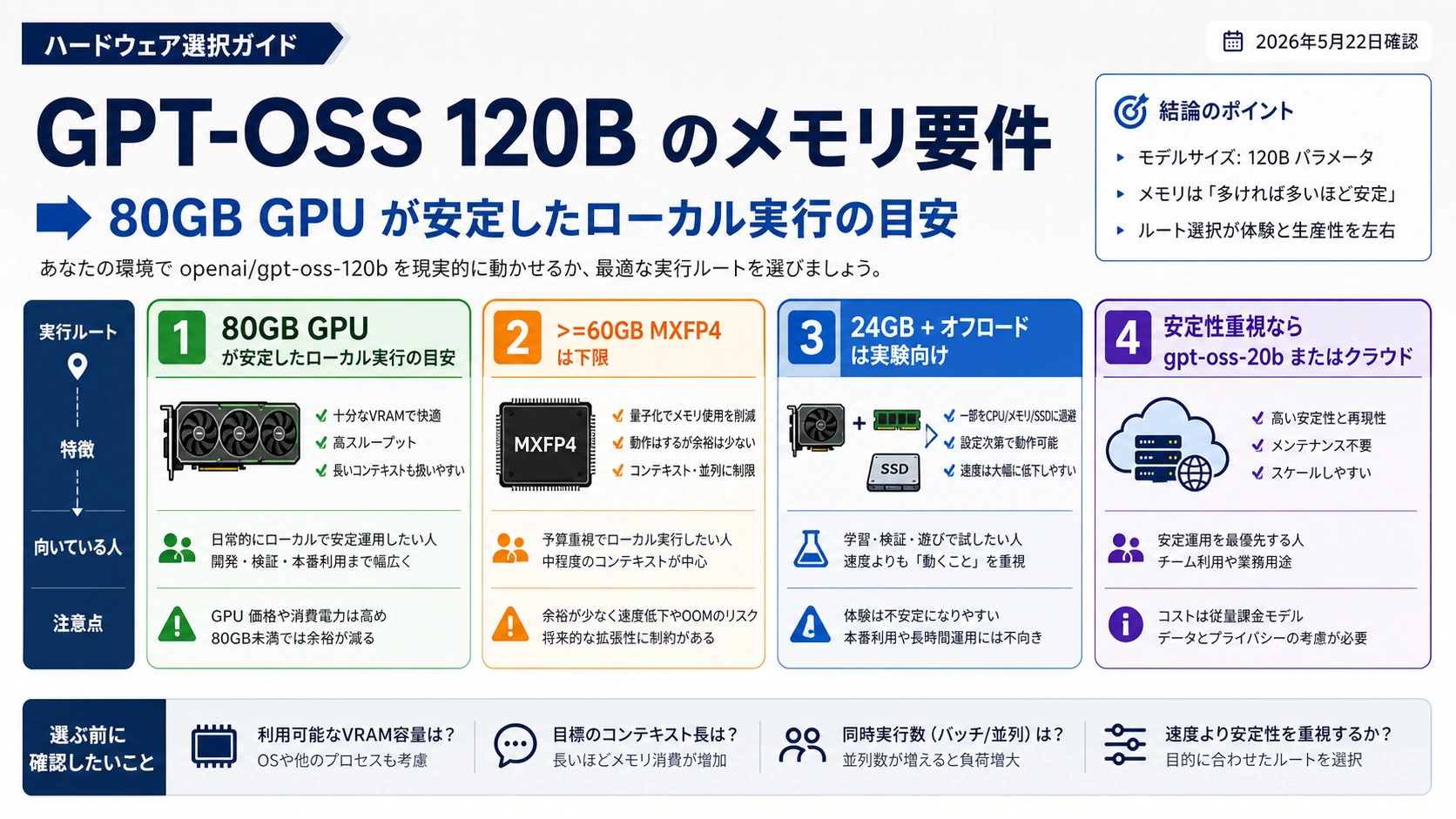
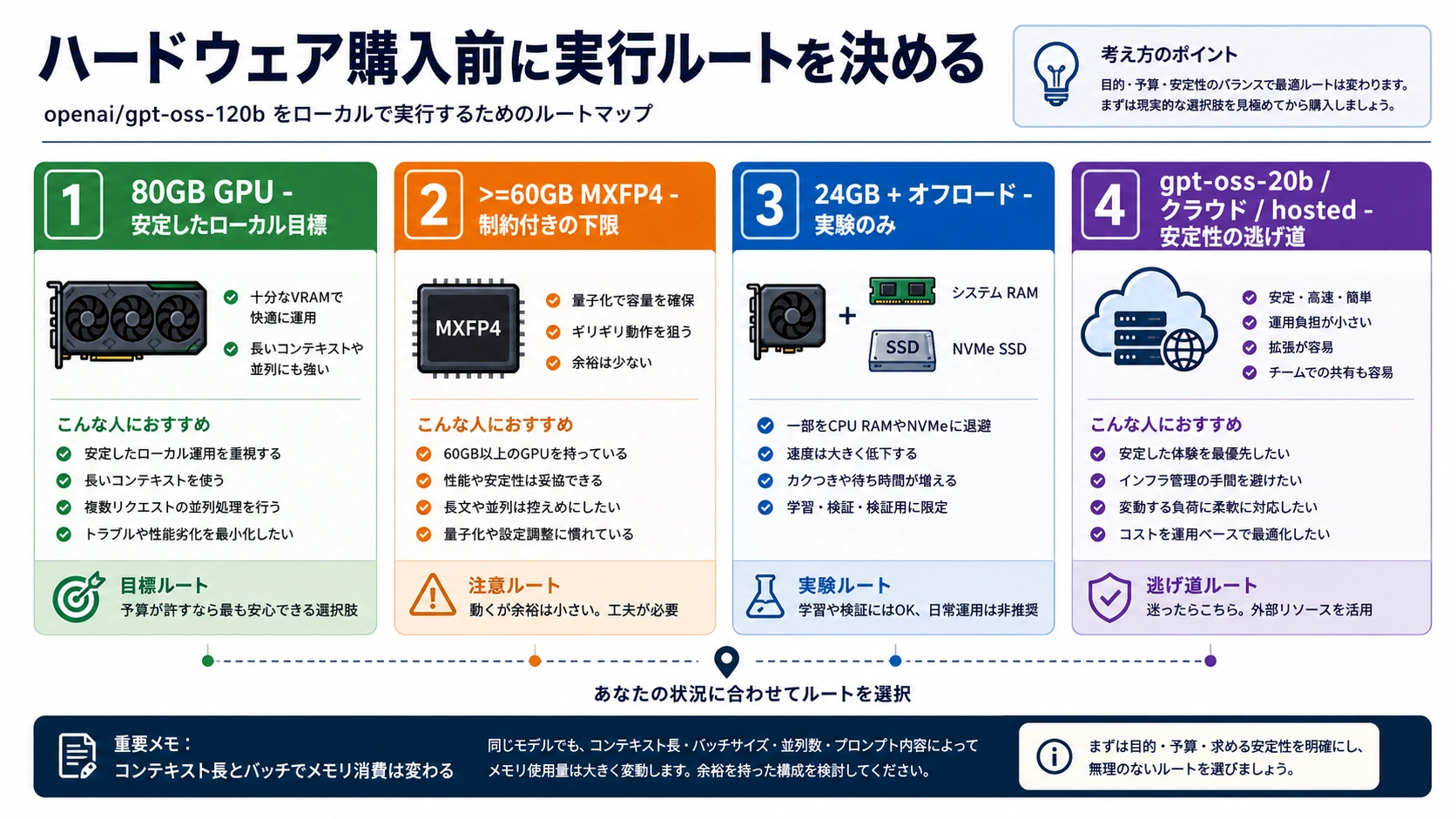
gpt-oss-120b を安定してローカル実行したいなら、まず 80GB GPU クラスのモデルとして計画します。>=60GB は MXFP4 対応 runtime での制約付き下限であり、余裕のある運用枠ではありません。24GB GPU に CPU や NVMe offload を足す構成は、学習や検証には使えても、本番用の 120B ローカル計画とは分けて扱うべきです。速度、長い文脈、同時利用、再現性を重視するなら、gpt-oss-20b、クラウド GPU、hosted access も同時に比較します。
| 実行ルート | 扱い方 | 実務上の意味 |
|---|---|---|
| 80GB クラスのサーバー GPU | 安定したローカルルート | 120B を本気で試す、または内部利用する時の基準。 |
>=60GB VRAM またはユニファイドメモリ | 制約付き下限 | 対応 runtime なら可能性はあるが、context、batch、overhead の余裕は小さい。 |
| 24GB GPU + CPU/NVMe offload | 実験ルート | モデル形式や prompt を学ぶ用途。運用計画としては弱い。 |
gpt-oss-20b、クラウド GPU、hosted access | 退避ルート | ローカルメモリ、速度、安定性が制約なら最短の選択肢になりやすい。 |
総 RAM の数字、1件の成功報告、短いデモだけで購入を決めないでください。必要なのは、あなたの runtime、context length、batch、同時利用数で同じ条件を再現できるかどうかです。
実行ルートを先に決める
GPT-OSS 120B のメモリ要件は、単独の数字ではなく実行ルートに紐づく判断です。OpenAI のモデル資料では gpt-oss-120b は 117B parameters、5.1B active parameters、長い context window を持つ open-weight model として扱われ、80GB GPU クラスでのローカル実行が読み取りやすい基準になります。これは購入やレンタルの安全な出発点です。
ただし、同じ 80GB でも runtime、driver、kernel、context、batch の条件で挙動は変わります。短い prompt が返ること、モデルが load できること、長い文書を処理できること、チームで同時に使えることは別の検証です。まず目的を、短いローカル chat、120B 評価、長文処理、内部サービス、または product delivery に分けます。
目的が private local assistant なら gpt-oss-20b が実用的な場合があります。120B の能力評価が目的なら cloud GPU を短時間借りる方が購入リスクを下げます。長期的に 120B をローカルで何度も使う根拠がある時だけ、80GB クラスの所有が合理的になります。
ルートを先に決めると、load 成功と運用成功を分けて考えられます。後者には速度、context、同時利用、保守の余裕が必要です。
