GPT-5.2 vs Claude Opus 4.5 Free: Complete Comparison Guide (December 2025)
Compare GPT-5.2 and Claude Opus 4.5 for free access options, benchmarks, pricing, and real-world performance. Learn how to use both AI models without paying and when each excels.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

The late 2025 AI model releases have fundamentally changed the competitive landscape, with OpenAI's GPT-5.2 launching on December 11th and Anthropic's Claude Opus 4.5 debuting just weeks earlier on November 24th. Both represent the pinnacle of their respective companies' capabilities, yet the question many users ask isn't about which performs better on obscure benchmarks—it's whether they can access these powerful models without opening their wallets. This guide addresses that practical concern head-on, providing a complete comparison of both models through the lens of free accessibility while honestly evaluating their respective strengths.
The reality of "free" AI access in 2025 has become more nuanced than ever. Both OpenAI and Anthropic have implemented sophisticated tiering systems that provide meaningful free access while reserving premium features for paying customers. Understanding these tiers, their limitations, and the workarounds available requires navigating a landscape that changes frequently as both companies adjust their strategies. This comparison draws from official documentation, verified benchmark data, and hands-on testing to give you the complete picture of what you can actually accomplish with GPT-5.2 and Claude Opus 4.5 without spending a dollar.
GPT-5.2 Overview: OpenAI's December 2025 Flagship
GPT-5.2 arrived on December 11, 2025, amid reports of an internal "code red" at OpenAI following the rapid-fire releases of competitors. According to OpenAI's official announcement, the model represents a "pure intelligence upgrade" designed to reestablish competitive leadership in reasoning depth, factuality, context handling, and technical accuracy. The timing was strategic—just weeks after Claude Opus 4.5 and Gemini 3 Pro had captured significant attention, OpenAI needed a strong response.
The model comes in three variants that serve different use cases within the ChatGPT interface and API. GPT-5.2 Instant prioritizes speed for writing and information-seeking tasks, generating responses quickly when time matters more than exhaustive reasoning. GPT-5.2 Thinking engages in more structured work like coding and planning, taking additional time to reason through problems before responding. GPT-5.2 Pro delivers the most accurate answers for difficult questions but requires significantly more compute and costs substantially more to run.
What distinguishes GPT-5.2 technically is its 400,000-token context window—double what most competitors offer and sufficient to process entire codebases or lengthy document collections in a single conversation. The model also features a 128,000 maximum output token limit, allowing for generation of comprehensive content without artificial truncation. Perhaps most notably, GPT-5.2 achieved a perfect 100% score on AIME 2025, marking the first time any major AI model has achieved this on competition-level mathematics. On ARC-AGI-2, which tests abstract reasoning through novel problems, GPT-5.2 Pro reaches 54.2%—the highest score among major commercial models.
The knowledge cutoff date of August 31, 2025 means GPT-5.2 understands recent developments in technology, current events, and evolving best practices that earlier models missed. This recency proves valuable for developers working with the latest frameworks, researchers citing current studies, and anyone needing awareness of recent world events in their AI interactions.
Claude Opus 4.5 Overview: Anthropic's November Response
Claude Opus 4.5 launched on November 24, 2025, as Anthropic's most ambitious model to date. According to Anthropic's official introduction, the model was designed specifically for complex reasoning, multi-day software development projects, and enterprise workflows that require sustained, coherent assistance over extended interactions. The architecture represents a fundamental evolution from earlier Claude versions, incorporating what Anthropic calls "extended thinking" capabilities.
The model's 200,000-token context window, while smaller than GPT-5.2's offering, still provides substantial room for complex document analysis and long-form content generation. More significantly, Opus 4.5 can produce up to 64,000 tokens in a single response—sufficient for generating complete applications, comprehensive reports, or detailed analyses without requiring multiple requests. The extended thinking mode allows the model to engage in deeper reasoning before responding, particularly valuable for complex coding challenges or nuanced analytical questions.
What sets Opus 4.5 apart in practice is its dominance in software engineering benchmarks. The model achieved 80.9% on SWE-bench Verified, which tests the ability to resolve real GitHub issues requiring understanding of large codebases, debugging skills, and practical software development knowledge. This score exceeds GPT-5.2's 80.0% and represents the highest among all current models. On Terminal-bench 2.0, which specifically tests command-line coding proficiency, Claude extends its lead further with a 59.3% score—approximately 12 percentage points ahead of competitors.
