
gpt-oss-120b를 안정적으로 로컬에서 쓰려면 먼저 80GB GPU급 모델로 계획해야 합니다. >=60GB는 MXFP4를 지원하는 특정 runtime에서의 제한적인 하한이지 여유 있는 운영 기준이 아닙니다. 24GB GPU에 CPU나 NVMe offload를 붙이는 방식은 실험으로 분리해야 합니다. 속도, 긴 context, 동시 사용, 재현성이 중요하다면 gpt-oss-20b, 클라우드 GPU, hosted access를 같은 선택지 안에서 비교해야 합니다.
| 실행 경로 | 해석 | 실무 의미 |
|---|---|---|
| 80GB급 서버 GPU | 깨끗한 로컬 경로 | 120B를 진지하게 평가하거나 내부에서 반복 사용하려는 기준. |
>=60GB VRAM 또는 통합 메모리 | 제한적 하한 | 지원 runtime에서는 가능하지만 context, batch, overhead 여유가 작다. |
| 24GB GPU + CPU/NVMe offload | 실험 경로 | 학습과 느린 검증에는 유용하지만 운영 계획은 아니다. |
gpt-oss-20b, 클라우드 GPU, hosted access | 대안 경로 | 메모리, 속도, 안정성이 핵심 제약일 때 더 빠른 선택지. |
총 RAM 숫자, 짧은 영상, 단일 커뮤니티 성공담만 보고 장비를 사면 위험합니다. 실제 runtime, context length, batch, 동시 요청, tokens/sec가 같은 조건에서 확인되어야 합니다.
먼저 실행 경로를 정한다
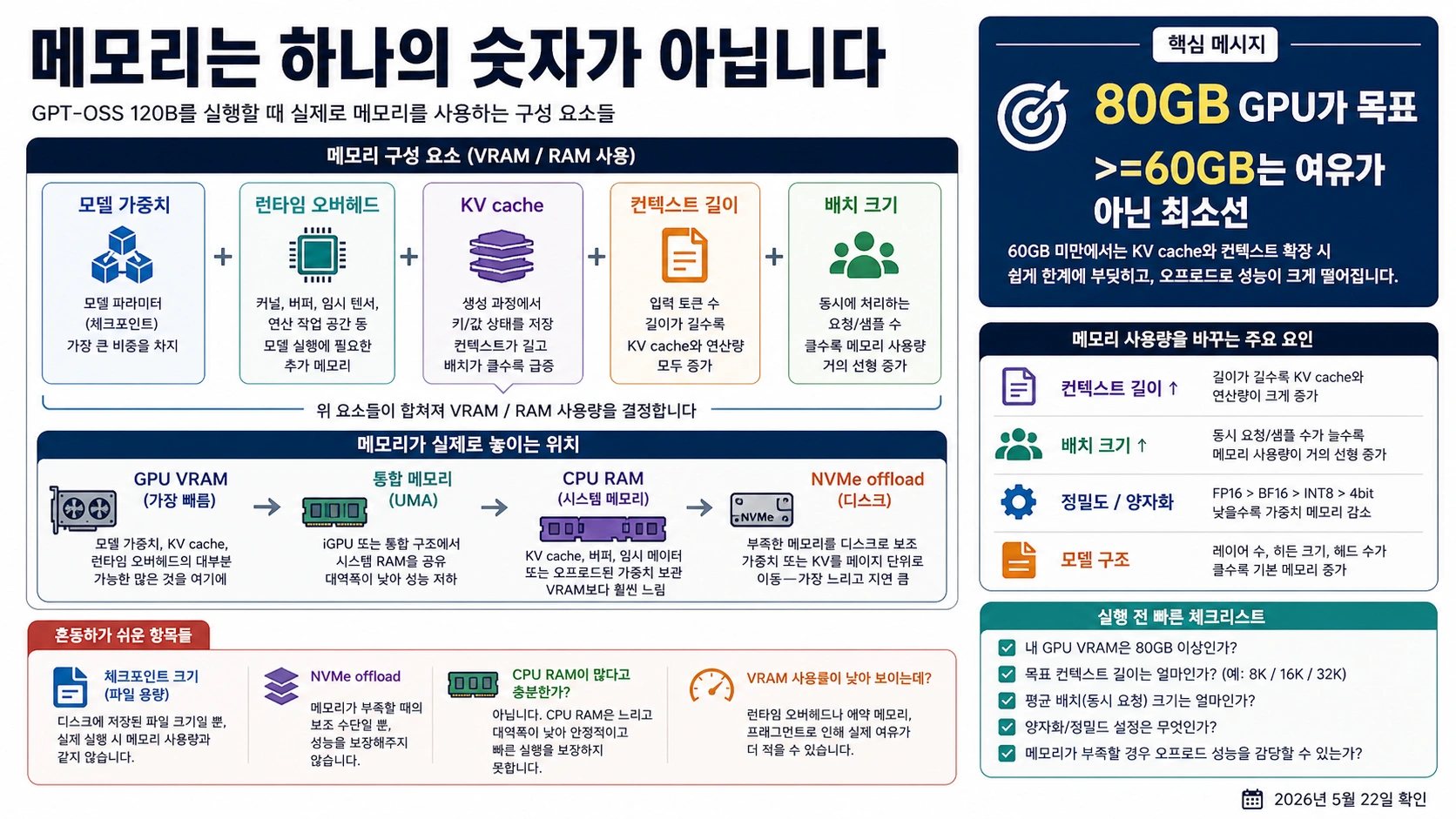
GPT-OSS 120B의 메모리 요구 사항은 하나의 숫자로 끝나지 않습니다. OpenAI 모델 자료는 gpt-oss-120b를 117B parameters, 5.1B active parameters, 긴 context window를 가진 open-weight 모델로 다룹니다. 안정적인 로컬 실행을 계획할 때 80GB GPU급 하드웨어를 기준으로 삼는 이유는 weights, runtime overhead, 보통의 context, 일부 여유를 한 장치 안에 담기 쉽기 때문입니다.
하지만 load 가능, 짧은 prompt 응답, 긴 문서 처리, 여러 사용자 serving은 서로 다른 검증입니다. Transformers, vLLM, Ollama, multi-GPU, offload, hosted route는 모두 메모리의 쓰임새를 바꿉니다. 그래서 먼저 목적을 적어야 합니다. 단일 사용자의 로컬 chat인지, 120B 성능 평가인지, 내부 서비스인지, 제품 delivery인지에 따라 적절한 경로가 달라집니다.
