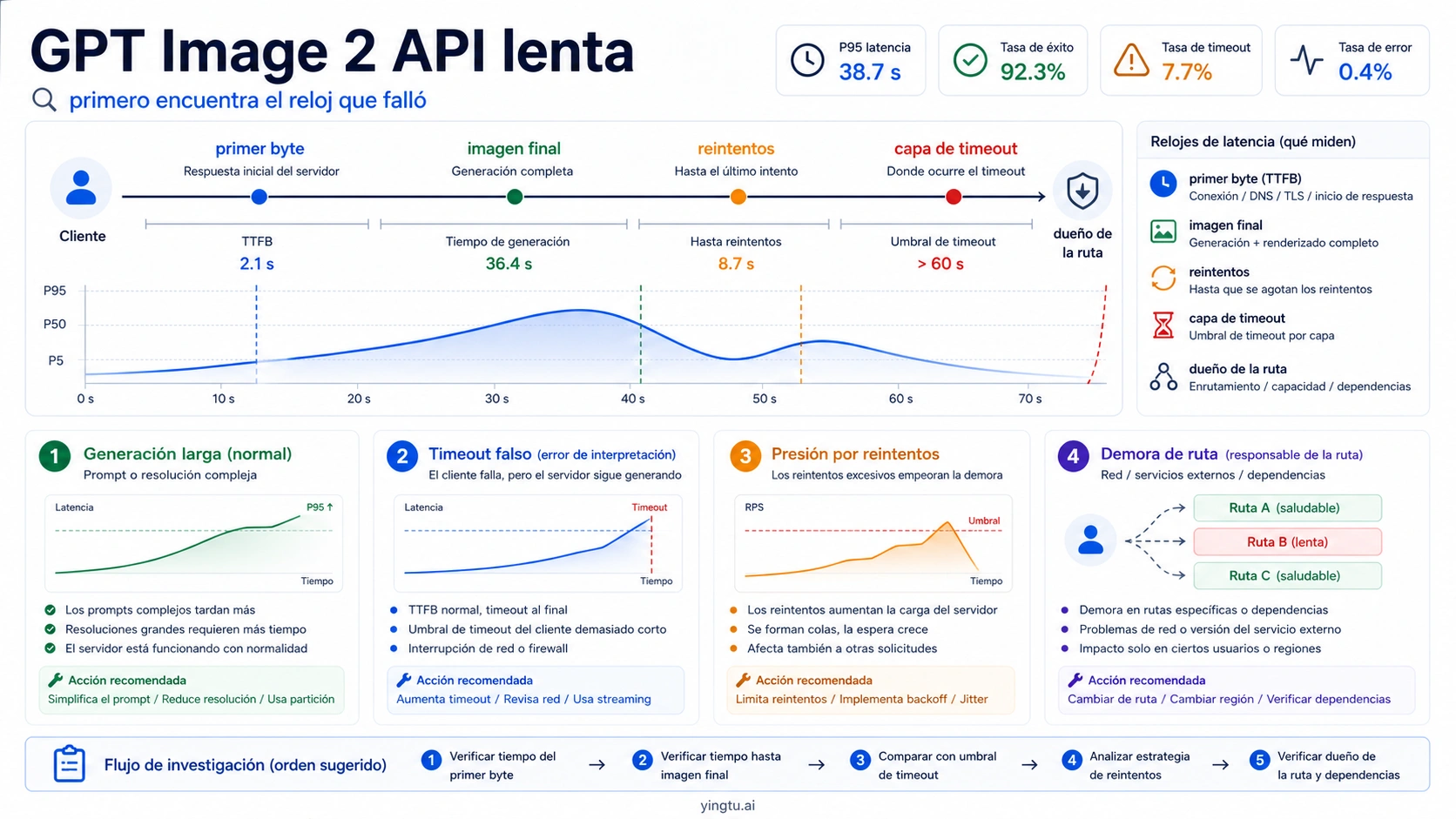
Una llamada lenta a GPT Image 2 API no significa automáticamente que el modelo esté fallando. Un prompt complejo, varias imágenes de referencia, quality alta o un tamaño grande pueden hacer que la generación tarde mucho. Pero en producción muchas veces falla antes otra capa: el navegador corta el fetch, una función serverless alcanza su límite, el proxy inverso cierra la conexión idle, un gateway reintenta sin mostrarlo, o el frontend deja al usuario con un spinner y provoca otro clic. El primer paso no es optimizar, sino medir.
| Lo que ves | Primera clasificación | Primera acción segura |
|---|---|---|
| El primer byte tarda, pero la imagen final llega | generación larga o cola | mostrar estado, considerar streaming o job asíncrono, luego probar low quality o square output si el producto lo tolera |
| El backend termina pero el navegador falla | timeout falso | ampliar solo la capa que falló, no toda la cadena |
| Se acumulan reintentos o aparece 429 | presión de retries y rate limits | parar reintentos cortos, leer headers de límite, drenar cola con backoff |
| Solo va lento por un gateway | demora del dueño de ruta | comparar la misma forma de request con una ruta más directa y escalar con datos anonimizados |
No cambies claves, proveedor, quality ni retry policy antes de saber qué reloj falló y qué sistema posee los logs.
