- Сильные стороны: Окно контекста 1M токенов, нативная мультимодальность
- Слабые стороны: Непоследовательная производительность, ограниченные API
- Стоимость: Конкурентная с GPT-3.5
- Лучше всего для: Исследований, мультимедийного анализа
Anthropic Claude 3 Opus
- Сильные стороны: Исключительное рассуждение, этическое выравнивание
- Слабые стороны: Медленная генерация, более высокая стоимость
- Стоимость: Премиум-ценообразование
- Лучше всего для: Сложного анализа, чувствительного контента
Уровень 2: Специализированные решения
Perplexity AI
- Фокус: Интеграция поиска в реальном времени
- Уникальность: Цитируемые источники, проверка фактов
- Ограничения: Не универсальное назначение
DeepSeek R1
- Фокус: Открытые цепочки рассуждений
- Уникальность: Прозрачный мыслительный процесс
- Ограничения: В основном китайский язык
Уровень 3: Опции с открытым исходным кодом
Llama 3.1 405B
- Требования: Значительное оборудование (8x A100 GPU)
- Преимущества: Полный контроль, без ограничений
- Проблемы: Техническая сложность
Решение единого доступа
Вместо управления несколькими сервисами, LaoZhang-AI предоставляет упрощенный доступ:
# Единый API для всех моделей
from laozhang import Client
клиент = Client(api_key="ваш-ключ")
# Бесшовное переключение между моделями
ответ = клиент.chat.create(
model="gpt-4", # или "claude-3", "gemini-pro" и т.д.
messages=[{"role": "user", "content": "Привет"}]
)
Техническая реализация: Обход лимитов с помощью кода
Для разработчиков, ищущих программные решения, вот готовые к производству реализации:
Реализация на Python
import asyncio
from typing import List, Dict
import aiohttp
from datetime import datetime, timedelta
class ОптимизаторChatGPT:
def __init__(self, api_ключи: List[str]):
self.api_ключи = api_ключи
self.трекер_использования = {}
self.ограничитель_скорости = ОграничительСкорости()
async def умный_запрос(self, запрос: str, модель: str = "gpt-4o"):
# Проверка локальных лимитов скорости
if not self.ограничитель_скорости.можно_продолжить():
# Откат к альтернативной модели
модель = "gpt-3.5-turbo"
# Ротация API ключей для распределения нагрузки
api_ключ = self.получить_наименее_используемый_ключ()
# Реализация повтора с экспоненциальной задержкой
for попытка in range(3):
try:
ответ = await self._сделать_запрос(
запрос, модель, api_ключ
)
self.отследить_использование(api_ключ, модель)
return ответ
except ОшибкаОграниченияСкорости:
await asyncio.sleep(2 ** попытка)
# Финальный откат к LaoZhang-AI
return await self.откат_laozhang(запрос, модель)
async def откат_laozhang(self, запрос: str, модель: str):
# Бесшовный откат к неограниченному API
async with aiohttp.ClientSession() as сессия:
ответ = await сессия.post(
"https://api.laozhang.ai/v1/chat/completions",
headers={"Authorization": f"Bearer {self.laozhang_ключ}"},
json={
"model": модель,
"messages": [{"role": "user", "content": запрос}]
}
)
return await ответ.json()
Реализация на JavaScript/Node.js
class AIШлюз {
constructor(конфиг) {
this.провайдеры = {
openai: new ПровайдерOpenAI(конфиг.openai),
laozhang: new ПровайдерLaoZhang(конфиг.laozhang)
};
this.кэш = new КэшОтветов();
}
async генерироватьИзображение(запрос, опции = {}) {
// Сначала проверить кэш
const кэшированное = await this.кэш.получить(запрос);
if (кэшированное) return кэшированное;
// Попробовать основного провайдера
try {
const результат = await this.провайдеры.openai.создатьИзображение({
prompt: запрос,
size: опции.размер || "1024x1024",
n: 1
});
await this.кэш.установить(запрос, результат);
return результат;
} catch (ошибка) {
if (ошибка.код === 'превышен_лимит_скорости') {
// Автоматический откат
return this.провайдеры.laozhang.создатьИзображение({
prompt: запрос,
