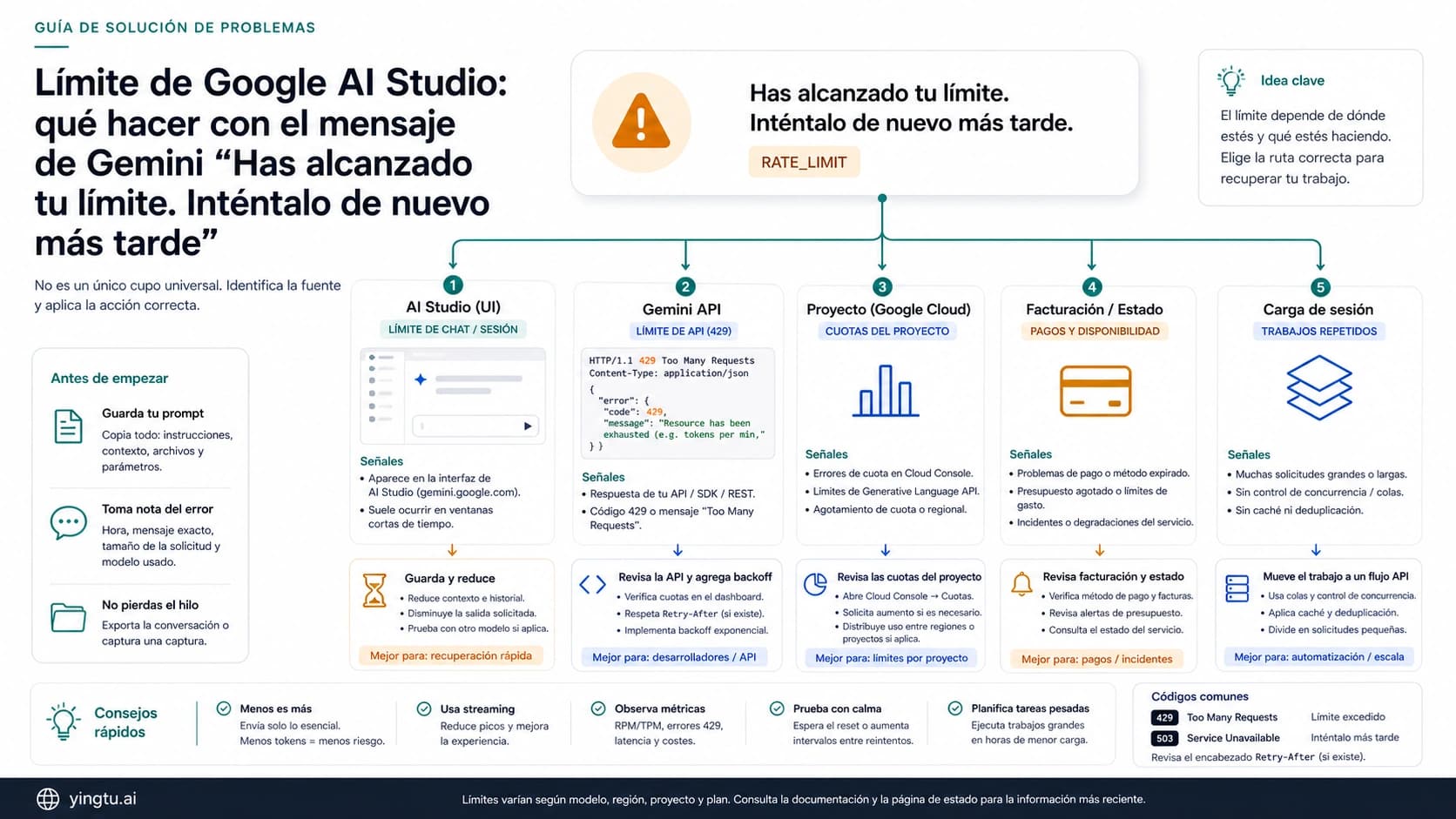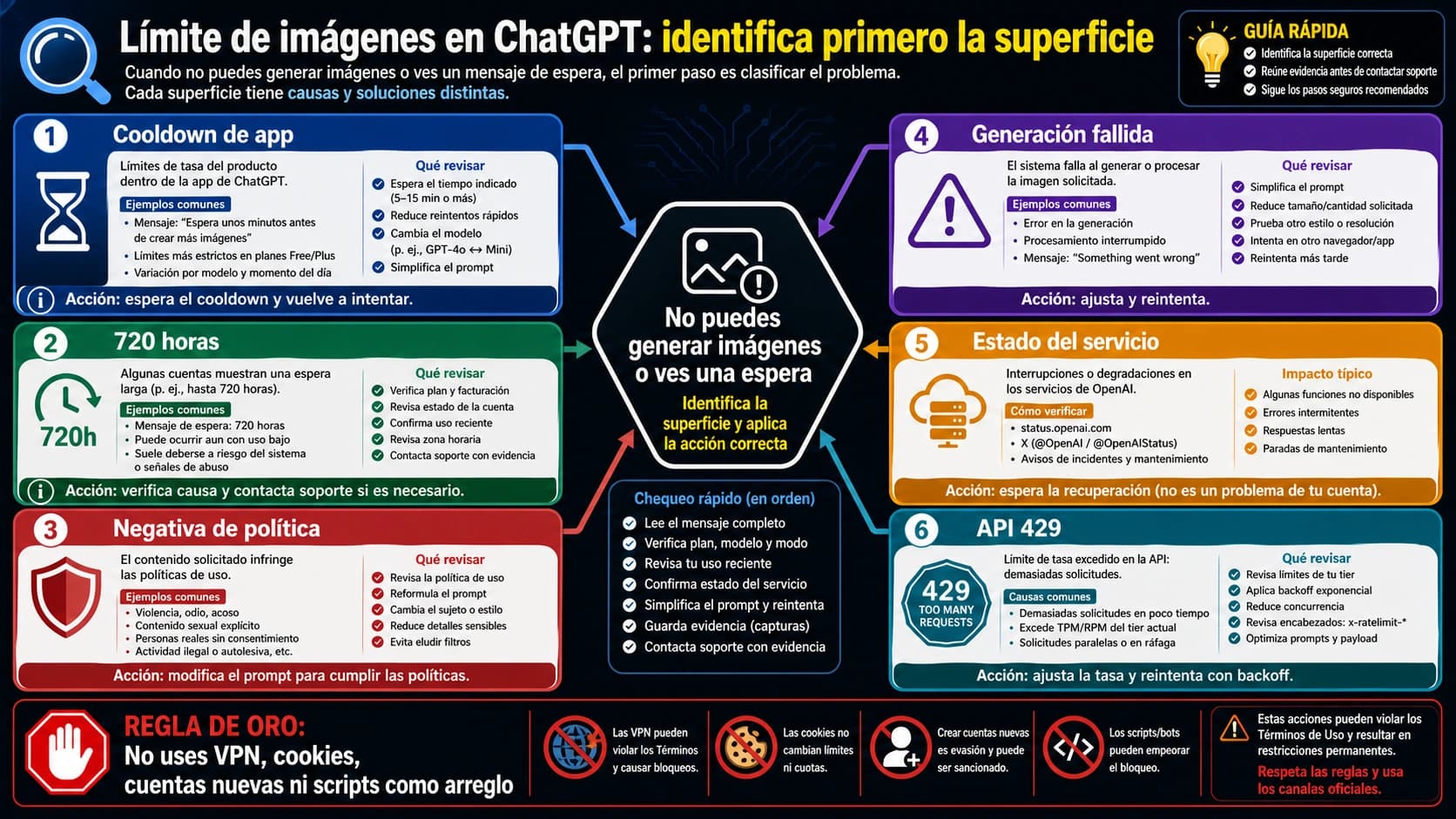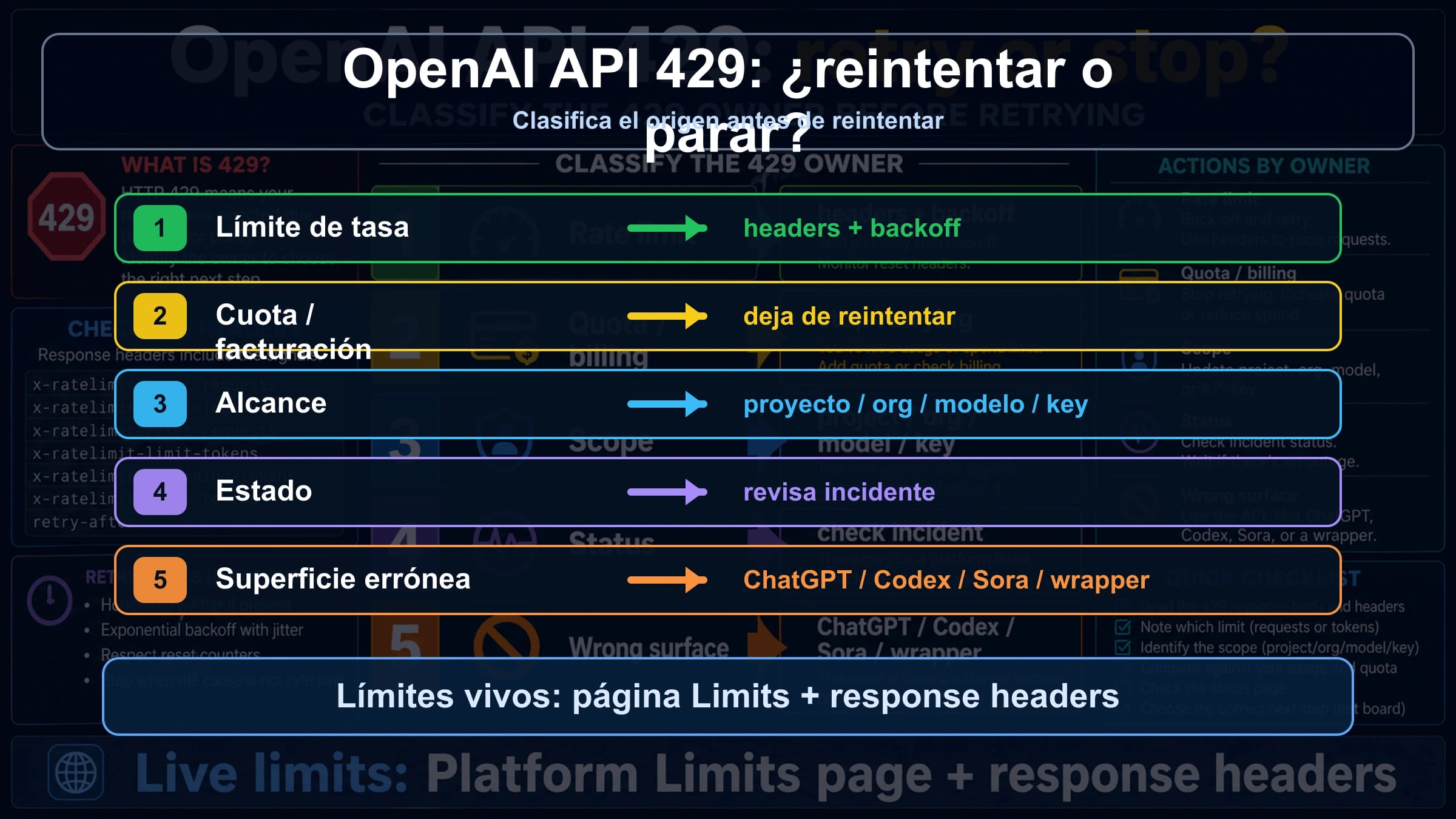
Si una llamada a OpenAI Platform API dice quota exceeded, insufficient_quota o devuelve 429, no aumentes los reintentos antes de leer el cuerpo. Un rate limit real necesita backoff, throttling o cola; cuota, billing, scope, model access, status incident o wrapper limit necesitan otra ruta.
| Pista | Causa probable | Primera comprobacion | Retry o stop |
|---|---|---|---|
rate limit reached, too many requests o remaining headers casi cero | request/token rate limit | headers, Limits, model family, reset window | retry con backoff y jitter, luego throttle o queue |
You exceeded your current quota o insufficient_quota | cuota, billing o spend cap | Billing, Usage, Limits, monthly spend, account state | stop hasta que cambie el estado |
| un key nuevo falla igual o solo falla un project/model | project, organization, model o key scope | project, organization, model access | arreglar scope antes de cambiar traffic |
| muchas llamadas fallan y Status muestra incidente | platform status o capacity | OpenAI Status, timestamp, request id | esperar y guardar evidencia |
| error desde ChatGPT, Codex, Sora, Azure o wrapper | wrong surface | product surface, provider docs, route, headers | usar ese contrato |
La regla de parada es clara: solo reintenta cuando la causa es presion de requests o tokens y existe una senal de reset. Si el cuerpo apunta a cuota, billing, proyecto equivocado, modelo equivocado, superficie equivocada o incidente, repetir la misma llamada no arregla nada.
Lee el cuerpo del 429 antes de cambiar codigo
La documentacion oficial de OpenAI separa al menos dos familias de 429: trafico que llega demasiado rapido y cuota actual agotada. En equipos de desarrollo suelen mezclarse en una sola frase, asi que la primera decision debe venir del cuerpo del error. Antes de cambiar la politica de retry, guarda message, code, type, endpoint, model, project, organization, timestamp y request id.
