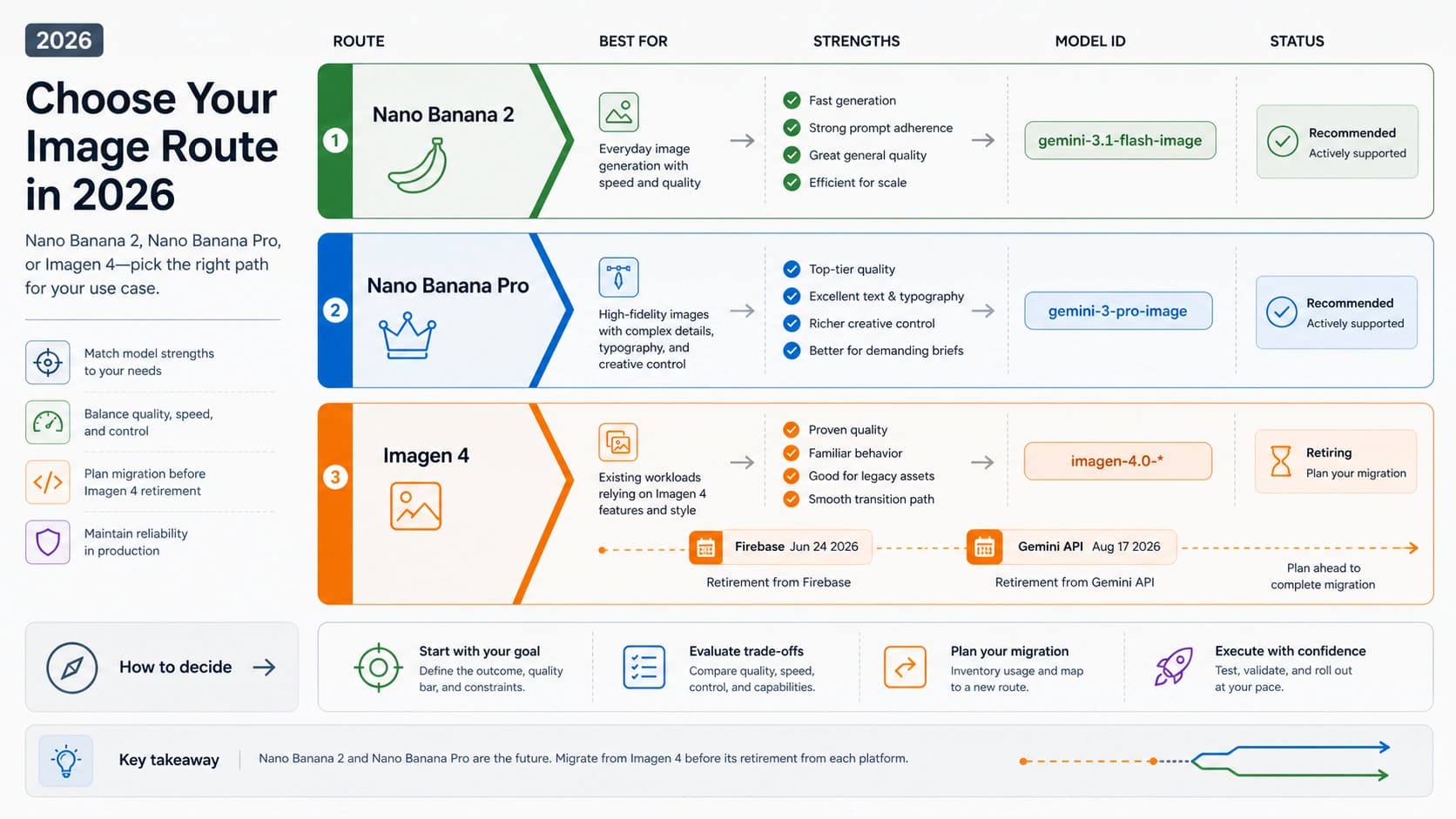
2026년 5월 8일 기준으로 Qwen을 고를 때는 가장 긴 모델명부터 비교하지 말고 사용 경로를 먼저 나누는 편이 안전합니다. 일반적인 안정 API 통합은 Plus 계열의 안정 후보부터 시험하고, 지연 시간이나 비용이 더 중요하면 빠른 API 후보를 먼저 봅니다. 최신 상위 품질을 확인하려면 평가용 후보를 따로 두고, 로컬 또는 서버에서 직접 운영할 제어권이 필요하면 dense 또는 MoE open-weight 후보를 봅니다. 음성·이미지·비디오·혼합 입력은 Omni, 코드 생성과 리포지토리 작업은 Coder를 별도 경로로 평가합니다.