Separa generación lenta de timeout falso
Un log que solo dice duration_ms=90000 no alcanza. No muestra si el problema fue la conexión, el primer byte, la primera imagen parcial, la imagen final, la descarga, el render, un retry duplicado o una capa local que cortó antes. Para GPT Image 2 necesitas varios relojes en el mismo evento de job.
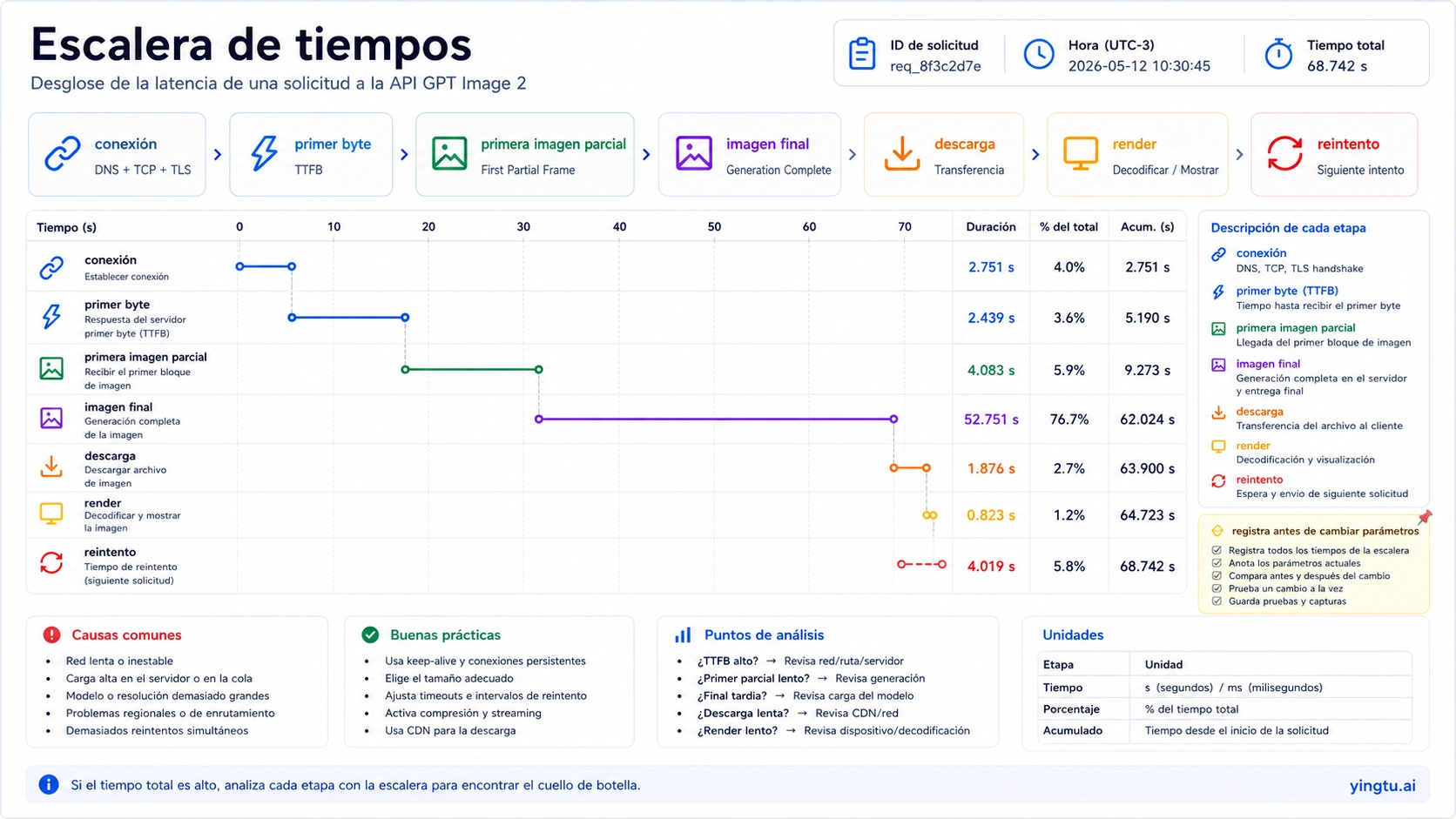
El evento mínimo debe incluir request_started_at, connect_ms, first_byte_ms, first_partial_image_ms, final_image_ms, download_ms, render_ms, retry_count, retry_reason, http_status, error_type, request_id, model, quality, size, format y route_owner. Con esos campos puedes saber si esperaste red, modelo, archivo, navegador o un retry.