80GB と 60GB が同時に出てくる理由
80GB と >=60GB は同じ質問への競合回答ではありません。80GB は、余裕をもってローカル 120B を扱うための安定基準です。>=60GB は、MXFP4 と対応 runtime を前提にした下限で、context や batch を絞った時の入り口です。
OpenAI の Transformers、vLLM、Ollama 系の資料でも、この違いが現れます。Transformers は直接試せる Python ルートですが、hardware support と precision に左右されます。vLLM は serving に近く、max model length や batched tokens の設定がメモリに効きます。Ollama や desktop runner は始めやすい一方、VRAM または unified memory という表現をそのまま全マシンへの保証にしてはいけません。
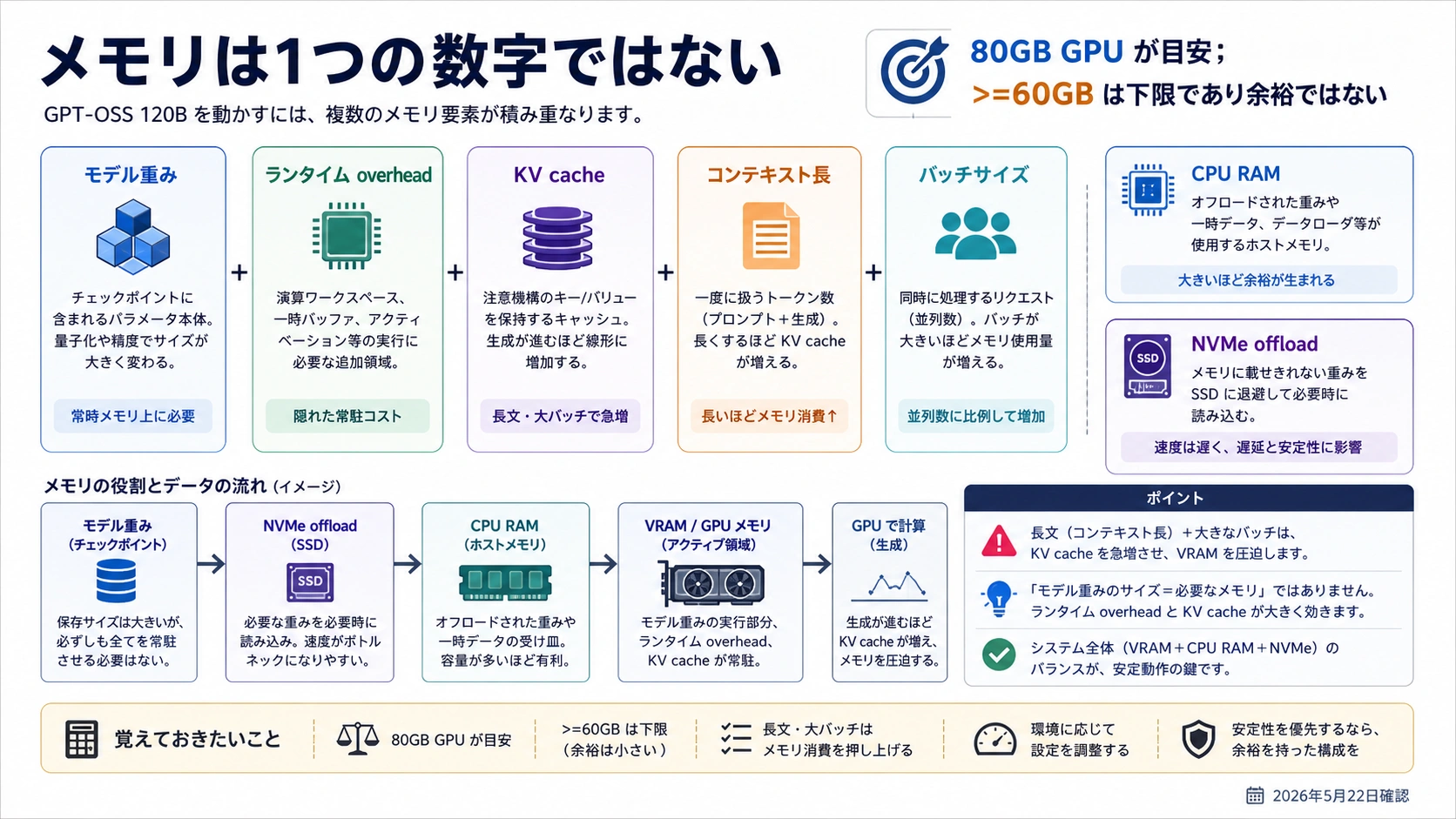
モデルファイルの大きさだけでは runtime memory は決まりません。allocator の予約、temporary buffers、KV cache、長い context、複数 request、multi-GPU sharding が重なります。60GB で load できても、あなたの実際の context と同時実行で余裕がないなら、購入判断としてはまだ不十分です。
VRAM、ユニファイドメモリ、RAM、ディスク、KV cache を分ける
VRAM は GPU 上の高速メモリで、weights、runtime state、KV cache の一部を支えます。ユニファイドメモリは一部のシステムで CPU/GPU が共有する領域ですが、容量だけでなく速度、熱、runtime の使い方を確認する必要があります。システム RAM は OS、tokenizer、offload buffers、background tasks を支えますが、高速 VRAM にはなりません。
NVMe offload は、load できる範囲を広げる一方で latency を悪化させます。interactive chat、long-context reasoning、team serving では、disk movement が増えた時点で別の仕事になります。KV cache も見落とせません。context length と同時 request が増えるほど、weights 以外のメモリが効いてきます。
そのため、購入前のメモには「VRAM 何 GB」「system RAM 何 GB」「unified memory の実効」「disk offload の有無」「想定 context」「batch/concurrency」を別々に書きます。単に総メモリが大きい machine ではなく、どの pool がどの役割を持つかを決めることが重要です。
| メモリ項目 | gpt-oss-120b での意味 | 判断への影響 |
|---|---|---|
| VRAM | GPU 上で weights、runtime state、KV cache を支える高速メモリ | clean single-device target は 80GB クラス。 |
