Медленный вызов GPT Image 2 API не стоит сразу считать проблемой модели. Сложный prompt, несколько reference images, высокий quality или большой размер действительно могут держать запрос почти две минуты. Но в продакшене часто ломается не модель, а слой вокруг нее: браузер закрывает fetch, serverless worker достигает своего лимита, reverse proxy обрывает idle connection, gateway делает невидимый повтор, а фронтенд показывает пользователю обычный spinner и провоцирует второй клик. Поэтому первый проход — не оптимизация, а аудит времени.
| Симптом | Первая классификация | Безопасное первое действие |
|---|---|---|
| Первый байт поздний, но изображение приходит | длинная генерация или очередь | показывать статус, рассмотреть streaming или async job, затем отдельно тестировать low quality или square output |
| Backend завершил работу, но браузер упал | ложный таймаут | расширить только слой, который реально оборвал ожидание |
| Растут повторы или появляется 429 | давление retries и rate limits | остановить плотные повторы, читать reset headers, выпускать очередь с backoff |
| Медленно только через gateway | задержка владельца маршрута | сравнить тот же запрос с более прямым маршрутом и эскалировать с обезличенными метриками |
Не меняйте ключи, провайдера, quality и retry policy до того, как известно, какие часы сломались и кому принадлежат логи.
Сначала разделите медленную генерацию и ложный таймаут