La clasificacion segura es conservadora. Si aparece insufficient_quota o wording de current quota, tratalo como stop por cuota o billing. Si el cuerpo dice rate limit o too many requests y los headers muestran remaining/reset, tratalo como presion retryable. Si ninguna rama es clara, mantén la ruta estable y junta evidencia en vez de cambiar cinco variables a la vez.
Esto importa en operaciones reales. Un 429 ambiguo invita a reparar lo equivocado: un retry loop estrecho puede consumir mas capacidad por minuto, un key nuevo puede ocultar que el mismo project sigue bloqueado, y un cambio de billing en otra organization puede no tocar el request de produccion.
Ruta de recuperacion en diez minutos
Usa los primeros diez minutos para clasificar el owner, no para experimentar al azar. Copia el raw body y los headers, abre Limits, Billing y Usage del mismo project y organization, confirma la model family, revisa OpenAI Status y luego envia un request controlado mas pequeno. Ese orden mantiene la evidencia legible.
| Tiempo | Accion | Que demuestra |
|---|---|---|
| 0-1 | Guardar body y headers | si la rama es rate, quota, billing o unknown |
| 1-3 | Revisar Limits, Usage y Billing | si la cuenta tiene capacity o problema de billing state |
| 3-5 | Comparar model y endpoint | si participa una model family mas estricta o compartida |
| 5-7 | Revisar OpenAI Status | si un public incident cambia la respuesta |
| 7-10 | Enviar un request controlado menor | si pesa mas workload size o account state |
Si el request pequeno funciona, investiga concurrency, token size, image throughput o fan-out. Si falla con quota wording, deja de reintentar. Si endpoints no relacionados fallan durante un incident declarado, conserva evidencia y espera en vez de rotar cuentas.
Cuando retry y backoff son correctos
Retry y backoff son correctos solo para presion temporal de requests o tokens. Las senales utiles son rate-limit wording, valores remaining bajos, reset timing y un patron de trafico que supera el budget actual del project/model. Retry no es una reparacion magica; es una herramienta de ritmo.
Usa exponential backoff con jitter, limita el retry count y agrega un limiter central por project y model family. Un limiter dentro de cada worker no basta si los workers no comparten estado. Estima token size antes de enviar, porque reducir prompt size o max output puede quitar presion de TPM antes de que la API rechace el request.
Los requests fallidos tambien pueden contar contra minute limits. Una flota que reintenta cada segundo puede mantenerse dentro de la ventana de fallo. Un buen sistema baja velocidad, usa queue, descarta trabajo no urgente o usa Batch para trabajo async.
Cuando seguir reintentando es un error
Retry es incorrecto cuando el error apunta a insufficient_quota, current quota, billing, monthly spend o account state. Esperar unos segundos no agrega cuota. La ruta correcta es Billing, Usage, Limits, spend cap, organization, project y model access.
Muchos casos de "tengo creditos pero sigo con 429" son problemas de scope. El credito puede estar en otra organization, el request puede usar otro project, un monthly spend cap puede seguir activo, el model puede no estar disponible para ese project o un wrapper puede aplicar su propio pool. Mantén un request minimo estable mientras revisas cada scope.
Por que un nuevo API key puede no ayudar
Un API key no es un bucket separado de capacidad. Un key nuevo ayuda cuando el anterior fue revocado, filtrado, restringido o asociado al wrong project. No crea capacidad si organization, project, model family y billing owner siguen iguales.
| Scope | Que revisar | Patron de fallo |
|---|---|---|
| Organization | que el request use la org correcta | personal org y team org tienen billing o limits distintos |
| Project | que el key pertenezca al project inspeccionado | miraste Limits en un project y el trafico sale de otro |
| Model family | que el selected model tenga access y headroom | se agoto un family limit mas estricto o compartido |
| Team workload | que otros servicios compartan capacity | un batch job u otra app consume el pool |
Si solo falla un model, prueba un request pequeno a un model que el project pueda usar. Si todos los models fallan con quota wording, revisa account state primero. Si el key funciona en otro servicio, mira concurrency y request shape en el servicio que falla.
Usa headers y Limits como evidencia viva
La evidencia viva esta en la response y en la cuenta. El body da la rama. Los headers pueden mostrar limit, remaining y reset timing. La pagina Limits da el contexto actual de project, organization y model. Cualquier tabla estatica es mas debil que la evidencia live de la propia cuenta.
| Evidencia | Por que importa |
|---|---|
| status y body | separa rate pressure retryable de quota o billing |
| request id | da a soporte un handle de busqueda |
| rate-limit headers | muestra limit, remaining y reset timing |
| project y organization | confirma quien posee el request |
| model y endpoint | expone model limit estricto o wrong endpoint |
| Limits y Usage state | registra account state durante el fallo |
| Status snapshot | separa incident de fallo local de cuenta |
El 2026-04-29 la revision publica de OpenAI Status no mostraba un active incident amplio. Eso no garantiza salud futura. Durante tu propio incident, revisa Status en vivo; si esta green, sigue con account scope, headers y workload shape.
