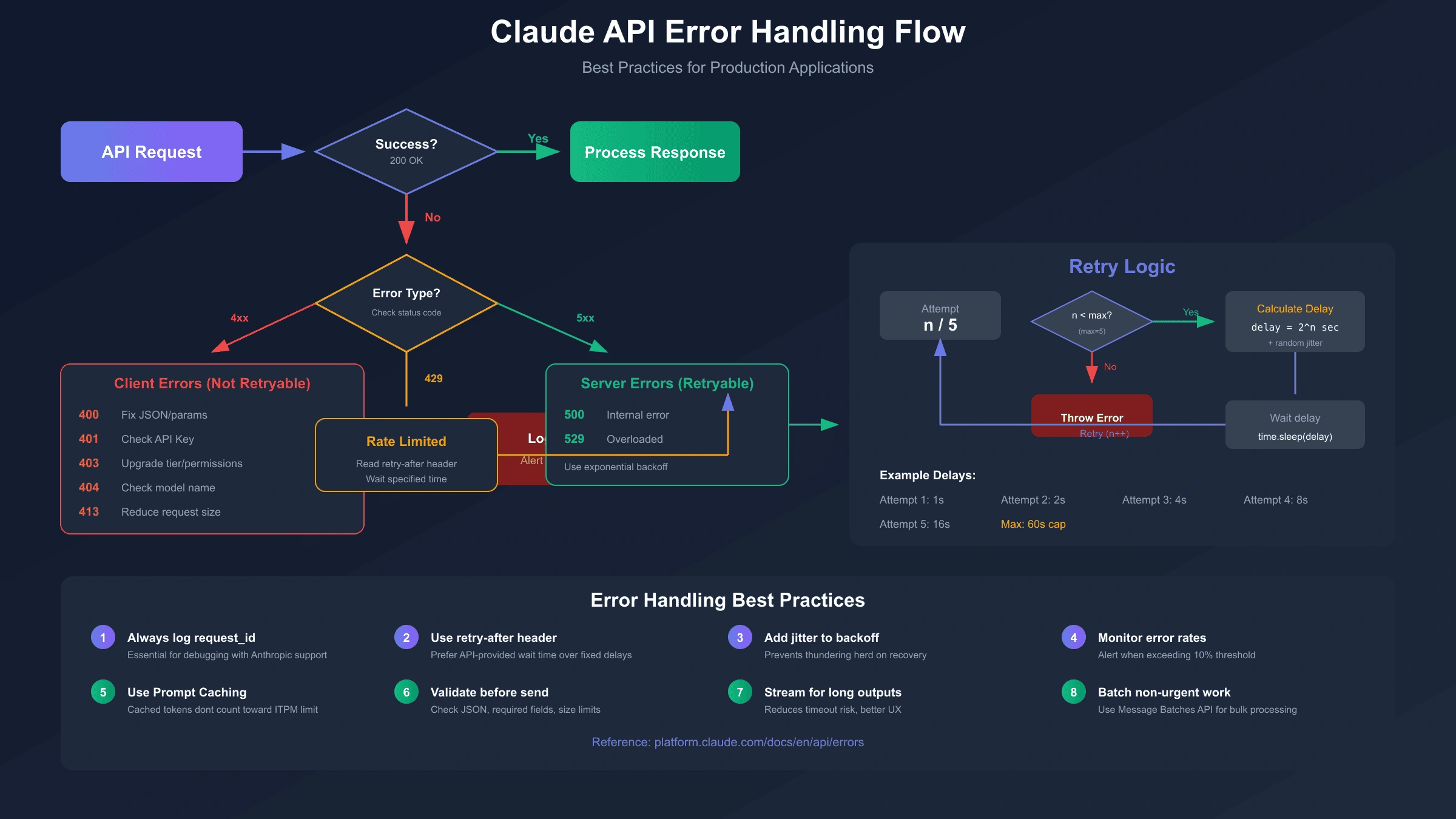
调用Claude API时遇到错误是开发过程中的常态。一个429错误可能意味着你触发了速率限制,一个529错误则说明Anthropic服务器正在经历高负载。理解每种错误码的含义和对应的解决方案,能让你在遇到问题时快速定位原因并恢复服务。
Claude API采用标准HTTP状态码体系,共有8种主要错误类型。从身份验证失败(401)到请求过载(529),每种错误都有其特定的触发条件和处理方式。本文将逐一拆解这些错误码,提供经过验证的解决方案和可直接复用的代码示例。
无论你是刚接触Claude API的新手,还是需要排查生产环境问题的资深开发者,这份指南都能帮助你快速定位问题。文章还包含了Tier 1-4速率限制的完整数据对比,以及针对中国开发者常见的网络连接问题的专项解决方案。
Claude API错误响应格式解析
在深入各种错误码之前,首先需要了解Claude API的错误响应结构。Anthropic采用统一的JSON格式返回所有错误,这让解析和处理变得相对简单。
标准错误响应结构
hljs json{
"type": "error",
"error": {
"type": "not_found_error",
"message": "The requested resource could not be found."