이 이름들은 하나의 단순한 순위표가 아닙니다. API 계열 후보는 hosted API 선택지이고, open-weight 계열 후보는 배포 판단입니다. Omni는 입력과 출력의 형태를 바꾸고, Coder는 평가 대상을 소프트웨어 엔지니어링 작업으로 바꿉니다. 같은 Qwen 계열이라도 확인해야 할 증거는 모델 ID, 가격, region, quota, license, hardware, serving stack, repository context처럼 서로 다릅니다.

| 해야 할 일 | 먼저 볼 후보 | 이 경로를 먼저 보는 이유 | 가정하지 말 것 | 운영 전 재확인 |
|---|---|---|---|---|
| 안정적인 일반 API 통합 | Qwen3.6-Plus | support, RAG, extraction, 업무 자동화에 맞는 hosted API 기본 후보 | Max-Preview가 항상 production 기본값 | model ID, region, price, context, quota |
| 빠르거나 비용 민감한 API | Qwen3.6-Flash | API 경로를 유지하면서 latency와 operating cost를 우선 | Flash와 35B-A3B가 같은 선택 | pricing, rate limits, 품질 차이, 지역 |
| 최신 Max 계열 품질 평가 | Qwen3.6-Max-Preview | 어려운 prompt, migration 판단, agent behavior 확인에 적합 | preview가 장기 안정성을 의미 | preview status, migration path, provider support |
| 로컬 또는 서버 오픈웨이트 운영 | Qwen3.6-27B / 35B-A3B | weights, license, hardware, serving stack을 직접 확인 | open model이 hosted API 계약을 증명 | model card, license, weights, serving stack |
| 음성·이미지·비디오 | Qwen3.5-Omni | 작업의 중심이 text-only가 아니라 media | Omni가 모든 text/code 경로를 대체 | modalities, latency, streaming, API support |
| 코딩 에이전트와 소프트웨어 작업 | Qwen3-Coder-Plus | repository context, patch, test repair를 측정 | 일반 chat 성능이 coding 성능과 동일 | tooling, context, repo workflow, API availability |
운영 전에는 잠시 멈춰야 합니다. Provider catalog와 커뮤니티 글은 접근 경로를 찾는 데 도움이 되지만, model identity, price, license, context, region, quota, support에 관한 운영 주장은 해당 경로의 책임 있는 출처에서 다시 확인해야 합니다.
모델 이름보다 사용 경로가 먼저입니다
Qwen 계열은 단순히 더 큰 모델이 더 좋은 모델이라는 방식으로 고르기 어렵습니다. 실제 의사결정은 hosted API를 쓸지, 오픈웨이트를 직접 운영할지, media input을 처리할지, coding agent를 만들지로 나뉩니다. Hosted API에서는 정확한 model ID, billing owner, quota, region, response shape, support가 중요합니다. Open weights에서는 license, weights version, GPU memory, quantization, prompt template, serving framework, monitoring이 중요합니다. Omni에서는 audio/video/image 경계가, Coder에서는 repository context와 test feedback이 중요합니다.
Qwen 공식 사이트와 Alibaba Cloud Model Studio는 hosted API의 모델명과 capability row를 확인하는 곳입니다. QwenLM repository와 model card는 오픈웨이트의 release identity, license, 변경 사항을 확인하는 곳입니다. Qwen-Omni 문서는 multimodal input/output 경계를 확인하는 곳입니다. Provider catalog는 빠른 시험에 유용하지만 official status, license, long-term support를 대신 증명하지는 않습니다.
