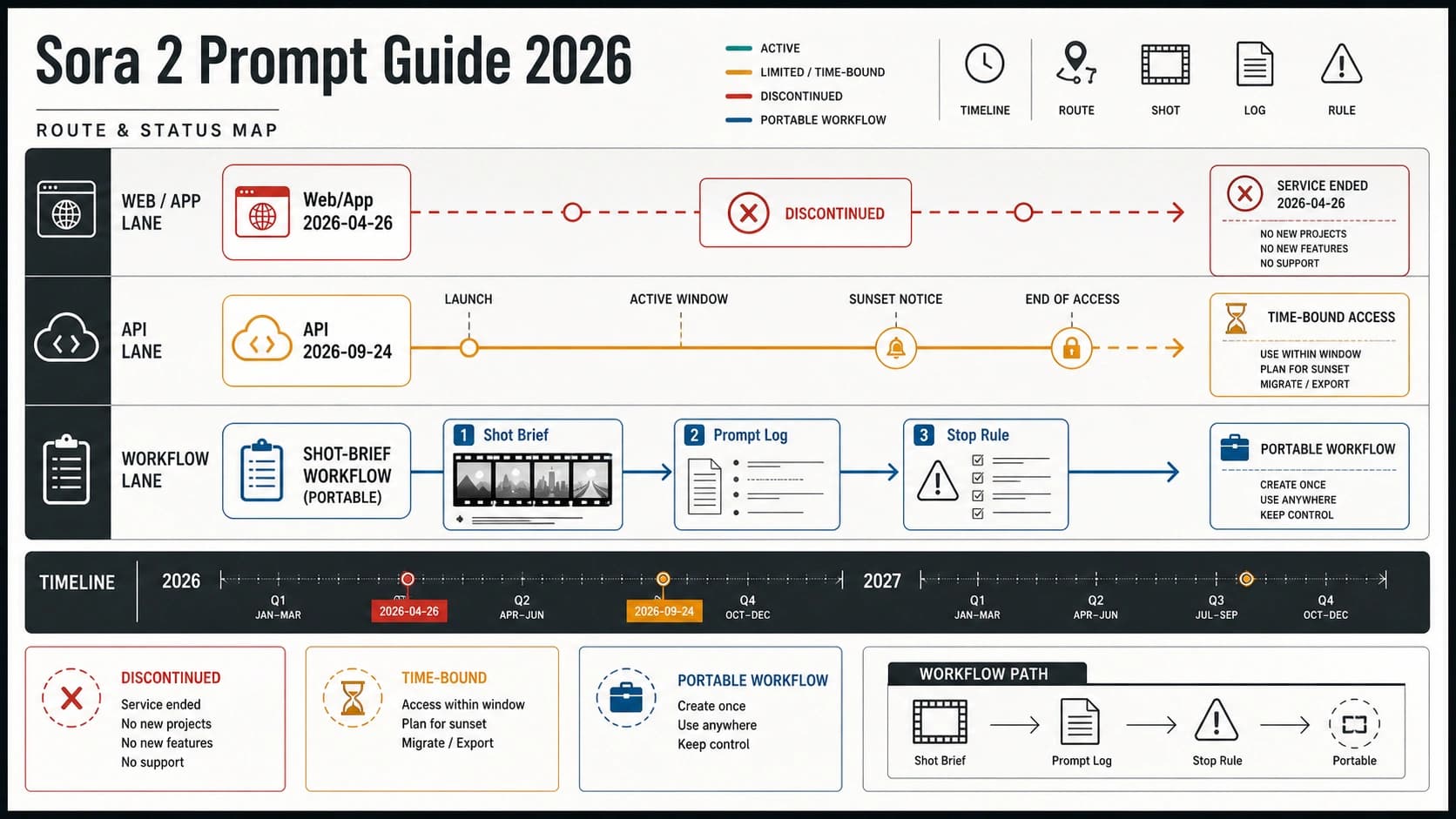
现在要接入 Grok,先把问题拆成路线,而不是先比较版本号。普通文本、迁移旧模型、结构化抽取、客服自动化和 RAG 回答,优先从 Grok 4.3 开始;只有当任务明确需要 4.20 的推理分支、非推理分支、2M 上下文、provider 别名或多智能体协作时,再把 Grok 4.20 放进评估。Grok Imagine 和 Grok Voice 属于图像/视频与语音接口家族,不是 Grok 4.3 或 4.20 的模式开关。
| 路线 | 适用场景 | 必须核对 | 主要风险 |
|---|---|---|---|
| Grok 4.3 | 新建或迁移文本 API,默认先测它 | xAI 模型页、别名、reasoning effort、上下文、价格 | 价格、上下文和可用性都必须按日期复核 |
| Grok 4.20 reasoning / non-reasoning | 需要 2M 上下文、深推理、低延迟直答或 provider 已选定 4.20 | xAI 或 provider 的模型 ID 与模式说明 | 不能把每个 4.20 标签当成 4.3 的统一替代 |
| Grok 4.20 multi-agent | 任务有并行研究、工具调用、复杂代码或多路径判断 | Responses API、多智能体数量、工具和计费 | 主智能体、子智能体和工具调用都会改变成本面 |
| Grok Imagine | 图像生成、视频生成、批量媒体产出 | imagine image/video 模型、端点、质量、时长、分辨率 | 它是媒体路线,不是文本模型升级 |
| Grok Voice | 实时语音、TTS、STT、自定义声音或语音代理 | realtime、TTS、STT、Voice Agent、Custom Voices 文档 | 语音有独立端点、延迟和价格面 |
| Provider 接入 | 已经在 Vercel、Oracle、OpenRouter 等网关内交付 | provider 模型名、区域、限额、价格、数据策略 | provider 能证明自己的路线,不能自动证明 xAI 一方可用 |
停止线:还没确认路线归属、端点家族、计费面、生命周期和回滚方案之前,不要直接把配置切到多智能体或 provider 别名。图像/视频需求直接核对 Imagine;语音需求直接核对 Voice;文本需求才回到 Grok 4.3 与 4.20 的选择。
中文团队尤其要避免把“海外文档里的模型名”“provider 控制台里的别名”和“社交媒体里的版本号讨论”混成同一条采购结论。更稳妥的做法是先写一张内部路线卡:谁是合同所有者,哪个端点接收请求,是否需要 reasoning effort,是否走 Responses API,是否产生临时媒体文件,是否有语音会话状态,以及上线前由谁复核价格和限额。这样讨论 Grok 4.3、Grok 4.20、Imagine 和 Voice 时,团队对齐的是交付边界,而不是单纯追一个看起来更新的名称。
先选路线,再看版本号
Grok 相关名称现在同时覆盖五类合同:xAI 一方文本模型、4.20 的专门分支、多智能体编排、图像/视频生成、语音实时接口,以及 provider 打包后的模型名。如果把它们排成一个简单版本梯子,最容易犯的错就是看见 4.20、multi-agent、Imagine 或 Voice 就以为都能替代同一个聊天模型。实际落地时,第一步应该是判断任务所有者:文本模型、媒体接口、语音接口、provider 网关,还是多智能体工作流。
