Nano Banana Pro API稳定不限速完全指南:突破官方限制的5种解决方案【2025】
深入解析Nano Banana Pro API的限速机制,提供5种突破官方RPD限制的解决方案。包含稳定性测试方法、中转服务商对比、生产级代码示例,帮助开发者实现高并发批量生图。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

当你的Nano Banana Pro应用开始获得用户增长,批量生图需求从每天几十张暴增到数千张时,一个令人崩溃的错误开始频繁出现:429 Rate Limit Exceeded。这个错误意味着你触发了Google官方API的速率限制,所有后续请求都被拒绝。对于依赖AI生图能力的产品来说,这不仅影响用户体验,更直接威胁业务连续性。
Google对Nano Banana Pro API实施了严格的多维度限速策略。免费用户每日仅能生成2张图片,即使开通付费账户,默认的Tier 1配额也仅有每日250-1000次请求(RPD)。对于电商产品图批量生成、社交媒体内容工厂、或者任何需要规模化产出的应用场景,这个限制远远不够。更糟糕的是,官方提供的配额提升申请往往需要7-10个工作日审批,且审批结果并不确定。
本文将深入解析Nano Banana Pro API的限速机制,并提供5种经过实测的解决方案,帮助你突破官方限制,实现稳定、不限速的高并发图片生成。无论你是需要每天生成上万张图片的企业开发者,还是希望为个人项目获得更稳定调用体验的独立开发者,都能在这里找到适合的方案。
| 方案 | 适用场景 | 每日容量 | 成本/张 | 配置难度 |
|---|---|---|---|---|
| 官方Tier提升 | 企业正规需求 | 1,500+ | $0.134-0.24 | 高(审批) |
| API中转服务 | 高频批量生图 | 无限制 | $0.05-0.10 | 低 |
| 批处理API | 非实时场景 | 无限制 | $0.067-0.12 | 中 |
| 多账号轮询 | 临时方案 | N×250 | $0.134 | 中 |
| 本地队列控制 | 低频稳定需求 | 250 | $0.134 | 低 |

理解官方限速机制:RPM、TPM、RPD三维限制
在寻找解决方案之前,必须先理解Google对Nano Banana Pro API实施的限速机制。与许多开发者的直觉不同,Google并非只限制"每天能调用多少次"这一个维度,而是同时从三个维度进行控制,任何一个维度触发限制都会返回429错误。