20B가 충분한 일이라면 gpt-oss-20b가 더 빠르고 조용합니다. 120B 능력을 평가해야 한다면 클라우드 GPU를 하루 빌려 실제 prompt를 돌리는 편이 낫습니다. 반복적인 로컬 120B 사용과 데이터 상주 요구가 명확할 때 80GB급 구매가 의미를 갖습니다.

경로를 먼저 정하면 load 성공과 유용한 운영을 분리할 수 있습니다. 운영에는 속도, context, 동시성, 유지보수 여유가 필요합니다.
80GB와 60GB가 함께 나오는 이유
80GB와 >=60GB는 서로 다른 경계를 말합니다. 80GB는 안정적인 로컬 실행을 위한 기준입니다. >=60GB는 MXFP4와 지원 runtime을 전제로 한 제한적 하한입니다. 이 하한은 모델이 load될 수 있다는 의미에 가깝고, 긴 context나 높은 batch, 다중 사용자 serving까지 보장하지 않습니다.
공식 runtime 자료에서도 경로별 표현은 다르게 나타납니다. Transformers는 직접 Python으로 실험하기 좋지만 hardware support와 precision path가 중요합니다. vLLM은 serving 설정이 중요하며 max model length, batched tokens, tensor parallelism, KV cache 정책이 메모리에 직결됩니다. Ollama와 desktop runner는 시작이 쉽지만 VRAM 또는 통합 메모리라는 문구를 모든 장치의 성능 보장으로 읽으면 안 됩니다.
모델 파일 크기 역시 runtime memory와 다릅니다. allocator reserve, temporary buffers, KV cache, kernel fallback, multi-GPU sharding이 추가됩니다. 짧은 prompt가 성공한 설정도 긴 문서와 동시 요청에서 OOM이 날 수 있습니다.
VRAM, 통합 메모리, 시스템 RAM, 디스크, KV cache를 분리한다
VRAM은 accelerator 위의 빠른 메모리이며 weights, runtime state, KV cache의 일부를 담당합니다. 통합 메모리는 일부 시스템에서 CPU/GPU가 공유하는 공간이지만 속도와 runtime 지원을 별도로 확인해야 합니다. 시스템 RAM은 OS, tokenizer, offload buffers, background tasks를 돕지만 GPU VRAM처럼 동작하지 않습니다.
