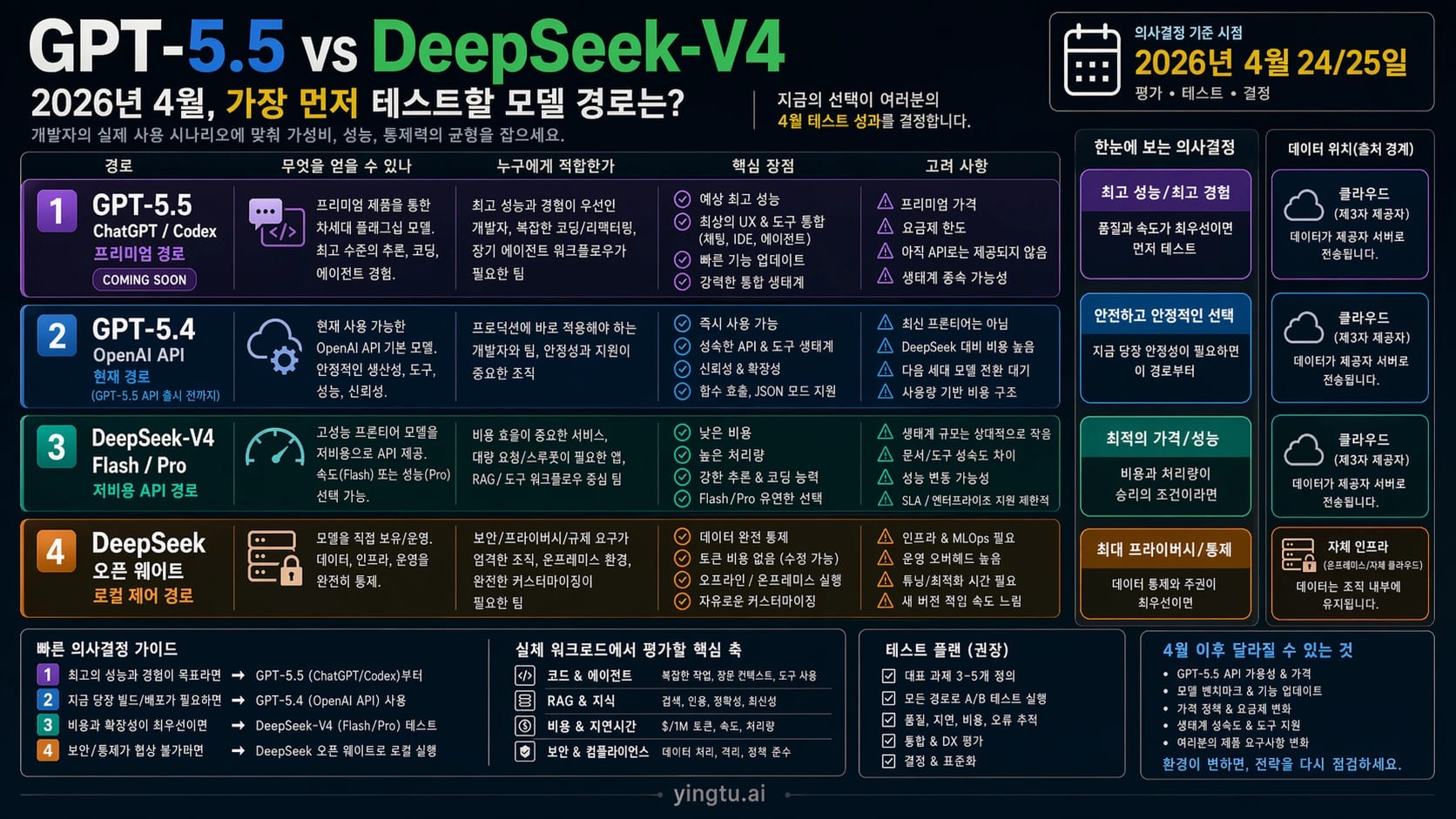
2026년 4월 24/25일 기준으로 GPT-5.5와 DeepSeek-V4는 같은 방식으로 배포할 수 있는 API 선택지가 아닙니다. ChatGPT나 Codex 안에서 코딩, 에이전트 작업, 고급 추론을 한다면 GPT-5.5를 먼저 테스트하세요. 지금 OpenAI API 서비스를 운영하거나 배포해야 한다면 GPT-5.4를 현재 기준선으로 유지하세요. API 비용, 1M 컨텍스트, 오픈 웨이트, 자체 호스팅이 중요하다면 DeepSeek-V4-Flash 또는 DeepSeek-V4-Pro를 먼저 평가해야 합니다.
