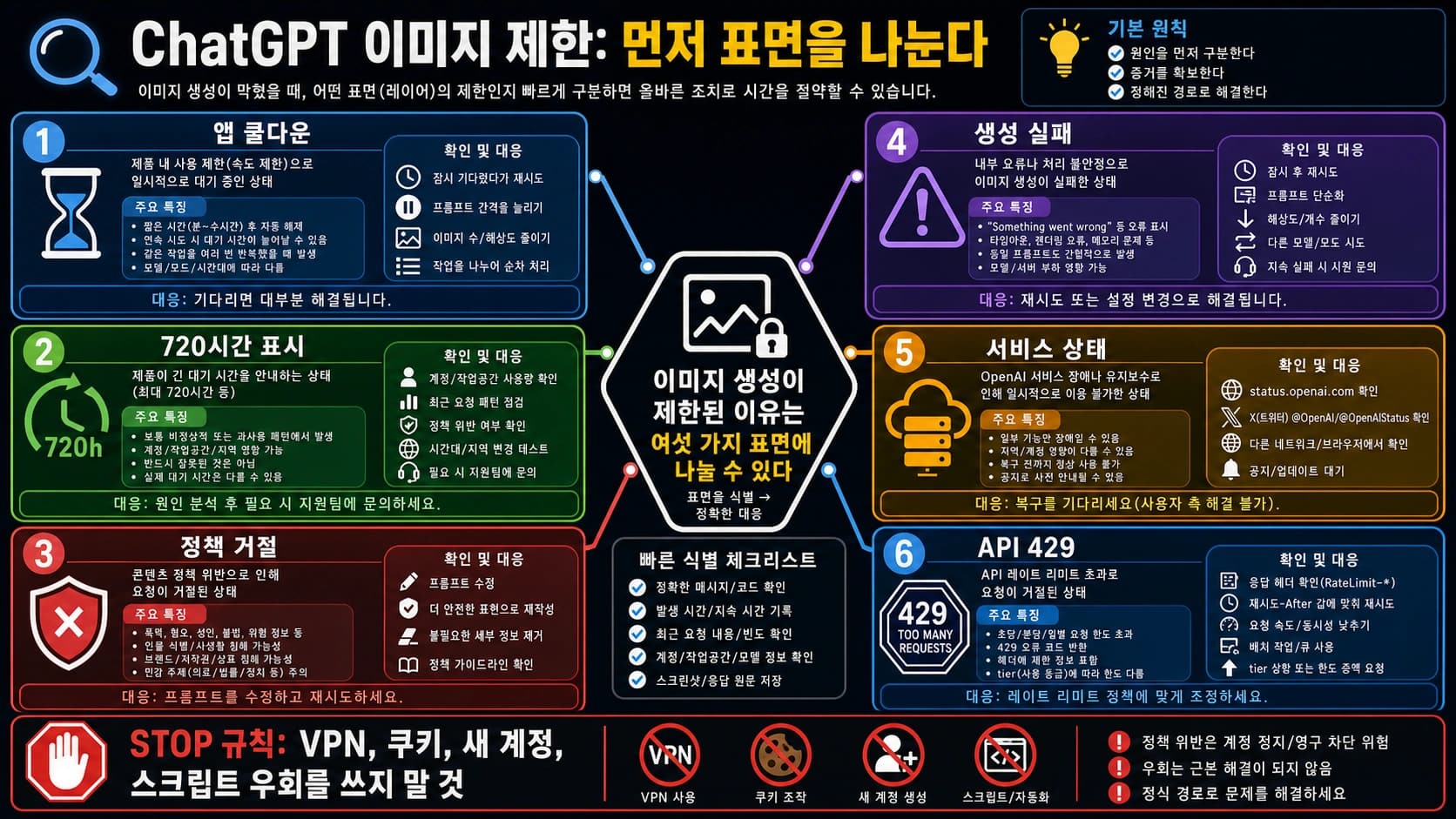
OpenAI Platform API가 quota exceeded, insufficient_quota 또는 429를 반환하면 먼저 retry 횟수를 늘리지 말고 오류 본문을 읽어야 한다. rate limit이면 backoff, throttling, queue가 맞지만 quota, billing, project scope, model access, status incident, wrapper limit이면 확인 대상이 달라진다.
