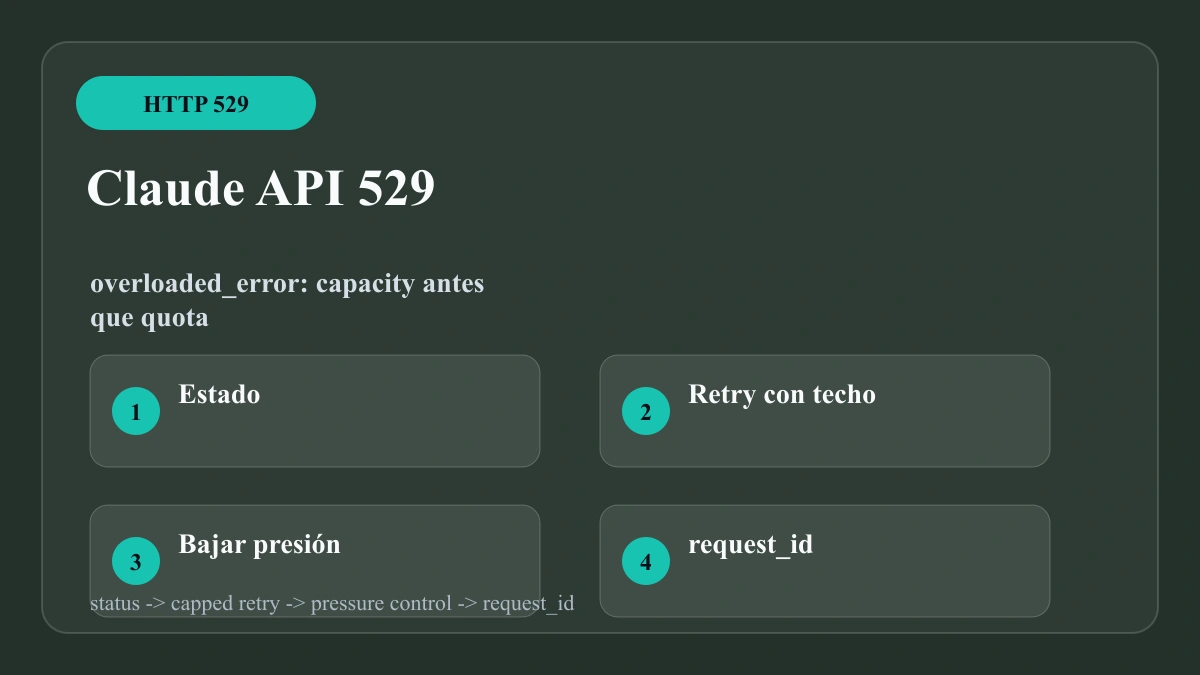
Si la API de Claude devuelve HTTP 529 con overloaded_error, trátalo primero como una rama de capacidad de Anthropic, no como un límite 429 de tu cuenta. Abre Claude Status, detén cualquier bucle de reintento inmediato, baja las llamadas paralelas y vuelve a intentar solo con exponential backoff limitado y jitter. Durante la prueba mantén estables endpoint, modelo, workspace, clave, proxy y biblioteca cliente; cambiar todo a la vez oculta el dueño del fallo.
| Señal de respuesta | Dueño probable | Primer movimiento | Cuándo parar |
|---|---|---|---|
HTTP 529 + overloaded_error | Capacidad de Anthropic | Revisar estado, retry lento, cola para trabajo nuevo | Al terminar el presupuesto de retry |
HTTP 429 + rate_limit_error | Límite de organización o workspace | Leer headers de límite | Hasta reset o cambio de límite |
| HTTP 500 o 504 | Error interno o timeout | Revisar estado y enviar solicitud pequeña | Escalar si se reproduce |
| Claude Code muestra repeated 529 | Claude Code ya reintentó automáticamente | Estado, espera, modelo alterno si procede | No asumir quota agotada |
La regla de reparación es estrecha: 529 puede reintentarse, pero despacio, con techo y con reducción de presión. Un loop inmediato, rotar claves o aplicar un playbook de 429 suele empeorar el diagnóstico.