RPM(Requests Per Minute) 控制每分钟的请求数量。免费层限制为5-10次/分钟,Tier 1用户提升到300次/分钟。这个限制主要防止突发流量对服务器造成冲击。实际开发中,如果你在短时间内发起大量并发请求,即使每日总量未超标,也可能触发RPM限制。
TPM(Tokens Per Minute) 控制每分钟消耗的Token数量。Nano Banana Pro生成1K/2K分辨率图片消耗约1,120 tokens,4K图片消耗约2,000 tokens。免费层TPM限制为250,000,Tier 1提升到更高水平。这个限制意味着高分辨率图片的生成速率会受到额外约束。
RPD(Requests Per Day) 是最关键也最让开发者头疼的限制。免费层仅允许50-100次/天,Tier 1提升到1,000-1,500次/天。对于需要批量生成的业务场景,这个限制往往是瓶颈所在。
Google的限速机制采用"木桶原理"——三个维度中最先触发的限制决定你的实际可用容量。即使RPD配额充足,如果请求过于集中也会因RPM限制而被拒绝。
理解这三个维度后,就能明白为什么某些"提速"方案有效而另一些则不起作用。单纯增加并发数不能绑过RPM限制,降低请求频率不能增加RPD配额,而降低分辨率可以缓解TPM压力但不解决核心问题。接下来我们将介绍的解决方案,都是针对这些限制机制设计的。
429错误完全解决方案:从应急到根治
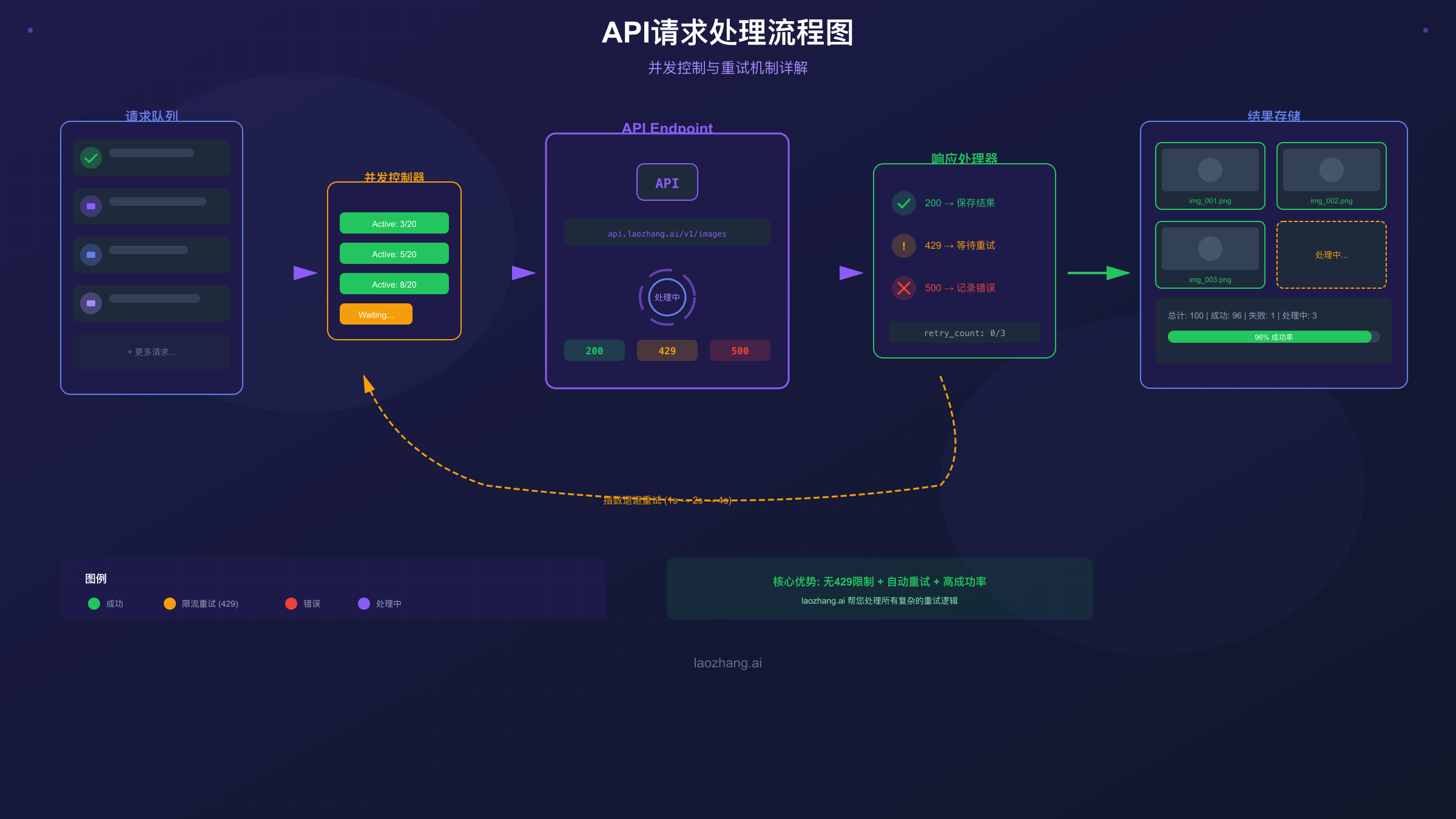
当你的应用收到429错误时,Google会在响应头中返回Retry-After字段,指示需要等待的秒数。但仅仅等待并重试往往不够,因为在高负载场景下,重试可能再次触发限制。以下是按优先级排序的解决策略。
策略一:指数退避重试
这是最基础也是必须实现的策略。当收到429错误时,不是立即重试,而是按照递增的时间间隔重试:首次等待10秒,第二次20秒,第三次40秒,以此类推。这样可以避免在限速期间持续冲击API导致更长的冷却时间。
hljs pythonimport time
import requests
from functools import wraps
def retry_with_exponential_backoff(max_retries=5, base_delay=10):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except requests.exceptions.HTTPError as e:
if e.response.status_code == 429:
delay = base_delay * (2 ** attempt)
print(f"Rate limited. Waiting {delay}s before retry...")