| ユニファイドメモリ | 一部システムの共有メモリ | 60GB 以上でも速度と余裕は実測する。 |
| システム RAM | OS、runtime、offload buffers、background tasks | 実験を助けるが VRAM ではない。 |
| Disk/NVMe offload | 一部状態を storage 経由で動かす | load 可能でも latency が問題になる。 |
| KV cache | active context を保持する生成時メモリ | 長い context と同時利用で増える。 |
| batch/concurrency | 同時に処理する token や request | service use は single chat より余裕が必要。 |
この分解をしておくと、system RAM だけを増やして VRAM 不足を解決したつもりになる誤解を避けられます。
runtime ごとに必要な余裕は変わる
runtime はメモリの使われ方を変えます。Transformers は実験に向きますが、kernel が合わない、precision が変わる、unsupported path に落ちると、必要メモリも速度も変わります。vLLM は serving 向けで、max model length、tensor parallelism、batch tokens、KV cache policy を調整しないと、load 後に余裕が消えます。
Ollama や desktop app は最初の体験が簡単です。ただし、ローカルで動くことと、長い context で快適に使えることは別です。multi-GPU も同じで、24GB GPU を複数枚足した合計だけでは判断できません。interconnect、manual placement、driver、sharding、runtime support が弱ければ、調整時間が膨らみます。
cloud GPU は検証ルートとして強いです。H100 クラスを短く借りて、実際の prompt、context、同時実行、tokens/sec を測ると、購入すべきか、20B で足りるか、hosted route にすべきかが見えます。
consumer GPU の停止条件
24GB GPU は実験用として扱うのが安全です。CPU や NVMe offload を使えば load できる可能性はありますが、latency、context、reliability が変わります。prompt を試す、tool behavior を見る、model format を理解する用途なら価値があります。長い文書やチーム利用の土台には向きません。
48GB workstation GPU はより現実的な test route ですが、80GB の安定基準には届きません。2枚の 24GB、3枚の 24GB、Apple unified memory も、総容量ではなく runtime がその形を安定して使えるかで判断します。
停止条件は明確です。短い demo が通っても、本番 prompt が落ちるなら未検証です。load できても first token が遅すぎるなら interactive ではありません。単独 request が通っても batch や同時利用で OOM になるなら、service route ではありません。