529 es capacidad, no quota
La referencia de errores de Anthropic separa 529 de los límites de la organización. 429 corresponde a rate limit, 500 a error interno, 504 a timeout y 529 a sobrecarga temporal de la API. Por eso cambia el primer movimiento. Con 429 lees headers, reset y límites del workspace. Con 529 verificas estado del servicio, mantienes una ruta de solicitud estable, limitas los reintentos y pones trabajo nuevo en cola.
La página de estado no es solo verde o roja. A las 2026-04-30T13:42:00+08:00, el API público de Statuspage mostraba el componente Claude API como operational, pero también registraba incidentes el mismo día y el día anterior. En problemas de capacidad esto es normal: el componente general puede estar recuperado mientras un modelo, una ruta, un wrapper o una ventana corta siguen devolviendo 529.
No borres el síntoma demasiado pronto. Guarda response body, HTTP status, error type, request_id, modelo, endpoint, workspace, provider route y hora local. Si luego la solicitud pasa, ese registro muestra si ayudó esperar, bajar concurrency, reducir payload o cambiar ruta.
Primeros cinco minutos: fija la ruta
Empieza por evidencia. Copia body y headers, request id, modelo, endpoint, workspace, provider route, tamaño de entrada, concurrency y timestamp con zona horaria. Abre Claude Status y mira si Claude API, Claude Code o un modelo concreto tienen incidente. Si hay Zapier, Make, un proxy o un hosted agent entre tu app y Anthropic, registra esa capa por separado.
Luego envía una solicitud pequeña por la misma ruta. Mantén la misma API key, organización, modelo, endpoint y client library. Reduce el prompt y el límite de salida. Si la solicitud pequeña funciona pero el burst de producción falla, la reparación está en traffic shaping. Si la solicitud pequeña también devuelve 529, la evidencia apunta más a capacidad o presión de ruta.
Define un stop rule. En una solicitud de usuario, tres a cinco intentos con backoff y jitter suelen bastar. Un batch job puede esperar más, pero debe volver a una cola duradera, no ocupar un worker golpeando el mismo endpoint. Al terminar el presupuesto, devuelve un estado temporal de capacidad y conserva la evidencia.
Reintenta lento y con techo
529 es retryable solo en el sentido de que la misma solicitud puede funcionar cuando vuelva la capacidad. No significa que más intentos inmediatos produzcan éxito. La política debe distribuir carga, proteger workers y mantener claro el diagnóstico.
hljs tsfunction classifyClaude(status: number, type?: string) {
if (status === 529 || type === "overloaded_error") return "slow_retry";
if (status === 429 || type === "rate_limit_error") return "wait_for_limit";
if (status === 500 || status === 504) return "server_or_timeout";
return "do_not_retry_blindly";
}
El punto central es el ceiling. Una ruta interactiva puede intentar varias veces y devolver fallo temporal. Un worker de batch puede guardar next retry time y attempt count. Una interfaz streaming debe decir que la ruta del modelo está temporalmente sobrecargada, no quedarse congelada sin contexto.
No mezcles 529 con reparación de 429. La documentación de rate limits explica que 429 puede incluir retry-after y headers de límite. En 529, el reset de tu bucket no suele ser la señal principal; mandan tu backoff y el estado del servicio.
Baja presión sin romper el diagnóstico
Reducir presión sirve cuando preserva la comparación. Baja worker concurrency, desactiva speculative fan-out, pon tareas nuevas en cola, acorta contexto y evita dos capas agresivas de retry entre SDK y wrapper. Si el SDK ya reintenta transient failures, la capa externa necesita un límite todavía más claro.
No empujes todo trabajo largo por solicitudes síncronas. Cuando el usuario no necesita respuesta inmediata, usa queue o batch. Para salidas largas, streaming reduce la confusión con idle timeout. Si reutilizas mucho contexto grande, prompt caching ayuda con presión de tokens y con 429, aunque no garantiza que desaparezca 529.