NVMe offload는 모델을 load하는 범위를 넓힐 수 있습니다. 그러나 interactive latency와 안정성을 희생합니다. KV cache는 특히 중요합니다. context가 길어지고 동시 요청이 늘수록 weights 외의 메모리 압박이 커집니다.
따라서 장비 계획에는 VRAM, 통합 메모리, 시스템 RAM, disk offload, context target, batch/concurrency를 각각 적어야 합니다. 128GB 시스템 RAM과 24GB GPU는 흥미로운 실험 장치일 수 있지만, 80GB accelerator와 같은 의미가 아닙니다.
| 메모리 항목 | gpt-oss-120b에서의 의미 | 판단 의미 |
|---|---|---|
| VRAM | GPU 위에서 weights, runtime state, KV cache를 담당 | 깨끗한 단일 장치 목표는 80GB급. |
| 통합 메모리 | 일부 장치의 공유 메모리 풀 | 가능성은 있지만 속도와 여유는 실측해야 한다. |
| 시스템 RAM | OS, runtime, offload buffers, background tasks | 실험을 돕지만 VRAM은 아니다. |
| Disk/NVMe offload | 상태 일부를 storage로 이동 | load 가능과 interactive 가능은 다르다. |
| KV cache | active context를 유지하는 생성 메모리 | context와 동시 요청이 늘수록 커진다. |
| Batch/concurrency | 함께 처리하는 token 또는 request | 서비스는 단일 chat보다 더 큰 여유가 필요하다. |
이 구분이 없으면 시스템 RAM을 많이 달고도 VRAM 병목을 해결했다고 착각하기 쉽습니다.
runtime이 메모리 예산을 바꾼다
runtime은 메모리 요구를 바꿉니다. Transformers는 빠르게 실험할 수 있지만 지원되지 않는 kernel이나 precision fallback이 발생하면 메모리와 속도가 바뀝니다. vLLM은 서버 경로에 가깝고, 설정 하나가 KV cache와 남은 VRAM을 좌우합니다. Ollama나 local app은 접근성이 좋지만, 긴 context와 안정적인 serving까지 같은 수준으로 보장하지 않습니다.
multi-GPU도 단순 합산 문제가 아닙니다. 24GB GPU 여러 장은 숫자상 충분해 보여도 interconnect, sharding, driver, manual placement가 병목이 될 수 있습니다. runtime이 깔끔하게 분배하지 못하면 한 장의 적절한 GPU보다 시간이 더 많이 듭니다.
클라우드 GPU는 검증에 적합합니다. 실제 prompt, context, batch를 H100급 인스턴스에서 먼저 측정하면 장비 구매, 20B 선택, hosted route 중 무엇이 맞는지 빠르게 드러납니다.
소비자 GPU의 중단선
24GB GPU는 production 경로가 아니라 실험 경로입니다. CPU나 NVMe offload를 쓰면 load에 성공할 수 있지만 latency와 안정성은 다른 문제가 됩니다. prompt를 시험하고 model format을 이해하고 tool behavior를 보는 데는 가치가 있습니다. 긴 context나 팀 서비스에는 약한 출발점입니다.
48GB workstation GPU는 더 진지한 테스트가 가능하지만 여전히 80GB 안정 기준 아래입니다. 2장의 24GB, 3장의 24GB, Apple 통합 메모리 시스템도 실제 throughput과 열 안정성, runtime 지원을 확인해야 합니다. 총 메모리만으로 결론을 내리면 안 됩니다.
중단선은 명확합니다. load만 되고 first token이 너무 느리면 interactive 사용이 아닙니다. 짧은 prompt만 성공하면 실제 workload proof가 아닙니다. 한 명은 되지만 batch나 여러 사용자가 실패하면 service 경로가 아닙니다.
| 하드웨어 상황 | 합리적 경로 | 중단선 |
|---|---|---|
| 24GB GPU 1장 | offload 실험 또는 gpt-oss-20b | CPU/NVMe 이동이 지연을 좌우하면 production 120B가 아니다. |
| 24GB GPU 2장 | 고급 실험 | manual placement가 불안정하면 멈춘다. |
| 48GB workstation GPU | 진지한 테스트 | 짧은 demo는 실제 workload proof가 아니다. |
| 대용량 통합 메모리 | 로컬 테스트 | capacity만 보고 throughput을 대체하지 않는다. |
| CPU-only | 학습과 offline inspection | interactive나 team serving에는 맞지 않는다. |
대안 경로를 정하는 것은 후퇴가 아닙니다. 20B, cloud GPU, hosted access를 먼저 열어 두면 한계 장비에 시간을 잃지 않습니다.