Один общий лог duration_ms=90000 почти бесполезен. Он не говорит, молчал ли маршрут до первого байта, пришел ли partial image, закончила ли модель работу, долго ли скачивался файл, сколько было повторов и какой слой остановил запрос. Для GPT Image 2 нужен журнал с несколькими часами, иначе команда будет спорить о модели, когда реальная проблема находится в proxy или frontend timeout.
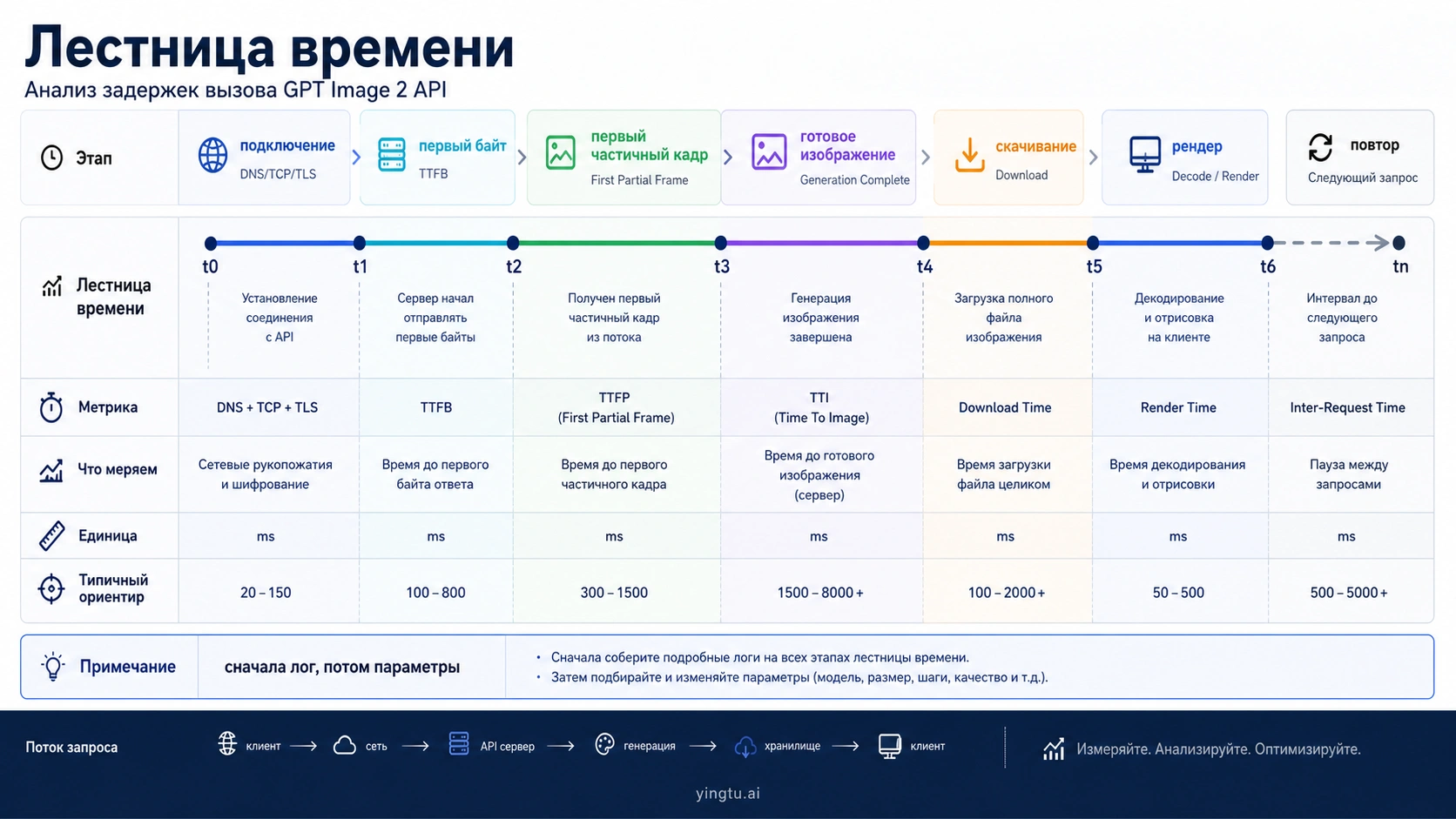
Минимальное событие для каждой image job должно включать request_started_at, connect_ms, first_byte_ms, first_partial_image_ms, final_image_ms, download_ms, render_ms, retry_count, retry_reason, http_status, error_type, request_id, model, quality, size, format и route_owner. Эти поля позволяют понять, что именно ожидало: сеть, модель, файл, браузер или повтор.
Route owner важен так же, как само время. OpenAI direct, Azure deployment, compatible gateway и reverse route могут использовать один model label, но иметь разные timeouts, headers, retries и support path. Если одинаковый prompt быстрый на одном маршруте и медленный на другом, модель перестает быть единственным подозреваемым.
Постройте timeout budget под изображение, а не под обычный API
Синхронный HTTP путь плохо подходит для долгой генерации, если внешний слой не знает, что именно он ждет. Браузер, CDN, worker, proxy, gateway и SDK не должны иметь один и тот же огромный timeout. У каждого слоя должна быть своя обязанность: быстро проверить connection, держать upstream только там, где это нужно, или передать работу в async job.