2026年5月8日核对的 xAI 文档中,Grok 4.3 模型页列出 Grok 4.3、grok-4.3-latest 和 grok-latest 等名称,并支持 none、low、medium、high 等 reasoning effort 设置。xAI 的 5月15日退休迁移说明也把多个旧 Grok 4、Grok 3、reasoning、non-reasoning 和 coding 模型的替代路线指向 Grok 4.3。对大多数新项目或迁移项目,这已经足够说明 Grok 4.3 应该先进入测试,而不是先追逐更复杂的 4.20 分支。

Grok 4.20 仍然有位置,但它的位置是专门路线,而不是全局默认。xAI 的 Grok 4.20 reasoning 页面写明 2M 上下文和 reasoning 能力;Vercel、Oracle 等 provider 也会展示 4.20 的 reasoning、non-reasoning 或 multi-agent 变体。这些证据说明 4.20 不是不存在,而是必须先问清楚:你的应用是否真的需要这条路线,还是只是被一个更醒目的名字带偏。
Grok 4.3 什么时候应该先测
只要任务是普通文本 API 集成,Grok 4.3 就是更干净的起点。客服问答、摘要、分类、信息抽取、RAG 回答、文案辅助、工作流自动化、旧模型迁移,都更需要一个当前一方文档清楚、reasoning effort 可控、迁移方向明确的文本合同。先测 Grok 4.3 能减少模型别名、provider 差异和 beta 生命周期带来的额外变量。
一个合格的 Grok 4.3 测试不需要复杂。选定 Grok 4.3 或 grok-4.3-latest,把 reasoning effort 写进请求,使用同一组业务 prompt 跑延迟、可接受输出率、token 用量、拒答行为、错误处理和回滚路径。如果任务没有用到超长上下文、并行研究、媒体生成或语音互动,这组小测试通常比对比所有可见 Grok 名称更快得出答案。
非推理任务也不一定要换模型家族。迁移说明把一些 non-reasoning 工作负载指向 Grok 4.3,并通过 reasoning effort 关闭推理开销。分类、格式转换、轻量总结、固定模板回复等场景,可以先用 Grok 4.3 加 none 推理设置来测。只有当你的部署路线已经由 provider 拥有,并且 provider 明确提供 4.20 non-reasoning 模型时,才需要把那条路线作为单独选择。
价格和上下文要贴着来源使用。2026年5月8日核对时,Grok 4.3 页列出了 1M 上下文和输入/输出 token 价格;这些数字可以作为预算评估依据,但不应该写成长期承诺。生产上线前重新打开 xAI 模型页、Console、限额和状态信息,因为地域、账号、速率限制和可用性都可能改变。
Grok 4.20 什么时候仍然值得保留
Grok 4.20 应该留在决策表中,但只在任务确实需要它时。典型情况包括:需要 2M 上下文做长文分析,需要 reasoning 分支处理复杂逻辑,需要 provider 内已经暴露的 4.20 non-reasoning 直答路线,或者需要已经验证过的 beta 能力。这里的关键不是“4.20 是否更大”,而是“4.20 是否是这次任务的合同所有者”。