| 오류 단서 | 가능한 소유자 | 먼저 볼 것 | retry 또는 stop |
|---|---|---|---|
rate limit reached, too many requests, remaining headers near zero | request/token rate limit | headers, Limits, model family, reset window | backoff와 jitter 후 throttle 또는 queue |
You exceeded your current quota 또는 insufficient_quota | quota, billing, spend cap | Billing, Usage, Limits, account state | account state 변경 전 stop |
| 새 key도 동일하거나 일부 project/model만 실패 | project, organization, model, key scope | project, organization, model access | scope 수정 후 traffic 변경 |
| 여러 call 실패와 Status incident | platform status/capacity | OpenAI Status, timestamp, request id | 대기, 증거 보존 |
| ChatGPT, Codex, Sora, Azure, wrapper 오류 | wrong surface | product surface, provider docs, route, headers | 해당 계약으로 분리 |
중지 규칙은 단순하다. request/token pressure이고 reset signal이 있을 때만 retry한다. quota, billing, wrong project, wrong model, wrong surface, status incident가 보이면 같은 요청 반복은 해결책이 아니다.
429 본문을 먼저 읽고 코드를 바꾼다
OpenAI 공식 문서는 429를 적어도 두 갈래로 나눈다. 하나는 traffic이 너무 빠른 경우이고, 다른 하나는 current quota가 소진된 경우다. 현장에서는 둘 다 429 오류로 묶이기 쉽기 때문에 첫 판단은 오류 제목이 아니라 본문이 가져가야 한다. retry policy를 바꾸기 전에 message, code, type, endpoint, model, project, organization, timestamp, request id를 기록한다.
안전한 분류는 보수적이어야 한다. insufficient_quota나 current quota 문구가 보이면 quota 또는 billing 중지 분기로 처리한다. 본문이 rate limit 또는 too many requests를 말하고 headers가 remaining/reset 정보를 보여 주면 retry 가능한 pressure로 본다. 어느 쪽도 명확하지 않다면 여러 변수를 한꺼번에 바꾸지 말고 request route를 고정한 채 증거를 모은다.
운영에서는 이 차이가 중요하다. 애매한 429는 잘못된 수정을 유도한다. 촘촘한 retry loop는 minute capacity를 더 소모할 수 있고, 새 key는 같은 project가 계속 막혀 있다는 사실을 가릴 수 있으며, wrong organization에서 billing을 바꿔도 production request는 그대로 실패한다.
10분 안에 복구 경로를 정한다
처음 10분은 무작위 실험이 아니라 문제의 owner를 분류하는 시간이다. raw body와 headers를 복사하고, 같은 project와 organization의 Limits, Billing, Usage를 열고, model family를 확인하고, OpenAI Status를 본 뒤 작은 controlled request를 한 번 보낸다. 이 순서가 증거를 읽기 좋게 유지한다.
| 시간 | 행동 | 확인할 수 있는 것 |
|---|---|---|
| 0-1 | body와 headers 저장 | rate, quota, billing, unknown 중 어느 분기인지 |
| 1-3 | Limits, Usage, Billing 확인 | account capacity 또는 billing state 문제인지 |
| 3-5 | model과 endpoint 비교 | 더 엄격하거나 공유되는 model family가 관련됐는지 |
| 5-7 | OpenAI Status 확인 | public incident가 대응을 바꾸는지 |
| 7-10 | 작은 controlled request 1회 전송 | workload size 또는 account state 가능성 |
작은 request가 성공하면 concurrency, token size, image throughput, fan-out을 조사한다. 같은 quota wording으로 실패하면 retry를 멈춘다. declared incident 중에 관련 없는 endpoints도 실패한다면 account를 바꾸기보다 evidence를 보존하고 기다린다.
retry와 backoff가 맞는 경우
Retry와 backoff는 일시적인 request 또는 token pressure일 때만 맞다. 유용한 신호는 rate-limit wording, 낮은 remaining values, reset timing, 현재 project/model budget을 넘는 traffic pattern이다. retry는 마법 같은 수리가 아니라 속도를 맞추는 도구다.
exponential backoff에는 jitter를 넣고, retry count에는 상한을 두며, project와 model family별 central limiter를 둔다. workers가 상태를 공유하지 않는다면 각 worker 안의 limiter만으로는 충분하지 않다. dispatch 전에 token size를 추정하면 prompt size나 max output을 줄여 API가 거절하기 전에 TPM pressure를 낮출 수 있다.
