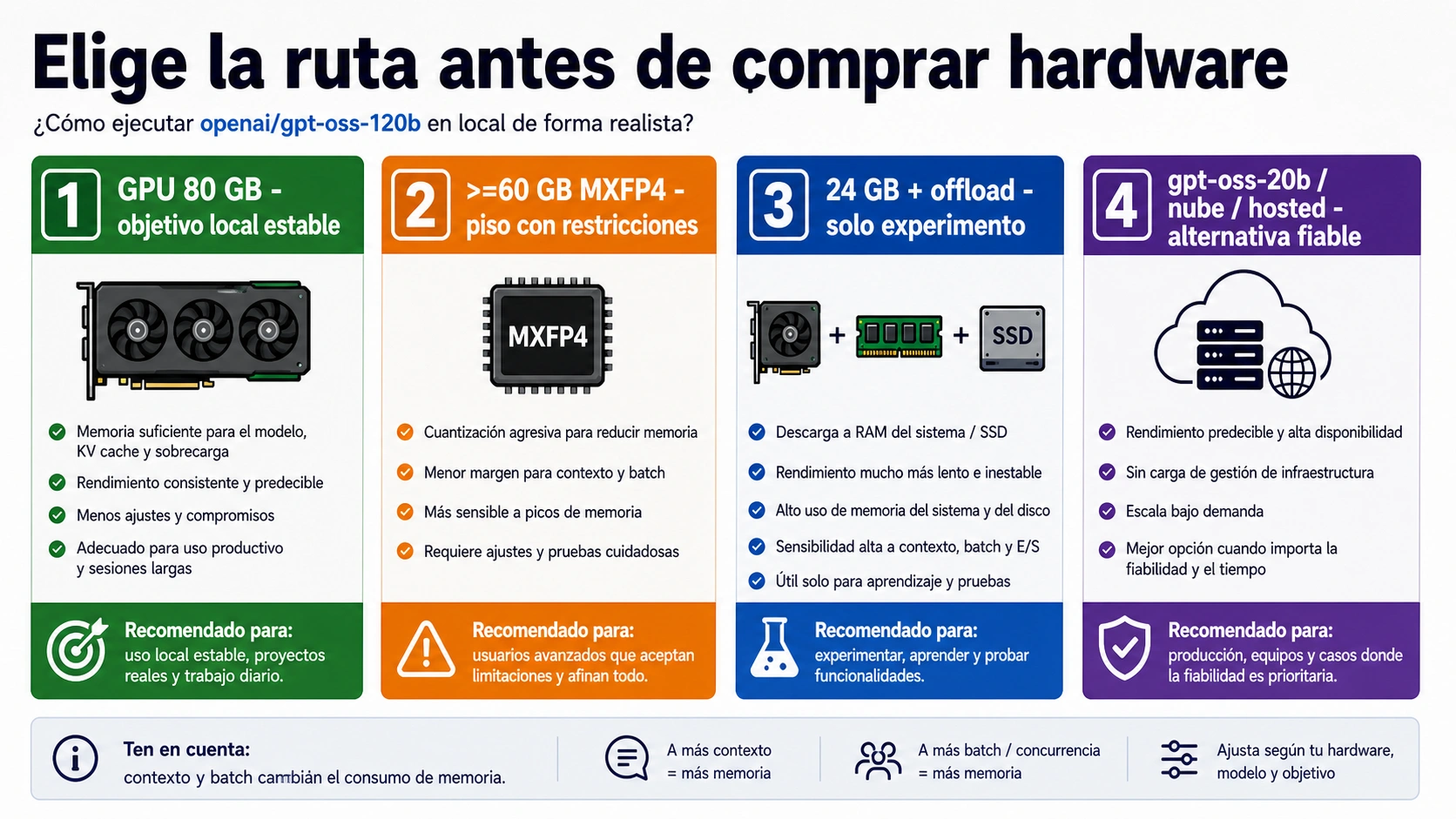
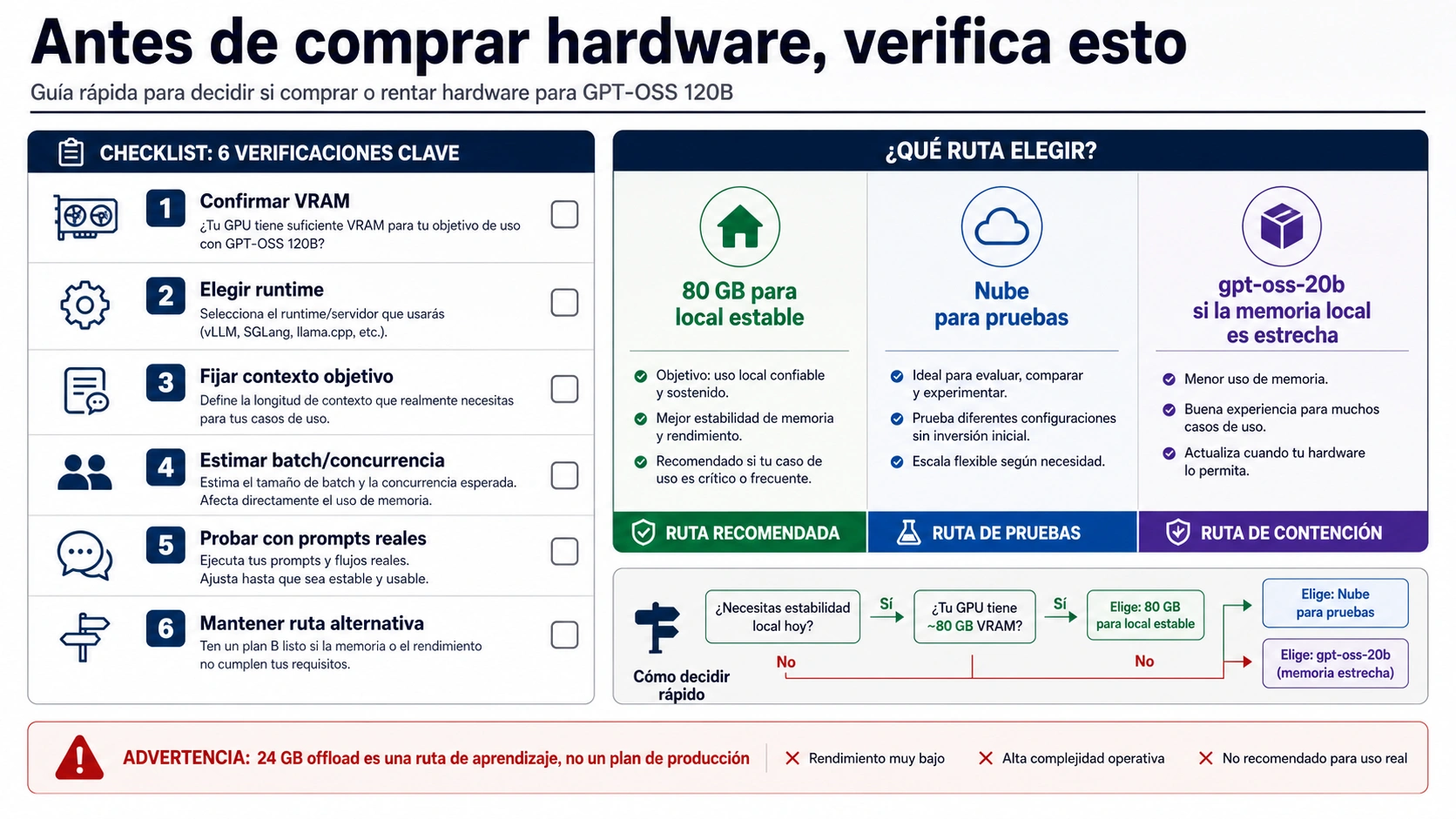
Planifica gpt-oss-120b como un modelo de clase GPU de 80 GB si quieres una ejecución local limpia. El número >=60GB es un piso limitado para rutas MXFP4 compatibles, no una reserva cómoda. Una tarjeta de 24 GB con CPU o NVMe offload pertenece al terreno experimental. Si te importan la velocidad, el contexto largo, la concurrencia o la repetibilidad, compara desde el principio gpt-oss-20b, cloud GPU y acceso hosted en la misma decisión.