따라서 먼저 질문을 바꿔야 합니다. 오늘 바로 managed API endpoint가 필요한가, 모델을 직접 실행해야 하는가, 입력이 media인가, 소프트웨어 작업을 맡길 것인가, provider를 단기 시험 경로로만 쓸 것인가. 이 질문이 정리되면 Plus와 Flash는 API tradeoff로, 27B와 35B-A3B는 deployment choice로, Omni와 Coder는 workflow-specific test로 비교할 수 있습니다.
| 판단 층 | 결정하는 것 | 첫 질문 |
|---|---|---|
| Hosted API | model ID, billing, quota, region, API behavior, support | 오늘 managed endpoint가 필요한가 |
| Open weights | weights, license, hardware, serving stack, reproducibility | 직접 실행하거나 검사해야 하는가 |
| Omni | audio, image, video, mixed interaction | 작업이 실제로 multimodal인가 |
| Coder | code generation, repo work, agents, IDE/CLI workflow | 평가 대상이 software engineering인가 |
| Provider | access wrapper, catalog mapping, credit, retry, data terms | official fact인지 access route인지 |
API 작업은 Plus, Flash, Max-Preview를 같은 과제로 비교합니다
일반적인 production-style API 통합에서는 Qwen3.6-Plus를 첫 후보로 두는 것이 자연스럽습니다. 고객 지원, RAG, structured extraction, drafting, classification, business workflow automation처럼 안정적인 response shape와 운영 지원이 중요한 경우 hosted API 기본값이 검증하기 쉽습니다. Plus를 선택하는 이유는 모든 Qwen보다 항상 강해서가 아니라, 통합 정확성, region, quota, 비용, support boundary를 확인하기 쉽기 때문입니다.
Qwen3.6-Flash는 같은 API 경로에 있지만 주된 기준이 다릅니다. latency, throughput, operating cost가 품질 상한보다 중요할 때 시험합니다. 배치성 가벼운 작업, 내부 도구, 빠른 응답 UX, 비용 상한이 있는 실험에 맞습니다. Flash는 35B-A3B와 같은 종류의 선택이 아닙니다. Flash는 managed API의 속도와 비용이고, 35B-A3B는 self-hosted control입니다.
Qwen3.6-Max-Preview는 최신 Max-class behavior를 평가하는 경로로 다루는 편이 안전합니다. 어려운 prompt, reasoning stress, migration planning, agentic behavior 확인에는 유용하지만, 운영 기본값으로 쓰려면 current official docs, account region, price, quota, context, provider support, migration plan을 먼저 확인해야 합니다.
API 비교는 작고 반복 가능해야 합니다. 실제 업무를 대표하는 prompt set 하나를 고르고 output format, latency, failure mode, cost unit, review result를 같은 방식으로 기록합니다. Plus에서는 support prompt, Coder에서는 repository patch, Omni에서는 audio turn을 돌린 뒤 하나의 순위로 합치면 안 됩니다. 작업 표면이 달라지면 비교 기준도 달라집니다.
27B와 35B-A3B는 오픈웨이트 제어권이 필요할 때 봅니다
Qwen3.6-27B와 Qwen3.6-35B-A3B의 핵심 가치는 더 싼 API가 아니라 제어권입니다. private environment에서 실행해야 하거나, weights version을 고정해야 하거나, 내부 inference server와 monitoring, rollback, data boundary를 직접 관리해야 한다면 open-weight route가 의미를 가집니다.
27B는 dense model 기준선을 만들기 좋은 후보입니다. serving framework, GPU memory, context handling, prompt template, batching, logging을 확인하고 같은 task에서 quality와 latency를 봅니다. 하지만 parameter count만으로 hardware fit을 결정하면 위험합니다. model card와 실제 serving stack에서 확인해야 합니다.
35B-A3B는 다른 종류의 open model choice입니다. A3B 표기는 dense 35B와 같은 방식으로 읽기 어려운 active parameter behavior를 가리킵니다. throughput, memory planning, benchmark interpretation, serving economics에 영향을 주므로 community performance claim만으로 capacity planning을 만들면 안 됩니다.
