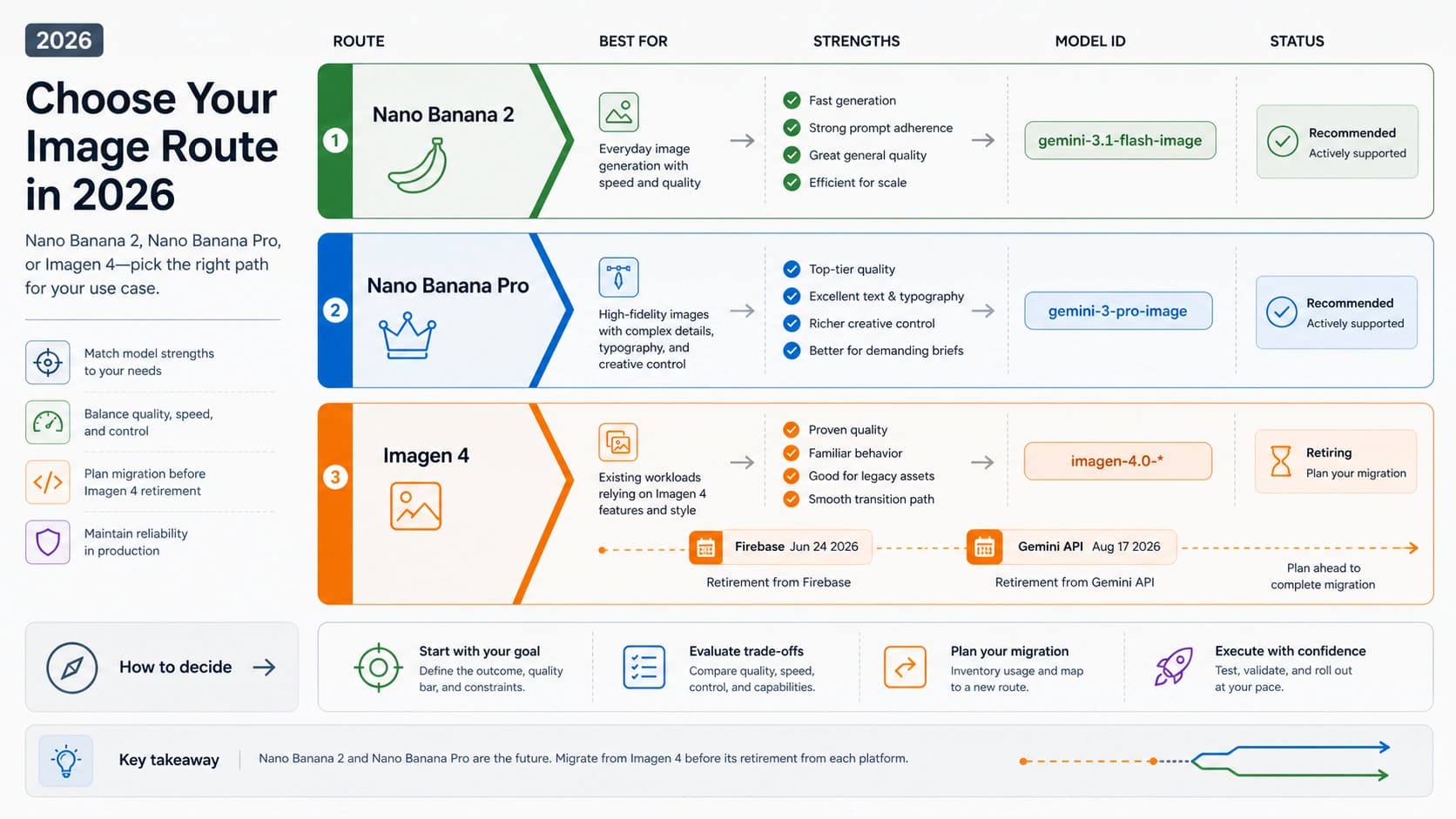
2026년 5월 8일 기준 DeepSeek V4 Preview는 공식 공개된 상태입니다. DeepSeek의 4월 24일 릴리스는 V4 Preview가 공식적으로 공개되고 오픈 웨이트로 제공된다고 말하며, API에서는 deepseek-v4-pro와 deepseek-v4-flash라는 명확한 model ID를 제공합니다. 그래서 실제 질문은 출시 여부가 아니라 어떤 경로와 어떤 모델부터 검증할지입니다.