},
"request_id": "req_011CSHoEeqs5C35K2UUqR7Fy"
}
响应中包含三个关键字段:
- type: 固定为"error",标识这是一个错误响应
- error.type: 具体的错误类型,如
rate_limit_error、authentication_error等 - error.message: 人类可读的错误描述,通常包含问题的具体原因
- request_id: 唯一的请求标识符,联系Anthropic支持时必须提供此ID
Request ID的重要性
每个API响应的HTTP头中都包含request-id字段。这个ID是排查问题的关键——当你向Anthropic提交工单时,提供request_id能让支持团队快速定位你的具体请求日志,大幅缩短问题解决时间。
在官方SDK中获取request_id的方式:
hljs pythonimport anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello"}]
)
# 获取request_id用于问题排查
print(f"Request ID: {message._request_id}")
流式响应中的错误处理
需要特别注意的是,使用SSE流式响应时,错误可能在返回200状态码之后才发生。这意味着你不能仅依赖HTTP状态码来判断请求是否成功,必须解析完整的响应流才能确定结果。建议在流式处理中加入异常捕获机制,确保能正确处理中途出现的错误。
完整错误码速查表
Claude API共定义了8种HTTP错误状态码。以下是完整的对照表,方便你快速定位错误类型:
| HTTP状态码 | 错误类型 | 简要说明 | 是否可重试 |
|---|---|---|---|
| 400 | invalid_request_error | 请求格式或内容有问题 | 否,需修改请求 |
| 401 | authentication_error | API Key无效或未提供 | 否,需检查凭证 |
| 403 | permission_error | API Key权限不足 | 否,需升级权限 |
| 404 | not_found_error | 请求的资源不存在 | 否,需检查端点 |
| 413 | request_too_large | 请求体超过32MB限制 | 否,需减小请求 |
| 429 | rate_limit_error | 触发速率限制 | 是,等待后重试 |
| 500 | api_error | Anthropic内部错误 | 是,等待后重试 |
| 529 | overloaded_error | API服务过载 | 是,等待后重试 |
可重试错误的处理策略
对于429、500、529这三种可重试的错误,API响应头中会包含retry-after字段,指示建议的等待时间(秒)。最佳实践是结合指数退避算法:首次等待1秒,失败后等待2秒、4秒、8秒,依次递增,最多重试5次。
不可重试错误的处理原则
400、401、403、404、413这五种错误通常意味着请求本身存在问题,重试不会解决问题。正确的做法是:检查错误消息中的具体原因,修改请求参数或配置后再次尝试。
请求大小限制参考
不同API端点有不同的请求大小限制:
| 端点类型 | 最大请求大小 |
|---|---|
| Messages API | 32 MB |
| Token Counting API | 32 MB |
| Batch API | 256 MB |
| Files API | 500 MB |
超过这些限制会返回413错误。需要注意的是,413错误由Cloudflare在请求到达Anthropic服务器之前返回,所以错误响应格式可能与标准格式略有不同。
400 invalid_request_error:请求格式错误
400错误是最常见的客户端错误之一,表示你发送的请求在格式或内容上存在问题。Anthropic也会将其他4XX错误(未在列表中的)统一归类为此类型。
常见触发原因
- JSON格式错误:请求体不是有效的JSON,或存在语法错误
- 必填字段缺失:未提供
model、messages或max_tokens等必需参数 - 参数类型错误:例如
max_tokens传入了字符串而非整数 - 上下文长度超限:输入token数加max_tokens超过模型的上下文窗口限制
- 消息格式错误:messages数组中的role或content字段格式不正确
上下文长度超限的具体表现
这是开发者最容易遇到的400错误场景。错误消息通常类似于:
hljs json{
"type": "error",
"error": {
"type": "invalid_request_error",
"message": "input length and max_tokens exceed context limit: 197202 + 21333 > 200000, decrease input length or max_tokens and try again"