| Ruta de hardware | Cómo tratarla | Significado práctico |
|---|---|---|
| GPU de servidor de 80 GB | Ruta local limpia | Mejor punto de partida para trabajo local serio con 120B. |
>=60GB de VRAM o memoria unificada | Piso limitado | Puede cargar en stacks compatibles, pero contexto, batch y overhead siguen importando. |
| GPU de 24 GB con CPU/NVMe offload | Ruta experimental | Útil para aprender y probar despacio, débil como plan de operación. |
gpt-oss-20b, cloud GPU o hosted access | Ruta de salida | Mejor cuando memoria local, velocidad o fiabilidad son la restricción real. |
No compres hardware si el plan depende de la palabra RAM sin precisar el pool de memoria, de una captura aislada o de una prueba que no replica tu runtime, longitud de contexto y concurrencia.
Primero decide la ruta de ejecución
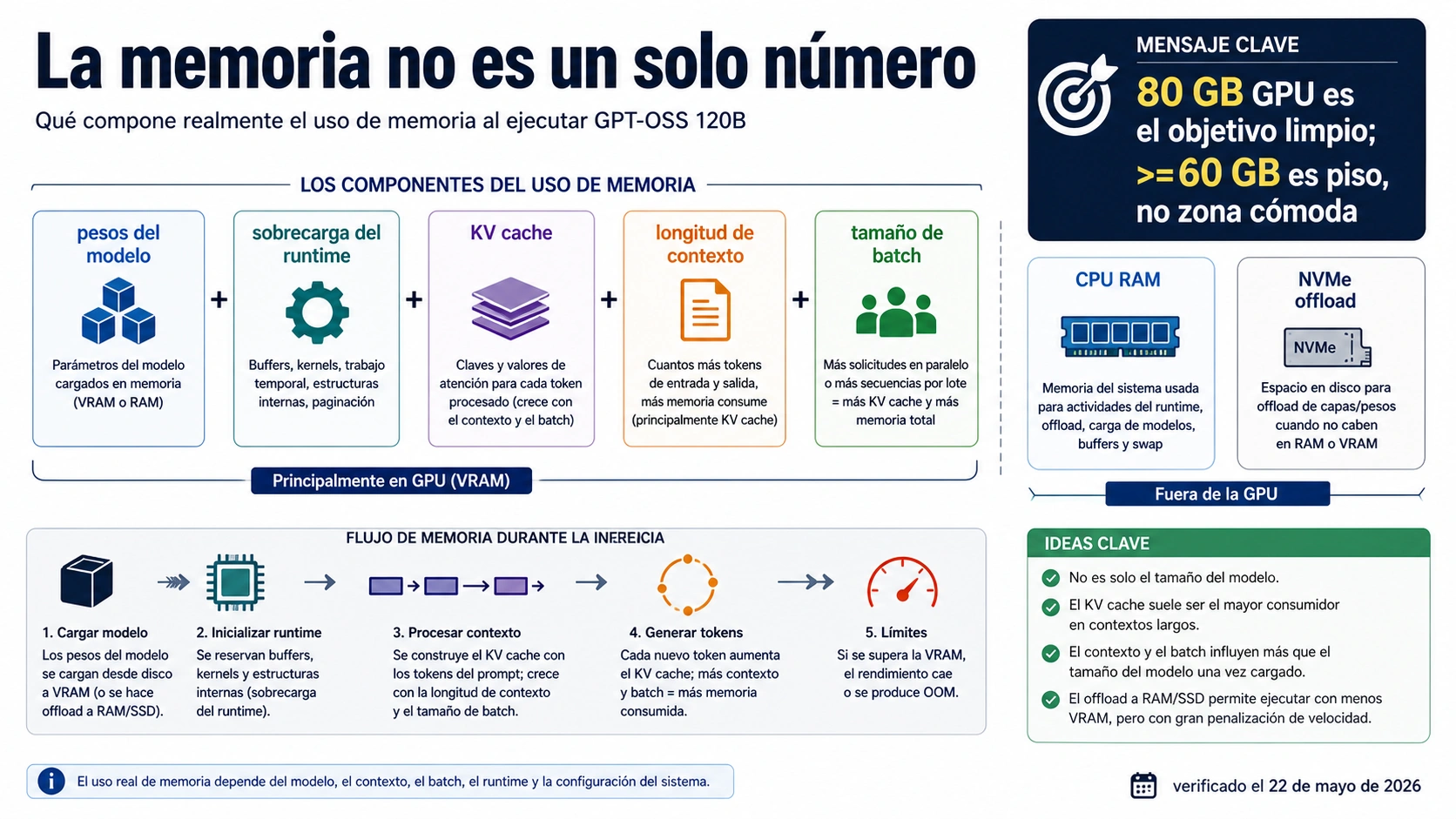
La respuesta útil para GPT-OSS 120B no es un número universal. Depende de la ruta. OpenAI describe gpt-oss-120b como un modelo open-weight de 117B parámetros, 5.1B active parameters y una ventana de contexto larga. La referencia de una GPU de 80 GB es el punto limpio para planificar una ejecución local seria, porque deja espacio para pesos, runtime overhead, contexto normal y margen operativo.
Ese punto no significa que todos los equipos de 80 GB sean iguales ni que cualquier cifra inferior sea falsa. Un chat local corto, una evaluación de calidad de 120B, un servicio interno con varios usuarios y un benchmark puntual tienen presupuestos distintos. Antes de mirar precios, escribe el trabajo real: privacidad local, evaluación de modelo, análisis de documentos largos, servicio de equipo o entrega de producto.