| 경로 | 먼저 쓸 때 | 운영 전 확인할 것 |
|---|---|---|
| App / Chat | 빠르게 모델 감을 보고 싶을 때 | 기능 제한, 개인정보 경계, API로 재현되는지 |
| 공식 API | DeepSeek의 hosted contract와 model ID가 필요할 때 | Pro/Flash, 1M 컨텍스트, 384K max output, 가격 확인일, streaming, thinking mode |
| Hugging Face | 오픈 웨이트 제어권이나 연구가 필요할 때 | 하드웨어, serving stack, 라이선스, recall, latency, 공식 API와의 차이 |
| Provider | 기존 gateway, 결제, 지역 경로가 필요할 때 | provider 가격, quota, routing, log, fallback, 지원 정책 |
| 로컬 실행 | 최대 제어, 보안 민감 pilot, offline 성격이 있을 때 | GPU, 메모리, KV cache, 운영, 모니터링, 평가셋 |
첫 선택 기준은 명확해야 합니다. 대량이고 자동 검증이 가능하며 latency와 비용이 중요한 작업은 deepseek-v4-flash부터 봅니다. 복잡한 추론, 코드, Agent, 장문 종합, 사람이 고치는 비용이 큰 작업은 deepseek-v4-pro부터 봅니다. deepseek-v4-preview를 model ID로 쓰지 말고, 1M 컨텍스트를 곧바로 안정적인 장문 이해로 해석하지 않아야 합니다.
공식 발표가 확정하는 것
DeepSeek의 2026년 4월 24일 릴리스는 V4 Preview가 officially live이며 open-sourced라고 설명합니다. DeepSeek-V4-Pro는 1.6T total parameters와 49B active parameters, DeepSeek-V4-Flash는 284B total과 13B active로 표시됩니다. 두 모델 모두 1M 컨텍스트와 thinking / non-thinking mode가 핵심 표면입니다.
이 사실만으로 운영 선택이 끝나지는 않습니다. 구현 판단에서는 provider 통합 글, API 리뷰, 커뮤니티 반응, 오픈 웨이트 소개가 서로 다른 계약이라는 점을 분리해야 합니다. DeepSeek 문서는 first-party API와 릴리스 사실을, Hugging Face는 weights와 license를, provider 자료는 provider 자체 계약만을 증명합니다.
이미 DeepSeek 연동이 있다면 먼저 route owner를 정리해야 합니다. 어떤 서비스가 공식 API를 쓰는지, 어디가 gateway나 provider를 거치는지, 어느 config에 deepseek-chat 또는 deepseek-reasoner가 남았는지, 로컬 실험이 운영과 섞였는지를 확인합니다. 이 작업 없이 model ID만 바꾸면 가격, 로그, fallback, 지원 경계 변화가 숨어버립니다.
Pro와 Flash 차이는 성능 서열 하나로 정리할 수 없습니다. Flash는 측정 가능한 대량 처리에서 빠르게 실패를 걸러내는 경로이고, Pro는 실패 비용이 큰 어려운 경로입니다. 비용 판단도 token price가 아니라 accepted-output cost, 즉 재시도와 사람 검토까지 포함한 실제 통과 비용으로 봐야 합니다.
Flash와 Pro를 어떻게 나눌까
Flash는 분류, 추출, 문서 screening, 구조화 JSON, 대량 요약, 라우팅, 낮은 위험의 초안 생성처럼 acceptance check가 분명한 일에 먼저 넣습니다. schema, 테스트셋, 샘플 리뷰, 두 번째 검증 모델이 있다면 Flash의 저비용과 throughput으로 더 넓게 측정할 수 있습니다.

