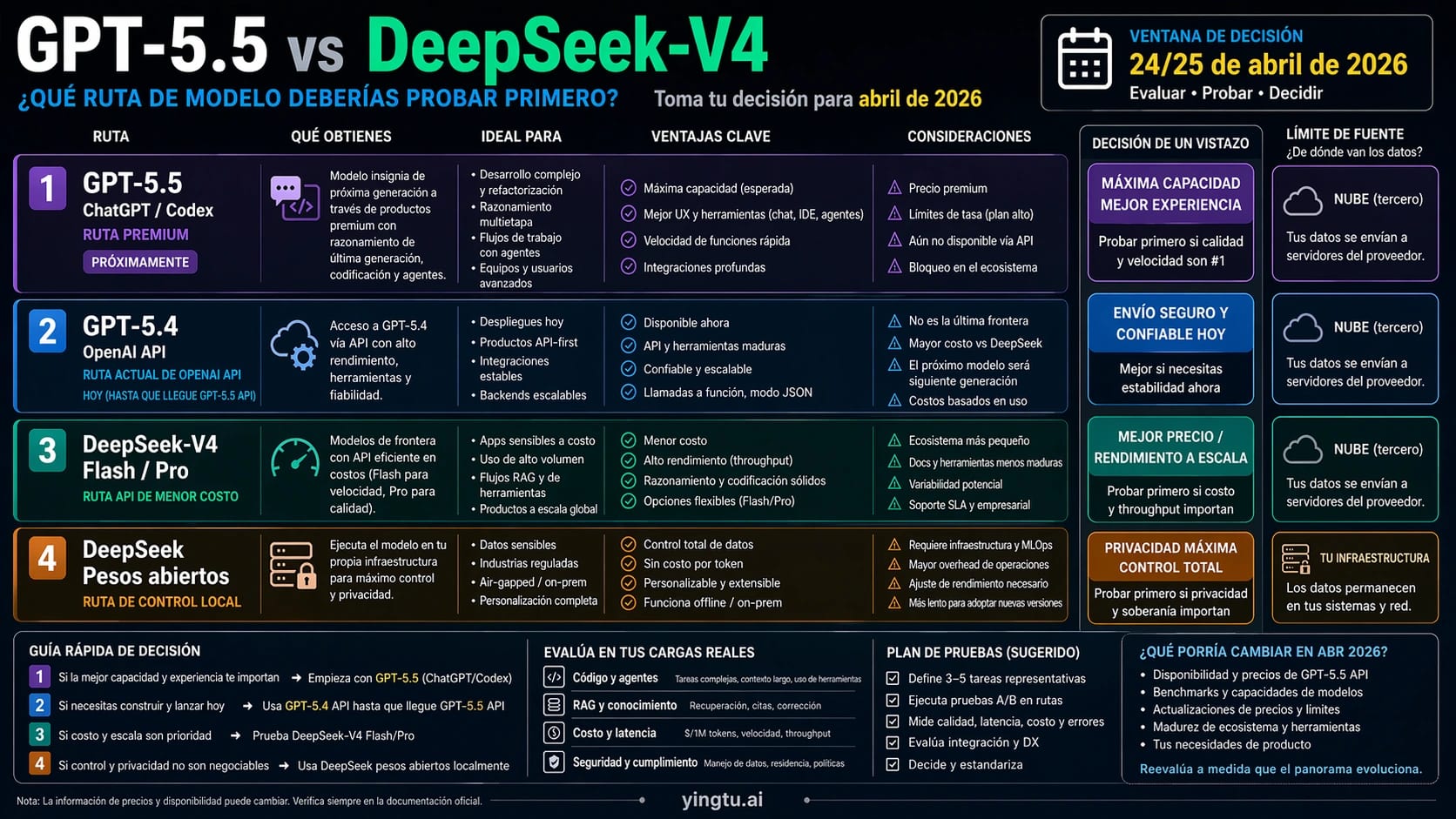
A 24/25 de abril de 2026, GPT-5.5 y DeepSeek-V4 no son dos opciones API intercambiables. Prueba primero GPT-5.5 cuando el trabajo vive dentro de ChatGPT o Codex. Mantén GPT-5.4 como base de producción si hoy estás desplegando sobre OpenAI API. Prueba DeepSeek-V4-Flash o DeepSeek-V4-Pro cuando el coste de API, el contexto de 1M, los pesos abiertos o el control local importan más que permanecer dentro del ecosistema OpenAI.