El route owner importa tanto como el tiempo. OpenAI direct, Azure, un gateway compatible o una ruta inversa pueden compartir el nombre gpt-image-2, pero tener timeouts, headers, retries, logs y soporte distintos. Si el mismo prompt es rápido en una ruta y lento en otra, el modelo ya no es el único sospechoso.
Diseña un timeout budget para generación de imágenes
Un buen presupuesto de timeout no es poner 300 segundos en todas partes. Cada capa debe saber qué espera: el navegador espera estado, el backend espera el job, el proxy espera upstream, el gateway informa su mapping, y la cola conserva el resultado. Mientras más cerca del usuario mantengas una espera síncrona, más probable es tener un timeout falso.
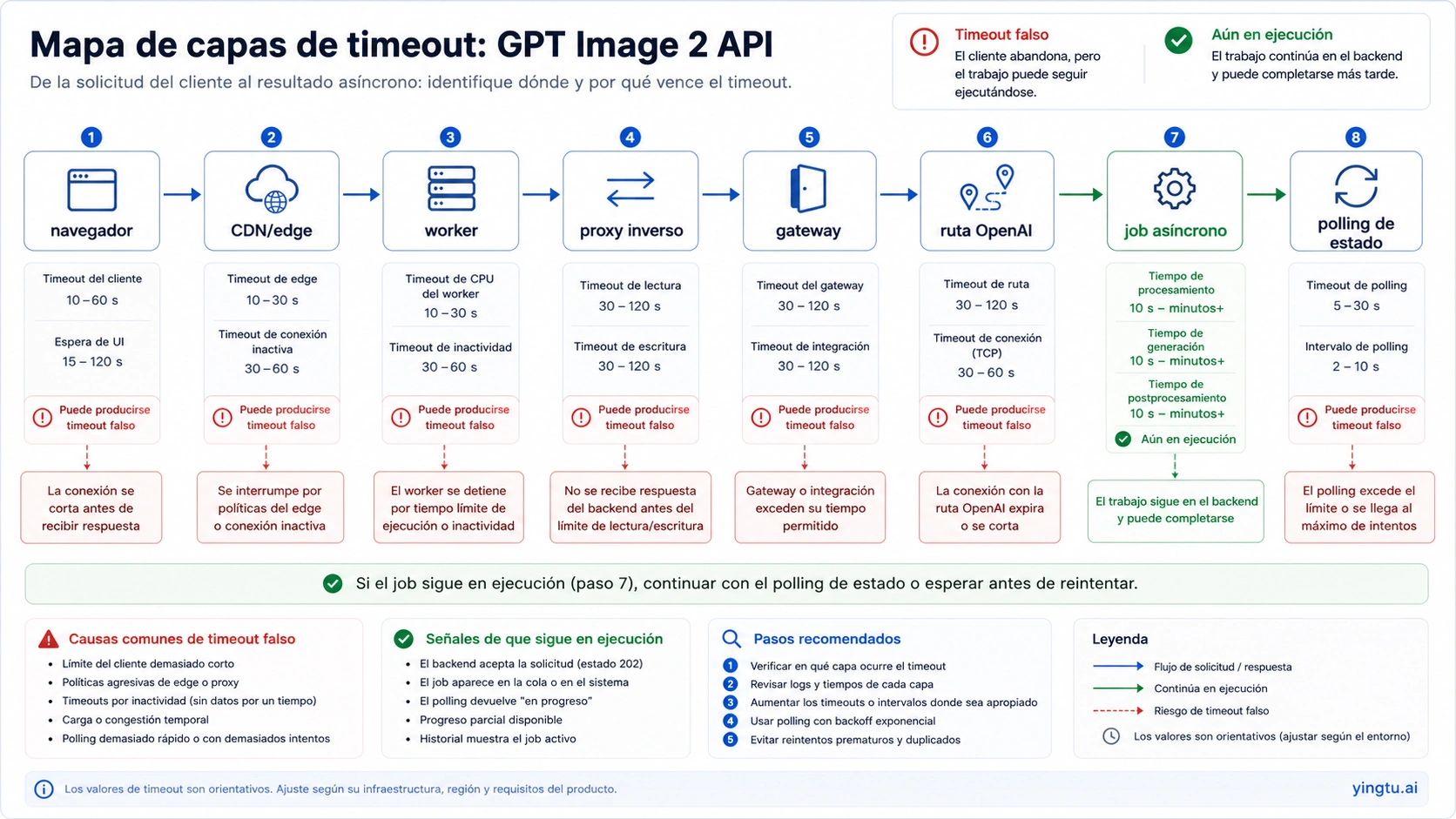
| Capa | Falla típica | Regla más segura |
|---|---|---|
| Browser o mobile client | fetch aborta antes del backend | devolver job id, stream de progreso o polling |
| CDN o edge | límite de plataforma corta la solicitud | sacar generación de rutas edge cortas |
| Serverless worker | function timeout antes de la imagen | usar worker largo, cola o background job |
| Reverse proxy | idle/upstream timeout | ampliar solo la ruta de imagen |
| Gateway/provider | respuesta tarde o retries invisibles | revisar logs, upstream status y timeout del provider |
| SDK/HTTP client | timeout local primero | definir timeout explícito junto a retry policy |
Para un producto interactivo, el usuario no debe esperar en silencio. Usa estados como queued, generating, partial preview, finalizing, saved, failed upstream o failed at local timeout. Eso reduce clics duplicados y hace que soporte pueda reconstruir qué pasó.
Cambia parámetros solo después del baseline
La guía oficial de imágenes da palancas reales. Low quality es útil para drafts, square output suele ser más simple, JPEG puede ser más rápido que PNG cuando importa latency, y un prompt complejo puede tardar cerca de dos minutos. Pero estas palancas se usan después de medir, no antes.
| Cambio | Puede mejorar | Puede dañar | Cuándo probar |
|---|---|---|---|
| quality low | respuesta de borrador | detalle, texto y acabado | ideación, thumbnail, preview interno |
| square output | generación y layout | relación de aspecto requerida | cuando puedes recortar o componer luego |