}
}
解决方案
针对上下文超限问题:
- 减少输入文本长度,移除不必要的上下文
- 降低
max_tokens值。如果只需要简短回复,设置为500-1000即可 - 使用Claude的自动上下文管理功能(付费版),自动压缩历史对话
- 开始新对话,避免历史消息累积
针对JSON格式问题:
hljs pythonimport json
# 发送前验证JSON格式
try:
payload = {
"model": "claude-sonnet-4-5",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "Hello"}]
}
json.dumps(payload) # 验证可序列化
except json.JSONDecodeError as e:
print(f"JSON格式错误: {e}")
针对必填字段问题:
hljs pythondef validate_request(payload):
required_fields = ["model", "messages", "max_tokens"]
missing = [f for f in required_fields if f not in payload]
if missing:
raise ValueError(f"缺少必填字段: {missing}")
# 验证messages格式
for msg in payload.get("messages", []):
if "role" not in msg or "content" not in msg:
raise ValueError("每条消息必须包含role和content字段")
401 authentication_error:身份验证失败
401错误表示API Key存在问题——可能是无效的、过期的,或者根本没有提供。这是新手开发者最常遇到的问题之一。
常见触发原因
- API Key格式错误:包含多余的空格、换行符或其他不可见字符
- API Key未设置:环境变量
ANTHROPIC_API_KEY未正确配置 - 使用了错误的Key:混淆了不同项目或平台的API Key
- Key已被撤销:在Console中删除或轮换了Key但代码未更新
验证API Key的方法
hljs bash# 检查环境变量是否设置
echo $ANTHROPIC_API_KEY
# 测试API Key是否有效
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{"model":"claude-sonnet-4-5","max_tokens":10,"messages":[{"role":"user","content":"Hi"}]}'
解决方案
-
检查Key格式:确保没有前后空格
hljs pythonapi_key = os.environ.get("ANTHROPIC_API_KEY", "").strip() if not api_key: raise ValueError("ANTHROPIC_API_KEY环境变量未设置") -
验证Key来源:登录Anthropic Console确认Key状态
-
重新生成Key:如果怀疑Key泄露,立即在Console中撤销并生成新Key
-
配置文件检查(针对Claude Code用户):
hljs bash# 检查配置文件 cat ~/.claude.json # 确保包含正确配置 # {"anthropic_api_key": "sk-ant-xxx..."}
中国开发者常见问题
使用Claude Code时,国内开发者可能遇到"Unable to connect to Anthropic services"错误。这通常不是Key本身的问题,而是网络连接问题。解决方案包括:
- 配置全局代理:设置
HTTP_PROXY和HTTPS_PROXY环境变量 - 使用API中转服务:如laozhang.ai,无需代理即可直连
403 permission_error:权限不足
403错误表示你的API Key没有访问所请求资源的权限。这与401不同——401是身份验证失败,403是身份验证成功但权限不够。
常见触发原因
- 模型访问权限:某些模型(如Claude Opus)可能需要更高层级的账户才能使用
- 功能限制:某些功能(如长上下文窗口)仅对特定层级开放
- API Key类型限制:Claude Code专用的Key只能用于Claude Code,不能用于直接API调用
- 组织权限:多人协作场景下,你的账户可能未被授权访问特定资源
典型错误消息
hljs json{
"type": "error",
"error": {
"type": "permission_error",
"message": "This credential is only authorized for use with Claude Code and cannot be used for other API requests."