Cuando el objetivo es un asistente local privado, gpt-oss-20b puede ser la mejor elección. Cuando el objetivo es evaluar la capacidad de 120B, alquilar una instancia H100 durante unas horas reduce el riesgo. Cuando el objetivo es entregar un servicio fiable, una ruta hosted puede separar la evaluación del modelo de la propiedad de la infraestructura.
Elegir la ruta primero separa dos preguntas: si el modelo puede cargar y si el sistema será útil bajo tu contexto, batch, latencia y mantenimiento reales.
Por qué 80 GB y 60 GB pueden ser ciertos a la vez
Los 80 GB y los >=60GB contestan preguntas diferentes. 80 GB responde qué clase de acelerador conviene planificar para una ruta local limpia. >=60GB responde qué piso puede funcionar en rutas MXFP4 específicas con un runtime compatible y ajustes prudentes de contexto, batch y overhead.
Las rutas oficiales de ejecución muestran esa diferencia. Transformers es una entrada directa para experimentos en Python, pero depende de kernels y precisión. vLLM encaja mejor con serving y expone controles como longitud máxima del modelo, tokens batched, tensor parallelism y uso de KV cache. Ollama y runners locales facilitan el primer arranque, pero la frase VRAM o memoria unificada no es una garantía para cualquier ordenador de consumo.
El tamaño del checkpoint tampoco es el requisito de memoria. El runtime puede reservar buffers, usar temporales, crear KV cache, cambiar precisión o repartir capas entre GPU. Una prueba corta puede cargar y responder, pero fallar con documentos largos o varios usuarios.
Separa VRAM, memoria unificada, RAM, disco y KV cache
VRAM es la memoria rápida del acelerador. Ahí viven los pesos, el estado del runtime y a menudo el KV cache. Memoria unificada es un pool compartido en algunos sistemas, útil si el runtime lo usa bien, pero no se debe leer como promesa automática de velocidad. RAM del sistema ayuda al sistema operativo, tokenizer, buffers y offload, pero no reemplaza la VRAM.
