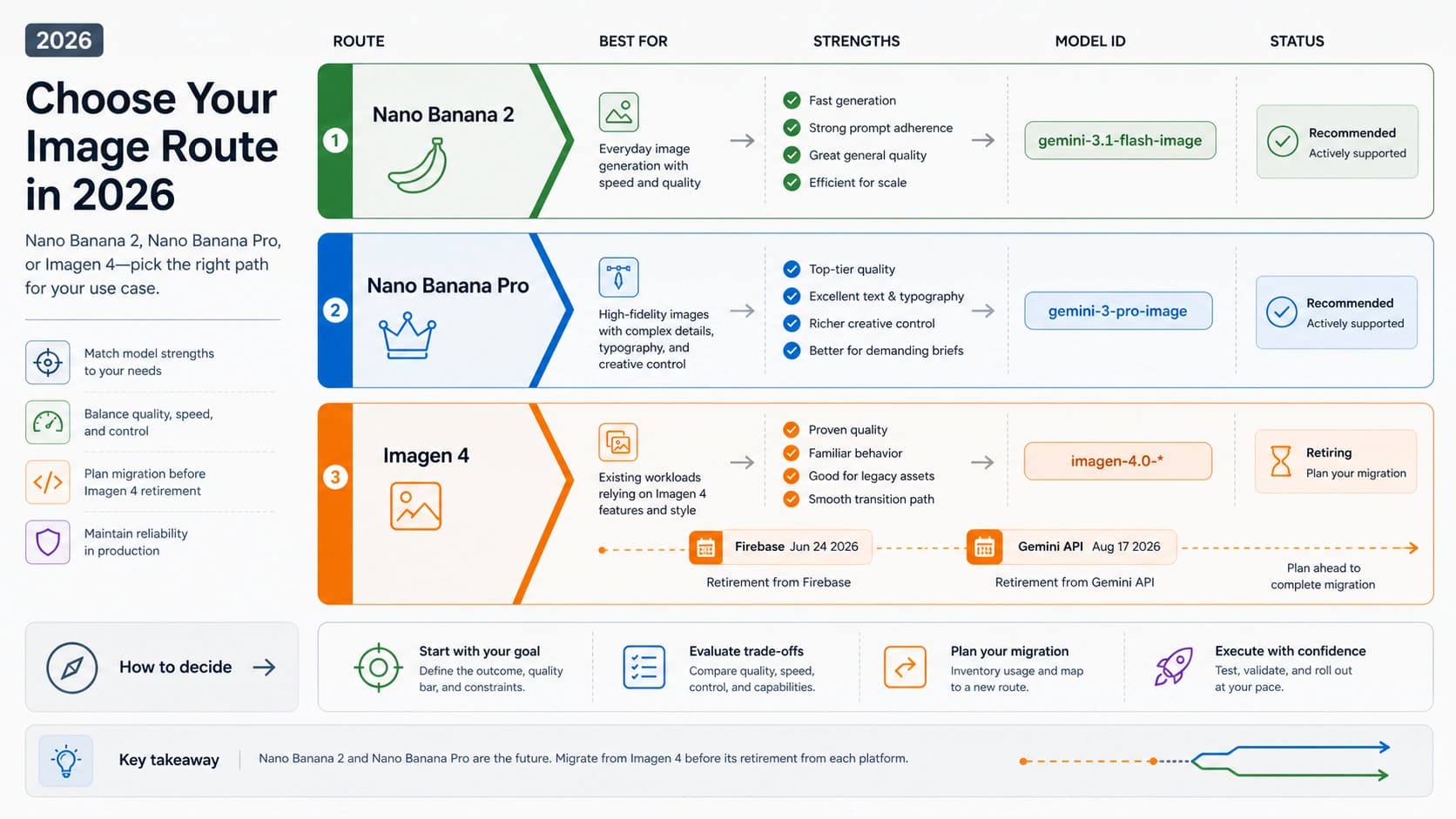
2026년 5월 7일 기준, 대부분의 Claude 작업은 Sonnet 4.6부터 시작하는 편이 맞습니다. Opus 4.7은 더 비싼 이름표가 아니라, 작업 난도와 실패 비용이 충분히 클 때 열어 두는 승격 모델입니다. Sonnet은 속도, 비용, 반복 실행, 운영 규모의 균형이 좋고, Opus는 고위험 추론, 복잡한 아키텍처, 긴 agent 실행, 무거운 문서 종합, 또는 Sonnet이 같은 검수 기준에서 계속 실패하는 경우에 테스트해야 합니다.