| ハードウェア | 現実的なルート | 停止条件 |
|---|---|---|
| 24GB GPU 1枚 | offload 実験または gpt-oss-20b | CPU/NVMe movement が主役なら production 120B ではない。 |
| 24GB GPU 2枚 | advanced experiment | manual placement が脆いなら止める。 |
| 48GB workstation GPU | serious test route | 短い demo だけでは実 workload を証明しない。 |
| 高容量 unified memory | local test route | 容量だけで throughput を代替しない。 |
| CPU-only | 学習と offline inspection | interactive や service には向かない。 |
退避ルートを持つことは弱さではありません。20B、cloud GPU、hosted access を先に決めておくと、境界ぎりぎりの hardware に時間を吸われにくくなります。
購入やレンタル前の検証チェックリスト
検証は benchmark screenshot ではなく workload から始めます。runtime、hardware memory pool、context target、batch/concurrency、precision/quantization、real prompt set、telemetry、fallback を順番に書きます。telemetry には peak VRAM、system RAM、swap、NVMe activity、tokens/sec、time-to-first-token、OOM point を含めます。
レンタルなら、同じ runtime と同じ context target で proof session を走らせます。購入なら、短い sample ではなく、実際に使う文書長、tool calls、複数 request を試します。20B が十分なら、低コストで安定します。120B 評価なら、cloud GPU が早いです。delivery が先なら hosted access で infrastructure ownership を後回しにできます。
結論は「何 GB 必要か」では終わりません。80GB を買う、60GB で制約付きに試す、24GB は offload lab に留める、20B を選ぶ、cloud GPU を借りる、hosted に逃がす。この分岐を決めてから hardware budget を動かします。

| 手順 | 記録する内容 | 理由 |
|---|---|---|
| Runtime | Transformers、vLLM、Ollama、multi-GPU、offload、hosted | 同じモデルでも memory behavior が変わる。 |
| Memory pool | VRAM、unified memory、system RAM、disk offload | RAM だけでは bottleneck が見えない。 |