| 경로 | 먼저 테스트할 때 | 보류할 때 |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | OpenAI 제품 안에서 가장 강한 코딩, Agent, reasoning 경험이 필요할 때. | 오늘 바로 production API 모델이 필요할 때. |
| GPT-5.4 in OpenAI API | OpenAI API 워크로드를 지금 운영하며 안정적인 현재 기준선이 필요할 때. | 다음 frontier 경로만 평가하고 GPT-5.5 API를 기다릴 수 있을 때. |
| DeepSeek-V4-Flash / V4-Pro API | 낮은 API 비용, 긴 컨텍스트, DeepSeek-native 성능 검증이 필요할 때. | OpenAI-native tooling, 엔터프라이즈 지원, 이미 검증한 품질 기준이 더 중요할 때. |
| DeepSeek-V4 open weights | 로컬 제어, MIT license, 프라이버시, 자체 추론 실험이 필요할 때. | GPU, serving, monitoring, MLOps를 직접 감당하고 싶지 않을 때. |
공개 벤치마크는 테스트 순서를 정하는 증거이지, 모든 워크로드의 승자를 선언하는 표가 아닙니다. production 트래픽을 바꾸기 전에 같은 실제 작업을 후보 경로에 넣고 품질, 지연 시간, 비용, tool behavior, error recovery, data boundary를 측정해야 합니다.
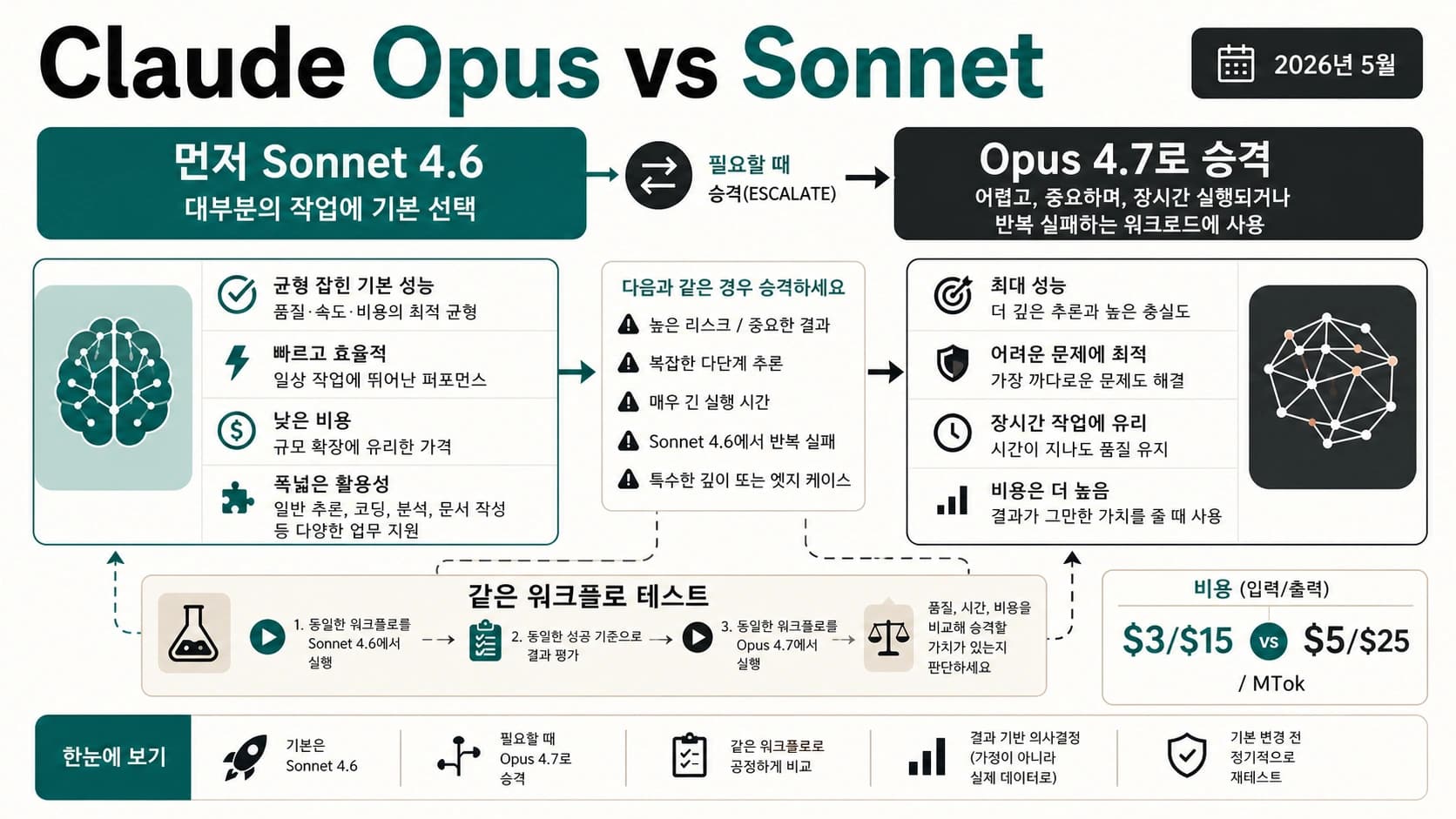
승자보다 먼저 경로를 고른다
한국어 검색 환경에서는 "GPT-5.5와 DeepSeek-V4 중 누가 더 좋나"라는 질문이 빠르게 가격, 성능, 영상 테스트, 커뮤니티 반응으로 흘러갑니다. 하지만 개발자가 바로 써야 하는 답은 더 구체적입니다. 지금 어떤 경로를 테스트할 수 있는지, 어떤 경로를 production 기준선으로 삼을 수 있는지, 어떤 경로는 공식 상태가 바뀔 때까지 기다려야 하는지가 먼저입니다.