| 작업이 이런 모습이면 | 먼저 시도할 모델 | 승격 기준 |
|---|---|---|
| 일상 코딩, 리서치, 문서, 사무 분석, 브라우저나 컴퓨터 조작 흐름 | Sonnet 4.6 | 같은 오류를 반복하거나 수동 수정이 계속 커진다. |
| API 대량 호출이나 운영 트래픽 | Sonnet 4.6 | 실패, 재시도, 리뷰 비용이 Opus 프리미엄보다 크다. |
| 아키텍처 판단, 원인 분석, 여러 파일과 제약이 얽힌 추론 | Opus 4.7 테스트 레인 | 실제 산출물이 개선되지 않으면 Sonnet을 기준으로 둔다. |
| 장시간 agent 또는 다단계 워크플로 | Sonnet 기준선과 Opus 비교 | Opus가 계획 유지와 완주율에서 눈에 띄게 낫다. |
| 단순 추출, 분류, 형식 변환, 라우팅 | Haiku 4.5 보조 레인 | Haiku가 부족하면 Sonnet으로 올리고, 바로 Opus로 가지 않는다. |
가격표만 보면 판단이 단순해 보이지만 실제 비용은 그렇지 않습니다. Anthropic의 현재 문서에서 Sonnet 4.6은 100만 입력 token당 3달러, 100만 출력 token당 15달러이고, Opus 4.7은 각각 5달러와 25달러입니다. 그러나 최종 비용은 출력 길이, prompt caching, batch, thinking 설정, 재시도, 사람이 다시 보는 시간, 그리고 Opus 4.7 tokenizer가 같은 고정 텍스트를 더 많은 token으로 계산할 수 있다는 주의에 따라 달라집니다.
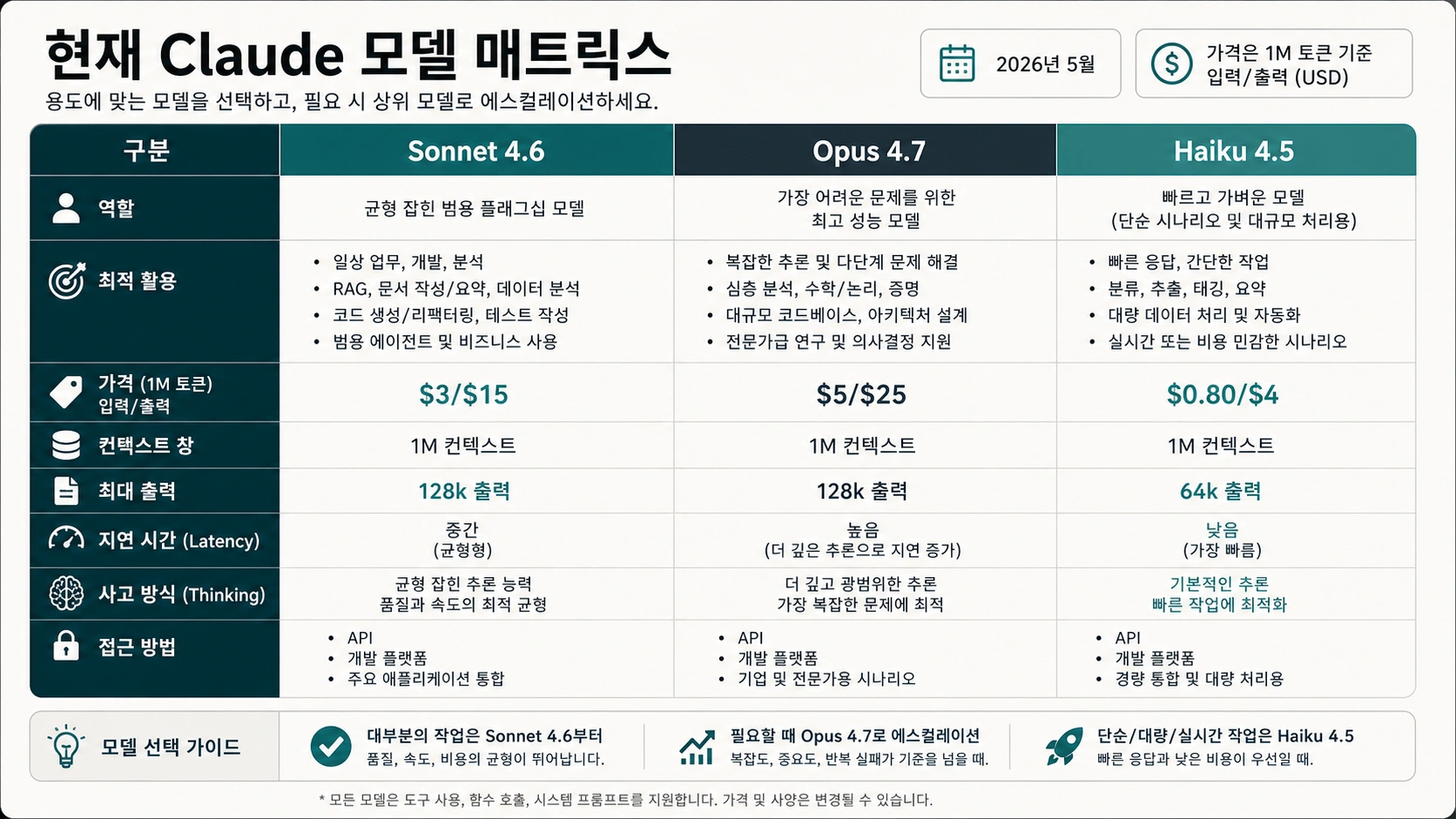
현재 비교 대상은 Opus 4.7과 Sonnet 4.6이다
한국어 비교 자료에는 Opus 4.5, Opus 4.6, Sonnet 4.5 또는 예전 Claude 4 기준의 정리가 아직 많습니다. 그런 자료는 사용감 참고로는 읽을 수 있지만, 지금 결정해야 할 문제는 현재 Sonnet 4.6을 기본으로 둘지, 특정 작업을 Opus 4.7로 올릴 가치가 있는지입니다.