Reduce el proximo 429 en produccion
Despues de la recuperacion inmediata, lleva la leccion a production controls. La aplicacion debe conocer su budget antes de que OpenAI la rechace: project/model limiters, tenant budgets, token estimates, queue alerts, retry counters y observaciones de reset-window.
El trafico interactivo y los background jobs no deben competir a ciegas. Pon en queue lo no urgente, separa tenants, reduce prompt size cuando sea posible y enruta trabajo simple a models mas baratos o con menos pressure cuando sea una decision de producto aprobada. Usa Batch cuando la latencia no sea urgente y el workload encaje.
Descarta primero la superficie equivocada
"OpenAI API 429" debe significar una llamada Platform API hecha por codigo. ChatGPT, Codex, Sora, Azure OpenAI y wrappers tambien pueden mostrar limit messages, pero el owner y el fix son distintos.
| Surface | No asumas | Revisa en cambio |
|---|---|---|
| ChatGPT | consumer plan cambia API quota | ChatGPT product limits y account state |
| Codex | coding-agent limits equivalen a API RPM/TPM | Codex product contract y status |
| Sora | video capacity equivale a text API limits | Sora route, queue, plan y video status |
| Azure OpenAI | OpenAI Platform Limits gobierna deployment | Azure quota, deployment, region y subscription |
| Wrapper | OpenAI headers siempre pasan intactos | provider dashboard, docs, route id y upstream evidence |
Si el request no va directo a api.openai.com, identifica primero el provider boundary. El wrapper puede estar lleno, traducir un upstream 429 o aplicar su propio account cap.
Escala con evidencia limpia
Escala solo cuando la rama este estable y los secretos esten fuera. Un packet compacto debe incluir timestamp, timezone, request id, endpoint, model, SDK version, organization, project, billing owner, body seguro, headers seguros, Limits/Usage state, Status state, retry count, concurrency, prompt size, queue depth y recent changes.
No publiques API keys, bearer tokens, card details, private prompts ni user data en lugares publicos. La evidencia limpia es mas rapida para soporte y mas segura para usuarios.
Preguntas frecuentes
Todos los 429 de OpenAI API son retryables?
No. Retry solo corresponde cuando el cuerpo y headers apuntan a presion temporal de requests o tokens. insufficient_quota exige Billing, Usage, Limits, project, organization y model access.
Que significa insufficient_quota?
Significa cuota, billing, spend cap o account state, no un pico de trafico que se arregla esperando segundos.
Por que aparece 429 si ya agregue credito?
Puede ser otro organization/project, spend cap, billing state pendiente, model access, shared family limit o un wrapper con su propia cuota.
Varios API keys aumentan el limite?
No si pertenecen al mismo project y organization. Un key nuevo arregla credenciales, no crea una cuota nueva.
Que headers debo mirar?
Los headers de limit, remaining y reset para requests/tokens cuando esten presentes, junto con la pagina Limits.
Debo mirar OpenAI Status?
Si. Un incidente cambia la respuesta a esperar y guardar evidencia; si esta verde, sigue con account, headers, Limits y workload.
ChatGPT Plus comparte cuota con la API?
No. ChatGPT consumer plans y OpenAI Platform API billing son superficies distintas.
Que envio a soporte?
Timestamp, timezone, request id, endpoint, model, project, organization, safe error body, safe headers, Limits/Usage, Status, retry count, workload y cambios recientes.
Plantilla de revision operativa
Registra cada 429 con el mismo formato: hora, zona horaria, endpoint, modelo, proyecto, organizacion, error body, headers, Limits, Usage, Billing, Status, retry count, concurrencia, tamano de prompt, cola y cambios recientes. Ese formato evita discutir si "parece limite" y obliga a separar rate pressure, cuota, billing, scope, status y provider route.
En la retrospectiva pregunta tres cosas. Que rama dio la primera senal fuerte? Cambiamos key, model, project o billing antes de guardar evidencia? Que control de produccion deberia actuar antes del rechazo de la API: central limiter, tenant budget, token estimate, queue, Batch o alerta por remaining/reset? Con esas respuestas, el siguiente 429 sera mas corto y menos costoso.