El offload a disco o NVMe amplía lo que puede cargarse, aunque traslada el problema a la latencia. KV cache es otra fuente de presión: crece con el contexto activo y con solicitudes simultáneas. Batch y concurrency también cambian el presupuesto. Un entorno que sirve a un usuario no prueba que funcione para un equipo.
Por eso conviene escribir cada pool por separado. Cuánta VRAM real tiene el acelerador, cuánta memoria unificada puede usar el runtime, cuánta RAM queda libre después del sistema, si hay swap, si el NVMe participa y qué context length se va a usar. Sin esa separación, la palabra memoria crea decisiones caras.
| Término | Qué significa para gpt-oss-120b | Implicación |
|---|---|---|
| VRAM | Memoria del acelerador para pesos, runtime state y KV cache | Objetivo limpio de un dispositivo: 80 GB. |
| Memoria unificada | Pool compartido en algunos sistemas | Puede servir como ruta limitada, pero exige medición. |
| RAM del sistema | Memoria CPU para sistema, runtime, buffers y offload | Ayuda al experimento, no reemplaza VRAM. |
| Disk/NVMe offload | Movimiento de estado por almacenamiento | Puede cargar, pero la latencia domina. |
| KV cache | Memoria del contexto activo durante generación | Crece con contexto y concurrencia. |
| Batch/concurrency | Tokens o solicitudes procesadas juntas | Serving requiere más margen que chat local. |
Separar estos términos evita la confusión típica: creer que mucha RAM del sistema compensa una VRAM insuficiente para inferencia limpia.
El runtime cambia el presupuesto real
El runtime decide dónde aparece el cuello de botella. En Transformers, el camino es transparente para experimentar, pero un fallback de precisión o un kernel no soportado puede elevar memoria y bajar velocidad. En vLLM, los ajustes de serving controlan el margen restante. En Ollama o herramientas de escritorio, la instalación puede ser sencilla, pero la experiencia con contexto largo depende del mismo presupuesto de memoria.
Multi-GPU tampoco se decide sumando números. Dos tarjetas de 24 GB o tres tarjetas antiguas pueden parecer suficientes por capacidad total, pero interconnect, sharding, drivers y placement manual pueden hacer que la configuración sea frágil. Una GPU del tamaño correcto puede ahorrar más tiempo que varias tarjetas marginales.
Cloud GPU sirve como prueba neutral. Ejecuta tus prompts reales, la longitud de contexto esperada, batch y tokens/sec antes de reservar más tiempo o comprar hardware. Hosted access entra cuando fiabilidad y entrega importan más que operar el stack.
Límites para GPU de consumo
Una GPU de 24 GB cambia la promesa: pasa de despliegue limpio a experimento. Puede enseñar el flujo, permitir pruebas de prompts, mostrar comportamiento de herramientas y explorar offload. No demuestra que GPT-OSS 120B vaya a funcionar bien con contexto largo o servicio compartido.
Una GPU workstation de 48 GB es una ruta de prueba más seria, pero sigue por debajo del objetivo limpio de 80 GB. Dos tarjetas de 24 GB requieren que el runtime distribuya el modelo sin una colocación manual frágil. Un equipo con mucha memoria unificada debe medirse con throughput real, temperatura y prompts reales, no solo capacidad total.
La línea de parada es práctica. Si el modelo carga pero el primer token tarda demasiado, no es una ruta interactiva. Si un prompt corto funciona y el documento real falla, falta validación. Si un usuario funciona y la concurrencia rompe la memoria, no es una ruta de servicio.
| Situación | Ruta sensata | Límite |
|---|---|---|
| Una GPU NVIDIA de 24 GB | Experimento offload o gpt-oss-20b | Si CPU/NVMe domina la latencia, no es producción 120B. |
| Dos GPU de 24 GB | Experimento avanzado | Detente si el placement es frágil o el runtime no soporta tu contexto. |
| GPU workstation de 48 GB | Prueba seria | Un demo corto no prueba el workload real. |
| Sistema con mucha memoria unificada | Prueba local | No sustituyas throughput medido por capacidad nominal. |
| CPU-only | Aprendizaje e inspección offline | No sirve para interacción o servicio compartido. |
La ruta de salida no es fracaso. 20B, cloud GPU y hosted access reducen la probabilidad de gastar una semana ajustando hardware marginal.