| JPEG | transferencia y decode | transparencia y postproducción | preview o imagen fotográfica |
| PNG/WebP | calidad y control de compresión | transferencia y procesamiento | asset final o flujo posterior |
| menos referencias | upload y input processing | estilo, identidad y composición | referencias sin beneficio medible |
| prompt más simple | trabajo del modelo | precisión de dirección artística | cuando el reloj lento está en generación |
Si la calidad es el valor del producto, no la sacrifiques por una métrica. La rama de calidad pertenece a /es/blog/gpt-image-2-low-quality/, y la de gran resolución a /es/blog/gpt-image-2-4k-image-generation/. Aquí el foco sigue siendo el reloj lento y el dueño de la ruta.
Usa streaming y async para mejorar la latencia percibida
Streaming de partial images ayuda a mostrar progreso antes de la imagen final. No garantiza que el cómputo final termine antes. En logs, separa first byte, first partial image y final image. Si streaming no encaja con tu interfaz, un job asíncrono con polling suele ser más robusto.
El backend crea el job, devuelve un id estable y el frontend consulta estado. Así el navegador no sostiene toda la ventana de generación y el producto distingue entre todavía corre y falló, hace falta un nuevo job. En generación de imágenes, un segundo clic puede ser trabajo nuevo, costo nuevo y presión nueva sobre límites.
No conviertas lentitud en un incidente de rate limit
Si un timeout local a 60 segundos dispara retry inmediato, el primer job quizá sigue corriendo upstream. El sistema ya creó un segundo job. Con varios usuarios, eso se convierte en presión de RPM, TPM, IPM o daily limit. La recuperación correcta debe saber si el job original sigue vivo.
| Condición | Comportamiento de retry |
|---|---|
| timeout local sin respuesta | comprobar si el job original sigue ejecutándose |
| 429 o limit headers | backoff con jitter y respeto de reset headers |
| 5xx o error transitorio | retry acotado con máximo de intentos |
| usuario pulsa generar otra vez | reutilizar pending job o pedir confirmación |
| gateway reintentó internamente | contar retries del gateway por separado |
Si el diagnóstico se desplaza a 429 o cuotas, usa /es/blog/openai-api-rate-limit/ y /es/blog/gpt-image-2-usage-limits/. Arreglar latency no debe convertirse en un rodeo oculto de límites.