Pro는 약한 답변 하나가 큰 손실로 이어지는 일을 먼저 맡깁니다. coding agent, multi-file debugging, 설계 판단, 장문 리포트 종합, tool-heavy workflow, 서로 먼 증거를 결합하는 작업에서는 token 차이보다 실패 후 수리 시간이 큽니다. Pro가 재시도와 리뷰를 줄이면 더 비싼 모델이 실제로는 더 낮은 통과 비용을 만들 수 있습니다.
| 작업 | 첫 테스트 | 이유 |
|---|---|---|
| 대량 분류와 태깅 | deepseek-v4-flash | 실패를 규칙이나 샘플링으로 잡기 쉽다 |
| 문서 screening | deepseek-v4-flash | throughput과 비용이 우선이다 |
| 코드 Agent | deepseek-v4-pro | 잘못된 답이 개발 시간을 크게 낭비한다 |
| 장문 종합 | 쉬운 문서는 Flash, 어려운 문서는 Pro | 모든 요청에 Pro 비용을 지불하지 않는다 |
| tool calling | 같은 schema로 둘 다 비교 | 인자 안정성은 실제 workflow마다 다르다 |
API ID와 기존 alias
새로운 코드에는 deepseek-v4-pro 또는 deepseek-v4-flash를 명시해야 합니다. 릴리스는 deepseek-chat과 deepseek-reasoner가 compatibility aliases이며 2026-07-24 15:59 UTC 이후 접근 불가가 될 예정이라고 설명합니다. 이 alias들은 기존 client의 완충 장치일 뿐, 새 운영 설정의 중심 이름이 아닙니다.

OpenAI-compatible client를 쓴다면 DeepSeek 공식 base URL은 https://api.deepseek.com입니다. 이것은 공식 API의 진입점이지 provider의 가격, fallback, log, quota를 보장하지 않습니다. 운영 config에는 model ID, route owner, 가격 확인일, streaming, JSON/tool 요구사항, thinking mode와 rollback 계획을 분리해 남겨야 합니다.
hljs tsimport OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: "https://api.deepseek.com",
});
const response = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [{ role: "user", content: "Summarize the document and cite evidence lines." }],
stream: true,
max_tokens: 4096,
});
가격은 날짜와 함께 다뤄야 한다
2026년 5월 8일 기준 DeepSeek pricing 페이지는 deepseek-v4-flash에 대해 cache hit input $0.0028, cache miss input $0.14, output $0.28 per 1M tokens를 표시합니다. deepseek-v4-pro는 할인 중 cache hit input $0.003625, cache miss input $0.435, output $0.87이고, 원래 행은 $0.0145, $1.74, $3.48입니다. DeepSeek는 V4-Pro 75% 할인이 2026-05-31 15:59 UTC까지 연장된다고 적고 있습니다.
가격은 변동 사실입니다. Provider가 다른 가격, 크레딧, 지역 라우팅, 로그, fallback, quota, 지원 정책을 제공한다면 그건 provider 계약입니다. 공식 API 가격을 인용할 때는 DeepSeek 문서를 쓰고, provider 가격은 별도 경로로 표시해야 합니다.
1M 컨텍스트 검증 방법
1M 컨텍스트는 긴 입력을 받을 수 있다는 능력이지 결과 품질 보장이 아닙니다. 먼 위치의 사실 회수, 여러 구간의 증거 결합, 충돌 처리, latency, timeout, 384K max output, 재시도율, accepted-output cost를 봐야 합니다. 특히 긴 문서의 앞부분만 근거로 답하고 중간이나 끝의 반례를 놓치는지 확인해야 합니다.

| 검증 | 증명하는 것 | 실패 신호 |
|---|---|---|
| 입력 수용 | 목표 길이를 넣을 수 있는지 | reject, truncation, timeout |
| 먼 위치 recall | 중간과 끝의 사실을 회수하는지 | 앞부분만 인용 |
| 장거리 추론 | 여러 증거를 합치는지 | 한 구간만 보고 결론 |
| latency | SLA에 맞는지 | p95나 timeout이 높다 |
| output 경계 | 384K max output을 다루는지 | 답이 끊기거나 비대해짐 |
| route 안정성 | Preview/provider 차이를 관리하는지 | 경로 변경 후 결과 drift |
오픈 웨이트, Provider, 로컬 실행
DeepSeek의 verified Hugging Face collection에는 Pro, Pro-Base, Flash, Flash-Base가 있습니다. model card는 Preview series, MoE 구조, 1M context, thinking modes, MIT license를 보여줍니다. 이것은 오픈 웨이트 가용성의 근거지만, 로컬 환경이 공식 API와 같은 latency, context 처리, tool behavior를 갖는다는 뜻은 아닙니다.