Reasoning 分支适合复杂推理、长链分析、研究型回答和代码判断。Oracle 的 OCI 文档把 reasoning 与 non-reasoning 拆成两个模型,并把 reasoning 放在复杂分析场景里。这对 OCI 用户有用,但它首先证明的是 OCI 路线,不等于每个 xAI 一方账号都有同样的可用性、模型名和生命周期。
Non-reasoning 分支更窄。Vercel AI Gateway 页面把 Grok 4.20 Non-Reasoning 描述成 beta 的速度/直答路线,并使用 provider 自己的模型字符串。对已经采用 Vercel AI SDK 或 AI Gateway 的项目,这可能正好减少集成摩擦;对还没有选定 provider 的一方 xAI 项目,它不能替代 Grok 4.3 加 none 推理设置的基础测试。
| 需求 | 更稳妥的首测路线 | 只有在何时升级 |
|---|---|---|
| 当前一方文本 API | Grok 4.3 | Grok 4.3 未通过业务验收 |
| 低延迟直答 | Grok 4.3 关闭推理 | provider 已经拥有并文档化 4.20 non-reasoning |
| 超长上下文分析 | Grok 4.20 reasoning | 真实使用了额外上下文并测过召回质量 |
| 网关交付 | provider 模型 ID | provider 的价格、限额、区域和数据策略可接受 |
衡量标准必须是业务任务。2M 上下文不是完美召回的保证;non-reasoning 标签也不自动意味着最低成本;beta 名称更不等于长期生产默认。把同一组请求跑完,再根据可接受答案率、成本、延迟和回滚难度选择。
多智能体是工作负载选择,不是默认升级
Grok 4.20 multi-agent 最容易被过度使用。xAI 的多智能体文档把它定义为 beta 路线,使用多个智能体、内置工具、默认输出 leader 结果,并支持 4-agent 或 16-agent 配置。这对研究、复杂代码、广泛信息收集和工具密集推理有意义;对常规客服、轻量抽取、短回答和固定模板,它通常只会增加验证和成本。

多智能体真正要证明的是总失败成本下降。文档说明 leader、sub-agent token 和服务端工具调用都会计费,所以问题不是“智能体更多是不是更强”,而是“额外智能体是否让错误率、人工复核时间或研究遗漏明显下降”。一个多智能体研究任务如果节省工程师数小时,成本可以接受;把 16-agent 用在简单 FAQ 改写上,就是把复杂度转成账单。
| 条件 | 为什么重要 |
|---|---|
| 任务天然可拆成并行子问题 | 多个智能体才有独立工作可做 |
| 工具调用或实时研究会改变结论 | 否则单模型回答更简单 |
| 结果有复核或验收流程 | 生成内容越多,验证越重要 |
| 预算能覆盖 leader、sub-agent 和工具 | 成本面不再等于一次普通 completion |
还要检查 API 形状。多智能体属于 Responses API 路线,不一定能直接塞进旧的 chat completions wrapper。监控、日志、重试、成本归因、响应解析和 provider 兼容性都要重测。把它当作“模型字符串替换”通常会在上线后暴露问题。
Imagine 和 Voice 是独立能力路线