Anthropic의 현재 모델 개요는 Opus 4.7, Sonnet 4.6, Haiku 4.5를 주요 계층으로 보여 줍니다. Opus 4.7은 전문 소프트웨어 엔지니어링, 복잡한 추론, agentic workflow, 고급 코딩, 고위험 기업 작업에 맞는 모델입니다. Sonnet 4.6은 일상 작업, 확장형 운영, 코딩, agent, 브라우저와 computer use, 긴 컨텍스트, 비용 효율적인 성능에 맞춘 균형형 모델입니다.
| 현재 공식 기준 | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| 실무 역할 | 대부분 작업의 기본 모델 | 가장 어려운 작업의 승격 모델 |
| API 가격, 2026-05-07 확인 | $3 입력 / $15 출력 per MTok | $5 입력 / $25 출력 per MTok |
| 지연 시간 계층 | Fast | Moderate |
| 컨텍스트 창 | 1M | 1M |
| 최대 출력 | 64k | 128k |
| thinking 지원 | Extended thinking 및 adaptive thinking | Adaptive thinking |
| 첫 사용처 | 일상 업무, 코딩 반복, 운영 처리 | 깊은 추론, agent 코딩, 고위험 판단 |
Haiku 4.5는 보조 선택지입니다. 단순 추출, 분류, 라우팅, 형식 변환처럼 위험이 낮고 빠른 처리만 필요한 곳에 맞습니다. 핵심 판단은 세 모델의 이름 설명이 아니라, Sonnet과 Opus 사이의 기본 경로와 승격 기준입니다.
Sonnet 4.6을 기본으로 둘 때
Sonnet의 장점은 단지 싸다는 점이 아닙니다. 충분히 똑똑하면서 빠르고, 비용 예측이 쉽고, 검증 루프를 붙이기 좋다는 점입니다. 일상 코딩, PR 리뷰, 문서 정리, 데이터 정리, 구조화 요약, 고객 지원 분류, 콘텐츠 초안, 사무 분석, 브라우저 자동화, 많은 API 운영 경로는 Sonnet부터 시작해야 합니다.
지시가 분명하고, 출력 형식이 측정 가능하고, 실패를 테스트나 리뷰로 잡을 수 있다면 Opus로 시작해도 결과가 거의 바뀌지 않을 수 있습니다. 운영 환경에서는 모델 이름보다 승인 가능한 결과까지 드는 총비용이 중요합니다. Sonnet으로 충분하다면 남는 예산을 검증, 두 번째 패스, 더 많은 테스트, 더 넓은 컨텍스트에 쓸 수 있습니다.