}
}
解决方案
-
检查账户层级:
- 登录Claude Console
- 查看Settings > Limits页面确认当前层级
- 如需升级,充值相应金额即可自动升级
-
确认Key类型:
- OAuth获取的Key可能有特定限制
- 建议使用Console生成的标准API Key
-
联系组织管理员:
- 如果是企业账户,联系管理员授予相应权限
-
使用正确的模型名称:
hljs python# 确认模型名称正确 # claude-sonnet-4-5 ✓ # claude-4-sonnet ✗ (错误格式)
429 rate_limit_error:速率限制详解
429错误是生产环境中最常遇到的问题,表示你的请求频率或token消耗超过了账户限制。Claude API采用三个维度的速率限制:
- RPM (Requests Per Minute):每分钟请求次数
- ITPM (Input Tokens Per Minute):每分钟输入token数
- OTPM (Output Tokens Per Minute):每分钟输出token数
触发任意一个限制都会返回429错误。
错误响应示例
hljs json{
"type": "error",
"error": {
"type": "rate_limit_error",
"message": "Number of request tokens has exceeded your per-minute rate limit"
}
}
响应头中的限制信息
每次API响应都会包含当前速率限制状态:
| Header | 说明 |
|---|---|
retry-after | 建议等待秒数 |
anthropic-ratelimit-requests-limit | RPM上限 |
anthropic-ratelimit-requests-remaining | RPM剩余 |
anthropic-ratelimit-tokens-limit | TPM上限 |
anthropic-ratelimit-tokens-remaining | TPM剩余 |
解决方案
- 遵循retry-after头:等待指定时间后重试
- 降低请求频率:在请求之间添加延迟
- 减少token消耗:缩短输入文本或降低max_tokens
- 升级账户层级:充值达到更高层级门槛
- 使用批处理API:非实时场景改用Message Batches API
- 启用Prompt Caching:缓存的token不计入ITPM限制
重试逻辑示例
hljs pythonimport time
import anthropic
from anthropic import RateLimitError
def call_with_retry(client, max_retries=5, **kwargs):
for attempt in range(max_retries):
try:
return client.messages.create(**kwargs)
except RateLimitError as e:
if attempt == max_retries - 1:
raise
# 优先使用retry-after,否则指数退避
wait_time = getattr(e, 'retry_after', None) or (2 ** attempt)
print(f"触发速率限制,等待{wait_time}秒后重试...")
time.sleep(wait_time)
# 使用示例
client = anthropic.Anthropic()
response = call_with_retry(
client,
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello"}]
)
渐进式流量增长
如果你的应用流量突然激增,可能触发"加速限制"(acceleration limits),即使总量未超标也会返回429。解决方法是渐进式增加流量,避免瞬时峰值。
速率限制层级完整对比
Claude API采用层级制(Tier 1-4),不同层级有不同的速率限制和月消费上限。层级会根据累计充值金额自动升级。
层级升级要求
| 层级 | 累计充值要求 | 单次最高充值 |
|---|---|---|
| Tier 1 | $5 | $100 |
| Tier 2 | $40 | $500 |
| Tier 3 | $200 | $1,000 |
| Tier 4 | $400 | $5,000 |
| Custom | 联系销售 | 无限制 |
Tier 1 速率限制
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 50 | 30,000 | 8,000 |
| Claude Haiku 4.5 | 50 | 50,000 | 10,000 |
| Claude Opus 4.x | 50 | 30,000 | 8,000 |
Tier 2 速率限制
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 1,000 | 450,000 | 90,000 |
| Claude Haiku 4.5 | 1,000 | 450,000 | 90,000 |
| Claude Opus 4.x | 1,000 | 450,000 | 90,000 |
Tier 3 速率限制
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 2,000 | 800,000 | 160,000 |
| Claude Haiku 4.5 | 2,000 | 1,000,000 | 200,000 |
| Claude Opus 4.x | 2,000 | 800,000 | 160,000 |
Tier 4 速率限制
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 4,000 | 2,000,000 | 400,000 |
| Claude Haiku 4.5 | 4,000 | 4,000,000 | 800,000 |
| Claude Opus 4.x | 4,000 | 2,000,000 | 400,000 |
Prompt Caching的优势