Grok Imagine 不是 Grok 4.3 的图像模式。它是图像和视频生成路线,涉及 grok-imagine-image、grok-imagine-video、图像/视频端点、异步轮询、临时媒体链接、质量、时长、分辨率和价格面。2026年5月8日核对的 xAI 图像文档还提示 grok-imagine-image-pro 计划在 2026年5月15日退役,并建议新请求使用质量路线。这个信息只能作为带日期的迁移提醒,不能写成永远有效的产品承诺。

视频同样属于 Imagine 家族,但实现方式不同。grok-imagine-video 使用异步生成和轮询,输出临时视频 URL,并有时长、分辨率和输入媒体的计费边界。只要需求是生成媒体,就不应该再纠结 Grok 4.3 与 4.20 哪个更“聪明”;应该直接验证媒体端点、质量、时长、分辨率、内容政策、成本和资源保存方式。
Grok Voice 又是另一条路线。Voice 文档覆盖 Voice Agent API、Text to Speech、Speech to Text 和 Custom Voices,实时语音使用不同请求形状和延迟预算。如果产品要做语音代理、实时对话、转录、语音播报或自定义声音,选择问题就是音频端点、时延、会话状态、计费和安全边界,而不是文本模型排行榜。
中文读者还容易把开发者 API 选择和消费端 Grok Imagine 问题混在一起。成人模式可见性、NSFW 边界、免费替代工具、高需求报错,都有不同的处理路线。本文的边界是开发者模型和 API 路由:选择文本、多智能体、媒体、语音或 provider,而不是教消费端绕过功能限制。
Provider 可以有用,但不能替代一方事实
Vercel、Oracle、OpenRouter 等 provider 很有价值,因为它们能把 Grok 模型放进已有 SDK、网关、日志、计费和部署体系里。它们也能解释某个 provider 如何包装 reasoning、non-reasoning 或 multi-agent 变体。但是 provider 页面证明的是 provider 路线:它的模型名、价格、区域、限额、生命周期和 SDK 支持,不自动证明 xAI Console、xAI API 或另一个网关拥有同样条件。
| Provider 能证明 | Provider 不能证明 |
|---|---|
| 它自己暴露某个模型或别名 | xAI 一方对所有账号开放同名路线 |
| 它当前的价格、网关 ID、区域和 SDK | xAI 一方长期价格、生命周期或上下文 |
| 它自己的日志、重试、监控和账单行为 | 其他 provider 或 xAI Console 的特性一致 |
| 现有技术栈内的快速测试路径 | beta 名称可以长期作为生产默认 |
Oracle 文档把 Grok 4.20 的 reasoning 与 non-reasoning 分开,并把 multi-agent 标成 API-only;Vercel AI Gateway 提供自己的模型字符串和 SDK 路线。这些信息都可以引用,但必须把 provider 名字跟在 claim 旁边。复制 provider 的价格或模型名到 xAI 一方配置里,是最常见的错误。
生产检查可以很短:谁拥有路线,模型或端点字符串是什么,价格和限额由谁定义,数据策略和区域在哪里,生命周期说明是否有日期,回滚模型是什么,状态页和账号可用性如何验证。任何一个答案来自 provider,就把 provider 名称保留下来。
当前 Grok 集成检查表
改配置前先写一行路线决策。它能阻止团队把 Grok 4.3、Grok 4.20、Imagine、Voice 和 provider 名称混成一个大开关。