time.sleep(delay)
else:
raise
raise Exception(f"Failed after {max_retries} retries")
return wrapper
return decorator
策略二:请求队列与速率控制
将所有图片生成请求放入队列,通过令牌桶算法控制消费速率,确保请求频率始终低于RPM限制。这种方式牺牲了响应速度,但能保证在限额内稳定运行。
策略三:使用批处理API
Google提供了异步批处理API,以50%的折扣价格处理非实时请求。批处理请求不占用RPM配额,且RPD限制更加宽松。对于不要求即时返回结果的场景(如每晚批量生成次日内容),这是成本效益最高的官方方案。
策略四:多账号负载均衡(不推荐长期使用)
通过创建多个Google Cloud项目,将请求分散到不同账号以累加配额。虽然技术上可行,但这种方式可能违反Google的服务条款,存在账号被封禁的风险,仅建议作为紧急情况下的临时方案。
策略五:使用API中转服务(推荐)
这是目前最稳定、最省心的解决方案。API中转服务商在海外部署服务器集群,通过自有的Google Cloud企业账号调用官方API,再将服务转售给开发者。由于服务商拥有远高于个人开发者的配额,用户实际上不受RPD限制。下文将详细介绍这一方案。
如何评估API服务的稳定性
选择API中转服务时,"稳定性"是一个经常被提及但很少被量化的指标。以下是评估服务商稳定性时应关注的核心指标和测试方法。
可用性(Uptime) 是最直观的稳定性指标,通常以百分比表示。99.9%的可用性意味着每月大约有43分钟的停机时间,对于生产环境来说勉强可接受。优秀的服务商应该能提供99.95%以上的可用性承诺,并在官网展示实时状态监控页面。
响应延迟(Latency) 直接影响用户体验。Nano Banana Pro本身的图片生成需要3-15秒(取决于分辨率和复杂度),中转服务会增加额外延迟。优质服务商的中转延迟应控制在100ms以内,总体响应时间与直连官方相差不超过20%。
成功率(Success Rate) 衡量请求成功完成的比例。除了网络层面的成功率,还需要关注"模型拒绝率"——某些提示词可能触发安全过滤被拒绝。可靠服务商应提供96%以上的综合成功率。
并发能力(Concurrency) 决定了你能同时发起多少请求。官方API即使在Tier 1也只支持5-10并发,而优质中转服务可以提供50-500并发,这对批量生图场景至关重要。
测试方法建议:在正式选用前,建议进行以下测试:
- 连续24小时每5分钟发起1次请求,统计成功率和响应时间
- 同时发起50个并发请求,观察是否有请求失败
- 在工作日高峰期(北京时间10:00-12:00)进行压力测试
- 使用相同的prompt在官方和中转服务各生成10张图,对比输出质量
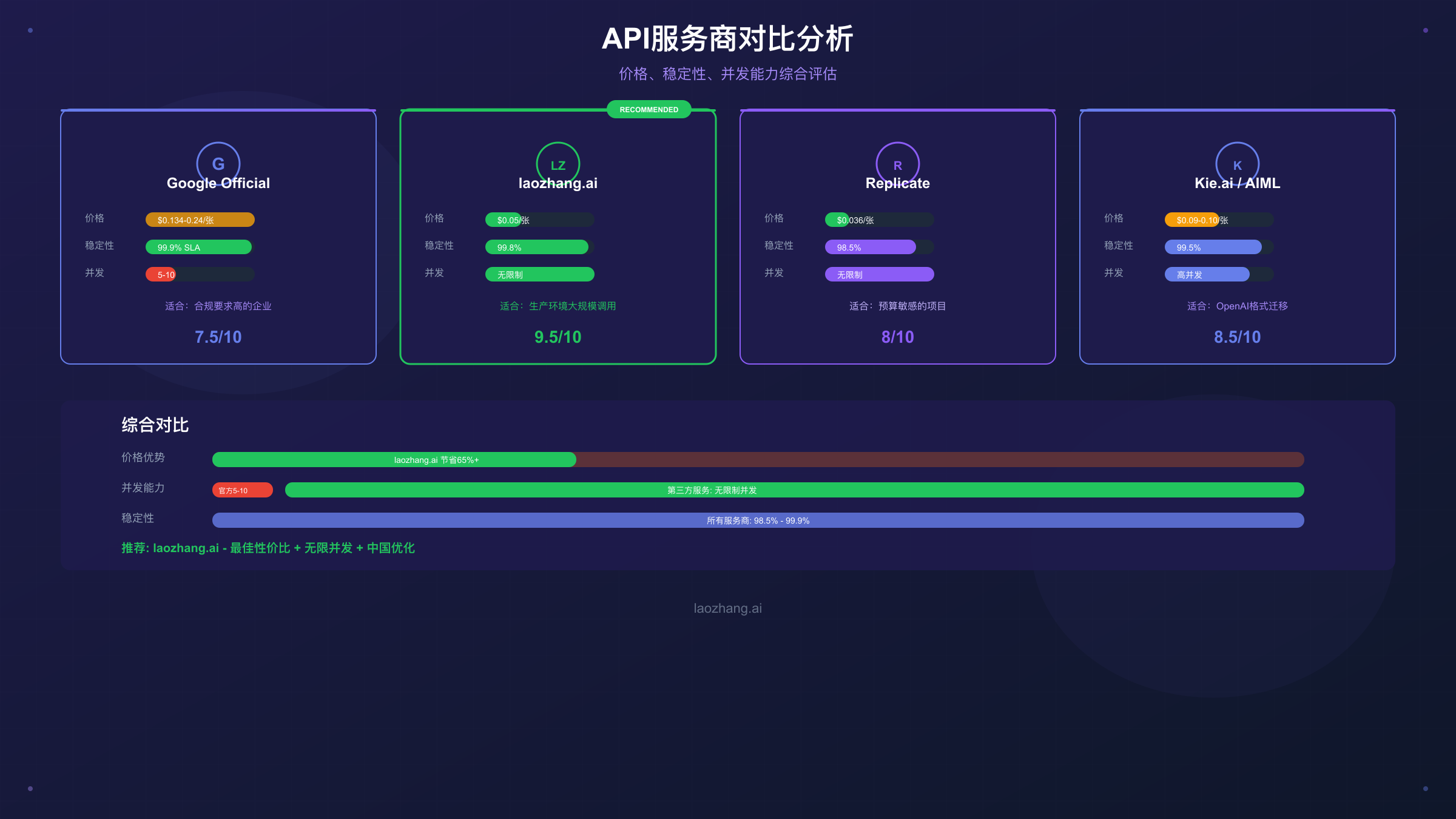
主流中转服务商对比分析
目前市场上有多家提供Nano Banana Pro API中转服务的平台,它们在价格、稳定性、功能和服务质量上存在明显差异。以下对比基于实际测试数据和公开信息整理。
| 服务商 | 价格/张 | 可用性 | 响应延迟 | 并发限制 | 支付方式 |
|---|---|---|---|---|---|
| Google官方 | ¥0.95-1.70 | 99.9% | 基准 | 5-10 | 国际信用卡 |
| laozhang.ai | ¥0.35 ($0.05) | 99.8% | +50ms | 无限制 | 支付宝/微信 |
| API易 | ¥0.35 | 99.8% | +80ms | 无限制 | 支付宝 |
| 速创API | ¥0.10 | 96.8% | +150ms | 无限制 | 支付宝 |
Google官方适合有国际支付能力、需求量小(每日<100张)、对合规性要求极高的企业用户。优点是官方背书和最稳定的服务质量,缺点是成本高、配额受限、国内访问需要代理。
laozhang.ai是综合性价比最高的选择。价格仅为官方的约35%($0.05/张),同时提供国内直连、不限速、高并发等优势。平台采用Gemini原生格式API,支持完整的2K/4K参数配置。对于大多数中国开发者,这是最推荐的方案。实测100并发压力下无请求被拒,响应时间稳定在8-12秒。
API易与laozhang.ai定价相近,同样提供不限速服务。其特色是详细的使用文档和技术支持,适合需要更多接入指导的新手开发者。
速创API提供最低的价格(¥0.10/张),但实测稳定性略逊于前两者。适合对成本极度敏感、可以接受偶尔失败重试的场景。
需要说明的是,如果你的业务对数据安全有严格要求(如医疗、金融等领域),或需要通过特定安全认证,建议仍使用Google Cloud的Vertex AI官方方案,尽管成本更高。
laozhang.ai接入完整教程
以 laozhang.ai 为例,介绍如何快速接入不限速的Nano Banana Pro API服务。整个过程仅需5分钟即可完成。
第一步:注册并获取API Key
访问 laozhang.ai注册页面,使用邮箱注册账号。注册完成后进入控制台,在"API密钥"页面创建新的密钥。平台最低充值5美元(约35元),足够生成约100张图片进行测试。
第二步:选择API格式