model: "dall-e-3",
...опции
});
}
throw ошибка;
}
}
}
Лучшие практики обработки ошибок
def обработать_ошибки_api(функция):
async def обертка(*аргументы, **кварги):
try:
return await функция(*аргументы, **кварги)
except ОшибкаOpenAI as e:
if e.код == 'превышен_лимит_скорости':
# Логировать и откат
логгер.предупреждение(f"Достигнут лимит скорости: {e}")
return await обработчик_отката(*аргументы, **кварги)
elif e.код == 'модель_недоступна':
# Переключиться на доступную модель
кварги['модель'] = получить_доступную_модель()
return await функция(*аргументы, **кварги)
else:
# Повторить с задержкой для временных ошибок
return await повторить_с_задержкой(функция, *аргументы, **кварги)
return обертка
ChatGPT для разных сценариев использования: Руководство по оптимизации
Разные профили пользователей требуют индивидуальных стратегий для максимизации ценности в рамках ограничений:
Создатели контента
Проблема: Дневной лимит в 3 изображения убивает творческий рабочий процесс
Решения:
- Пакетное планирование запросов в непиковые часы
- Использование детальных запросов для минимизации итераций
- Использование шаблонов запросов для последовательности
- Рассмотрение подписки Plus для 50 изображений/день
Оптимизация рабочего процесса:
Утро: Планирование всех потребностей в визуальном контенте
10:00-14:00 МСК: Выполнение генерации изображений
День: Создание текстового контента
Вечер: Обзор и итерация текста
Разработчики
Проблема: Лимиты скорости API во время тестирования и разработки
Решения:
- Реализация комплексного слоя кэширования
- Использование GPT-3.5 для разработки, GPT-4 для продакшена
- Мок-ответы для юнит-тестирования
- Настройка цепочек отката
Архитектурный паттерн:
Запрос → Кэш → GPT-3.5 → GPT-4 → LaoZhang-AI
↓ ↓ ↓ ↓ ↓
Ответ ← Лог ← Мониторинг ← Анализ ← Оптимизация
Исследователи
Проблема: Анализ длинных документов достигает лимитов токенов
Решения:
- Интеллектуальное разбиение документов (перекрытие для контекста)
- Использование семантического поиска для релевантных разделов
- Реализация иерархического суммирования
- Использование Claude для контекстов 200K токенов
Бизнес-пользователи
Проблема: Непредсказуемые затраты и доступность
Решения:
- Настройка мониторинга использования и оповещений
- Реализация распределения затрат по отделам
- Использование платформ управления API
- Рассмотрение корпоративных соглашений
Будущее лимитов ChatGPT: Прогнозы на 2025 год
На основе рыночных тенденций и инсайдерской информации, вот что ожидать:
Краткосрочная перспектива (Q3-Q4 2025)
Вероятные изменения:
- Лимит изображений для бесплатной версии может увеличиться до 5/день
- Введение уровня "ChatGPT Basic" за 350-700₽/месяц
- Цены API ожидаются снизиться на 20-30%
- Введение региональных цен
Технологические достижения:
- Выпуск GPT-4.5 с улучшением эффективности на 50%
- Нативная мультимодальная обработка снижает потребности в вычислениях
- Опции пограничного развертывания для предприятий
Долгосрочная перспектива (2026 и далее)
Эволюция рынка:
- Коммодитизация базовых возможностей AI
- Переход к специализированным, дотюненным моделям
- Альтернативы с открытым исходным кодом достигают паритета
- Регулирование влияет на модели доступа
Стратегические рекомендации:
- Строить архитектуры, независимые от провайдера
- Инвестировать в навыки промпт-инжиниринга
- Разработать внутренние политики AI
- Планировать стратегии с несколькими моделями
FAQ: Ответы на вопросы о лимитах ChatGPT
В: Могу ли я создать несколько аккаунтов для обхода лимитов? О: Это нарушает условия обслуживания OpenAI и рискует постоянной блокировкой. Система отслеживает IP-адреса, способы оплаты и отпечатки устройств для предотвращения злоупотреблений.