Sonnet부터 시작할 조건은 다음과 같습니다.
- 출력이 test, schema, rule, 사람이 보는 review로 확인된다.
- 호출이 잦아 token 비용이 빠르게 누적된다.
- 최대 깊이보다 빠른 반복이 더 중요하다.
- prompt와 성공 기준이 이미 명확하다.
- 모델이 전략을 새로 만들기보다 절차를 따라야 한다.
- 실패가 retry, lint, unit test, validation, 사람 검수에서 잡힌다.
Claude 앱 사용자에게 Sonnet은 보통 자연스러운 출발점입니다. API 사용자에게도 현재 공식 가격 행이 낮고 확장형 사용에 맞기 때문에 첫 운영 후보가 되어야 합니다.
Opus 4.7을 테스트할 가치가 있는 경우
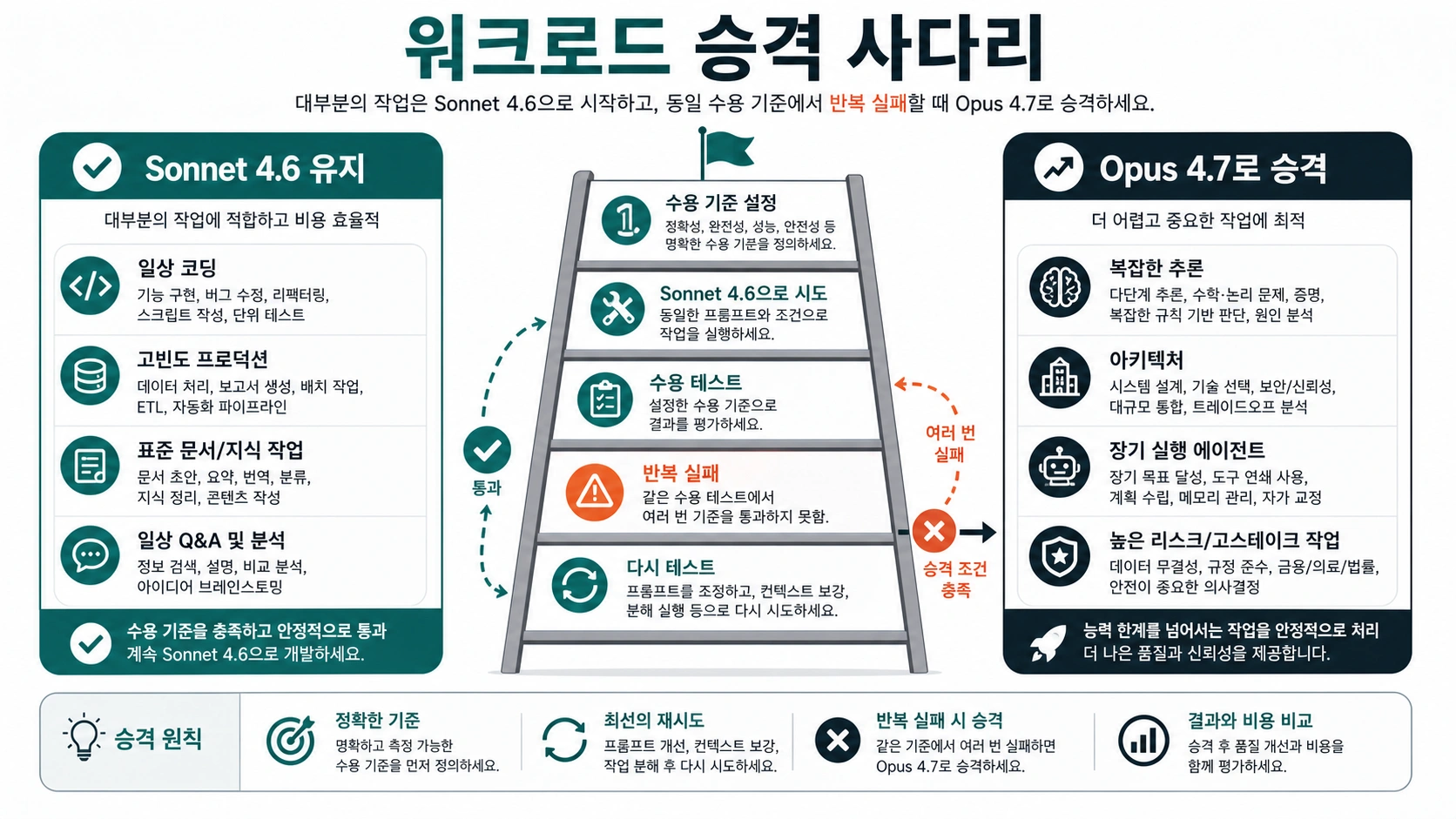
Opus는 실패 비용이 크고, 컨텍스트가 지저분하고, 판단이 모호하고, 저렴한 재시도로는 품질이 올라가지 않을 때 가치가 있습니다. 중요한 작업이라서 무조건 Opus가 아니라, 더 깊은 추론과 더 긴 계획 유지가 결과를 바꾸는 작업에서 필요합니다.