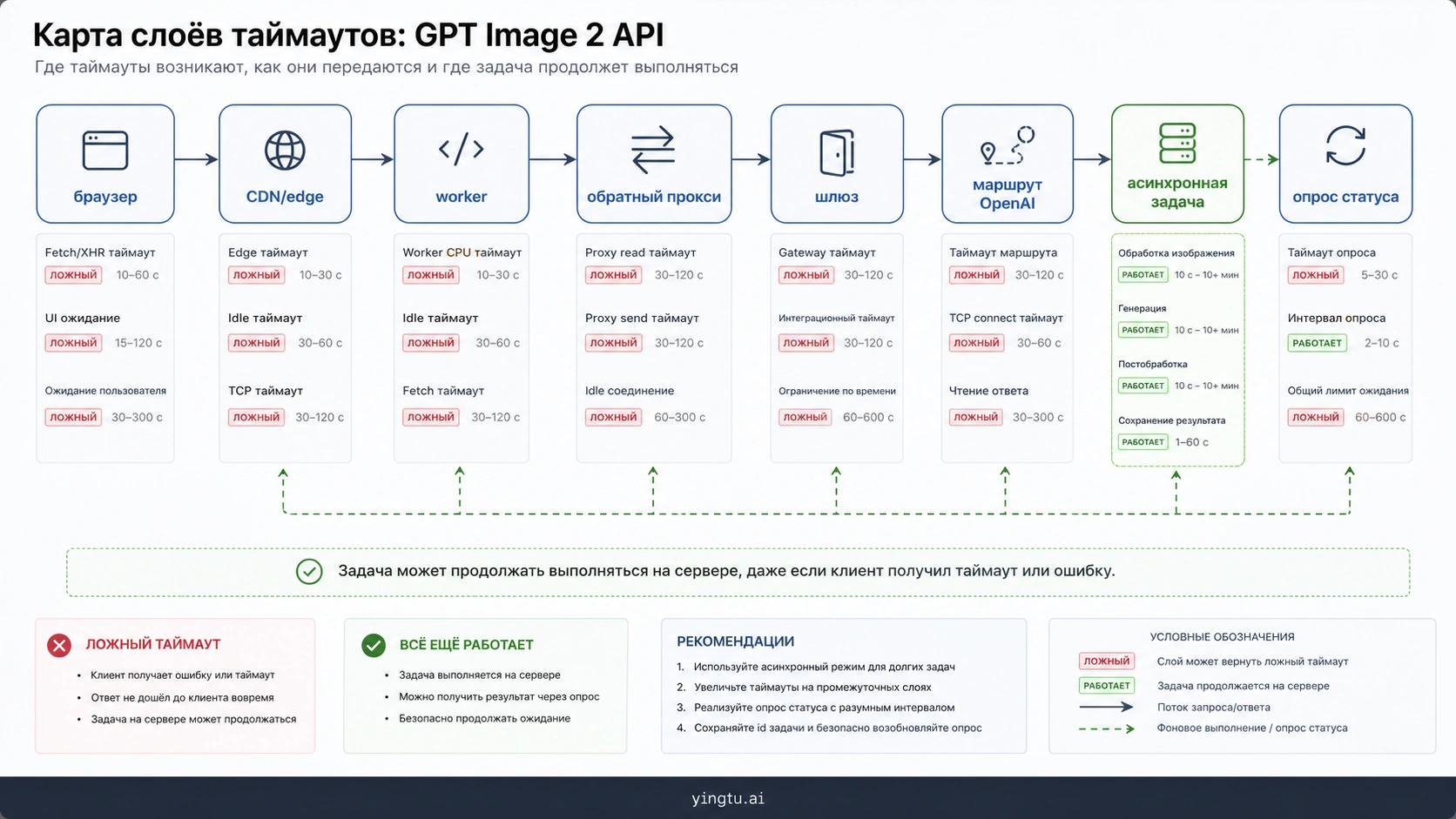
| Слой | Как обычно ломается | Более точное правило |
|---|---|---|
| Browser / mobile client | fetch abort до окончания backend job | вернуть job id, progress stream или polling status |
| CDN / edge function | платформа режет длинный request | не держать image generation внутри короткого edge path |
| Serverless worker | function timeout срабатывает раньше модели | использовать long-running worker, queue или background job |
| Reverse proxy | idle или upstream timeout | расширять только image route, не весь proxy globally |
| Gateway/provider | late response или скрытые retries | отдельно проверять provider logs, upstream status и timeout |
| SDK/HTTP client | локальный abort до upstream результата | задать явный timeout, связанный с product path и retry policy |
Для интерактивного продукта лучше вернуть стабильный job id и статус: queued, generating, partial preview, finalizing, saved, failed by upstream, failed by local timeout. Такой язык уменьшает повторные клики и помогает support понять, была ли создана еще одна image job.