| Ruta | Probar primero cuando | Esperar cuando |
|---|---|---|
| GPT-5.5 en ChatGPT/Codex | Necesitas la experiencia premium de OpenAI para código, agentes y razonamiento dentro del producto. | Necesitas una API de producción normal hoy. |
| GPT-5.4 en OpenAI API | Ya envías cargas sobre OpenAI API y necesitas una base actual estable. | Puedes esperar a que GPT-5.5 API esté realmente disponible. |
| DeepSeek-V4-Flash o V4-Pro API | Buscas menor coste, pruebas de largo contexto o una evaluación nativa de DeepSeek. | Necesitas tooling OpenAI-native, soporte empresarial o una base de calidad ya validada. |
| Pesos abiertos de DeepSeek-V4 | Necesitas control local, licencia MIT, privacidad o experimentos self-hosted. | No quieres operar infraestructura de inferencia. |
Los benchmarks públicos sirven para elegir qué pruebas diseñar, no para declarar un ganador universal. Antes de mover tráfico de producción, ejecuta las mismas tareas en las rutas candidatas y mide calidad, latencia, coste, comportamiento de herramientas, recuperación de errores y manejo de datos.
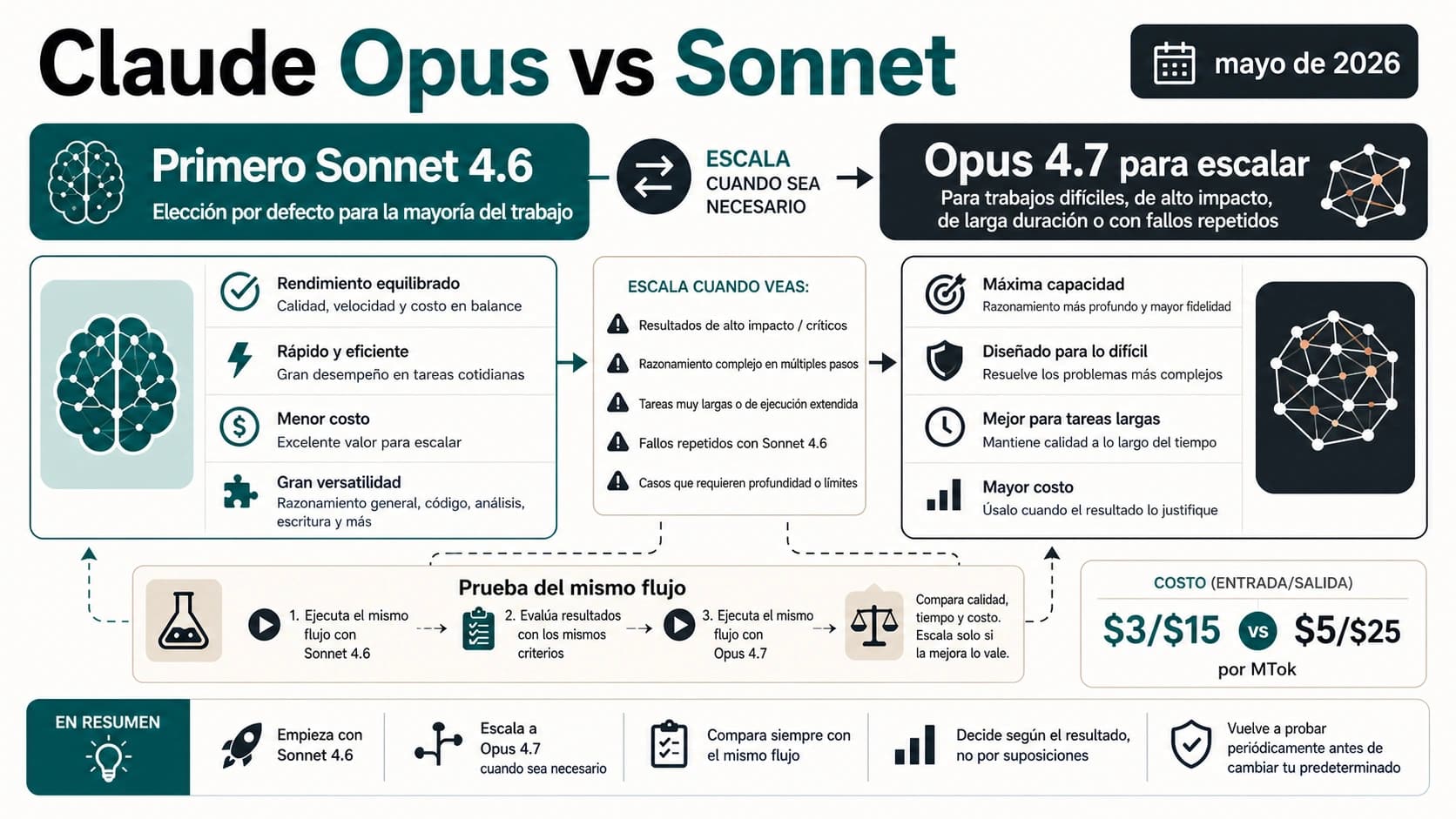
La respuesta práctica: elige ruta, no campeón
En español, muchas comparaciones se quedan en "DeepSeek es más barato" o "GPT sigue siendo mejor". Esa forma es rápida, pero incompleta para un desarrollador. La decisión real es qué puedes usar ahora, qué puedes poner en producción, qué ruta solo está anunciada y qué ruta exige infraestructura propia.
GPT-5.5 debe evaluarse primero como una experiencia OpenAI-native. Su valor no es solo el modelo: también entran Codex, ChatGPT, permisos de cuenta, integración con editor o terminal, flujo de revisión y contexto del producto. DeepSeek-V4 ofrece otra propuesta: API hospedada de bajo coste, variantes Flash y Pro, contexto de 1M, pesos abiertos y opción de control local. Compararlas como si fueran dos filas idénticas borra la parte más importante de la decisión.