| 检查项 | 通过标准 |
|---|---|
| 工作负载归属 | 明确是文本、多智能体、图像/视频、语音或 provider |
| 模型或端点 | 使用 Grok 4.3、文档化 4.20 变体、Imagine、Voice 或 provider 别名 |
| 生命周期风险 | 旧文本模型和 Imagine 退役信息按当前文档复核 |
| 推理设置 | 非推理工作有明确 setting 或 provider 路线 |
| 成本面 | token、子智能体、工具、图像、视频、语音或 provider 账单分别归属 |
| 可用性证据 | xAI 文档、Console、状态页或 provider 文档对应具体 claim |
| 回滚 | 旧模型、验收样例、阈值和回滚步骤已记录 |
状态页只能当作时间戳健康信号。xAI Status 可以提示 API、Console、Docs、Grok Web、X 内 Grok、iOS 和 Android 组件是否有事件,但绿色状态不等于你的账号必然有权限。遇到高需求横幅、账号识别或消费端入口问题,应进入专门的故障排查分支,而不是继续改模型名。
常见问题
Grok 4.3 比 Grok 4.20 新吗?
对大多数当前一方文本 API 工作,Grok 4.3 是 xAI 当前模型页和迁移说明指向的首选路线。Grok 4.20 仍存在于 reasoning、non-reasoning、2M 上下文、provider 和多智能体分支中,所以正确答案是按路线判断,不是按数字排序。
Grok 4.3 会完全替代 Grok 4.20 吗?
不会完全替代。Grok 4.3 能覆盖很多新建和迁移文本任务,但 4.20 的推理、非推理、超长上下文、provider 和多智能体分支仍可能是特定任务的所有者。只有验收测试证明需要时才保留 4.20。
新 Grok API 项目应该先用哪个模型?
先用 Grok 4.3,并明确设置 reasoning effort。除非产品需求已经是多智能体研究、图像/视频生成、实时语音或 provider 路线,否则先把基础文本任务跑通,再评估专门分支。
Grok 4.20 multi-agent 什么时候值得用?
当任务能拆成并行子问题、工具调用会改变答案、输出有复核流程、预算能覆盖 leader、子智能体和工具调用时,才值得用多智能体。常规聊天、短问答和简单抽取不应该默认使用。
Grok Imagine 是 Grok 4.3 的一部分吗?
不是。Grok Imagine 是图像和视频生成路线,有自己的模型、端点、质量、时长、分辨率和媒体资产行为。媒体需求直接核对 Imagine 文档,不要把它当成文本模型的开关。
Grok Voice 是文本模型吗?
不是。Grok Voice 是音频能力家族,覆盖实时语音代理、TTS、STT 和自定义声音。语音产品要看实时端点、延迟、会话、价格和音频安全边界。
可以相信 Vercel、Oracle 或 OpenRouter 的 Grok 名称吗?
可以相信它们对自己路线的说明。provider 页面能证明该 provider 的模型别名、价格、SDK 路径或可用性,不能自动证明 xAI 一方或其他 provider 拥有相同条件。
上线前最该复核什么?
复核 xAI 模型文档、Console 权限、迁移说明、Imagine 与 Voice 文档、provider 模型页、价格、速率限制、状态页和账号可用性。所有易变事实都要跟来源和日期绑定。