Меняйте параметры только после baseline
Официальные параметры действительно влияют на работу. Low quality подходит для drafts, square output часто проще и быстрее, JPEG может быть быстрее PNG при latency-sensitive preview, а сложные prompts могут ждать почти две минуты. Но эти факты не означают, что первое действие — снизить качество. Сначала нужен baseline на той же route owner, с тем же prompt, size, quality, format и retry policy.
| Изменение | Что может улучшить | Что может испортить | Когда пробовать |
|---|---|---|---|
| quality low | быстрый draft feedback | детали, текст, polish | ideation, thumbnail, internal preview |
| square output | меньше layout и generation risk | неподходящий aspect ratio | когда можно crop или compose later |
| JPEG | transfer и browser decode | transparency и post-production | preview или photographic output |
| PNG/WebP | downstream quality и compression control | больше transfer/processing | когда asset идет в production |
| меньше reference images | input processing и upload overhead | style, identity, composition control | когда references не дают выгоды |
| simpler prompt | меньше model work | слабее art direction | когда slow clock внутри generation stage |
Если изображение является продуктовой ценностью, качество нельзя приносить в жертву ради одного графика. Для качества используйте /ru/blog/gpt-image-2-low-quality/, для больших размеров — /ru/blog/gpt-image-2-4k-image-generation/. Текущий путь остается про latency diagnosis.
Streaming и async улучшают ощущение, но не отменяют финальное время
Streaming partial images полезен тем, что пользователь видит движение до final image. Это снижает повторные клики и помогает понять, жив ли маршрут. Но final_image_ms все равно остается отдельным clock. Если streaming недоступен или усложняет frontend, async job с polling часто надежнее открытого browser request.
Хорошая UX схема разделяет first byte, first partial image и final image. Backend пишет одно состояние job, frontend показывает его без скрытых повторов, а кнопка Generate не создает второй billable job без явного решения пользователя. В image generation duplicate click может быть новой работой, а не просто новым просмотром статуса.
Не превращайте медленную работу в rate-limit incident
Локальный timeout на 60 секундах часто вызывает автоматический retry. Если первый job еще выполняется upstream, система уже создала вторую работу. Через несколько пользователей это становится RPM/IPM pressure или 429. Ошибка здесь не в том, что retry существует, а в том, что он не знает состояние original job.
| Условие | Правило retry |
|---|---|
| local timeout без ответа | сначала проверить, не продолжает ли выполняться исходный job |
| 429 или limit headers | backoff with jitter, уважать reset headers |
| 5xx или transient route error | ограниченный retry с максимальным числом попыток |
| пользователь снова нажал Generate | вернуть existing pending job или предупредить о новом запуске |
| gateway уже retry internally | считать provider retries отдельно от своих |
Если проблема смещается в quotas или 429, используйте /ru/blog/openai-api-rate-limit/ и /ru/blog/gpt-image-2-usage-limits/. Latency recovery не должен становиться скрытым обходом лимитов.
Разделяйте OpenAI direct, Azure, gateway и reverse route
Support packet для direct OpenAI должен содержать model id, endpoint, request id if present, status, headers и форму запроса. Для Azure нужны deployment, region, quota, APIM и regional status. Для compatible gateway нужны base URL owner, upstream mapping, provider timeout, retry policy и log visibility. Reverse route добавляет risk: account/session owner, hidden retries, policy boundary и слабый support path.
Если gateway не показывает transparent logs, не умеет отделить local timeout от upstream wait и не дает route owner, он непригоден для production latency diagnosis. Cost/access выбор можно оставить для /ru/blog/gpt-image-2-api-cheap/; slow-call страница должна удерживать clocks и ownership.
Эскалируйте с правильным пакетом

Эскалация быстрее, когда данные уже обезличены и разделены по слоям. Включите timestamp, timezone, repeated or one-off flag, route owner, model, endpoint, streaming flag, quality, size, format, reference images, first byte, partial image, final image, download, render, timeout layer, retries, returned status, request id if present, worker/runtime, proxy, CDN, browser timeout и minimal reproduction.