| Trabajo | Primera ruta | Motivo |
|---|---|---|
| Reparación de código y agentes dentro de Codex | GPT-5.5 | Evalúas modelo y superficie OpenAI juntos. |
| Servicio ya desplegado sobre OpenAI API | GPT-5.4 | Es la base actual mientras GPT-5.5 API no aparece en la documentación viva. |
| Extracción, clasificación, resumen y routing de alto volumen | DeepSeek-V4-Flash | Permite bajar coste si hay validación automática. |
| Código difícil, razonamiento y síntesis de largo contexto | DeepSeek-V4-Pro | Es la ruta DeepSeek más razonable cuando la calidad pesa más que el mínimo coste. |
| Privacidad, self-hosting o control local | DeepSeek-V4 pesos abiertos | La decisión se vuelve también una decisión de infraestructura. |
La comparación útil no pregunta solo "cuál gana". Pregunta qué ruta reduce riesgo operativo para tu caso. Si ya tienes prompts, clientes, monitorización y contratos sobre OpenAI API, GPT-5.4 es el baseline. Si estás explorando Codex como flujo de trabajo premium, GPT-5.5 merece el primer turno. Si tu factura de inferencia o tu necesidad de control local son el problema, DeepSeek-V4 merece una prueba seria.
Disponibilidad y precios: qué se puede usar hoy
El anuncio de GPT-5.5 de OpenAI presenta el modelo como una nueva opción premium para ChatGPT y Codex. También adelanta precios de API, pero la guía de modelos actuales de OpenAI mantiene GPT-5.4 como ruta actual de OpenAI API a 24/25 de abril de 2026. Por eso GPT-5.5 es una ruta actual para trabajos OpenAI-native, no todavía una ruta API normal equivalente a DeepSeek-V4.
