Anthropic的Claude API采用分层配额体系,但官方文档对各层级的实际含义、晋级逻辑和预算管理缺乏深入解释。作为长期使用Claude API的开发者,我将基于官方文档和实际使用经验,系统拆解Tier1-4的完整配额机制,帮助你理解消费限制、速率限制的真正含义,以及如何高效管理API预算。
Claude API配额体系概览
Claude API的限制分为两个维度:消费限制(Spend Limits) 和 速率限制(Rate Limits)。消费限制决定你每月能花多少钱,速率限制决定你每分钟能发多少请求。这两个维度都与你的使用层级(Usage Tier) 直接挂钩。
当前Anthropic提供五个层级:
| 层级 | 累计充值门槛 | 月度消费上限 | 核心特点 |
|---|---|---|---|
| Tier 1 | $5 | $100 | 入门级,适合个人开发测试 |
| Tier 2 | $40 | $500 | 中小项目,API调用频率提升20倍 |
| Tier 3 | $200 | $1,000 | 生产级应用,支持中等规模业务 |
| Tier 4 | $400 | $5,000 | 高负载场景,解锁1M上下文窗口 |
| 自定义 | 联系销售 | 无上限 | 企业级,定制化限制 |
关键理解:层级晋升是累计充值金额决定的,而非当前余额。充值$5立即进入Tier 1,累计充值达到$40自动升级到Tier 2,无需额外操作。
Tier 1-4消费限制详解
Tier 1:开发者入门阶段
晋级条件:首次充值$5即可解锁
消费限制:
- 月度消费上限:$100
- 单次最大充值:$100(防止账户过度充值)
速率限制(以Claude Sonnet 4.x为例):
- RPM(每分钟请求数):50
- ITPM(每分钟输入Token):30,000
- OTPM(每分钟输出Token):8,000
实际场景:假设平均每次请求消耗1,000输入Token + 500输出Token,Tier 1允许你每分钟进行约30次完整对话,每月最多消费$100。对于个人开发者测试或小型内部工具,这个限制通常足够。
Tier 2:项目验证阶段
晋级条件:累计充值$40
消费限制:
- 月度消费上限:$500
- 单次最大充值:$500
速率限制提升幅度:
| 模型 | Tier 1 RPM | Tier 2 RPM | 提升倍数 |
|---|---|---|---|
| Claude Sonnet 4.x | 50 | 1,000 | 20倍 |
| Claude Haiku 4.5 | 50 | 1,000 | 20倍 |
| Claude Opus 4.x | 50 | 1,000 | 20倍 |
ITPM/OTPM提升:
- Sonnet 4.x:30K → 450K(15倍)
- Haiku 4.5:50K → 450K(9倍)
实际场景:Tier 2是多数创业项目的起步层级。每分钟1,000个请求足以支撑一个中等流量的AI应用,月度$500的消费上限也能覆盖大部分MVP验证期的需求。
Tier 3:生产环境阶段
晋级条件:累计充值$200
消费限制:
- 月度消费上限:$1,000
- 单次最大充值:$1,000
速率限制:
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 2,000 | 800,000 | 160,000 |
| Claude Haiku 4.5 | 2,000 | 1,000,000 | 200,000 |
| Claude Opus 4.x | 2,000 | 800,000 | 160,000 |
关键变化:Tier 3的ITPM提升到80万,这意味着你可以在单个请求中处理更长的上下文(约200K Token),同时保持每分钟2,000个请求的吞吐量。
Tier 4:高负载生产阶段
晋级条件:累计充值$400
消费限制:
- 月度消费上限:$5,000
- 单次最大充值:$5,000
速率限制(完整表格):
| 模型 | RPM | ITPM | OTPM |
|---|---|---|---|
| Claude Sonnet 4.x | 4,000 | 2,000,000 | 400,000 |
| Claude Haiku 4.5 | 4,000 | 4,000,000 | 800,000 |