구매나 임대 전 검증 체크리스트
검증은 실제 workload에서 시작합니다. runtime, hardware memory pool, context target, batch/concurrency, precision/quantization, real prompt set, telemetry, fallback을 순서대로 기록합니다. telemetry에는 peak VRAM, system RAM, swap, NVMe activity, tokens/sec, time-to-first-token, OOM point를 포함해야 합니다.
클라우드 임대라면 같은 runtime과 같은 context target으로 proof session을 실행합니다. 구매라면 짧은 demo 대신 실제 문서 길이, tool calls, 동시 요청을 검증합니다. local assistant가 목적이면 20B가 더 안정적일 수 있습니다. 120B 평가가 목적이면 cloud GPU가 낫습니다. delivery가 우선이면 hosted route가 infrastructure ownership을 뒤로 미룹니다.
결론은 80GB 구매, 60GB 제한 테스트, 24GB offload lab, 20B 선택, cloud GPU 검증, hosted route 중 하나로 좁혀져야 합니다. 단일 메모리 숫자는 좋은 구매 결정을 만들지 못합니다.

| 단계 | 기록할 것 | 이유 |
|---|---|---|
| Runtime | Transformers, vLLM, Ollama, multi-GPU, offload, hosted | 경로마다 memory behavior가 다르다. |
| Memory pool | VRAM, 통합 메모리, 시스템 RAM, disk offload | RAM이라는 말만으로는 병목이 숨는다. |
| Context target | short chat, 32k, 64k, 128k, 실제 한계 | KV cache가 여유를 지운다. |
| Batch/concurrency | 1명, batch test, multi-user serving | 단일 요청 성공은 서비스 성공이 아니다. |
| Precision/quantization | MXFP4, BF16, runtime conversion | 메모리 주장은 실제 representation에 의존한다. |
| Real prompts | tools, long docs, code, short chat | toy prompt는 지연과 OOM을 숨긴다. |
| Telemetry | peak VRAM, RAM, swap, tokens/sec, OOM point | 반복 가능한 측정이 screenshot보다 강하다. |
| Fallback | 20B, cloud GPU, hosted, shorter context | 탈출 경로를 먼저 정한다. |
검증 뒤에는 80GB를 살지, cloud GPU를 빌릴지, 20B를 쓸지, context를 줄일지, self-host를 미룰지 판단할 수 있습니다.
자주 묻는 질문
GPT-OSS 120B에는 VRAM이 얼마나 필요합니까?
안정적인 로컬 경로라면 80GB GPU급을 기준으로 잡습니다. >=60GB는 일부 MXFP4 runtime의 제한적 하한이며 context, batch, KV cache, overhead에 영향을 받습니다.
24GB GPU로 GPT-OSS 120B를 실행할 수 있습니까?
offload 실험으로는 가능성이 있습니다. 하지만 CPU나 NVMe를 쓰는 순간 latency와 안정성이 달라지므로 production 경로로 보지 않는 편이 안전합니다.
시스템 RAM이 많으면 VRAM 부족을 대신할 수 있습니까?
대신할 수 없습니다. 시스템 RAM은 offload와 buffers를 돕지만 accelerator VRAM과 같은 속도나 특성을 갖지 않습니다.
80GB와 60GB는 무엇이 다릅니까?
80GB는 안정적인 로컬 기준이고 60GB는 제한적 runtime 하한입니다. 둘 다 실제 context, batch, concurrency 조건과 함께 봐야 합니다.
GPT-OSS 20B도 같은 하드웨어가 필요합니까?
아닙니다. gpt-oss-20b는 16GB급 로컬 경로입니다. 작은 로컬 assistant 목적이면 20B가 더 적합할 수 있습니다.
128k context는 어떤 장비에서도 쓸 수 있습니까?
아닙니다. 긴 context는 KV cache를 키웁니다. 실제 사용할 context length로 측정해야 합니다.
H100급 GPU를 사야 합니까, cloud GPU를 빌려야 합니까?
반복적인 로컬 120B 작업이 명확할 때 구매를 검토합니다. 평가 단계라면 cloud GPU, 안정적인 delivery가 우선이면 hosted route가 낫습니다.
8GB나 24GB 성공 사례는 의미가 있습니까?
실험 아이디어로는 의미가 있습니다. 하지만 구매 기준은 공식 model/runtime 자료와 자신의 workload proof가 되어야 합니다.