GPT-5.5는 OpenAI 제품 경로와 함께 봐야 합니다. Codex, ChatGPT, 계정, editor/terminal workflow, review loop가 모델 성능과 같이 작동합니다. DeepSeek-V4는 다른 장점이 있습니다. Flash/Pro hosted API, 낮은 token 가격, 1M context, open weights, self-hosting 가능성입니다. 두 모델을 단순히 점수표 한 줄로 비교하면 API 상태와 운영 책임을 놓치게 됩니다.
첫 테스트는 이렇게 나누면 됩니다.
| 워크로드 | 첫 후보 | 이유 |
|---|---|---|
| Codex 안의 repo repair, coding agent, review workflow | GPT-5.5 | OpenAI 제품면까지 포함해 평가할 수 있습니다. |
| 이미 운영 중인 OpenAI API 서비스 | GPT-5.4 | GPT-5.5 API가 live docs에 나오기 전까지의 현재 기준선입니다. |
| 대량 추출, 분류, 요약, routing | DeepSeek-V4-Flash | 자동 검증과 결합하면 accepted output cost를 낮추기 쉽습니다. |
| 복잡한 reasoning, code, long-context synthesis | DeepSeek-V4-Pro | Flash보다 어려운 작업 품질을 보기 좋습니다. |
| local control, private inference, self-hosting | DeepSeek-V4 open weights | 모델 선택이 아니라 인프라 선택까지 포함합니다. |
중요한 점은 DeepSeek-V4를 하나의 모델 행으로 압축하지 않는 것입니다. Flash, Pro, open weights는 가격, 품질, 책임이 다릅니다. GPT-5.5도 마찬가지입니다. ChatGPT/Codex 경로와 일반 API 경로를 분리하지 않으면 실제 배포 판단이 흔들립니다.