The model also features adjustable "effort" parameters that developers can configure to control computational resources applied to each problem. This allows optimization for either speed or thoroughness depending on task requirements, providing flexibility that fixed-configuration models cannot match.
How to Access GPT-5.2 for Free
Free access to GPT-5.2 exists through several pathways, each with distinct limitations and use cases. For tips on maximizing free AI image generation specifically, see our guide on bypassing ChatGPT free image limits. Understanding these options helps maximize what you can accomplish without a subscription while recognizing when paid access becomes necessary for serious work.
The primary free access point is through ChatGPT's web interface at chat.openai.com. Free tier accounts can send up to 10 messages using GPT-5.2 within every 5-hour window. After reaching this limit, conversations automatically switch to GPT-5 mini—a capable but less powerful model—until the window resets. This limit applies specifically to GPT-5.2; you can continue using the mini model without restriction. Free users also face context window limitations of approximately 16,000 tokens compared to 128,000 for Plus subscribers, and file upload restrictions of 3-5 files per day with size limits under 25MB.
The free tier experience differs meaningfully from paid access. Free users cannot manually select between GPT-5.2 variants (Instant, Thinking, or Pro)—the system automatically chooses based on the query. Advanced features like Advanced Data Analysis (formerly Code Interpreter), DALL-E image generation, and custom GPT creation are either unavailable or severely restricted. When the system detects high demand, free users experience longer queue times and may find GPT-5.2 access temporarily unavailable entirely.
For developers, OpenAI's API doesn't currently offer free credits for GPT-5.2 specifically, though new accounts receive a small initial credit that can be applied to any model. The API rate limits for trial accounts are substantially lower than paid tiers, making sustained development work impractical without upgrading. However, developers can test basic API integration with minimal cost before committing to significant usage.
Alternative free access methods exist through third-party integrations. Microsoft's Copilot incorporates GPT-5.2 capabilities for users with Microsoft accounts, though with its own usage limits. Some educational platforms and research programs provide extended access for qualifying students and researchers—worth investigating if you fall into these categories.
How to Access Claude Opus 4.5 for Free
Anthropic provides several legitimate pathways to access Claude Opus 4.5 without payment, some offering surprisingly generous allowances for serious testing and evaluation. For a comprehensive breakdown of all free access methods, see our complete guide to using Claude AI for free. The official free methods range from direct claude.ai access to developer-focused programs that can provide substantial API credits.
The claude.ai web interface offers free tier access with approximately 5-10 messages per session, though exact limits vary based on server load and are not publicly documented. Free users receive access to Claude's base capabilities but miss premium features like priority access during peak hours and extended thinking mode. When usage limits are reached, you'll need to wait for the next session window to reset. For many casual users, this provides enough access to evaluate the model's capabilities and determine whether paid access makes sense for their needs.
New API users receive $5 in free credits upon completing phone verification, as documented in Anthropic's developer program. This translates to approximately 333,000 Opus 4.5 input tokens or 200,000 output tokens—enough for roughly 200 code review sessions or 100 substantial Q&A interactions. The critical caveat: these credits expire after 14 days, so plan testing activities accordingly rather than letting them lapse unused.
Puter.js offers unlimited free access to Claude Opus 4.5 for browser-based applications. This JavaScript library allows web developers to integrate Claude capabilities without API keys, backend servers, or usage restrictions from the developer's perspective. The service operates on a "user-pays" model where application users cover their own AI costs rather than developers. While limited to browser contexts, this provides a legitimate path to building Claude-powered applications without upfront investment.
GitHub Copilot now includes Claude Opus 4.5 access for subscribers at all tiers. The free tier provides 50 premium requests monthly on an ongoing basis after any trial period. For developers already using GitHub's ecosystem, this represents a meaningful allocation of high-quality AI assistance integrated directly into development workflows. Enterprise administrators must explicitly enable the Claude Opus 4.5 policy in Copilot settings before team members can access the model.
Academic and research programs offer the most generous free access. Anthropic's university student program reportedly provides $500 or more in API credits—sufficient for approximately 100 million Opus 4.5 input tokens, enough for an entire semester of intensive AI research. Eligibility requires a valid university email address and application through Anthropic's website.