值得注意的是,缓存的输入token(cache_read_input_tokens)不计入ITPM限制。这意味着:如果你有200万ITPM限制,80%的缓存命中率可以让你实际处理1000万token/分钟。

使用中转服务突破限制
对于需要更高限额但暂时无法升级层级的开发者,可以考虑使用API中转服务。例如laozhang.ai聚合了多个API Key,提供更高的有效限额,并且在国内可以直连访问,无需配置代理。接入方式与官方SDK完全兼容,只需修改base_url:
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="sk-YOUR_LAOZHANG_KEY",
base_url="https://api.laozhang.ai/v1"
)
response = client.chat.completions.create(
model="claude-sonnet-4-5",
messages=[{"role": "user", "content": "Hello"}]
)
529 overloaded_error:服务过载处理
529是Claude API特有的状态码,表示Anthropic服务器当前负载过高。与429不同,529是全局性的——不是你的账户超限,而是整个API服务正在经历高流量。
典型错误消息
hljs json{
"type": "error",
"error": {
"type": "overloaded_error",
"message": "Overloaded"
}
}
529与429的区别
| 维度 | 429 rate_limit_error | 529 overloaded_error |
|---|---|---|
| 原因 | 个人账户超限 | 全局服务过载 |
| 影响范围 | 仅你的账户 | 所有用户 |
| 解决方式 | 升级层级/降低频率 | 等待重试 |
| 持续时间 | 固定(到限制重置) | 不确定(取决于流量) |
处理策略
529错误的最佳策略是指数退避重试:
hljs pythonimport time
import random
def exponential_backoff(attempt, base_delay=1, max_delay=60):
"""带随机抖动的指数退避"""
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1)
return delay + jitter
def call_with_overload_handling(client, max_retries=10, **kwargs):
for attempt in range(max_retries):
try:
return client.messages.create(**kwargs)
except anthropic.APIError as e:
if e.status_code == 529:
wait = exponential_backoff(attempt)
print(f"服务过载,等待{wait:.1f}秒后重试 (尝试 {attempt+1}/{max_retries})")
time.sleep(wait)
else:
raise
raise Exception("重试次数已达上限,服务仍然过载")
监控Anthropic状态页面
遇到持续的529错误时,建议查看Anthropic Status Page确认是否有全局性故障。如果状态页显示服务正常但你仍然频繁遇到529,可能是特定区域或模型的问题。
高峰时段规避
根据经验,北美工作时间(太平洋时间上午9点至下午6点)通常是API使用高峰。如果你的应用可以容忍延迟,可以考虑在非高峰时段处理批量任务。
500/404/413错误处理
这三种错误相对少见,但了解它们的处理方式同样重要。
500 api_error:内部服务器错误
500错误表示Anthropic服务器端发生了意外故障。这不是你的请求问题,而是服务端的bug或故障。
处理方式:
- 与529类似,使用指数退避重试
- 如果持续出现,联系Anthropic支持并提供request_id
- 检查状态页面确认是否有已知故障
hljs pythontry:
response = client.messages.create(...)
except anthropic.InternalServerError as e:
print(f"服务器内部错误: {e}")
print(f"Request ID: {e.request_id}")
# 记录日志并重试
404 not_found_error:资源未找到
404错误通常意味着你请求的资源不存在,最常见的原因是模型名称拼写错误。
常见原因:
- 模型名称错误:
claude-4-sonnet(错误)vsclaude-sonnet-4-5(正确) - 请求了不存在的端点
- 在Batch API中引用了不存在的batch_id
解决方案:
hljs python# 有效的模型名称(2025年)
VALID_MODELS = [
"claude-sonnet-4-5",
"claude-sonnet-4",
"claude-haiku-4-5",
"claude-opus-4"
]
def validate_model(model_name):
if model_name not in VALID_MODELS:
raise ValueError(f"无效的模型名称: {model_name}")
413 request_too_large:请求体过大
413错误发生在请求大小超过端点限制时(Messages API为32MB)。这个错误由Cloudflare返回,不会到达Anthropic服务器。
常见原因:
- 发送了过大的图片(base64编码后)
- 单次请求包含过多的对话历史
- 工具定义过于庞大
解决方案:
hljs pythonimport sys
def check_request_size(payload):
size = sys.getsizeof(str(payload))
max_size = 32 * 1024 * 1024 # 32MB
if size > max_size * 0.8: # 预警阈值80%
print(f"警告: 请求大小 {size/1024/1024:.1f}MB 接近限制")
if size > max_size:
raise ValueError(f"请求过大: {size/1024/1024:.1f}MB > 32MB")