Cambiar de modelo es una táctica de continuidad. Sirve si el contrato del producto permite variar calidad o estilo. Si la respuesta debe venir del modelo original, espera y reintenta después en lugar de cambiarlo en silencio.
Verifica la misma ruta antes de escalar
La mejor verificación es same-path small-load test. Deja fijos key, organization, workspace, endpoint, model, client library, proxy y network path. Primero manda una solicitud pequeña; luego manda la forma de producción con menor concurrency. Ese par separa presión del proveedor, tamaño del payload, patrón de burst y wrapper layer.
Mantén un overload log aparte. Incluye request id, status, error type, model, endpoint, workspace, provider route, attempt, delay, input token estimate, output cap y final disposition. La documentación de Anthropic indica que request id ayuda a soporte a investigar una solicitud concreta. Una escalación con request ids, timestamps, snapshot de estado y reproducción same-path vale más que una captura genérica de terminal.
Escala cuando el síntoma sea persistente, amplio y reproducible. Si solo falla Zapier, Make o proxy mientras una llamada directa funciona, empieza por esa plataforma. Si las solicitudes directas pequeñas también devuelven 529 con estado limpio, envía request ids y ventana temporal a soporte. Si hay incidente activo, conserva evidencia y deja que la cola espere la recuperación.
Claude Code, gateways y automatizaciones
Claude Code tiene comportamiento propio. Su referencia de errores indica que server errors, overloaded responses, timeouts, temporary throttles y dropped connections se reintentan automáticamente antes de mostrarse. Por eso repeated 529 en terminal ya aparece después de varios intentos. El siguiente paso es estado, espera o cambio de modelo para continuidad, no concluir que se agotó tu quota de Console API.
Los gateways y productos de automatización agregan otra rama. Zapier, Make, proxy o hosted agent pueden replay, delay o transform error. Separa upstream Anthropic status de wrapper status. Si la plataforma solo muestra generic failure, añade logging del HTTP status original y del Anthropic error type. Sin eso, 529, 429, timeout y wrapper quota parecen lo mismo.
En producción funciona mejor una state machine pequeña: classify error, check service status, retry with cap, reduce pressure, queue deferred work, preserve request evidence. Es más fiable que rotar claves, hacer loop inmediato o degradar el modelo sin aviso.
Checklist de producción
| Control | Por qué importa en 529 | Implementación |
|---|---|---|
| Error classifier | Separa 529 de 429/500/504 | Leer HTTP status y error type |
| Capped jittered retry | Evita retry storm | Presupuestos distintos para foreground y batch |
| Concurrency limits | Evita que todos los workers despierten juntos | Cap por model, endpoint y route |
| Durable queue | Protege solicitudes de usuario | Guardar next retry time y attempt |
| Same-path probe | Confirma si una solicitud pequeña pasa | Mantener key, workspace, model y route |
| Request id logging | Hace accionable soporte | Guardar id del body y header |
| Status observation | Distingue incident de local pressure | Registrar checked time y component |
Preguntas frecuentes
Claude API 529 consume quota?
Trátalo primero como capacity branch. La referencia de Claude Code separa repeated 529 de usage limit. En API directa conviene revisar Billing y Usage, pero no apliques reparación de 429 a overloaded_error.
Puedo reintentar overloaded_error inmediatamente?
No. Usa backoff, jitter y ceiling. Los reintentos inmediatos aumentan carga justo cuando el servicio pide bajar velocidad.
Cambiar de modelo arregla el problema?
Es una táctica de continuidad. Solo encaja cuando el producto permite otra calidad de salida. Si necesitas el modelo original, espera y reintenta.
Qué debo enviar a soporte?
Request ids, timestamps con zona horaria, model, endpoint, workspace, provider route, status-page state, retry schedule y resultado de una solicitud pequeña por la misma ruta.