Opus 4.7 테스트 레인을 열어야 할 조건은 다음과 같습니다.
- Sonnet이 prompt를 정리한 뒤에도 같은 acceptance criterion을 놓친다.
- 여러 파일, 시스템, 제약을 넘나드는 아키텍처 판단이 필요하다.
- 긴 문서 묶음을 읽고 예외와 뉘앙스를 보존해야 한다.
- 장시간 agent가 계획을 잃거나, 루프를 돌거나, 취약한 지름길을 택한다.
- 결과가 엔지니어링, 법무, 재무, 기업 의사결정에 직접 영향을 준다.
- 원인 분석에서 그럴듯한 추측 하나가 큰 비용을 만든다.
- 사람이 다시 보는 시간이 가장 큰 비용이 되었다.
Opus는 모든 prompt의 상위 호환이 아닙니다. Sonnet과 같은 답을 내거나 문장만 더 매끈해진다면 Sonnet을 유지하세요. Opus가 나쁜 설계 결정을 막고, 숨은 의존성을 찾고, Sonnet이 완주하지 못한 긴 실행을 끝낼 때만 비용 차이가 의미 있습니다.
비용 차이는 가격표보다 크다
Anthropic pricing 페이지는 token 단가의 기준이지만, 가격표가 전체 작업 비용은 아닙니다. Sonnet 4.6의 $3/$15와 Opus 4.7의 $5/$25는 기본 차이일 뿐입니다. 실제 비용은 출력 길이, 반복 컨텍스트, cache write와 cache hit, batch 가능 여부, thinking 강도, tool schema, 재시도, 사람 리뷰 시간으로 달라집니다.
현재 pricing 페이지는 Opus 4.7이 새로운 tokenizer를 사용하며, 내용에 따라 같은 고정 텍스트가 최대 35% 더 많은 token으로 계산될 수 있다고 설명합니다. 모든 호출이 35% 더 비싸다는 뜻은 아니지만, 지난달 Sonnet token 수에 Opus 가격만 곱해서 예산을 잡으면 안 된다는 뜻입니다.
| 비용 층 | 선택에 미치는 영향 |
|---|---|
| 입력과 출력 단가 | Opus는 token당 더 비싸다. |
| 출력 길이 | 깊은 답변은 더 길어질 수 있다. |
| prompt caching | 반복 입력을 줄일 수 있지만 cache write도 비용이다. |
| batch | 비동기 작업은 더 싸질 수 있다. |
| thinking | 어려운 답을 개선하지만 비용과 지연을 늘릴 수 있다. |
| tokenizer | Opus 4.7은 같은 텍스트를 다르게 셀 수 있다. |
| 사람 리뷰 | 비싼 모델이 수정을 줄이면 총비용은 낮아질 수 있다. |
올바른 질문은 “어느 모델의 단가가 낮은가”가 아니라 “이 워크플로에서 승인 가능한 결과를 가장 낮은 비용으로 만드는 모델은 무엇인가”입니다.