| Claude Opus 4.x | 4,000 | 2,000,000 | 400,000 |
独家功能:Tier 4用户可以使用1M Token上下文窗口(目前处于Beta阶段),这对于处理超长文档、代码库分析等场景至关重要。
1M上下文限制:当请求超过200K Token时,适用专门的长上下文速率限制——ITPM 1,000,000,OTPM 200,000。
层级晋升的隐藏规则
即时晋升机制
官方文档明确指出:达到充值门槛后立即晋升,不存在等待期。这与部分第三方平台报道的"7天等待期"不同。
hljs python# 晋级逻辑示意
def check_tier_upgrade(cumulative_deposits: float) -> str:
if cumulative_deposits >= 400:
return "Tier 4"
elif cumulative_deposits >= 200:
return "Tier 3"
elif cumulative_deposits >= 40:
return "Tier 2"
elif cumulative_deposits >= 5:
return "Tier 1"
else:
return "Free Tier"
充值上限的设计逻辑
Anthropic设计了单次充值上限等于月度消费上限的机制,目的是防止用户过度充值后无法使用。例如:
- Tier 1用户单次最多充值$100
- 要充值$500,必须先升级到Tier 2(累计充值$40)
这意味着如果你预计月度消费超过$100,应该提前分批充值到$40以解锁Tier 2,否则你会被$100的单次充值上限卡住。
跨月重置规则
消费限制在每个日历月的第一天UTC时间重置。例如,1月份消费了$80,2月1日自动恢复$100的配额(Tier 1用户)。未使用的配额不会累积。

速率限制的深度理解
令牌桶算法
Claude API使用令牌桶算法进行速率限制,而非固定时间窗口重置。这意味着:
- 容量持续补充到最大值
- 短时间爆发请求可能触发限制
- 60 RPM可能被强制执行为1 RPS
实际影响:即使你的平均请求率低于限制,短时间内的请求突增仍可能触发429错误。
缓存感知ITPM
这是Claude API的一个关键优势:对于大多数模型,只有未缓存的输入Token计入ITPM限制。
hljs python# Token计数逻辑
total_input_tokens = (
cache_read_input_tokens + # 不计入ITPM
cache_creation_input_tokens + # 计入ITPM
input_tokens # 计入ITPM(最后一个缓存断点之后的部分)
)
优化策略:使用提示缓存可以大幅提升有效吞吐量。假设你有2M ITPM限制和80%缓存命中率,实际可处理的总Token数为10M/分钟(2M未缓存 + 8M缓存)。
不同模型的限制差异
同一层级下,不同模型的限制存在明显差异:
| 模型 | Tier 4 ITPM | 特点 |
|---|---|---|
| Claude Haiku 4.5 | 4,000,000 | 最高吞吐,适合批量简单任务 |
| Claude Sonnet 4.x | 2,000,000 | 性能均衡,主力生产模型 |
| Claude Opus 4.x | 2,000,000 | 最强能力,复杂推理任务 |
注意:Opus 4.x和Sonnet 4.x的速率限制是跨版本共享的。例如,Opus 4、Opus 4.1、Opus 4.5共享同一个4,000 RPM的限制池。
预算设置与成本控制
Workspace级别限制
为了防止单个项目耗尽整个组织的配额,你可以为工作区(Workspace) 设置独立的限制:
- 登录Claude Console
- 进入Settings → Workspaces
- 为每个Workspace设置Token限制
示例:组织限制为40K ITPM + 8K OTPM,可以将某个Workspace限制为30K总Token/分钟,确保其他Workspace有资源可用。
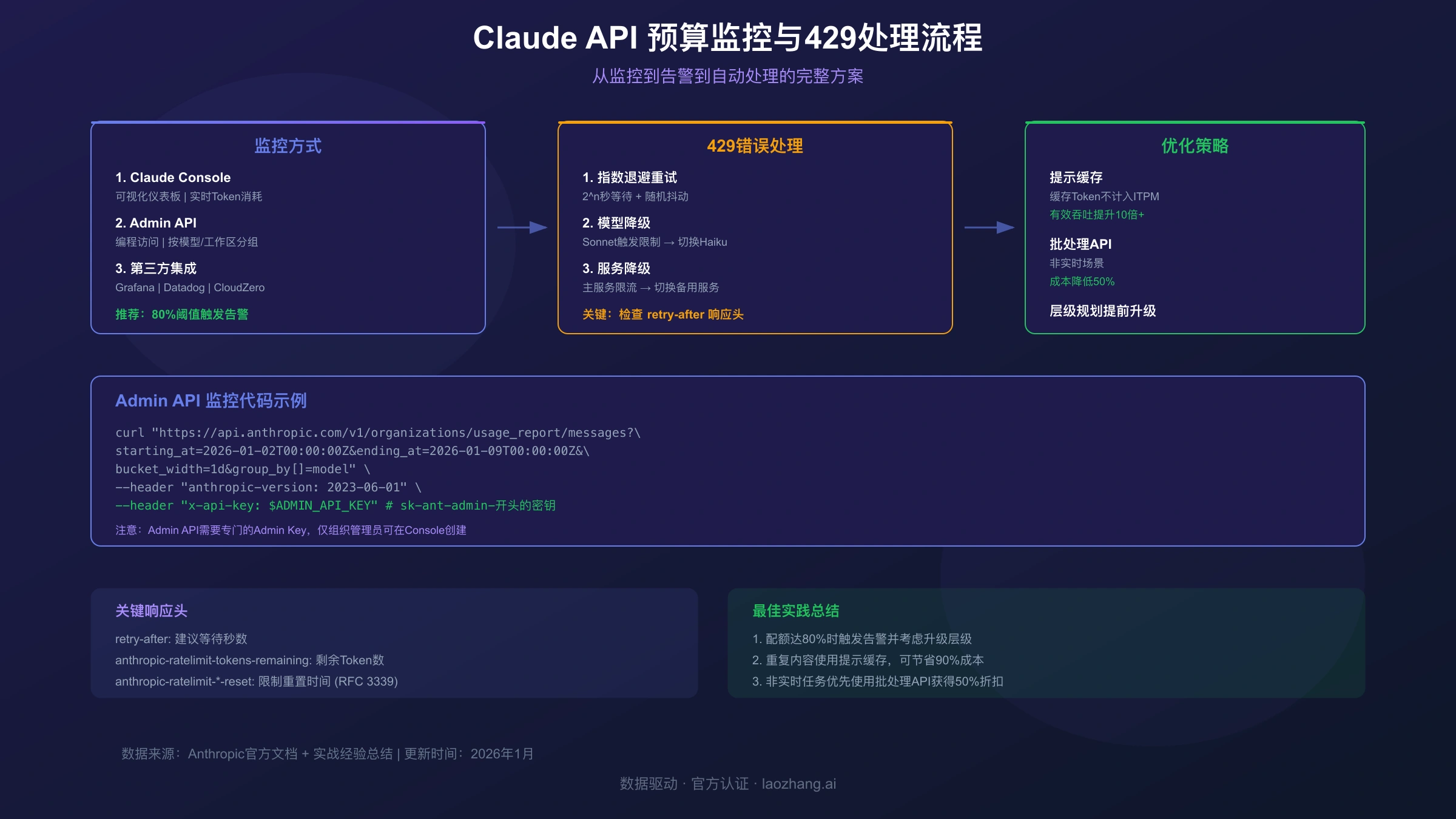
消费监控的三种方式
方式1:Console仪表板
Claude Console提供可视化的使用量监控:
- 按日/周/月查看Token消耗趋势
- 按模型分组的成本明细
- 速率限制使用率图表