# 图片压缩建议
# 1. 使用JPEG而非PNG
# 2. 降低分辨率(Claude通常不需要超高分辨率)
# 3. 只发送必要的图片区域
错误处理最佳实践
将前面讨论的各种错误处理方式整合成一个健壮的错误处理框架,是生产环境的关键。
统一错误处理类
hljs pythonimport time
import random
import anthropic
from anthropic import (
APIError,
AuthenticationError,
BadRequestError,
RateLimitError,
InternalServerError
)
class ClaudeAPIHandler:
def __init__(self, api_key=None, max_retries=5, base_delay=1):
self.client = anthropic.Anthropic(api_key=api_key)
self.max_retries = max_retries
self.base_delay = base_delay
def _calculate_delay(self, attempt, retry_after=None):
"""计算重试延迟(带抖动的指数退避)"""
if retry_after:
return retry_after
delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, delay * 0.1)
return min(delay + jitter, 60) # 最大60秒
def _is_retryable(self, error):
"""判断错误是否可重试"""
if isinstance(error, RateLimitError):
return True
if isinstance(error, InternalServerError):
return True
if isinstance(error, APIError) and error.status_code == 529:
return True
return False
def create_message(self, **kwargs):
"""带完整错误处理的消息创建"""
last_error = None
for attempt in range(self.max_retries):
try:
response = self.client.messages.create(**kwargs)
return response
except AuthenticationError as e:
# 不可重试:立即抛出
raise ValueError(f"API Key无效: {e}")
except BadRequestError as e:
# 不可重试:立即抛出
raise ValueError(f"请求格式错误: {e}")
except (RateLimitError, InternalServerError) as e:
last_error = e
retry_after = getattr(e, 'retry_after', None)
delay = self._calculate_delay(attempt, retry_after)
error_type = "速率限制" if isinstance(e, RateLimitError) else "服务器错误"
print(f"{error_type},等待{delay:.1f}秒后重试 ({attempt+1}/{self.max_retries})")
time.sleep(delay)
except APIError as e:
if e.status_code == 529:
last_error = e
delay = self._calculate_delay(attempt)
print(f"服务过载,等待{delay:.1f}秒后重试 ({attempt+1}/{self.max_retries})")
time.sleep(delay)
else:
raise
raise Exception(f"重试{self.max_retries}次后仍然失败: {last_error}")
# 使用示例
handler = ClaudeAPIHandler()
response = handler.create_message(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello"}]
)
监控和告警
生产环境中,建议在错误率达到一定阈值时触发告警:
hljs pythonfrom collections import defaultdict
from datetime import datetime, timedelta
class ErrorMonitor:
def __init__(self, alert_threshold=0.1, window_minutes=5):
self.requests = []
self.errors = defaultdict(list)
self.alert_threshold = alert_threshold
self.window = timedelta(minutes=window_minutes)
def record_request(self, success=True, error_type=None):
now = datetime.now()
self.requests.append((now, success))
if not success:
self.errors[error_type].append(now)
self._cleanup()
self._check_alert()
def _cleanup(self):
cutoff = datetime.now() - self.window
self.requests = [(t, s) for t, s in self.requests if t > cutoff]
for error_type in self.errors:
self.errors[error_type] = [t for t in self.errors[error_type] if t > cutoff]