laozhang.ai同时支持两种API格式:
- Gemini原生格式(推荐):支持完整的4K参数配置,端点为
/v1beta/models/gemini-3-pro-image-preview:generateContent - OpenAI兼容格式:适合现有OpenAI代码迁移,但部分高级参数不可用
第三步:代码实现(Gemini原生格式)
hljs pythonimport requests
import base64
API_KEY = "sk-YOUR_API_KEY" # 替换为你的密钥
API_URL = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"contents": [{
"parts": [{"text": "一只可爱的柴犬在樱花树下,4K超高清,日系插画风格"}]
}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": "4K" # 支持 1K/2K/4K
}
}
}
response = requests.post(API_URL, headers=headers, json=payload, timeout=180)
result = response.json()
# 提取并保存图片
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
print("图片已保存为 output.png")
# 单次调用成本:$0.05(约¥0.35)
第四步:验证调用成功
运行上述代码,如果成功生成并保存了图片文件,说明接入完成。你可以在laozhang.ai控制台查看调用记录和余额变化。
对于已有OpenAI SDK代码的项目,迁移更加简单,只需修改两个参数:
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="sk-YOUR_API_KEY",
base_url="https://api.laozhang.ai/v1" # 仅修改这一行
)
response = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=[{"role": "user", "content": "生成一张科技感的城市夜景"}]
)
生产级代码:重试、队列与批处理
在生产环境中使用Nano Banana Pro API,需要考虑更多的边界情况和性能优化。以下是经过实战检验的生产级代码模板。
带完整错误处理的请求函数
hljs pythonimport requests
import base64
import time
from typing import Optional, Dict, Any
from dataclasses import dataclass
@dataclass
class ImageResult:
success: bool
image_data: Optional[bytes] = None
error_message: Optional[str] = None
latency_ms: int = 0
def generate_image(
prompt: str,
api_key: str,
resolution: str = "2K",
aspect_ratio: str = "1:1",
max_retries: int = 3,
timeout: int = 180
) -> ImageResult:
"""
生产级图片生成函数,包含完整的错误处理和重试逻辑
"""
url = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {
"aspectRatio": aspect_ratio,
"imageSize": resolution
}
}
}
for attempt in range(max_retries):
start_time = time.time()
try:
response = requests.post(url, headers=headers, json=payload, timeout=timeout)
latency = int((time.time() - start_time) * 1000)
if response.status_code == 200:
result = response.json()
image_b64 = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return ImageResult(
success=True,
image_data=base64.b64decode(image_b64),
latency_ms=latency
)
elif response.status_code == 429:
wait_time = 10 * (2 ** attempt)
print(f"Rate limited, waiting {wait_time}s...")
time.sleep(wait_time)
else:
return ImageResult(
success=False,