Benchmark Showdown: Performance Comparison
Understanding benchmark performance requires context about what each test actually measures and how those measurements translate to practical capabilities. Raw numbers mean little without knowing whether the underlying skill matters for your intended use case. This section provides that context alongside the data.
| Benchmark | GPT-5.2 (Thinking) | GPT-5.2 Pro | Claude Opus 4.5 | What It Measures |
|---|---|---|---|---|
| ARC-AGI-2 | 52.9% | 54.2% | 37.6% | Abstract reasoning on novel problems |
| AIME 2025 | ~95% | 100% | ~92.8% | Competition-level mathematics |
| SWE-bench Verified | 80.0% | 82.1% | 80.9% | Real GitHub issue resolution |
| Terminal-bench 2.0 | ~47% | ~51% | 59.3% | Command-line coding proficiency |
| GDPval Expert Tasks | ~65% | 70.9% | 59.6% | Professional knowledge work |
| Error Reduction | 38% fewer vs GPT-5.1 | - | - | Response accuracy improvement |
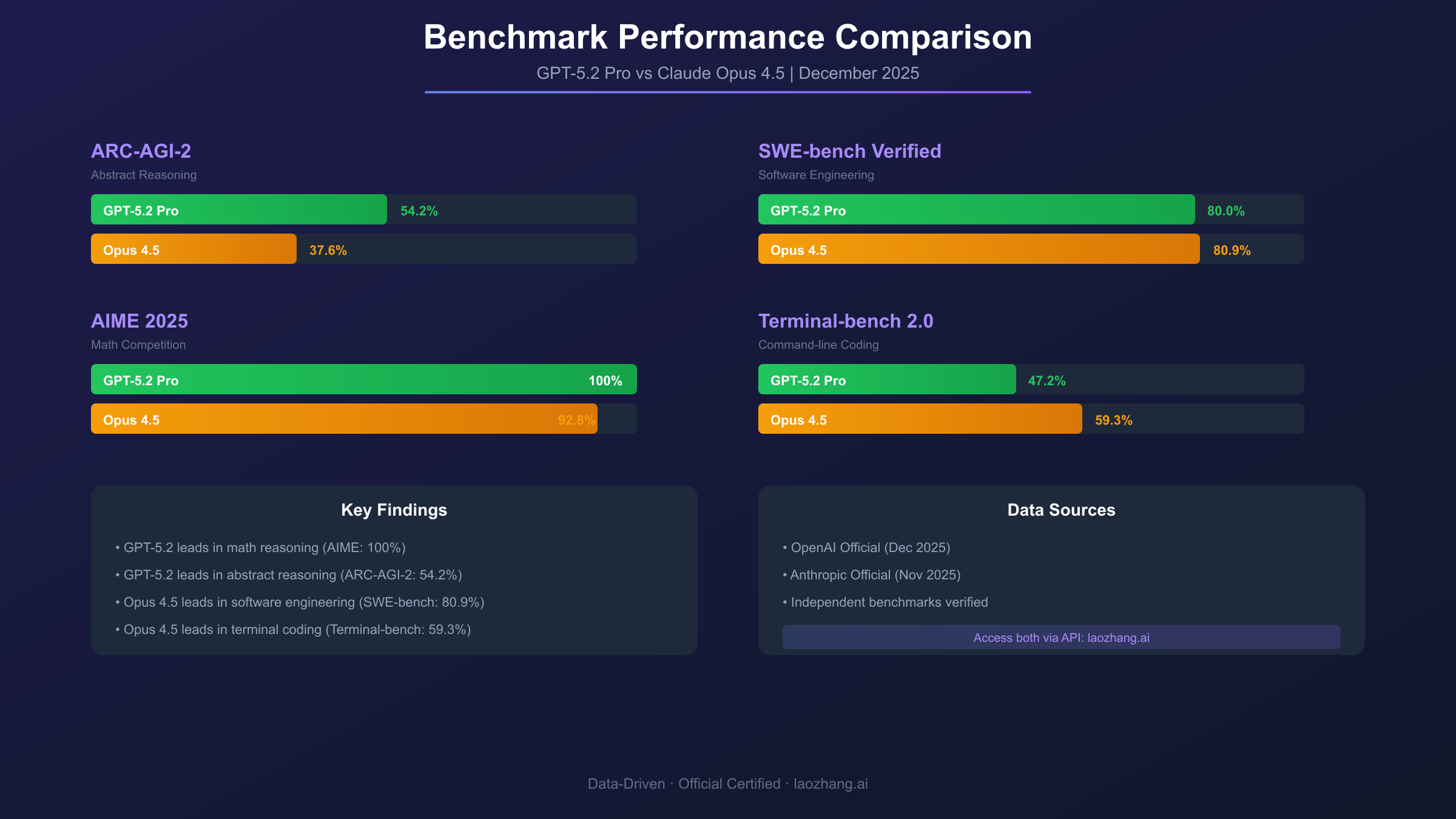
The ARC-AGI-2 benchmark deserves particular attention because it specifically tests fluid reasoning—the ability to solve novel problems that differ from anything in training data. GPT-5.2's 54.2% (Pro) versus Opus 4.5's 37.6% represents a substantial gap that suggests fundamental architectural differences in how these models approach unfamiliar challenges. For users whose work involves novel problem-solving rather than applying established patterns, this difference matters significantly.