DeepSeek sí lista rutas hospedadas actuales en su página de pricing de API: deepseek-v4-flash y deepseek-v4-pro. La documentación también describe endpoints compatibles con OpenAI y Anthropic, lo que facilita una prueba de integración sin rediseñar todo el cliente. Para producción conviene usar IDs explícitos en lugar de depender de alias como deepseek-chat o deepseek-reasoner, porque un alias puede cambiar de comportamiento.
| Ruta | Estado actual | Señal de precio a 24/25 de abril de 2026 |
|---|---|---|
| GPT-5.5 en ChatGPT/Codex | Disponible en las superficies de producto indicadas por OpenAI. | Acceso por producto o workspace, no billing normal por tokens de API. |
| GPT-5.5 API | Anunciada como coming soon. | Precio anunciado: $5 input y $30 output por 1M tokens. |
| GPT-5.5 Pro API | Anunciada como coming soon. | Precio anunciado: $30 input y $180 output por 1M tokens. |
| GPT-5.4 API | Ruta actual de OpenAI API. | Revisar precio y límites actuales antes de desplegar. |
| DeepSeek-V4-Flash API | Listada en DeepSeek API docs. | Cache hit $0.028, cache miss $0.14, output $0.28 por 1M tokens. |
| DeepSeek-V4-Pro API | Listada en DeepSeek API docs. | Cache hit $0.145, cache miss $1.74, output $3.48 por 1M tokens. |
| DeepSeek-V4 pesos abiertos | Respaldada por artefactos oficiales del modelo. | El coste pasa a GPU, serving, monitorización y equipo. |
La diferencia de precio es fuerte, pero no debe convertirse en una promesa de producción. DeepSeek-V4-Flash encaja bien en cargas repetitivas con validación automática. DeepSeek-V4-Pro es más adecuado para evaluar tareas duras. GPT-5.5 puede justificar un precio superior si dentro de Codex reduce iteraciones, revisiones humanas o fallos operativos.
Benchmarks: evidencia útil, no tabla final
OpenAI publica resultados de GPT-5.5 para coding, browsing y agentic work, incluyendo Terminal-Bench 2.0, SWE-Bench Pro public y BrowseComp. DeepSeek publica en la model card de DeepSeek-V4-Pro filas para DeepSeek-V4-Pro-Max, incluyendo Terminal-Bench 2.0, SWE Verified, SWE Pro, BrowseComp, MCPAtlas Public y Toolathlon.
Esas filas no forman una única clasificación neutral. Vienen de fuentes distintas, con modos y entornos que pueden variar. El uso correcto es convertirlas en hipótesis de prueba: qué tareas ejecutar, qué métricas capturar y qué fallos bloquean una migración.
| Área | Qué sugiere la evidencia pública | Qué debes medir tú |
|---|---|---|
| Código | GPT-5.5 muestra señales fuertes en flujos OpenAI; DeepSeek-V4-Pro no parece solo un modelo barato. | Parches multiarchivo, tests, dependencias, calidad de revisión. |
| Herramientas y agentes | Hay evidencia de tool use y browsing en ambos lados, pero no en el mismo entorno. | Argumentos de funciones, retries, recuperación parcial, JSON válido. |
| Largo contexto | DeepSeek-V4 enfatiza 1M context; GPT-5.5 API también se anuncia con 1M context. | Recuerdo de información tardía, instrucciones conflictivas, coste real del prompt. |
| Producción | Los benchmarks no muestran bien p95 latency, rate limits ni auditoría. | Timeouts, rechazo, latencia, logs, manejo de datos y cumplimiento. |
El criterio final debe ser accepted output cost: cuánto cuesta obtener una salida que pasa validación y no exige reparación humana. Un modelo barato que falla dos veces y requiere revisión manual puede salir caro.
DeepSeek-V4 no es una sola fila
DeepSeek-V4-Flash es la primera prueba para volumen. Encaja en extracción, clasificación, respuestas cortas, preprocesamiento RAG, routing y conversión de formato. El precio bajo permite añadir verificación, candidatos múltiples o retries sin disparar el coste.
DeepSeek-V4-Pro es la opción DeepSeek cuando la tarea es más difícil: coding agents, razonamiento multietapa, coordinación de herramientas, síntesis de contexto largo. Si Flash produce respuestas plausibles pero frágiles, Pro es una evaluación más honesta.
Pesos abiertos son otra clase de decisión. La licencia y los artefactos oficiales permiten control local, pero desaparece el token billing y aparecen GPU, batching, seguridad, actualizaciones, observabilidad y operación. Esta ruta tiene sentido cuando privacidad, data residency o personalización pesan más que la comodidad de una API hospedada.
El contexto de 1M tampoco se valida con un solo prompt largo. Incluye documentos irrelevantes, evidencias colocadas al final, requisitos contradictorios y comprobación de citas. El objetivo es medir si el modelo encuentra la información correcta, no si acepta una entrada grande.