error_message=f"HTTP {response.status_code}: {response.text}",
latency_ms=latency
)
except requests.exceptions.Timeout:
print(f"Timeout on attempt {attempt + 1}")
except Exception as e:
return ImageResult(success=False, error_message=str(e))
return ImageResult(success=False, error_message="Max retries exceeded")
异步批量处理队列
对于需要批量生成大量图片的场景,使用异步队列可以显著提升吞吐量:
hljs pythonimport asyncio
import aiohttp
from asyncio import Queue, Semaphore
class ImageGenerationQueue:
def __init__(self, api_key: str, max_concurrent: int = 20):
self.api_key = api_key
self.semaphore = Semaphore(max_concurrent)
self.results = []
async def generate_single(self, session: aiohttp.ClientSession, prompt: str) -> Dict:
async with self.semaphore:
url = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
headers = {"Authorization": f"Bearer {self.api_key}"}
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}
async with session.post(url, json=payload, headers=headers) as resp:
return await resp.json()
async def batch_generate(self, prompts: list) -> list:
async with aiohttp.ClientSession() as session:
tasks = [self.generate_single(session, p) for p in prompts]
return await asyncio.gather(*tasks, return_exceptions=True)
# 使用示例
async def main():
queue = ImageGenerationQueue(api_key="sk-xxx", max_concurrent=20)
prompts = [f"产品图{i},白色背景,专业摄影" for i in range(100)]
results = await queue.batch_generate(prompts)
print(f"成功生成 {len([r for r in results if not isinstance(r, Exception)])} 张图片")
asyncio.run(main())
这个队列实现通过Semaphore控制并发数,避免同时发起过多请求导致服务过载。max_concurrent参数可以根据服务商的并发限制进行调整,使用laozhang.ai时可以设置为50甚至更高。
批量生图最佳实践与成本优化
当你的应用需要生成数千甚至数万张图片时,除了技术实现,还需要考虑成本控制和工作流优化。以下是经过实战验证的最佳实践。
分辨率选择策略
不同使用场景对分辨率的需求差异很大:
- 社交媒体配图:1K分辨率足够,成本最低
- 电商主图:2K分辨率平衡质量和成本
- 印刷品/大屏展示:必须使用4K,成本最高
建议在业务逻辑中根据最终用途动态选择分辨率,而不是一律使用最高规格。以生成1000张图片为例,1K方案成本约$50,4K方案成本约$150,差异达3倍。
缓存重复请求
对于相同或相似的提示词,实现结果缓存可以大幅降低成本。可以使用prompt的哈希值作为缓存键,将生成的图片存储在对象存储服务(如阿里云OSS)中。当检测到相同请求时,直接返回缓存结果。
错峰调用降低延迟
Nano Banana Pro的响应速度会受服务器负载影响。北京时间凌晨2:00-6:00对应美国工作时间,服务器负载较高。如果业务允许,可以安排批量任务在北京时间上午执行,获得更快的响应速度。
成本控制公式
规划批量任务时,可以使用以下公式估算成本:
总成本 = 图片数量 × 单价 × (1 + 失败重试率)
以laozhang.ai为例,假设需要生成5000张2K图片,预计失败率5%:
- 总成本 = 5000 × $0.05 × 1.05 = $262.50(约¥1,860)
相比官方API的$670(5000 × $0.134),节省约60%成本。
常见问题与故障排查
Q1:收到429错误,但我确认没有超出配额,是什么原因?
