Gemini Pro vs Flash vs Flash-Lite:三款模型完全对比指南(2026年)
详细对比Google Gemini 2.5 Pro、Flash、Flash-Lite三款模型的性能、价格、速度差异,帮助你选择最适合的模型。含基准测试数据和选型决策框架。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

不知道选Gemini Pro、Flash还是Flash-Lite?这三款模型虽然都来自Google的Gemini 2.5系列,但在性能、速度和价格上有着显著差异。选错模型可能让你多花10倍的钱,或者得到不符合预期的结果质量。
快速答案:Gemini 2.5 Flash是大多数场景的最佳选择——它以Pro四分之一的价格提供接近的性能。Pro适合需要最强推理能力的复杂任务,Flash-Lite适合对成本极度敏感的高吞吐量任务。接下来我们将详细分析这三款模型的差异,帮你做出正确选择。

三款Gemini模型一览:Pro、Flash、Flash-Lite定位差异
Gemini 2.5系列包含三款定位明确的模型:Pro追求最强性能,Flash追求性价比,Flash-Lite追求最低成本。
Google在设计Gemini 2.5系列时,采用了"梯队策略"——不同模型服务不同需求。理解这个设计逻辑,是正确选择模型的第一步。
Gemini 2.5 Pro是旗舰模型,Google官方将其定位为"最先进的思考模型"(state-of-the-art thinking model)。它专门为复杂推理任务设计,在代码、数学和STEM领域表现最为出色。Pro模型支持完整的100万token上下文窗口,并且拥有最强大的"深度思考"能力。如果你的任务需要处理复杂的代码库分析、长篇技术文档理解或高级数学推理,Pro是唯一选择。
Gemini 2.5 Flash被Google定位为"最佳性价比模型"。它在保持高质量输出的同时,大幅提升了响应速度并降低了成本。Flash适合需要平衡质量和效率的生产环境,比如聊天机器人、内容摘要、数据提取等任务。企业客户Suggestic报告称,Flash在关键基准测试中比上一代模型提升了25%的处理速度。
Gemini 2.5 Flash-Lite是"极速低成本"的代名词。它是整个2.5系列中速度最快、价格最低的模型。Flash-Lite专门为高吞吐量、低延迟的场景优化,比如实时翻译、文本分类、智能路由等任务。Google数据显示,Flash-Lite的延迟比2.0 Flash更低,而且价格仅为Flash的三分之一。
| 模型 | 官方定位 | 核心优势 | 主要限制 |
|---|---|---|---|
| Gemini 2.5 Pro | 最先进的思考模型 | 最强推理能力 | 成本最高、速度最慢 |
| Gemini 2.5 Flash | 最佳性价比模型 | 平衡速度和质量 | 复杂推理略逊于Pro |
| Gemini 2.5 Flash-Lite | 极速低成本模型 | 最快速度、最低价格 | 高级推理能力有限 |
核心性能对比:推理、速度、质量三维分析
Pro在复杂推理上领先,Flash提供最佳平衡,Flash-Lite在速度上无可匹敌。
性能差异是选择模型时最需要考虑的因素。三款模型在推理能力、响应速度和输出质量上各有千秋,了解这些差异才能做出明智的选择。
在推理能力方面,Pro毫无疑问是最强的。它在数学推理测试AIME 2024中取得了92%的准确率,在科学推理测试GPQA Diamond中达到84%。这种能力差距在处理复杂代码、多步骤数学证明或长篇技术分析时尤为明显。Flash的推理能力约为Pro的85-90%,对于大多数日常任务来说已经足够。Flash-Lite的推理能力则更适合简单任务,处理复杂逻辑时可能出现质量下降。