Recomendaciones por flujo de trabajo
Para coding dentro de Codex o ChatGPT, prueba GPT-5.5 primero. El valor está en la combinación de modelo, producto, permisos, flujo de revisión e integración con herramientas. DeepSeek-V4 puede entrar como comparación externa, pero no reemplaza toda la experiencia Codex con una sola llamada API.
Para aplicaciones existentes sobre OpenAI API, mantén GPT-5.4 como baseline hasta que GPT-5.5 API aparezca en la documentación viva. Puedes preparar routing y abstracciones, pero no prometas GPT-5.5 API en material de producto, SLA o documentación de usuario antes de que esté disponible.
Para cargas de alto volumen y bajo riesgo, prueba DeepSeek-V4-Flash. El objetivo es reducir coste por salida aceptada. Si Flash falla en razonamiento, formato o herramientas, sube solo esas partes a DeepSeek-V4-Pro.
Para razonamiento o código difícil fuera de la superficie OpenAI, compara DeepSeek-V4-Pro con GPT-5.4 API ahora, y añade GPT-5.5 API cuando se abra. Las métricas deben ser parches aceptados, tests que pasan, JSON válido, éxito en tool calls y minutos de revisión humana.
Para privacidad o control local, empieza con un piloto pequeño de pesos abiertos. Ese piloto debe medir calidad de modelo e infraestructura. Si no puedes operar inferencia con seguridad y observabilidad, la ruta abierta no está lista para producción.
Plan de prueba antes de migrar
No migres con cien prompts improvisados. Elige de tres a cinco tareas reales: reparación de código, respuesta con largo contexto, extracción estructurada, tool call y batch de alto volumen. Para cada una define input, salida esperada, rúbrica, política de retry, severidad del fallo y fórmula de coste.
| Línea de prueba | Cuándo usarla | Qué medir |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | El flujo de producto OpenAI es parte del resultado. | Calidad, esfuerzo humano ahorrado, revisión de código, encaje del workflow. |
| GPT-5.4 API | Baseline actual de OpenAI API. | Coste, latencia, tools, structured output, regresiones. |
| DeepSeek-V4-Flash API | Carga de alto volumen o sensible a coste. | Pass rate, retry rate, formato válido, cache behavior. |
| DeepSeek-V4-Pro API | Evaluación DeepSeek más exigente. | Exactitud, estabilidad de razonamiento, tools, long-context recall. |
| DeepSeek-V4 pesos abiertos | Control local como requisito principal. | GPU cost, throughput, latency, seguridad y monitorización. |
Escribe reglas de parada antes de probar. No migres si la ruta rompe JSON, omite argumentos de herramientas, ignora evidencia tardía, genera cambios de código peligrosos o requiere tanta revisión humana que borra el ahorro. Empieza con shadow traffic o batch de bajo riesgo, confirma logs y monitorización, y aumenta el porcentaje solo después.
Preguntas frecuentes
¿GPT-5.5 está disponible en la API hoy?
OpenAI anunció precios y acceso futuro para GPT-5.5 API, pero a 24/25 de abril de 2026 la guía actual mantiene GPT-5.4 como ruta de producción de OpenAI API. Trata GPT-5.5 como ruta actual de ChatGPT/Codex y como futura ruta API.
¿Qué pruebo primero en DeepSeek-V4: Flash o Pro?
Flash si el trabajo es de alto volumen, bajo riesgo y con validación automática. Pro si importan razonamiento, código, herramientas o largo contexto. Pesos abiertos si el control local es el requisito principal.
¿DeepSeek-V4 es mejor solo porque cuesta menos?
No. El precio bajo justifica probarlo, no adoptarlo automáticamente. Decide por coste de salida aceptada, retries, revisión humana, latencia y riesgo operativo.
¿Los benchmarks pueden decidir el ganador?
No. Sirven para diseñar pruebas. La decisión de producción exige los mismos inputs, la misma rúbrica y el mismo entorno operativo.
¿Cuándo hay que revisar la decisión?
Cuando GPT-5.5 aparezca en la documentación de OpenAI API, cuando DeepSeek cambie precios o alias, cuando haya evaluaciones independientes comparables, o cuando cambie tu mezcla de tareas. No es un ranking fijo; es una decisión de ruta.