- 缓存命中率监控
方式2:Admin API编程监控
对于需要自动化监控的场景,使用Usage & Cost Admin API:
hljs pythonimport requests
ADMIN_API_KEY = "sk-ant-admin-YOUR_KEY" # Admin API Key(非普通API Key)
# 获取过去7天的每日使用量
response = requests.get(
"https://api.anthropic.com/v1/organizations/usage_report/messages",
params={
"starting_at": "2026-01-02T00:00:00Z",
"ending_at": "2026-01-09T00:00:00Z",
"bucket_width": "1d",
"group_by[]": "model"
},
headers={
"anthropic-version": "2023-06-01",
"x-api-key": ADMIN_API_KEY
}
)
usage_data = response.json()
for bucket in usage_data.get("data", []):
print(f"日期: {bucket['timestamp']}")
print(f" 输入Token: {bucket['input_tokens']:,}")
print(f" 输出Token: {bucket['output_tokens']:,}")
print(f" 缓存读取: {bucket['cache_read_input_tokens']:,}")
注意:Admin API需要专门的Admin API Key(以
sk-ant-admin开头),只有组织管理员可以在Console中创建。
方式3:第三方监控集成
对于已有监控基础设施的团队,可以集成:
- Grafana Cloud:无代理集成,提供预置仪表板和告警
- Datadog:LLM可观测性,自动追踪和监控
- CloudZero:云成本智能平台,预测和优化支出
预算告警设置
通过Admin API结合自己的告警系统,可以实现自动化预算监控:
hljs pythonimport requests
from datetime import datetime, timedelta
def check_daily_spend(threshold_usd: float = 50):
"""检查当日消费是否超过阈值"""
today = datetime.utcnow().strftime("%Y-%m-%dT00:00:00Z")
tomorrow = (datetime.utcnow() + timedelta(days=1)).strftime("%Y-%m-%dT00:00:00Z")
response = requests.get(
"https://api.anthropic.com/v1/organizations/cost_report",
params={
"starting_at": today,
"ending_at": tomorrow,
"bucket_width": "1d"
},
headers={
"anthropic-version": "2023-06-01",
"x-api-key": ADMIN_API_KEY
}
)
cost_data = response.json()
total_cost = sum(float(item["total_cost_usd"]) for item in cost_data.get("data", []))
if total_cost > threshold_usd:
send_alert(f"Claude API日消费已达${total_cost:.2f},超过阈值${threshold_usd}")
return True
return False
429错误处理与优化
错误类型识别
当遇到429错误时,响应中会包含具体的限制类型:
hljs json{
"type": "error",
"error": {
"type": "rate_limit_error",
"message": "Rate limit exceeded. Please retry after 60 seconds."