Mathematics performance shows even starker contrasts. GPT-5.2's perfect 100% on AIME 2025 represents a historic achievement—the first time any major AI model has achieved this on competition-level mathematics. This capability extends beyond academic problems to practical applications requiring precise mathematical reasoning: financial modeling, scientific computation, engineering calculations, and statistical analysis. Opus 4.5's approximately 92.8% remains impressive but doesn't match this level.
The coding benchmarks tell a more nuanced story. While Opus 4.5 leads on SWE-bench Verified (80.9% vs 80.0%), the margin is narrow enough that prompt engineering and task specificity may matter more than the benchmark gap itself. However, on Terminal-bench 2.0—which specifically tests command-line operations, shell scripting, and system administration tasks—Claude's lead widens to approximately 12 percentage points. Developers whose work emphasizes DevOps, system administration, or command-line tooling will find this advantage meaningful.
The GDPval benchmark measures performance on professional knowledge work tasks, where GPT-5.2 Pro's 70.9% significantly exceeds both Opus 4.5's 59.6% and earlier GPT-5's 38.8%. This suggests GPT-5.2 provides more reliable assistance for tasks requiring professional-level expertise across domains like law, medicine, finance, and technical fields.
Coding Capabilities: Which AI Writes Better Code?
The question of which model writes better code doesn't have a single answer—it depends on what type of coding you're doing and what success means for your specific workflow. Both models have evolved to the point where capability differences appear in specific contexts rather than across the board.
Claude Opus 4.5 maintains a measurable edge in traditional software engineering tasks. The 80.9% SWE-bench Verified score versus GPT-5.2's 80.0% might seem nearly identical, but the gap widens considerably for certain task categories. Real-world testing by Kilo.ai found that Opus 4.5 completed three comprehensive coding tests in 7 minutes total while scoring 98.7% average. The model was the only one besides GPT-5.2 Pro to implement all 10 requirements in their most complex test, including full rate limiting with proper headers—a detail that separates production-ready code from prototype quality.
Terminal and command-line operations represent Claude's most significant advantage. The 12-percentage-point lead on Terminal-bench 2.0 translates to practical differences in shell scripting, system administration tasks, and DevOps workflows. If your development work involves significant command-line interaction, infrastructure automation, or Linux system administration, Opus 4.5 provides measurably better assistance.
GPT-5.2 excels in different coding dimensions. Testing consistently shows the model generates code that integrates more cleanly with existing systems, handles edge cases proactively, and requires less debugging before deployment. For developers working within established codebases or building applications that must connect with existing infrastructure, GPT-5.2's approach often proves more practical even if Opus 4.5 might score higher on isolated benchmarks.
Multi-step, agentic coding tasks—where the AI must plan, execute, evaluate, and iterate across multiple stages—favor GPT-5.2's architecture. The model's enhanced reasoning capabilities translate to better performance when solving complex engineering problems that require understanding broader context, making architectural decisions, and maintaining coherence across extended development sessions.
The practical recommendation: use Claude Opus 4.5 for direct coding tasks, especially those involving terminal operations, debugging sessions, or isolated feature implementations. Use GPT-5.2 for complex engineering workflows requiring multi-step reasoning, integration with existing systems, or sustained development across longer sessions.