在响应速度方面,三款模型形成了明显的梯队。Flash-Lite的延迟比2.0 Flash低约50%,是整个系列中最快的。Flash的速度约为Pro的3倍,这在生产环境中意味着显著更好的用户体验和更低的服务器成本。Pro虽然最慢,但提供了可选的"Deep Think"模式,可以在需要时牺牲速度换取更深度的推理。
在输出质量方面,Pro在创意写作和技术文档生成上表现最佳,用词更精准、逻辑更严密。Flash的输出质量已经能满足商业级应用需求。Flash-Lite的输出在简单任务上与Flash相当,但在复杂任务上可能出现质量波动。
| 维度 | Pro | Flash | Flash-Lite |
|---|---|---|---|
| 推理能力 | 最强(基准100%) | 强(约85-90%) | 中等(约70-75%) |
| 响应速度 | 基准 | 约3倍 | 约4-5倍 |
| 输出质量 | 最高 | 高 | 中高 |
| Thinking模式 | 完整支持+Deep Think | 支持 | 默认关闭,可开启 |

价格与成本分析:三款模型费用差异高达12倍
Flash-Lite的输入价格仅为Pro的8%,选对模型可以大幅降低API成本。
价格是很多开发者选择模型时的首要考虑因素。三款模型的定价策略差异巨大,理解这些差异有助于在满足需求的前提下最大化成本效益。
Gemini 2.5 Pro的定价为输入$1.25/百万tokens、输出$10.00/百万tokens(200K上下文以内)。超过200K上下文时价格翻倍。这个价格在旗舰模型中属于合理水平,比GPT-4o便宜约4倍。Pro的定价反映了其强大的推理能力和资源消耗。
Gemini 2.5 Flash的定价为输入$0.30/百万tokens、输出$2.50/百万tokens。相比Pro,输入成本降低了76%,输出成本降低了75%。对于大多数应用场景而言,Flash提供了接近Pro的质量,但成本只有四分之一左右。
Gemini 2.5 Flash-Lite的定价为输入$0.10/百万tokens、输出$0.40/百万tokens。这是整个Gemini系列中最便宜的模型——输入价格仅为Pro的8%,输出价格仅为Pro的4%。对于成本敏感的大规模处理任务,Flash-Lite可以带来数量级的成本节省。
以一个实际场景为例:假设每天处理100万tokens的输入和50万tokens的输出。使用Pro每天成本为$6.25,使用Flash为$1.55,使用Flash-Lite仅为$0.30。一个月下来,选择Flash-Lite比Pro节省约$178,这对于中小企业来说是很可观的数字。
| 模型 | 输入价格/1M | 输出价格/1M | 月成本示例* |
|---|---|---|---|
| Pro | $1.25 | $10.00 | ~$188 |
| Flash | $0.30 | $2.50 | ~$47 |
| Flash-Lite | $0.10 | $0.40 | ~$9 |
*示例:每天100万输入+50万输出tokens
使用场景完全指南:什么任务用什么模型
Pro适合高价值复杂任务,Flash适合日常生产应用,Flash-Lite适合大规模简单任务。
选择正确的模型不仅关乎成本,更关乎任务的成功率和用户体验。以下是基于实际场景的详细推荐。
Gemini 2.5 Pro适合的场景包括:复杂代码生成和重构(需要理解大型代码库)、长篇技术文档分析(超过50K tokens的内容)、高级数学和科学推理、需要最高准确率的关键业务任务。实际案例中,Pro在处理完整代码库分析时能够理解模块间的依赖关系,这是Flash和Flash-Lite难以做到的。如果你的任务失败代价很高,比如自动化代码审查或金融数据分析,Pro的额外成本是值得的。