접근성과 가격: 지금 쓸 수 있는 것부터 분리한다
OpenAI의 GPT-5.5 announcement는 GPT-5.5를 ChatGPT와 Codex의 새로운 premium model로 소개합니다. API 가격도 예고되어 있지만, OpenAI의 latest-model API guide는 2026년 4월 24/25일 기준으로 GPT-5.4를 현재 OpenAI API 경로로 유지합니다. 따라서 GPT-5.5는 지금 OpenAI-native 제품 작업에서 평가할 수 있지만, 일반 production API peer로 쓰기에는 아직 이릅니다.
DeepSeek 쪽은 더 직접적입니다. DeepSeek API pricing은 deepseek-v4-flash와 deepseek-v4-pro를 나눠 표시합니다. OpenAI-compatible, Anthropic-compatible endpoint도 제공하므로 기존 client abstraction을 완전히 바꾸지 않고 소규모 비교 테스트를 시작할 수 있습니다. 다만 deepseek-chat, deepseek-reasoner 같은 alias는 장기적으로 바뀔 수 있으므로 production config에서는 명시적인 V4 model ID를 선호하는 편이 안전합니다.
| 경로 | 현재 상태 | 2026년 4월 24/25일 기준 가격 신호 |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | OpenAI 제품면에서 사용 가능. | 구독 또는 workspace 접근이며 일반 API token billing이 아닙니다. |
| GPT-5.5 API | coming soon으로 예고. | 예고 가격: input $5, output $30 / 1M tokens. |
| GPT-5.5 Pro API | coming soon으로 예고. | 예고 가격: input $30, output $180 / 1M tokens. |
| GPT-5.4 API | 현재 OpenAI API fallback. | 배포 전 최신 OpenAI docs와 pricing 확인 필요. |
| DeepSeek-V4-Flash API | DeepSeek API docs에 현재 listed. | cache hit $0.028, cache miss $0.14, output $0.28 / 1M tokens. |
| DeepSeek-V4-Pro API | DeepSeek API docs에 현재 listed. | cache hit $0.145, cache miss $1.74, output $3.48 / 1M tokens. |
| DeepSeek-V4 open weights | official model-card artifacts로 확인 가능. | token billing 대신 GPU, serving, monitoring, staff time 비용. |
가격 차이는 실제로 큽니다. 그러나 가격만으로 production 가치를 판단하면 위험합니다. DeepSeek-V4-Flash는 많은 요청을 자동 검증할 수 있을 때 특히 강합니다. DeepSeek-V4-Pro는 더 어려운 reasoning이나 coding에서 retry를 줄일 수 있는지 봐야 합니다. GPT-5.5는 비싸게 보일 수 있지만 Codex 안에서 사람의 review 시간과 실패 반복을 줄이면 전체 비용이 합리적일 수 있습니다.
벤치마크는 출처를 붙여 읽어야 한다
OpenAI는 GPT-5.5에 대해 Terminal-Bench 2.0, SWE-Bench Pro public, BrowseComp 등 coding, browsing, agentic work 관련 수치를 공개했습니다. DeepSeek는 DeepSeek-V4-Pro model card에서 DeepSeek-V4-Pro-Max의 Terminal-Bench 2.0, SWE Verified, SWE Pro, BrowseComp, MCPAtlas Public, Toolathlon 수치를 제시합니다.