def _check_alert(self):
if not self.requests:
return
error_rate = sum(1 for _, s in self.requests if not s) / len(self.requests)
if error_rate > self.alert_threshold:
print(f"⚠️ 告警: 错误率 {error_rate:.1%} 超过阈值 {self.alert_threshold:.1%}")
for error_type, times in self.errors.items():
if times:
print(f" - {error_type}: {len(times)}次")
中国开发者常见问题专项解决
由于网络环境的特殊性,中国开发者在使用Claude API时常遇到一些特定问题。这里整理了最常见的场景和解决方案。
连接超时问题
症状:API Error (Request timed out...) 或 Connection error
原因:直连Anthropic服务器的网络不稳定或被阻断
解决方案:
方案一:配置代理环境变量
hljs bashexport HTTP_PROXY="http://127.0.0.1:7890"
export HTTPS_PROXY="http://127.0.0.1:7890"
方案二:使用中转API服务
推荐使用laozhang.ai,无需代理即可直连。价格与官方一致,并且聚合多节点保障稳定性:
hljs pythonfrom openai import OpenAI
# 替换为laozhang.ai端点
client = OpenAI(
api_key="sk-YOUR_KEY",
base_url="https://api.laozhang.ai/v1"
)
response = client.chat.completions.create(
model="claude-sonnet-4-5",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Claude Code无法连接
症状:Unable to connect to Anthropic services 或 ERR_BAD_REQUEST
解决方案:
- 修改配置文件(Windows:
C:\Users\用户名\.claude.json,Mac/Linux:~/.claude.json):
hljs json{
"hasCompletedOnboarding": true,
"anthropic_api_key": "sk-ant-xxx"
}
- 配置代理(仅在运行Claude时启用):
hljs bash# 创建启动脚本 claude-proxy.sh
#!/bin/bash
export HTTP_PROXY="http://127.0.0.1:7890"
export HTTPS_PROXY="http://127.0.0.1:7890"
claude "$@"
- 使用第三方兼容服务:
hljs bash# 设置环境变量指向中转服务
export ANTHROPIC_BASE_URL="https://api.laozhang.ai"
export ANTHROPIC_API_KEY="sk-your-key"
显示Offline状态
原因:Claude Code尝试连接Google服务器检测网络状态
影响:通常不影响核心功能,只要能连接到API即可正常使用
忽略方式:只需确保API调用正常,offline状态可以忽略
快速参考与FAQ
错误码快速定位
| 看到的错误 | 含义 | 首要操作 |
|---|---|---|
| 400 | 请求格式错误 | 检查JSON和必填字段 |
| 401 | Key无效 | 验证API Key |
| 403 | 权限不足 | 检查账户层级 |
| 404 | 资源不存在 | 检查模型名称 |
| 413 | 请求太大 | 减小请求体 |
| 429 | 速率限制 | 等待retry-after |
| 500 | 服务器错误 | 重试并报告 |
| 529 | 服务过载 | 指数退避重试 |
FAQ
Q: 429错误多久会解除?
A: 取决于你触发的是哪种限制。查看响应头中的retry-after获取精确等待时间,通常几秒到几分钟不等。
Q: 如何查看当前的速率限制剩余量?
A: 每次API响应头中都包含anthropic-ratelimit-*系列字段,显示当前限制和剩余额度。也可以在Console的Limits页面查看。
Q: 529错误是我的问题吗?
A: 不是。529是Anthropic服务端过载,影响所有用户。你只能等待重试,无需修改代码。
Q: 能否绕过速率限制?
A: 正当方式包括:升级账户层级、使用Prompt Caching减少token消耗、使用Batch API处理非实时任务。使用中转服务也可以获得更高的有效限额。
Q: request_id在哪里找?
A: 响应头的request-id字段,或SDK中通过response._request_id获取。提交工单时务必提供此ID。
Q: 流式响应中如何处理错误?
A: 流式响应可能在200状态码后发生错误,需要解析完整响应流。建议包裹try-catch并在异常时检查已接收的数据完整性。
重试逻辑速查
hljs python# 最简重试模板
import time
def simple_retry(func, *args, max_retries=3, **kwargs):
for i in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if i == max_retries - 1:
raise
time.sleep(2 ** i) # 1, 2, 4秒
层级升级速查
| 当前层级 | 升级到下一级需充值 | 升级后RPM提升 |
|---|---|---|
| Tier 1 | $40累计 | 50 → 1,000 |
| Tier 2 | $200累计 | 1,000 → 2,000 |
| Tier 3 | $400累计 | 2,000 → 4,000 |
遇到未在本文列出的错误?建议先查看Anthropic官方文档,或在Anthropic Status页面确认服务状态。如需更稳定的API访问体验,可以了解laozhang.ai提供的中转服务,价格与官方一致,国内可直连。