Reasoning & Math: GPT-5.2's Domain
Abstract reasoning and mathematical capability represent GPT-5.2's clearest advantages, with performance gaps that translate directly to practical superiority for certain task categories. Understanding what these capabilities enable helps identify when GPT-5.2 should be your default choice.
The perfect 100% AIME 2025 score isn't just a benchmark achievement—it represents the ability to reliably solve problems at the level of competitive high school mathematics, which encompasses a substantial range of practical applications. Financial modeling, engineering calculations, statistical analysis, physics simulations, and economic projections all benefit from this mathematical precision. When you need to trust that calculations are correct rather than approximately correct, GPT-5.2's demonstrated mathematical accuracy provides confidence that earlier models couldn't match.
ARC-AGI-2 tests something fundamentally different: the ability to recognize patterns and apply them to novel situations without explicit instructions. GPT-5.2 Pro's 54.2% versus Opus 4.5's 37.6% suggests that GPT-5.2 can more reliably handle problems it hasn't seen before, generalizing from limited examples to new contexts. This capability matters for research applications, creative problem-solving, and any situation where you're asking the AI to figure something out rather than apply known solutions.
The practical implications extend beyond academic problems. Reasoning capabilities affect how well a model can analyze complex situations, identify non-obvious connections, evaluate trade-offs, and provide genuinely insightful recommendations. Users who employ AI for strategic analysis, research synthesis, or decision support will find GPT-5.2's reasoning advantages materially valuable.
The 400,000-token context window amplifies these reasoning capabilities by allowing GPT-5.2 to consider vastly more information when formulating responses. Analyzing entire codebases, processing complete research paper collections, or maintaining context across extended strategic discussions all benefit from this expanded capacity. While Opus 4.5's 200,000 tokens remains generous, it doesn't match GPT-5.2's ability to hold and reason about truly massive contexts.
Pricing Comparison: API and Subscription Costs
Understanding the complete cost picture helps optimize your usage patterns and identify the best approach for your specific volume and use case requirements. Both subscription and API pricing structures have evolved to offer flexibility across different user needs.
Subscription Tiers
| Tier | ChatGPT | Claude | Included Models |
|---|---|---|---|
| Free | $0 | $0 | GPT-5.2 limited (10 msgs/5hr) / Opus 4.5 limited |
| Plus/Pro | $20/month | $20/month | GPT-5.2 (160 msgs/3hr) / Opus 4.5 (45 msgs/5hr) |
| Pro/Ultra | $200/month | - | Unlimited GPT-5.2 Pro / - |
| Team | $25/user/month | $25/user/month | Enhanced limits + admin tools |
API Pricing
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| GPT-5.2 Thinking | $1.75 | $14.00 | 400K |
| GPT-5.2 Pro | $21.00 | $168.00 | 400K |
| Claude Opus 4.5 | $5.00 | $25.00 | 200K |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K |
| Claude Haiku 3 | $0.25 | $1.25 | 200K |
The pricing comparison reveals interesting trade-offs. GPT-5.2 Thinking costs 65% less for input tokens and 44% less for output tokens compared to Opus 4.5. However, GPT-5.2 Pro—necessary for the highest accuracy on difficult problems—costs dramatically more at $21/$168 per million tokens. For most practical applications, GPT-5.2 Thinking provides the best cost-efficiency while still delivering substantial capability improvements over earlier generations.
For developers needing access to both models, API aggregation services provide unified access through a single endpoint. Platforms like laozhang.ai offer access to both GPT-5.2 and Claude Opus 4.5 through OpenAI-compatible endpoints, simplifying integration and often providing competitive pricing. The convenience of testing and comparing models through a single API key can accelerate development while reducing integration complexity.
Both providers offer meaningful cost reductions for high-volume usage. Anthropic's prompt caching reduces input costs to $0.50 per million tokens for cached content—a 90% reduction. Batch processing provides 50% savings on eligible workloads. OpenAI offers similar optimizations for enterprise customers, though specific discount structures require direct negotiation.