실패한 requests도 minute limits에 계산될 수 있다. fleet 전체가 매초 retry하면 스스로 failure window 안에 머문다. 좋은 시스템은 속도를 늦추고, queue로 넘기고, 긴급하지 않은 작업을 줄이고, async work에는 Batch를 사용한다.
계속 retry하면 안 되는 경우
오류가 insufficient_quota, current quota, billing, monthly spend, account state를 가리키면 retry는 틀린 대응이다. 몇 초 기다려도 quota는 늘지 않는다. 올바른 확인 경로는 Billing, Usage, Limits, spend cap, organization, project, model access다.
“credits가 있는데도 429가 난다”는 사례의 상당수는 scope 문제다. credit이 다른 organization에 있거나, request가 다른 project를 쓰거나, monthly spend cap이 남아 있거나, model이 해당 project에서 불가능하거나, wrapper가 자체 pool을 적용할 수 있다. 각 scope를 확인하는 동안에는 최소 request 하나를 고정한다.
새 API key가 해결책이 아닐 수 있는 이유
API key는 별도의 capacity bucket이 아니다. 새 key는 기존 key가 revoke, leaked, restricted 상태이거나 wrong project에 붙어 있을 때 도움이 된다. organization, project, model family, billing owner가 같다면 capacity를 새로 만들지 않는다.
| Scope | 확인할 것 | 실패 패턴 |
|---|---|---|
| Organization | request가 의도한 org를 쓰는지 | personal org와 team org의 billing 또는 limits가 다름 |
| Project | key가 확인한 project에 속하는지 | Limits는 한 project에서 보고 traffic은 다른 project에서 나감 |
| Model family | selected model에 access와 headroom이 있는지 | 더 엄격하거나 공유되는 family limit이 소진됨 |
| Team workload | 다른 서비스와 capacity를 공유하는지 | batch job이나 다른 app이 pool을 소비함 |
한 model만 실패하면 그 project가 접근 가능한 model로 작은 request를 테스트한다. 모든 model이 quota wording으로 실패하면 account state를 먼저 본다. key가 다른 곳에서는 작동한다면 실패하는 서비스의 concurrency와 request shape를 점검한다.
headers와 Limits를 실시간 증거로 본다
live evidence는 response와 account 양쪽에 있다. body는 분기를 알려 주고, headers는 limit, remaining, reset timing을 보여 줄 수 있다. Limits 페이지는 현재 project, organization, model context를 보여 준다. 어떤 static table보다 독자의 계정에서 본 live evidence가 더 강하다.
| 증거 | 중요한 이유 |
|---|---|
| status와 body | retry 가능한 rate pressure와 quota/billing을 분리 |
| request id | support가 조회할 손잡이 제공 |
| rate-limit headers | limit, remaining, reset timing 표시 |
| project와 organization | request 소유자 확인 |
| model과 endpoint | 더 엄격한 model limit 또는 wrong endpoint 노출 |
| Limits와 Usage state | failure 당시 account state 기록 |
| Status snapshot | incident와 account-local failure 분리 |
2026년 4월 29일 public OpenAI Status 확인에서는 광범위한 active incident가 보이지 않았다. 이것은 이후 상태를 보장하지 않는다. 본인 incident 중에는 Status를 live로 확인하고, green이면 account scope, headers, workload shape를 계속 본다.
production에서 다음 429를 줄인다
즉시 복구가 끝나면 교훈을 production controls로 옮긴다. OpenAI가 거절하기 전에 application이 자신의 budget을 알아야 한다. project/model limiters, tenant budgets, token estimates, queue alerts, retry counters, reset-window observations가 필요하다.
interactive traffic과 background jobs를 무작정 경쟁시키지 않는다. 긴급하지 않은 jobs는 queue에 넣고, tenants를 나누고, 가능하면 prompt size를 줄인다. product decision으로 승인된 경우 더 단순한 작업은 더 저렴하거나 pressure가 낮은 models로 보낸다. latency가 급하지 않고 workload가 맞으면 Batch를 사용한다.