로컬 실행은 무료 hosted API가 아니라 runtime 책임 이전입니다. GPU, 메모리, KV cache, serving stack, batching, monitoring, 보안, 업데이트, 평가를 직접 운영합니다. Provider 경로도 별도 계약이므로 공식 API 테스트 결과가 그대로 이전된다고 보면 안 됩니다. 같은 평가셋으로 다시 확인해야 합니다.
로컬 평가는 처음부터 1M 전체를 목표로 삼기보다 32K, 128K, 256K, 더 긴 문서 순서로 늘리는 편이 안전합니다. 각 단계에서 메모리, p95 latency, 먼 위치 recall, 출력 채택률, retry율을 기록해야 모델 한계와 serving stack 한계를 분리할 수 있습니다.
GPT 비교가 필요한 경우
DeepSeek V4 Preview 내부 선택이라면 공식 상태, API ID, Pro/Flash, 1M 검증, 오픈 웨이트, provider, 로컬 실행을 결정하면 됩니다. OpenAI와 DeepSeek 중 무엇을 채택할지 비교하는 단계라면 GPT-5.5 vs DeepSeek-V4를 봐야 합니다.
운영 전 체크리스트
deepseek-v4-flash또는deepseek-v4-pro를 config에 고정한다.- route owner를 official API, provider, Hugging Face, local serving으로 기록한다.
- 같은 prompt/eval set으로 Flash와 Pro를 비교한다.
- 1M이 전환 이유라면 먼 위치 recall과 장거리 추론 테스트를 넣는다.
- token 단가가 아니라 accepted-output cost를 본다.
- streaming, JSON, tools, thinking mode는 실제 사용 지점에서만 테스트한다.
deepseek-chat과deepseek-reasoner잔존 서비스를 alias 종료 전 찾는다.- 가격, 할인, provider 조건, 가용성 주장은 공개 전 다시 확인한다.
평가셋은 세 층으로 유지하는 것이 좋습니다. 일반 회귀셋은 모델 업데이트와 provider 차이를 잡습니다. 장문셋은 lost-middle, 먼 위치 recall, 출력 절단을 봅니다. 고실패비용셋은 Flash에 남길지 Pro로 올릴지 결정합니다. 이 구조가 있어야 Preview 기간의 모델 변화나 가격 변화에도 판단을 다시 만들 수 있습니다.
FAQ
DeepSeek V4 Preview는 공식인가요?
네. DeepSeek의 2026년 4월 24일 릴리스는 V4 Preview가 공식 공개되고 오픈 웨이트로 제공된다고 말하며, API docs도 V4 model ID를 표시합니다. Preview라는 한정은 유지해야 합니다.
API model ID는 무엇인가요?
deepseek-v4-pro 또는 deepseek-v4-flash를 사용합니다. deepseek-v4-preview를 model ID로 쓰면 안 됩니다. deepseek-chat과 deepseek-reasoner는 compatibility aliases이며 2026-07-24 15:59 UTC 이후 접근 불가 예정입니다.
Flash와 Pro 중 무엇을 먼저 테스트해야 하나요?
대량, 저지연, 저비용, 자동 검증 가능 작업은 Flash입니다. 복잡한 추론, 코드, Agent, 장문 종합, 실패 수리 비용이 큰 작업은 Pro입니다.
1M 컨텍스트는 곧바로 운영 가능한가요?
아닙니다. 공식 문서와 model card는 능력을 뒷받침하지만, 운영에는 recall, latency, cost, max output 384K, provider 제한, Preview 변화를 검증해야 합니다.
DeepSeek V4 weights는 열려 있나요?
DeepSeek verified Hugging Face collection에는 Pro, Pro-Base, Flash, Flash-Base가 있고 model card는 MIT license를 표시합니다. 하지만 로컬 운영 품질은 별도 검증 대상입니다.
Provider route는 공식 API인가요?
아닙니다. Provider의 가격, routing, fallback, logs, quota, support는 별도 계약입니다. first-party claim은 DeepSeek docs에 근거해야 합니다.
로컬에서 1M 컨텍스트를 사용할 수 있나요?
평가는 가능하지만 GPU, 메모리, serving stack, latency, recall, accepted-output cost 문제입니다. 짧은 context ladder부터 늘려야 합니다.