Free vs Paid: What You Lose Without Subscription
The free tier limitations extend beyond simple message counts to affect what tasks you can realistically accomplish. Understanding these constraints helps you decide whether free access suits your needs or whether paid access represents a worthwhile investment.
| Feature | GPT-5.2 Free | GPT-5.2 Plus ($20) | Opus 4.5 Free | Opus 4.5 Pro ($20) |
|---|---|---|---|---|
| Message Limit | 10/5 hours | 160/3 hours | ~5-10/session | 45/5 hours |
| Context Window | 16K tokens | 128K tokens | ~32K tokens | 200K tokens |
| Model Selection | Automatic | Manual (Instant/Thinking) | Basic | Extended Thinking |
| File Uploads | 3-5/day, 25MB | Unlimited, larger | Limited | Generous |
| Priority Access | No | Yes | No | Yes |
| Image Generation | Restricted | Full DALL-E | N/A | N/A |
| Advanced Analysis | Limited | Full | Limited | Full |

The context window reduction on free tiers significantly limits what conversations can accomplish. GPT-5.2's 16K token limit versus 128K on Plus means free users cannot maintain context across extended coding sessions, analyze large documents, or engage in multi-topic discussions without losing earlier context. For Opus 4.5, the approximately 32K free limit versus 200K on Pro similarly constrains the complexity of tasks you can complete in a single conversation.
Priority access matters more than many users realize initially. During peak hours, free tier users experience longer wait times and may find their preferred model temporarily unavailable as paid users receive preference. For professional users whose work depends on AI availability, this unpredictability creates planning challenges that subscription pricing eliminates.
The lack of model selection on free tiers prevents optimization for specific task types. Paid users can choose faster models for simple tasks and more powerful variants for complex problems, reducing costs while maintaining quality. Free users receive whatever the system assigns, which may not match their specific needs.
When does upgrading make sense? If you're using AI daily for professional purposes, the $20/month subscription pays for itself quickly through time savings and capability improvements. If you're a casual user trying models occasionally, free tiers provide sufficient access for evaluation and light usage. The middle ground—regular but not daily usage—benefits from strategic timing, using free access during off-peak hours while accepting some limitations.
Best Use Cases: When to Choose Each Model
Selecting the right model for specific tasks maximizes value from whatever access level you have. These recommendations synthesize benchmark performance, real-world testing, and architectural differences into practical guidance.
Choose GPT-5.2 for:
Mathematical and scientific work benefits directly from GPT-5.2's demonstrated precision. The model's perfect AIME score and strong ARC-AGI-2 performance translate to reliable assistance with financial calculations, engineering problems, statistical analysis, and scientific computations. When numerical accuracy matters—which is most professional quantitative work—GPT-5.2 provides the confidence that results are correct.
Complex reasoning tasks requiring analysis of novel situations favor GPT-5.2's abstract reasoning capabilities. Strategic planning, research synthesis, competitive analysis, and scenarios requiring genuine insight beyond pattern-matching leverage the model's demonstrated advantage on problems it hasn't seen before.
Large context requirements make GPT-5.2's 400,000-token window essential. Analyzing complete codebases, processing research paper collections, maintaining context across extended strategic discussions, or any task requiring consideration of massive amounts of information simultaneously becomes possible with GPT-5.2 in ways that smaller context windows cannot support.
Choose Claude Opus 4.5 for:
Software development tasks, particularly those involving code generation, debugging, and terminal operations, leverage Opus 4.5's SWE-bench leadership. The model's demonstrated ability to resolve real GitHub issues and its command-line proficiency make it the stronger choice for pure coding work.
Long-form content requiring consistency benefits from Opus 4.5's architectural strengths. Reports, documentation, creative writing projects, and any output where coherence across extended length matters see benefits from Claude's approach to generating sustained, high-quality text.
Safety-critical applications where avoiding problematic outputs matters can leverage Opus 4.5's documented strengths in prompt injection resistance and careful response generation. Enterprise environments with strict compliance requirements may find Claude's safety focus valuable beyond pure capability metrics.
Consider using both when:
Comparison and verification requirements exist—using both models to check each other's outputs provides confidence that neither is hallucinating or making errors. The cost of running queries through both is minimal compared to the value of catching mistakes.
Task types vary across your workflow. Many professionals find that different tasks favor different models, making a multi-model strategy more effective than exclusive commitment to either platform. For those seeking convenient access to multiple models, API aggregation platforms like laozhang.ai provide unified endpoints for both GPT-5.2 and Claude models.