오픈웨이트 평가는 네 단계가 최소입니다. 정확한 model card와 repository source 확인, license와 intended use 확인, 실제 운영할 serving stack에서 same-task test, quality와 latency, memory, observability, failure recovery, update cost를 함께 비교하는 것입니다. hosted API 장애와 self-hosted 장애는 같은 Qwen 이름 아래에서도 조사 위치가 완전히 다릅니다.

Omni와 Coder는 일반 채팅 평가에서 분리해야 합니다
Qwen3.5-Omni는 multimodal route입니다. speech understanding, audio interaction, image-plus-text input, video segment, mixed media assistant가 핵심이면 먼저 볼 수 있습니다. 그러나 text-only prompt로 Omni를 평가하면 audio path, video latency, streaming behavior, media preprocessing, error handling을 검증하지 못합니다.
Omni 테스트는 실제 input shape로 시작해야 합니다. 오디오 클립, 이미지와 질문, 비디오 일부, media turn이 포함된 상호작용을 사용하고 latency, output format, streaming, cost, failure recovery를 기록합니다. 순수 텍스트 작업이라면 Plus나 Flash가 더 직선적인 선택인지 같이 확인합니다.
Qwen3-Coder-Plus는 coding-specialized lane입니다. code generation, debugging, refactoring, repository analysis, agentic coding, test repair를 평가할 때 의미가 있습니다. 일반 설명을 잘하는 모델이 실제 codebase에서 올바른 파일을 고르고 작은 patch를 만들며 test failure를 읽을 수 있는 것은 아닙니다.
코딩 평가는 repeatable same-repository task로 합니다. 작은 bug fix, 제약이 있는 refactor, API integration, test repair, code review를 같은 기준으로 돌립니다. patch scope, unrelated churn, compatibility, line-level evidence를 보지 않으면 coding-agent quality를 판단하기 어렵습니다.
| 테스트 | 측정할 것 | 의미 |
|---|---|---|
| 작은 bug fix | file selection, minimal patch, test result | 실제 codebase 안에서 행동하는지 확인 |
| 제약 있는 refactor | scope control, compatibility, unrelated churn 없음 | 넓은 rewrite를 피하는지 확인 |
| API integration | docs following, error handling, environment assumptions | developer workflow를 테스트 |
| Test repair | failure 읽기, 원인 추정, 제한된 수정 | loop discipline을 확인 |
| Code review | 구체적 bug, line evidence, risk judgment | 코드를 생성뿐 아니라 비판할 수 있는지 확인 |
Provider는 접근 경로이지 공식 사실의 소유자가 아닙니다
Provider catalog와 unified gateway는 유용합니다. OpenAI-compatible endpoint, playground, price unit, latency sample, credit rule을 빠르게 보여 주기 때문입니다. 평가 시작 비용을 낮추지만, catalog row가 official model identity, preview status, license, context window, region support, long-term support를 증명하지는 않습니다.
증거 계층을 나눠야 합니다. Hosted API model ID와 availability는 Alibaba Cloud Model Studio나 Qwen official surface, open-weight release identity는 QwenLM repository나 official model card, license는 model card와 repository license, provider endpoint와 retry/data terms는 provider docs와 dashboard, 실제 workload quality는 same-task test에서 확인합니다.
가격, free quota, rate limit, context window, region, provider coverage, preview status, migration notes는 변하기 쉽습니다. 내부 제안이나 구현 문서에 source owner와 checked date가 없다면 확정 문구로 쓰지 않는 편이 안전합니다. Provider가 access route를 제공하는 것과 Qwen이 그 provider를 통해 장기 production stability를 보장하는 것은 다른 말입니다.
| 의존하려는 주장 | 강한 확인처 | 약한 확인처 |
|---|---|---|
| official model ID / API availability | Alibaba Cloud Model Studio / Qwen official page | provider catalog row |
| open-weight release identity | QwenLM repository / official model card | forum or benchmark roundup |
| license and model-card notes | official model card and repository license | screenshot or social post |
| provider endpoint, credit, retry, data terms | provider docs and dashboard | another catalog summary |
| real workload fit | same-task test, model card, hands-on report | single benchmark number |
운영 전에는 빨리 바뀌는 사실을 다시 확인합니다
최종 선택은 하나의 Qwen 모델을 영구히 고르는 형태보다 primary route와 fallback rule의 조합으로 만드는 편이 좋습니다. Plus를 안정 API 기본값으로 두고 Flash를 latency-sensitive branch로 둘 수 있습니다. 35B-A3B를 self-hosted code review 후보로 보고 Coder-Plus를 hosted coding-agent branch로 둘 수 있습니다. Omni를 media turn에 쓰고 text-only support는 Plus로 되돌릴 수도 있습니다.