Никогда не отправляйте API keys, tokens, private prompts, private images, raw customer identifiers, IPs, channel ids, account-pool details или raw logs. Итоговое решение должно быть конкретным: расширить один timeout, перейти на async job, понизить draft quality, изменить output format, отделить high-resolution work, исправить backoff или передать route owner тому, кто реально видит logs.
Сделайте минимальный воспроизводимый тест
Когда основные часы уже записаны, переходите к controlled experiment. Не меняйте route, quality, size, format, retry policy и timeout в одной попытке. Иначе результат нельзя объяснить: команда не поймет, ускорился ли model work, исчез ли local timeout, уменьшилась ли загрузка файла или просто сменился provider path.
Практичный порядок такой. Сначала три раза запустите один и тот же prompt, quality, size, format и route owner. Это покажет, стабильная ли задержка или единичный всплеск. Затем поменяйте только способ ожидания: синхронный browser request против async job с polling. После этого меняйте только output format, например PNG против JPEG, и смотрите download_ms и render_ms. Потом отдельно тестируйте quality low, medium и high. Только последним шагом сравнивайте OpenAI direct, Azure или gateway.
| Раунд | Что не меняем | Единственная переменная | Что решаем |
|---|---|---|---|
| Baseline | prompt, quality, size, format, route | три одинаковых запуска | стабильная ли медленность |
| Sync vs async | prompt, параметры, route | способ ожидания | исчез ли browser timeout |
| Output format | prompt, quality, size, route | JPEG / PNG / WebP | влияет ли transfer/render |
| Quality | prompt, size, format, route | low / medium / high | меняется ли final_image_ms |
| Route owner | prompt, параметры, retry policy | direct / Azure / gateway | принадлежит ли задержка маршруту |
Если медленно только high quality, нельзя писать, что весь GPT Image 2 API медленный. Если падает только browser path, это не доказательство проблем у upstream. Если задержка есть только в gateway, treat it as route behavior and keep it separate from OpenAI direct. Такой тест не только помогает исправить систему, но и делает support conversation короче: у вас уже есть таблица с временем, параметрами и владельцем маршрута.
Guardrails перед продакшеном
После исправления slow path добавьте защитные правила. Кнопка Generate должна иметь pending state и не создавать второй job без подтверждения. Backend должен возвращать existing pending job для того же пользователя, prompt, параметров и route owner. Error message должен различать local timeout, gateway timeout, upstream error и returned API error. Dashboard должен группировать latency по route owner, иначе среднее значение смешает OpenAI direct, Azure, gateway и proxy.
Мониторинг должен учитывать не только failures. Успешный job с очень поздним first_byte_ms все равно плох для UX. Быстрый final_image_ms с тяжелым download_ms может быть mobile issue. Низкий retry_count при большом числе duplicate clicks говорит о проблеме интерфейса. Хороший image generation path измеряет success rate, clocks, user state, duplicate clicks и support packet readiness together.
Часто задаваемые вопросы
GPT Image 2 API в норме может быть медленным?
Да, сложная генерация может ждать долго. Но нормальная длинная генерация отличается от ложного timeout тем, что маршрут продолжает работать и возвращает результат. Смотрите first_byte_ms и final_image_ms, а не только общий duration.
60 секунд слишком мало?
Для сложного image job часто мало, если browser или worker синхронно ждет final image. Но не расширяйте все timeouts. Найдите failing layer и измените только его.
Streaming делает финальное изображение быстрее?
Нет гарантии. Streaming улучшает perceived latency и дает progress. Final generation time нужно писать отдельно.
Нужно ли сразу ставить low quality?
Только для drafts и previews. Для production asset сначала измерьте slow clock и сделайте controlled comparison.
Как понять, что виноват gateway?
Сравните тот же prompt и параметры с маршрутом, который вы контролируете лучше. Запишите base URL owner, upstream status, retries, first byte, final image time и returned status.