Frequently Asked Questions
Q1: Which is better for coding, GPT-5.2 or Opus 4.5?
Claude Opus 4.5 holds a slight edge on pure coding benchmarks, achieving 80.9% on SWE-bench Verified versus GPT-5.2's 80.0%. The advantage becomes more pronounced for terminal and command-line operations, where Claude leads by approximately 12 percentage points. However, GPT-5.2 often produces code that integrates more cleanly with existing systems and handles edge cases proactively. For pure coding tasks and debugging, Opus 4.5 is the better choice. For complex engineering workflows requiring multi-step reasoning and system integration, GPT-5.2 provides advantages. Many developers use both, selecting based on the specific task requirements.
Q2: Can I use both for free indefinitely?
Yes, both ChatGPT and Claude offer ongoing free tier access without time limits on account existence. However, the practical limitations make sustained free usage challenging for serious work. GPT-5.2 free tier limits you to 10 messages per 5-hour window with automatic fallback to a less capable model. Claude's free tier provides approximately 5-10 messages per session with variable limits based on server load. Neither free tier includes advanced features like extended context, file analysis, or model selection. For occasional testing and evaluation, free access works well. For regular professional use, the limitations typically necessitate paid access or alternative methods like academic programs or development credits.
Q3: Which has better context window on free tier?
Claude's free tier provides a larger context window of approximately 32,000 tokens compared to GPT-5.2's 16,000 tokens on free. This means Claude can maintain context across longer conversations and process more extensive documents without losing earlier information. However, this advantage disappears when comparing paid tiers, where GPT-5.2 Plus offers 128,000 tokens and GPT-5.2's API provides 400,000 tokens—double Claude Opus 4.5's 200,000 token maximum. If you're staying on free tier and need to handle longer documents or extended conversations, Claude provides better context retention.
Q4: Is the paid subscription worth upgrading?
The $20/month subscription for either ChatGPT Plus or Claude Pro typically pays for itself if you use AI daily for professional work. The value comes from eliminated message limits, larger context windows, priority access during peak hours, and advanced features like file analysis and model selection. For a professional using AI 3+ hours daily, the productivity gains easily exceed the subscription cost. For casual users who interact with AI a few times weekly, free tiers likely provide sufficient access. The decision point is typically around weekly usage—if you're consistently hitting free tier limits or needing features that free lacks, upgrading makes economic sense.
Q5: Which is faster on free tier?
GPT-5.2 generally responds faster on free tier, particularly for simpler queries. OpenAI's infrastructure investments and the GPT-5.2 Instant variant prioritize response speed for straightforward requests. Claude Opus 4.5's extended thinking capabilities, while producing higher-quality outputs for complex problems, inherently take longer to process. However, both free tiers experience variable response times based on server load, with peak hours producing notably slower responses regardless of underlying model speed. Free users also face queue delays that paid users skip, making the practical experience more dependent on when you're using the service than on inherent model speed differences.
Conclusion
The competition between GPT-5.2 and Claude Opus 4.5 has produced two genuinely excellent options with distinct strengths that serve different user needs. GPT-5.2 dominates in mathematical precision, abstract reasoning, and large-context processing—making it the clear choice for quantitative work, complex analysis, and tasks requiring extensive information synthesis. Claude Opus 4.5 leads in software engineering, particularly terminal operations and debugging, while offering the safety and consistency that enterprise environments often require.
Free access to both models exists and provides meaningful capabilities for evaluation and light usage. GPT-5.2's 10 messages per 5-hour window and Claude's variable session limits enable genuine testing without financial commitment. For serious or professional work, these limitations typically prove insufficient, but they serve their purpose for users determining which model better fits their needs before subscribing.
The pricing structures favor different use cases. GPT-5.2 Thinking offers the best cost-efficiency for general usage, while Claude's prompt caching provides dramatic savings for applications with repetitive prompts. Developers needing both models can simplify access through API aggregation platforms like laozhang.ai, which provide unified endpoints for multiple models with competitive pricing—particularly valuable for comparing outputs or building applications that benefit from model diversity.
Rather than declaring a single winner, the practical recommendation is to match model selection to task requirements. Use GPT-5.2 for math, reasoning, and large-context work. Use Claude Opus 4.5 for coding, especially terminal operations. When in doubt, testing both on your actual use case provides better guidance than any benchmark comparison could offer.