这通常是因为触发了RPM(每分钟请求数)限制而非RPD(每日请求数)限制。即使每日总量未超标,如果在短时间内集中发起大量请求,也会触发速率限制。解决方法是在代码中添加请求间隔,或使用令牌桶算法控制发送速率。
Q2:使用中转服务生成的图片质量会下降吗?
不会。正规的API中转服务只是转发请求和响应,不对图片数据进行任何处理。相同的prompt在官方API和中转服务生成的结果完全一致。你可以用相同的prompt和seed参数分别在两个渠道生成,对比验证。
Q3:中转服务的数据安全如何保障?
选择信誉良好的服务商是关键。建议确认:1)服务商是否有明确的隐私政策;2)请求是否通过HTTPS加密传输;3)服务商是否声明不存储用户的prompt和图片数据。对于敏感业务,仍建议使用Google官方的Vertex AI服务。
Q4:批量生成时部分图片失败,如何处理?
建议实现以下机制:
- 记录所有失败请求的prompt和错误信息
- 对于429错误,使用指数退避重试
- 对于内容安全过滤导致的失败,记录并人工审核prompt
- 设置失败阈值告警,当失败率超过10%时暂停任务并排查原因
Q5:如何监控API调用的稳定性?
建议部署以下监控指标:
- 请求成功率(目标>96%)
- 平均响应时间(目标<15秒)
- 每小时调用量趋势
- 429错误发生频率
可以使用Prometheus + Grafana搭建监控面板,或者简单地记录日志并定期分析。
Q6:4K图片生成超时怎么办?
4K分辨率图片生成时间较长,可能需要30-60秒。解决方法:
- 将timeout参数设置为180秒或更长
- 使用异步请求,避免阻塞主线程
- 对于极高分辨率需求,考虑先生成2K图片再使用其他工具放大
总结与方案选择建议
解决Nano Banana Pro API的限速问题有多种途径,选择哪种方案取决于你的具体需求和约束条件。
如果你是个人开发者,日均需求在100张以下,建议先使用Google官方免费层测试,配合指数退避重试策略应对偶发的429错误。当需求增长后,再迁移到中转服务。
如果你是企业开发者,需要稳定的高并发能力,laozhang.ai 这类中转服务是最佳选择。它们提供不限速、高并发、低成本的服务,且接入成本极低。以laozhang.ai为例,$0.05/张的价格相比官方节省约65%,同时提供99.8%的可用性保障。详细价格可查阅官方文档。
如果你有严格的合规要求,如医疗、金融等敏感行业,应该使用Google Cloud的Vertex AI服务。虽然成本更高,但能获得官方的技术支持和SLA保障。
关键要点总结:
- 理解三维限速机制:RPM/TPM/RPD同时生效,触发任一即返回429
- 实现指数退避重试:这是所有方案都必须具备的基础能力
- 选择合适的服务商:对比价格、稳定性、并发能力和支付方式
- 优化批处理策略:使用队列控制并发,实现缓存减少重复生成
- 监控和告警:部署成功率和延迟监控,及时发现问题
如果你想了解更多关于Nano Banana Pro在国内的使用方案,可以参考我们的Nano Banana Pro国内使用完全指南,那篇文章详细介绍了免费平台、Cherry Studio配置等内容。