Gemini 2.5 Flash适合的场景包括:生产环境的聊天机器人、内容摘要和改写、数据提取和格式转换、中等复杂度的代码辅助。Flash是大多数商业应用的最佳选择,因为它在质量和成本之间取得了很好的平衡。对于需要响应延迟低于500ms的实时应用,Flash比Pro更合适。
Gemini 2.5 Flash-Lite适合的场景包括:批量文本分类、实时多语言翻译、智能路由和意图识别、日志分析和异常检测。实际案例中,HeyGen使用Flash-Lite将视频翻译成180多种语言,Satlyt使用它处理卫星遥测数据,实现了45%的延迟降低。这些场景的共同特点是任务简单但量大,Flash-Lite的低延迟和低成本优势得以充分发挥。
基准测试详解:官方数据告诉你真实能力
Pro在GPQA和AIME上领先,但Flash在SWE-Bench上表现出色。
基准测试数据是客观评估模型能力的重要依据。以下是三款模型在主要测试中的表现,数据来源为Google官方和权威第三方测试。
在科学推理测试GPQA Diamond上,Pro得分84%,这是一个包含物理、化学、生物学研究生级别问题的高难度测试。这个分数表明Pro能够处理需要深度专业知识的任务。
在数学推理测试上,Pro在AIME 2024达到92%,在AIME 2025达到86.7%。这些是美国数学邀请赛级别的题目,需要多步骤复杂推理。Flash在这类测试中的得分约为Pro的80-85%。
在代码能力测试SWE-Bench上,有一个有趣的现象:最新的Gemini 3 Flash得分78%,实际上超过了Gemini 3 Pro的76.2%。这说明在某些具体任务上,Flash系列并不一定弱于Pro。对于日常代码任务,Flash已经完全够用。
在多模态理解测试MMMU上,Pro达到81.7%的单次准确率,这是已知模型中的最高分之一。如果你的应用涉及大量图像和文本混合理解,Pro是更好的选择。
| 测试 | Pro得分 | Flash参考* | 测试内容 |
|---|---|---|---|
| GPQA Diamond | 84% | ~70% | 研究生级科学推理 |
| AIME 2024 | 92% | ~75% | 高难度数学推理 |
| SWE-Bench | 63.8% | ~55% | 代码修复能力 |
| MMMU | 81.7% | ~70% | 多模态理解 |
*Flash参考得分为估计值
Thinking模式解析:深度思考功能的差异
Pro支持最完整的Thinking模式,Flash-Lite默认关闭以优化速度。
Thinking模式是Gemini 2.5系列的核心创新之一,它允许模型在回答前进行更深入的推理。但这个功能在三款模型上的实现有所不同。
Pro的Thinking模式最为完整,支持完整的深度思考和可选的"Deep Think"模式。Deep Think会在回答特别复杂的问题时,花费更多计算资源来进行更深层次的推理。这在处理需要多步骤逻辑链的数学证明或复杂代码设计时特别有用。Pro的Thinking模式默认开启,用户可以通过thinking_budget参数调整思考深度。
Flash的Thinking模式同样默认开启,但不支持Deep Think。它提供了标准的思考能力,足以处理大多数需要逻辑推理的任务。Flash的Thinking模式经过优化,在提供推理能力的同时保持了较低的延迟。