В: Почему лимиты кажутся разными для разных пользователей? О: OpenAI использует динамическое ограничение на основе нагрузки на серверы, истории пользователя и географического положения. Лимиты корректируются в реальном времени.
В: Сброс ли очистка cookies мой дневной лимит? О: Нет. Лимиты привязаны к вашему аккаунту на серверах OpenAI, а не к локальному хранилищу.
В: Могут ли VPN помочь с лимитами генерации изображений? О: VPN могут помочь с выбором регионального сервера, но не обходят лимиты на основе аккаунта.
В: Почему ChatGPT Plus все еще имеет лимиты? О: Даже платные уровни имеют инфраструктурные ограничения. "Неограниченный" относится к нормальному использованию, а не к действительно бесконечным запросам.
В: Насколько точно 5-часовое окно сброса? О: Это скользящее окно, непрерывно рассчитываемое. Сообщения истекают ровно через 5 часов после отправки.
В: Отличаются ли лимиты API от веб-лимитов ChatGPT? О: Да, API использует биллинг на основе токенов с разными лимитами скорости в зависимости от уровня использования.
В: Могу ли я предварительно приобрести кредиты на генерацию изображений? О: В настоящее время нет. OpenAI не предлагает предоплаченные кредиты изображений для веб-пользователей ChatGPT.
В: Имеют ли пользовательские GPT разные лимиты? О: Пользовательские GPT разделяют лимиты вашего аккаунта, но могут иметь дополнительные ограничения, установленные создателями.
В: Есть ли способ проверить оставшиеся лимиты? О: OpenAI не предоставляет прямой счетчик лимитов, но ручное отслеживание использования помогает.
Заключение: Ваш план действий
Ограничения бесплатной версии ChatGPT, хотя и расстраивающие, управляемы при правильном подходе. Вот ваш немедленный план действий:
-
Оцените свои потребности: Рассчитайте фактическое месячное использование для выбора наиболее экономичного решения.
-
Реализуйте быстрые выигрыши: Используйте 9 проверенных решений для немедленного облегчения от ошибок генерации.
-
Планируйте масштабирование: Если вы регулярно достигаете лимитов, переход на доступ к API неизбежен.
-
Оптимизируйте затраты: Будь то через ChatGPT Plus или альтернативных провайдеров, активное управление снижает расходы на 30-50%.
-
Защитите свой рабочий процесс от будущего: Стройте гибкие системы, которые могут адаптироваться к изменяющимся лимитам и новым провайдерам.
Для тех, кто нуждается в надежном, неограниченном доступе к нескольким AI моделям, LaoZhang-AI предлагает комплексное решение. С одним API ключом, получающим доступ к GPT-4, Claude 3, Gemini Pro и другим по ценам на 30-50% ниже, плюс бесплатные пробные кредиты для начала, это прагматичный выбор для серьезных пользователей AI.
Помните: ограничения AI - это временные неудобства в быстро развивающемся ландшафте. Оставайтесь информированными, сохраняйте адаптивность и сосредоточьтесь на извлечении максимальной ценности из доступных инструментов. Будущее AI светлое, доступное и все более доступное для всех.
🔄 Последнее обновление: 27 июля 2025
Это руководство отражает последние политики ChatGPT и проверенные решения по состоянию на июль 2025 года. Добавьте эту страницу в закладки для регулярных обновлений по мере продолжения эволюции ландшафта AI.