}
}
响应头中的关键信息:
| 响应头 | 含义 |
|---|---|
retry-after | 建议等待秒数 |
anthropic-ratelimit-requests-remaining | 剩余请求数 |
anthropic-ratelimit-tokens-remaining | 剩余Token数 |
anthropic-ratelimit-*-reset | 限制重置时间 |
指数退避重试策略
hljs pythonimport time
import random
from anthropic import Anthropic, RateLimitError
client = Anthropic()
def call_with_retry(prompt: str, max_retries: int = 5):
"""带指数退避的API调用"""
for attempt in range(max_retries):
try:
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response
except RateLimitError as e:
if attempt == max_retries - 1:
raise
# 指数退避 + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"触发速率限制,等待 {wait_time:.1f} 秒后重试...")
time.sleep(wait_time)
return None
自适应模型降级
当主力模型触发限制时,可以自动切换到更轻量的模型:
hljs pythonMODEL_PRIORITY = [
"claude-sonnet-4-5-20250929", # 首选
"claude-haiku-4-5-20250929", # 备选(更高ITPM)
]
def adaptive_call(prompt: str):
"""自适应模型选择"""
for model in MODEL_PRIORITY:
try:
response = client.messages.create(
model=model,
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response
except RateLimitError:
print(f"{model} 触发限制,尝试下一个模型...")
continue
raise Exception("所有模型均触发速率限制")
高级优化策略
批处理API的成本优势
对于非实时场景,使用Message Batches API可以获得50%的成本折扣:
hljs python# 创建批处理任务
batch = client.messages.batches.create(
requests=[
{
"custom_id": "req-1",
"params": {
"model": "claude-sonnet-4-5-20250929",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "分析这段代码..."}]
}
},
# ... 更多请求
]
)
批处理限制(Tier 4):
- RPM:4,000
- 处理队列最大请求数:500,000
- 单批次最大请求数:100,000
提示缓存最大化
对于包含大量重复内容的场景(系统提示、工具定义、文档上下文),使用提示缓存可以显著提升有效吞吐量:
hljs pythonresponse = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是一个专业的代码审查助手...", # 长系统提示
"cache_control": {"type": "ephemeral"} # 启用缓存
}
],
messages=[{"role": "user", "content": "审查这段代码..."}]
)
缓存的Token以基础价格的10%计费,且不计入ITPM限制(大多数模型)。
中转服务作为备选方案
对于需要更灵活配额管理或中国区访问的场景,可以考虑使用第三方中转服务作为补充。例如laozhang.ai提供:
- 兼容OpenAI SDK的接口,只需修改
base_url - 无月度消费上限限制
- 聚合多家模型供应商,自动故障转移
hljs pythonfrom openai import OpenAI
# 使用中转服务作为备选
backup_client = OpenAI(
api_key="sk-your-laozhang-key",
base_url="https://api.laozhang.ai/v1"
)
def call_with_fallback(prompt: str):
"""主服务限流时切换到备选"""
try:
return client.messages.create(...) # 优先使用官方API
except RateLimitError:
# 切换到备选服务
return backup_client.chat.completions.create(
model="claude-sonnet-4-5-20250929",
messages=[{"role": "user", "content": prompt}]
)
官方API仍然是首选,中转服务适合作为限流期间的应急方案或特殊网络环境下的替代选择。
常见问题解答
如何查看当前层级?
登录Claude Console,在Limits页面可以查看:
- 当前使用层级
- 累计充值金额
- 各项速率限制的当前值
- 本月已用消费额度
充值后多久生效?
立即生效。信用购买完成后,层级提升和新的配额限制立即应用。
429错误是否扣费?
不扣费。被限流的请求不产生任何费用,只有成功完成的请求才计费。
如何申请更高限制?
有两种方式:
- 自动晋升:继续充值到下一层级门槛
- 企业定制:年消费超过$10,000可联系销售申请自定义限制
不同模型的限制是否独立?
是的。每个模型有独立的RPM/ITPM/OTPM限制,可以同时使用不同模型直到各自的限制。但同一模型系列(如Opus 4.x包含4/4.1/4.5)共享限制池。
实用参考
层级对照表
| 层级 | 充值门槛 | 月消费上限 | Sonnet RPM | Sonnet ITPM |
|---|---|---|---|---|
| Tier 1 | $5 | $100 | 50 | 30,000 |
| Tier 2 | $40 | $500 | 1,000 | 450,000 |
| Tier 3 | $200 | $1,000 | 2,000 | 800,000 |
| Tier 4 | $400 | $5,000 | 4,000 | 2,000,000 |
推荐资源
Claude API的分层配额体系虽然复杂,但理解其底层逻辑后,你可以更好地规划项目的API使用策略。对于大多数创业项目,建议从Tier 2起步(累计充值$40),既有足够的速率限制支撑开发测试,又能避免意外超支。随着业务增长,再逐步升级到更高层级。