Hoja de validación antes de comprar o alquilar
La validación empieza con el trabajo real. Registra runtime, pool de memoria, longitud de contexto, batch o concurrencia, precisión o cuantización, prompts reales, telemetría y ruta de salida. La telemetría debe incluir pico de VRAM, RAM del sistema, swap, actividad NVMe, tokens/sec, time-to-first-token y punto de OOM.
Para alquilar, prueba exactamente el runtime y el context target que piensas usar. Para comprar, exige una prueba con tus documentos, llamadas de herramientas y carga simultánea. Si el objetivo es un asistente local privado, 20B puede ser mejor. Si el objetivo es evaluar 120B, cloud GPU reduce el riesgo. Si el objetivo es lanzar un servicio, hosted access puede ser la ruta más rápida.
La decisión final debe clasificarse como ruta: comprar 80 GB, probar el piso de 60 GB con límites, mantener 24 GB como laboratorio de offload, usar 20B, alquilar cloud GPU o usar hosted access. Un número sin ruta no protege de una compra equivocada.
| Paso | Qué anotar | Por qué |
|---|---|---|
| Runtime | Transformers, vLLM, Ollama, multi-GPU, offload, hosted | La memoria cambia por ruta. |
| Pool de memoria | VRAM, memoria unificada, RAM, disk offload | RAM sin precisión oculta el cuello de botella. |
| Context target | Chat corto, 32k, 64k, 128k o límite real | KV cache crece con contexto. |
| Batch/concurrency | Un usuario, batch tests, varios usuarios | Un request no prueba serving. |
| Precisión/cuantización | MXFP4, BF16, conversiones | La cifra depende de la representación cargada. |
| Prompts reales | Tools, documentos largos, código, chat corto | Los prompts de juguete esconden latencia. |
| Telemetría | Pico VRAM, RAM, swap, tokens/sec, OOM | La medición repetible supera la captura aislada. |
| Fallback | 20B, cloud GPU, hosted, contexto menor | La salida se decide antes del gasto. |
Después de medir, una respuesta honesta puede ser comprar 80 GB, alquilar primero, usar 20B localmente, bajar el contexto o no self-hostear todavía.
Preguntas frecuentes
¿Cuánta VRAM necesita GPT-OSS 120B?
Usa 80 GB de GPU como objetivo limpio para ejecución local seria. >=60GB es un piso limitado de algunas rutas MXFP4 y depende de runtime, contexto, batch, KV cache y overhead.
¿Puede correr GPT-OSS 120B en una GPU de 24 GB?
Trátalo como experimento con offload, no como despliegue limpio. CPU o NVMe pueden ayudar a cargar, pero la latencia y la fiabilidad cambian la promesa.
¿La RAM del sistema puede reemplazar la VRAM?
No. La RAM ayuda a buffers y offload, pero no equivale a la memoria rápida del acelerador.
¿Por qué aparecen 80 GB y 60 GB?
80 GB es el objetivo de hardware limpio. 60 GB es un piso de runtime limitado. Ambos necesitan contexto, batch y concurrencia para tener sentido.
¿GPT-OSS 20B requiere el mismo hardware?
No. gpt-oss-20b es la ruta pequeña de 16 GB. Para un asistente local privado puede ser más práctico que forzar 120B.
¿El contexto 128k funciona en cualquier configuración?
No. El contexto largo aumenta KV cache. Debes validar la longitud de contexto que vas a usar.
¿Conviene comprar H100, alquilar cloud GPU o usar hosted access?
Compra solo si el trabajo local 120B será repetido y justifica el hardware. Alquila para validar. Usa hosted cuando fiabilidad y entrega pesan más que operar infraestructura.
¿Sirven los reportes de Reddit sobre poca memoria?
Sirven como pistas de experimentos. No deben ser dueños del requisito. La frontera debe venir de documentación oficial, runtime y tu workload medido.