운영 전에는 exact model ID, preview/stable status, context window, output limits, price, quota, region, license, provider mapping, model-card updates, migration notes를 다시 확인합니다. API는 Alibaba Cloud Model Studio와 Qwen official surface, open weights는 QwenLM과 model card, provider access는 provider dashboard가 책임 있는 확인처입니다.
cost, availability, legal use, data boundary, uptime에 영향을 주는 claim은 기억에 의존하면 안 됩니다. 실험은 provider catalog에서 빠르게 시작할 수 있지만 code, procurement, customer promise에 들어가려면 current source와 checked date가 필요합니다. 확인되지 않는 claim은 애매하게 남기기보다 제거하는 편이 안전합니다.

| 운영 전 | 확인처 | 생략 시 위험 |
|---|---|---|
| hosted API model ID | Alibaba Cloud Model Studio docs | deprecated, preview, wrong model을 호출 |
| preview/stability status | Qwen or Alibaba official surfaces | preview test가 production assumption이 됨 |
| pricing and quotas | current billing, pricing, rate-limit surfaces | prototype이 비싸거나 throttled됨 |
| region and account support | account dashboard and official docs | docs에는 있지만 account에서 못 씀 |
| open-weight license | repository and model card | deployment가 usage terms와 충돌 |
| hardware and serving plan | serving stack plus model-card guidance | local success가 production latency/memory를 못 버팀 |
| provider mapping | provider dashboard and docs | provider label이 official route와 다름 |
| benchmark claim | benchmark owner or own same-task test | ranking number가 workload를 예측하지 못함 |
FAQ
Qwen 모델은 무엇부터 시험해야 하나요?
일반 hosted API 통합은 Qwen3.6-Plus부터 시작합니다. 속도나 비용이 더 중요하면 Qwen3.6-Flash, 최신 Max 계열 평가라면 Qwen3.6-Max-Preview, open weights가 필요하면 Qwen3.6-27B 또는 Qwen3.6-35B-A3B, media 작업은 Qwen3.5-Omni, coding agent는 Qwen3-Coder-Plus입니다.
빠른 API 후보와 open-weight MoE 후보는 같은 종류인가요?
아닙니다. Flash는 hosted API route이며 latency, throughput, cost가 핵심입니다. 35B-A3B는 open-weight route이며 weights, license, hardware, serving stack, self-hosted responsibility가 핵심입니다.
최상위 평가용 후보는 언제 쓰나요?
quality ceiling, difficult prompts, migration planning, newest Max-class behavior를 평가할 때 사용합니다. 운영 기본값으로 쓰기 전에는 official docs, account region, price, quota, context, support boundary를 확인해야 합니다.
Qwen3.5-Omni는 언제 적합한가요?
audio, speech, image, video, mixed media interaction이 핵심일 때 적합합니다. text-only support나 extraction이면 Plus나 Flash를 먼저 확인하는 편이 자연스럽습니다.
Qwen3-Coder-Plus는 언제 적합한가요?
code generation, debugging, repository analysis, refactoring, test repair, coding-agent workflow가 평가 대상일 때 적합합니다. generic chat이 아니라 real repository task로 비교해야 합니다.
Provider catalog로 Qwen availability를 증명할 수 있나요?
해당 provider를 통해 access할 수 있음을 보여줄 수는 있습니다. official model identity, release status, API behavior, license, long-term support는 Qwen, Alibaba Cloud Model Studio, QwenLM, official model card에서 확인해야 합니다.
운영 직전에 무엇을 확인해야 하나요?
exact model ID, preview/stable status, context window, output limits, price, quota, region, license, provider mapping, migration notes입니다. cost, legal use, availability, stability에 영향을 주는 claim은 current proof가 필요합니다.