| Context target | short chat、32k、64k、128k、実際の上限 | KV cache が余裕を消す。 |
| Batch/concurrency | 1人、batch test、multi-user serving | single request だけでは足りない。 |
| Precision/quantization | MXFP4、BF16、runtime conversion | memory claim は表現形式に依存する。 |
| Real prompts | tools、long docs、code、short chat | toy prompt では遅延が隠れる。 |
| Telemetry | peak VRAM、RAM、swap、tokens/sec、OOM point | 再現性が screenshot より強い。 |
| Fallback | 20B、cloud GPU、hosted、shorter context | 逃げ道を先に決める。 |
この検証の後で、80GB を買う、cloud GPU を借りる、20B を選ぶ、context を短くする、self-host を見送る、という判断が自然に出ます。
よくある質問
GPT-OSS 120B に必要な VRAM は?
安定したローカル実行なら 80GB GPU クラスを基準にします。>=60GB は一部 MXFP4 runtime の制約付き下限で、context、batch、KV cache、overhead に左右されます。
24GB GPU で GPT-OSS 120B は動きますか?
offload 実験としては可能性があります。CPU や NVMe を使うと load は近づきますが、latency と reliability は別物になります。
システム RAM が多ければ VRAM 不足を補えますか?
補助にはなりますが代替にはなりません。system RAM は offload や buffers に効きますが、GPU VRAM と同じ速度ではありません。
80GB と 60GB の違いは何ですか?
80GB は安定したローカル基準、60GB は一部 runtime の制約付き下限です。どちらも context、batch、concurrency を合わせて判断します。
GPT-OSS 20B も同じスペックが必要ですか?
いいえ。gpt-oss-20b は 16GB クラスの小さいローカルルートです。local assistant 用途では 20B の方が現実的なことがあります。
128k context はどの環境でも使えますか?
使えません。長い context は KV cache を増やします。実際に使う context length で検証してください。
H100 を買うべきか、クラウドを借りるべきか?
継続的なローカル 120B 利用があるなら購入を検討します。評価段階なら cloud GPU、delivery 優先なら hosted route が先です。
掲示板の低メモリ成功例は信用できますか?
実験の参考にはなります。購入判断では official docs と自分の workload proof を優先してください。