이 수치는 방향을 알려주지만 하나의 독립 leaderboard는 아닙니다. provider가 다르고, 환경이 다르고, thinking mode와 tool chain도 다를 수 있습니다. 그래서 공개 벤치마크를 "누가 이겼다"로 끝내지 말고, 내부 테스트를 설계하는 힌트로 써야 합니다.
| 증거 영역 | 공개 수치가 말해주는 것 | 내부에서 확인할 것 |
|---|---|---|
| Coding | GPT-5.5는 OpenAI coding/terminal 흐름에서 강한 신호가 있고, DeepSeek-V4-Pro도 후보에 들어갑니다. | multi-file patch, tests, dependency handling, review effort. |
| Tools / agents | 양쪽 모두 tool 또는 browsing evidence가 있지만 같은 환경은 아닙니다. | function arguments, retry, partial failure recovery, JSON validity. |
| Long context | DeepSeek-V4는 1M context를 강조하고, GPT-5.5 API도 1M context를 예고합니다. | late-context recall, conflicting instructions, long prompt cost. |
| Reliability | 공개 벤치마크는 p95 latency, timeout, rate limit을 잘 보여주지 못합니다. | latency, refusal, timeout, audit log, data handling. |
production migration에서는 raw token price보다 accepted output cost가 중요합니다. 검증을 통과한 결과 하나를 얻기까지의 token, retry, 사람 review, downstream failure 비용을 모두 더해야 합니다.
DeepSeek-V4는 Flash, Pro, open weights를 나눠 봐야 한다
DeepSeek-V4-Flash는 volume이 크고 자동 검증이 가능한 작업에 적합합니다. 추출, 분류, 짧은 요약, RAG pre-filter, routing, format conversion이 대표적입니다. 낮은 가격 덕분에 후보를 더 많이 만들거나 검증 단계를 추가해도 총 비용을 낮게 유지할 수 있습니다.
DeepSeek-V4-Pro는 실패 비용이 큰 작업에 맞습니다. code change, multi-step reasoning, tool coordination, long-context synthesis, agent planning에서 Flash가 그럴듯하지만 불안정하면 Pro를 봐야 합니다. Pro는 Flash보다 비싸지만, retry와 manual repair를 줄이면 실제 비용이 더 낮아질 수 있습니다.
Open weights는 다른 판단입니다. MIT license와 official artifacts는 강력한 장점이지만 hosted token billing이 사라지는 대신 GPU, batching, serving, security, monitoring, upgrade, incident response가 생깁니다. data locality나 private inference가 핵심이 아니라면 hosted API로 품질을 먼저 보는 편이 빠릅니다.
1M context도 숫자만 보지 말아야 합니다. 테스트에는 irrelevant documents, 뒤쪽에 놓인 핵심 조건, conflicting requirements, final citation check를 넣어야 합니다. 20K tokens에서 잘 답한 모델이 500K tokens에서도 같은 방식으로 근거를 찾는다는 보장은 없습니다.
워크플로별 추천
Codex나 ChatGPT 안에서 고급 coding, repo repair, agent debugging을 한다면 GPT-5.5를 먼저 보세요. 이 경우 가치는 모델만이 아니라 OpenAI product surface, review flow, editor/terminal integration, account controls에서 나옵니다.
이미 OpenAI API로 서비스를 운영한다면 GPT-5.4를 기준으로 둡니다. model routing을 추상화해 나중에 GPT-5.5를 붙일 준비는 해야 하지만, official API docs에 GPT-5.5가 나타나기 전에는 user-facing promise나 SLA에 넣지 않는 것이 안전합니다.
비용 민감도가 높은 API workload는 DeepSeek-V4-Flash부터 보세요. 핵심은 token이 싸다는 사실이 아니라 accepted output cost가 낮아지는지입니다. Flash가 format, reasoning, tool behavior에서 실패하는 부분만 V4-Pro로 올리면 됩니다.