Distingue OpenAI direct, Azure, gateway y reverse route
En OpenAI direct necesitas model id, endpoint, request id si existe, status y headers. En Azure importan deployment, región, quota, APIM y estado regional. En un gateway compatible importan base URL owner, upstream mapping, provider timeout, retry policy y visibilidad de logs. En una reverse route añade account/session owner, hidden retries, policy boundary y support risk.
Si el mismo request es rápido en direct y lento en gateway, no culpes solo al modelo. Si el gateway no muestra logs transparentes, no distingue local timeout de upstream wait o no tiene dueño claro, no es una buena ruta para diagnóstico de producción. La elección de coste o acceso puede ir a /es/blog/gpt-image-2-api-cheap/; el diagnóstico de lentitud se queda con clocks y ownership.
Escala con el paquete correcto

Incluye timestamp, zona horaria, si es repetido o aislado, route owner, modelo, endpoint, streaming, quality, size, format, referencias, first byte, partial image, final image, descarga, render, timeout layer, retry count, returned status, request id si existe, worker/runtime, proxy, CDN, browser timeout y reproducción mínima.
No envíes API keys, tokens, prompts privados, imágenes privadas, customer identifiers, IPs, channel ids, account-pool details ni raw logs. La decisión final debe ser concreta: ampliar una sola capa de timeout, pasar a async job, usar low quality para drafts, cambiar format, separar high-resolution work, corregir backoff o llevar el caso al route owner que sí tiene logs.
Haz una prueba mínima reproducible
Cuando ya tienes los relojes principales, el siguiente paso es una prueba controlada. No cambies route, quality, size, format, retry policy y timeout en la misma ejecución. Si cambias todo a la vez, no sabrás si mejoró el trabajo del modelo, si desapareció el timeout local, si bajó el peso del archivo o si solo cambió el dueño de la ruta.
El orden práctico es simple. Primero ejecuta tres veces el mismo prompt, quality, size, format y route owner. Eso muestra si la demora es estable o un pico aislado. Luego cambia solo la forma de espera: request síncrono del browser contra job asíncrono con polling. Después cambia solo output format, por ejemplo PNG frente a JPEG, y mira download_ms y render_ms. Luego prueba quality low, medium y high. Compara OpenAI direct, Azure o gateway solo al final.
| Ronda | Mantén fijo | Única variable | Decisión |
|---|---|---|---|
| Baseline | prompt, quality, size, format, route | tres ejecuciones iguales | si la lentitud es estable |
| Sync vs async | prompt, parámetros, route | forma de espera | si desaparece el browser timeout |
| Output format | prompt, quality, size, route | JPEG / PNG / WebP | si cambia transfer/render |
| Quality | prompt, size, format, route | low / medium / high | si cambia final_image_ms |
| Route owner | prompt, parámetros, retry policy | direct / Azure / gateway | si la demora pertenece a la ruta |
Si solo high quality es lento, no concluyas que todo GPT Image 2 API es lento. Si solo falla el browser path, no culpes al upstream. Si solo va lento el gateway, separa ese comportamiento de OpenAI direct. La prueba mínima no busca ampliar la culpa; busca reducir el problema a una capa que puedas cambiar o escalar.
También conviene guardar el resultado en una tabla compartida. Incluye hora, zona horaria, route owner, dueño del base URL, streaming, async, parámetros, first byte, final image, capa fallida, retry count y notas. Con esos campos, el equipo no depende de frases vagas como “va lento”; puede decidir si debe ajustar timeout, usar queue, cambiar formato o escalar al dueño de la ruta.
Preguntas frecuentes
¿GPT Image 2 API puede ser lento de forma normal?
Sí. Las generaciones complejas pueden tardar. Pero si browser, proxy o gateway fallan antes de la imagen final, no es solo espera normal: es un timeout falso o una capa mal presupuestada.
¿Un timeout de 60 segundos es demasiado corto?
Puede serlo para image jobs complejos. Aun así, no amplíes todo. Encuentra la capa que falló y ajusta solo esa ruta o mueve el trabajo a background.
¿Streaming hace más rápida la imagen final?
No necesariamente. Mejora progreso visible y reduce clics duplicados. El tiempo de final image se mide aparte.
¿Debo bajar quality primero?
Solo para drafts o previews donde la calidad lo permite. Para producción, mide el slow clock y prueba quality, size y format como comparación controlada.
¿Cómo sé si el gateway es la capa lenta?
Compara el mismo prompt, quality, size y format con una ruta más directa. Registra base URL owner, upstream status, retries, first byte, final image time y status code.