기본 모델을 바꾸기 전에 같은 워크플로로 테스트하기
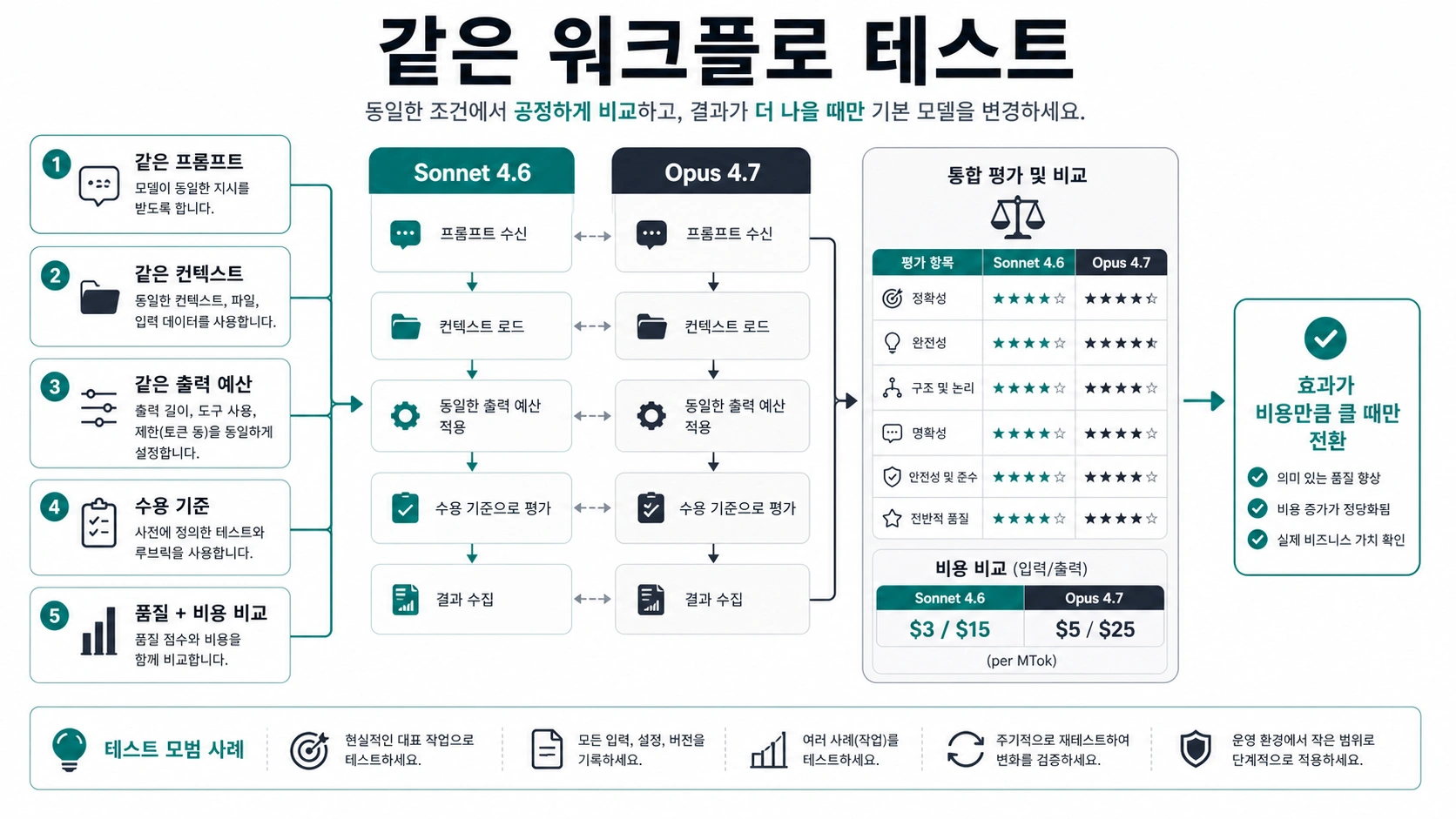
모델 이름만 보고 운영 기본값을 바꾸지 마세요. 공정한 테스트는 prompt, context, output budget, tools, acceptance criteria를 최대한 같게 둡니다. 이 조건이 바뀌면 모델 차이가 아니라 다른 작업을 비교하게 됩니다.
작은 테스트 절차는 다음과 같습니다.
- 실제 워크플로에서 대표 작업 세 개에서 다섯 개를 고른다.
- 민감한 데이터를 제거하거나 승인된 환경에서만 실행한다.
- 현재 prompt와 예산으로 Sonnet 4.6을 실행한다.
- 같은 prompt, context, 예산으로 Opus 4.7을 실행한다.
- 동일한 기준으로 두 결과를 평가한다.
- token cost, latency, retries, review time, 최종 승인 결과를 기록한다.