Flash-Lite的Thinking模式默认关闭,以最大化速度和降低成本。如果需要,可以手动开启。这个设计反映了Flash-Lite的定位——优先考虑速度和成本,而非复杂推理。对于分类、翻译等简单任务,关闭Thinking模式通常是正确的选择。
在实际使用中,如果你发现Flash-Lite在某些任务上表现不佳,可以尝试开启Thinking模式(设置thinking_budget > 0)。但这会增加延迟和成本,需要权衡。
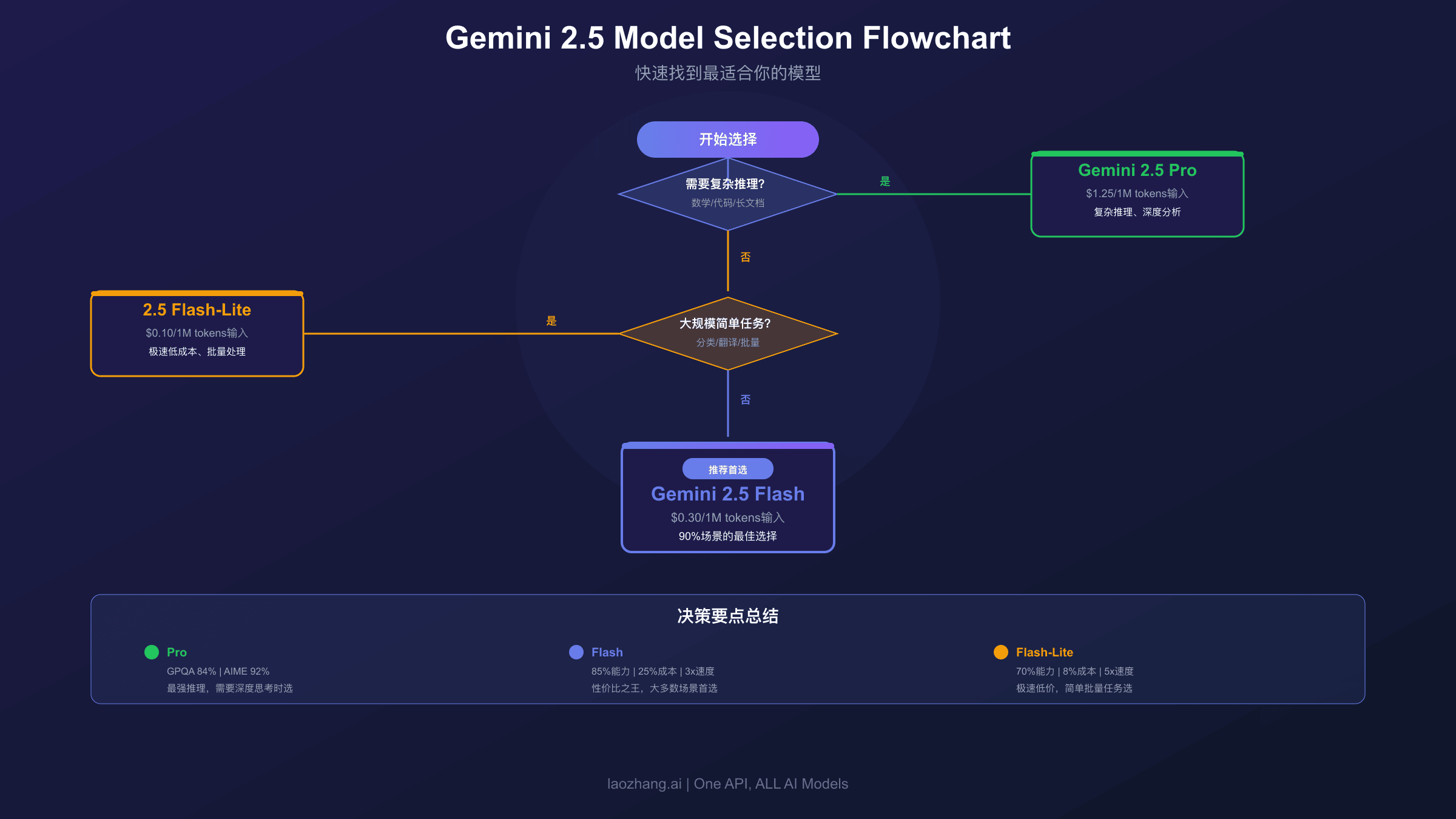
选型决策框架:快速确定最适合的模型
90%的场景选Flash,仅在复杂推理任务时选Pro,大规模简单任务选Flash-Lite。
选择模型不需要过度纠结。以下决策框架可以帮助你在一分钟内做出正确选择。
首先问自己:这个任务需要复杂推理吗?如果需要处理长代码库、多步骤数学推导或长篇技术文档分析,选Pro。否则继续下一步判断。
然后问自己:这个任务对延迟敏感或预算紧张吗?如果需要毫秒级响应(如实时翻译)或每天处理数百万请求,选Flash-Lite。否则选Flash。
这个简单的决策流程覆盖了大多数场景。Flash是默认选择,因为它在质量和成本之间取得了最好的平衡。只有明确需要最强能力或最低成本时,才需要选择Pro或Flash-Lite。
对于中国开发者,由于Google AI Studio不可直接访问,可以通过第三方平台接入Gemini API。例如laozhang.ai支持所有Gemini模型,使用OpenAI兼容接口,只需替换base_url即可调用。这种方式支持支付宝/微信支付,对国内开发者更加友好。
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="sk-YOUR_API_KEY",
base_url="https://api.laozhang.ai/v1"
)
# 根据任务选择合适的模型
response = client.chat.completions.create(
model="gemini-2.5-flash", # 大多数场景的最佳选择
messages=[{"role": "user", "content": "你好"}]
)
常见问题
Flash和Flash-Lite的质量差距大吗?
对于简单任务(分类、翻译、摘要),两者质量接近。但在需要一定推理的任务上,Flash明显更好。Google数据显示Flash-Lite在coding、math、reasoning基准上比2.0 Flash-Lite有全面提升,但仍不如标准Flash。建议先用Flash-Lite测试,如果质量不满意再升级到Flash。
什么时候应该选Pro而不是Flash?
当任务涉及以下场景时选Pro:超过50K tokens的长文档分析、需要理解大型代码库的编程任务、复杂数学推导或科学计算、对准确率要求极高的关键业务。如果你的任务不属于这些类别,Flash足够。
Gemini 2.0系列还能用吗?
可以用,但Google已宣布2.0 Flash和2.0 Flash-Lite将于2026年3月31日退役。建议尽快迁移到2.5系列。好消息是API接口完全兼容,只需更换model参数即可。
三款模型的上下文窗口都一样吗?
是的,三款2.5模型都支持100万tokens的上下文窗口。这意味着即使是最便宜的Flash-Lite,也能处理超长文档。但需要注意,Pro在处理超过200K tokens时价格会翻倍。
如何在Flash和Flash-Lite之间选择?
简单规则:如果任务需要任何程度的推理或创造性,选Flash;如果任务是纯机械性的(分类、翻译、格式转换),选Flash-Lite。Flash-Lite的Thinking模式默认关闭,这是其速度优势的来源,但也限制了它处理复杂任务的能力。