어려운 reasoning 또는 coding을 API에서 비교해야 한다면 지금은 DeepSeek-V4-Pro와 GPT-5.4 API를 병렬로 돌립니다. GPT-5.5 API가 열리면 같은 task, 같은 rubric, 같은 cost accounting에 추가하세요. 기준은 accepted patches, passing tests, valid JSON, tool-call success, human review minutes가 되어야 합니다.
privacy, local control, self-hosting이 첫 조건이라면 DeepSeek-V4 open weights를 작은 pilot으로 봅니다. 이 pilot은 model quality뿐 아니라 infrastructure readiness까지 검증해야 합니다.
migration 전에 dual-run을 설계한다
테스트는 작게 설계해야 합니다. 실제 production log 또는 내부 workflow에서 민감 정보를 제거한 3~5개 작업을 고르세요. code repair, long-context answer, structured extraction, tool call, high-volume batch 정도면 충분합니다. 각 task에는 input, expected output, scoring rubric, retry policy, failure severity, cost formula가 있어야 합니다.
| 테스트 라인 | 사용할 때 | 측정할 것 |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | OpenAI 제품 경험 자체가 결과에 중요할 때. | quality, saved human effort, code review result, workflow fit. |
| GPT-5.4 API | 현재 OpenAI API baseline. | cost, latency, tool behavior, structured output, regression. |
| DeepSeek-V4-Flash API | high-volume 또는 cost-sensitive 작업. | pass rate, retry rate, format validity, cache behavior. |
| DeepSeek-V4-Pro API | 더 어려운 DeepSeek quality 평가. | accuracy, reasoning stability, tools, long-context recall. |
| DeepSeek-V4 open weights | local control이 최우선일 때. | GPU cost, throughput, latency, security, monitoring. |
stop rule도 테스트 전에 정합니다. JSON이 자주 깨지거나, tool arguments가 빠지거나, 뒤쪽 context를 무시하거나, 위험한 code change를 만들거나, 사람 review 시간이 token savings를 지워버리면 migration을 멈춰야 합니다. 새 경로는 shadow traffic이나 낮은 위험의 batch에서 먼저 관찰하고, logging과 monitoring, audit field가 준비된 뒤 비율을 늘려야 합니다.
자주 묻는 질문
GPT-5.5는 지금 API에서 사용할 수 있나요?
OpenAI는 GPT-5.5 API와 가격을 예고했지만, 2026년 4월 24/25일 기준 현재 API guide는 GPT-5.4를 OpenAI API production route로 유지합니다. GPT-5.5는 지금 ChatGPT/Codex 경로이며, API는 live docs에 등장한 뒤 production 계획에 넣는 것이 안전합니다.
DeepSeek-V4는 Flash부터 볼까요, Pro부터 볼까요?
volume이 크고 자동 검증이 가능한 낮은 위험 작업이면 Flash부터 보세요. 복잡한 reasoning, coding, tool behavior, long context가 중요하면 Pro부터 보세요. open weights는 local control이 주요 요구일 때 별도 pilot으로 봐야 합니다.
DeepSeek-V4가 싸면 바로 더 좋은 선택인가요?
아닙니다. 낮은 가격은 테스트할 이유이지, 자동 채택 이유가 아닙니다. retry, manual repair, review time, downstream failure까지 포함한 accepted output cost로 판단해야 합니다.
벤치마크만 보면 승자를 정할 수 있나요?
정할 수 없습니다. 공개 벤치마크는 어떤 작업을 테스트할지 알려주는 신호입니다. production 판단은 같은 inputs, 같은 rubric, 같은 환경에서 비교해야 합니다.
언제 결정을 다시 봐야 하나요?
GPT-5.5가 OpenAI API docs에 올라올 때, DeepSeek가 가격이나 alias를 바꿀 때, independent same-harness 평가가 나올 때, 또는 내부 workload가 바뀔 때입니다. 이 선택은 고정 순위가 아니라 접근성, 품질, 비용, 운영 위험을 따르는 경로 선택입니다.