먼저 wrong surface를 분리한다
“OpenAI API 429”는 코드가 보낸 Platform API call을 뜻해야 한다. ChatGPT, Codex, Sora, Azure OpenAI, wrappers도 limit messages를 보여 줄 수 있지만 owner와 fix는 다르다.
| Surface | 가정하지 말 것 | 대신 확인할 것 |
|---|---|---|
| ChatGPT | consumer plan이 API quota를 바꿈 | ChatGPT product limits와 account state |
| Codex | coding-agent limits가 API RPM/TPM과 같음 | Codex product contract와 status |
| Sora | video capacity가 text API limits와 같음 | Sora route, queue, plan, video status |
| Azure OpenAI | OpenAI Platform Limits가 deployment를 소유함 | Azure quota, deployment, region, subscription |
| Wrapper | OpenAI headers가 항상 그대로 통과함 | provider dashboard, docs, route id, upstream evidence |
request가 api.openai.com으로 직접 가지 않는다면 provider boundary를 먼저 확인한다. wrapper pool이 가득 찼거나, upstream 429를 local error로 바꾸거나, 자체 account cap을 적용할 수 있다.
증거를 모아 에스컬레이션한다
분기가 안정되고 secrets를 제거한 뒤에만 에스컬레이션한다. 짧은 packet에는 timestamp, timezone, request id, endpoint, model, SDK version, organization, project, billing owner, 안전한 body와 headers, Limits/Usage state, Status state, retry count, concurrency, prompt size, queue depth, recent changes를 넣는다.
API keys, bearer tokens, card details, private prompts, user data를 공개 장소에 올리지 않는다. 정리된 evidence가 support에는 더 빠르고 users에게는 더 안전하다.
자주 묻는 질문
OpenAI API 429는 모두 retry 가능한가요?
아니다. 오류 본문과 headers가 일시적인 request/token pressure를 가리킬 때만 retry한다. insufficient_quota는 Billing, Usage, Limits, project, organization, model access를 본다.
insufficient_quota는 무엇인가요?
quota, billing, spend cap, account state 문제다. 몇 초 기다리는 것으로 해결되지 않으므로 같은 project/org에서 확인한다.
크레딧이 있는데 왜 429가 나오나요?
다른 organization/project, spend cap, billing 반영 지연, model access, shared family limit, wrapper pool이 원인일 수 있다.
API key를 여러 개 만들면 제한이 늘어나나요?
같은 project/org라면 늘어나지 않는다. 새 key는 credential 문제를 고치지만 quota pool을 새로 만들지 않는다.
어떤 headers를 봐야 하나요?
limit, remaining, reset을 보여주는 rate-limit headers다. Limits 페이지와 함께 읽어야 한다.
OpenAI Status를 확인해야 하나요?
그렇다. incident가 있으면 기다리고 증거를 보존한다. green이면 account, headers, Limits, workload를 계속 확인한다.
ChatGPT Plus와 API quota는 같은가요?
아니다. ChatGPT 소비자 구독과 OpenAI Platform API billing은 별도다.
지원팀에는 무엇을 보내나요?
timestamp, timezone, request id, endpoint, model, project, organization, error body, safe headers, Limits/Usage, Status, retry count, workload, recent changes를 보낸다.
운영 리뷰 템플릿
모든 429를 같은 형식으로 남긴다. 시간, timezone, endpoint, model, project, organization, error body, headers, Limits, Usage, Billing, Status, retry count, concurrency, prompt size, queue depth, recent deploy를 한 줄씩 기록하면 "제한처럼 보인다"는 감각 대신 rate pressure, quota, billing, scope, status, provider route 중 어느 가지인지 비교할 수 있다.
리뷰에서는 세 가지를 묻는다. 첫째, 가장 먼저 강한 신호를 준 분기는 무엇이었는가. 둘째, evidence를 저장하기 전에 key, model, project, billing을 동시에 바꾸지 않았는가. 셋째, API rejection 전에 application이 먼저 처리했어야 할 production control은 무엇이었는가. 답이 central limiter, tenant budget, token estimate, queue, Batch, remaining/reset alert 중 하나로 남으면 다음 429는 더 짧고 비용이 낮다.