- Opus의 개선이 비용 차이를 넘어서는 slice만 승격한다.
이 방법은 반대 실수도 막습니다. Sonnet 단가만 보고 유지했지만 재시도와 사람 수정 때문에 더 비싸지는 경우가 있기 때문입니다. 많은 팀에는 Sonnet이 일반 트래픽을 맡고, Opus가 어려운 예외를 맡는 혼합 전략이 더 좋습니다.
Claude 앱, API, Claude Code는 서로 다른 표면이다
Claude 앱에서 모델을 고르는 것, Claude Platform API에서 model ID를 호출하는 것, Claude Code 세션에서 실제 어떤 모델이 쓰이는 것은 관련되어 있지만 같은 문제가 아닙니다. 앱 사용자는 플랜과 메시지 제한을 봅니다. API 개발자는 token 가격, rate limit, caching, batch, 통합 동작을 봅니다. Claude Code 사용자는 구독 로그인, API key, 로컬 설정도 확인해야 합니다.
경계를 나누면 다음과 같습니다.
- Pro, Max, API billing을 고르는 문제라면 접근과 결제 문제입니다.
- Claude Code를 무료 또는 Pro로 쓸 수 있는지라면 사용 경로 문제입니다.
- 어떤 작업을 어떤 모델에 보낼지라면 Sonnet, Opus, Haiku, 테스트 레인을 고르는 문제입니다.
접근 권한을 샀다고 모델 라우팅이 끝난 것은 아닙니다. Pro 사용자도 대부분 Sonnet을 기본으로 둘 수 있습니다. Opus API 접근권이 있는 팀도 어려운 slice만 Opus에 보낼 수 있습니다. Claude Code도 현재 세션이 어느 경로로 작동하는지 먼저 확인해야 합니다.
자주 묻는 질문
Opus가 항상 Sonnet보다 좋은가요?
Opus 4.7은 가장 어려운 작업의 승격 모델로 더 강하지만, 모든 작업의 기본값은 아닙니다. 속도, 비용, 운영 규모가 중요하면 Sonnet 4.6부터 시작하는 편이 낫습니다.
먼저 무엇을 써야 하나요?
대부분은 Sonnet 4.6입니다. 작업이 고위험, 모호함, 장시간, 아키텍처 중심, 문서 중심이거나 Sonnet이 같은 기준에서 반복 실패하면 Opus 4.7을 비교하세요.
Opus는 Sonnet보다 얼마나 비싼가요?
2026년 5월 7일 기준 공식 행은 Sonnet 4.6을 $3 입력, $15 출력 per MTok, Opus 4.7을 $5 입력, $25 출력 per MTok으로 제시합니다. 실제 비용은 출력 길이, cache, batch, thinking, retry, tokenizer로 달라집니다.
Sonnet으로 코딩하기 충분한가요?
많은 coding loop, PR review, refactor, test, 일반 agent에는 Sonnet 4.6이 충분합니다. 여러 제약이 얽힌 설계, 원인 분석, 반복 실패 작업에서는 Opus를 같은 조건으로 테스트하세요.
Claude Code는 Opus를 쓰나요, Sonnet을 쓰나요?
Claude Code의 모델 동작은 제품, 플랜, 설정, 경로에 따라 달라질 수 있습니다. Claude Code는 작업 표면이고, Opus와 Sonnet 선택 자체는 아닙니다. 일반 코딩은 Sonnet, 어려운 repo task는 Opus를 비교하세요.
Haiku는 어디에 쓰나요?
Haiku 4.5는 빠르고 싼 보조 경로입니다. 추출, 분류, 라우팅, 형식 변환, 낮은 위험의 batch 작업에 씁니다. 부족하면 Sonnet으로 올리고 바로 Opus로 가지 않습니다.
예전 Opus 4.5 또는 Sonnet 4.5 조언은 유효한가요?
역사적 참고로는 읽을 수 있지만, 현재 선택은 Opus 4.7과 Sonnet 4.6의 공식 사실로 다시 판단해야 합니다.
팀은 언제 두 모델을 모두 써야 하나요?
저렴한 일반 경로와 어려운 예외 경로가 나뉠 때입니다. Sonnet은 기본 트래픽을 처리하고, Opus는 Sonnet 테스트 실패, 깊은 추론, 높은 리뷰 비용이 있는 작업을 처리합니다.