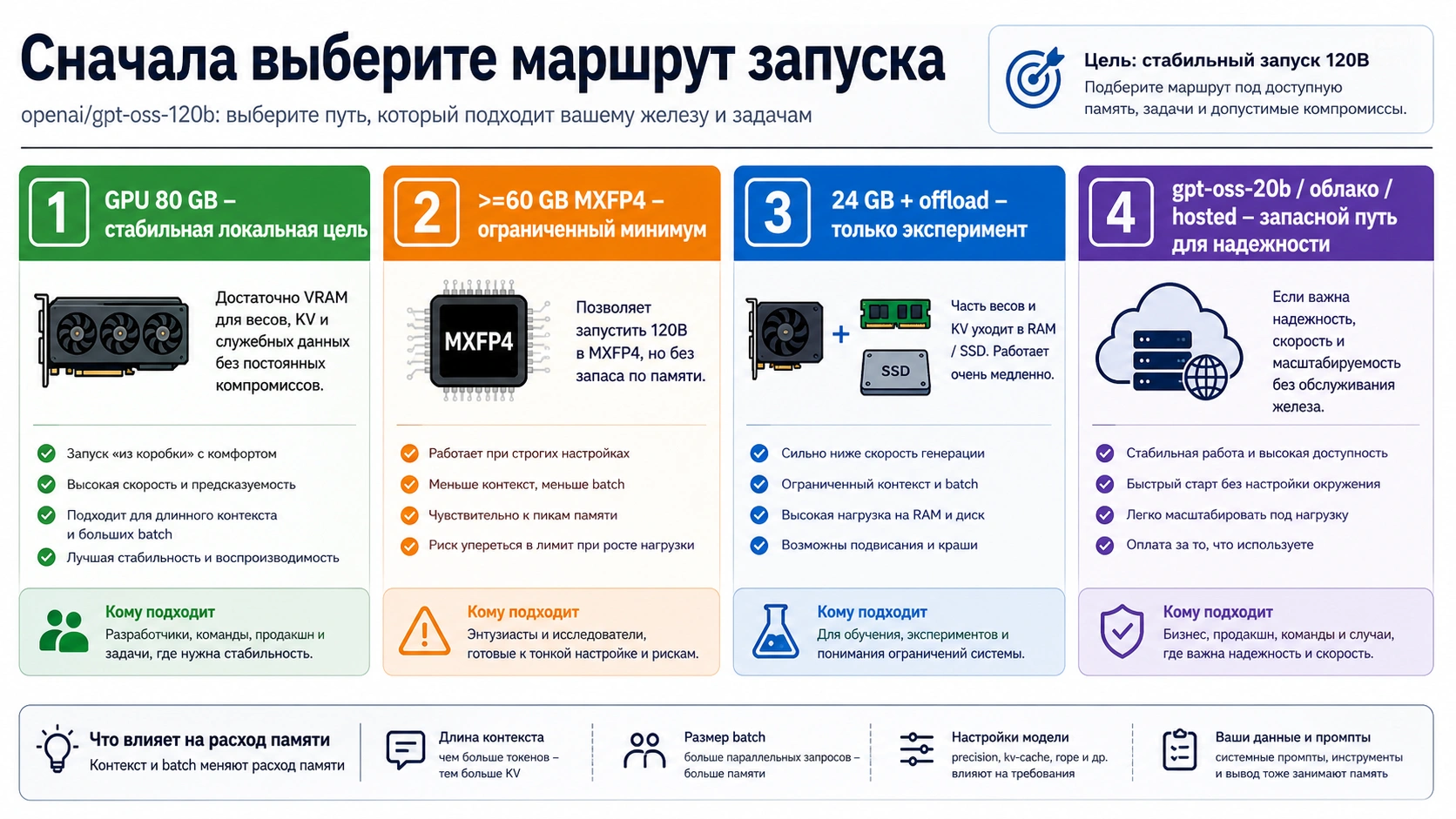
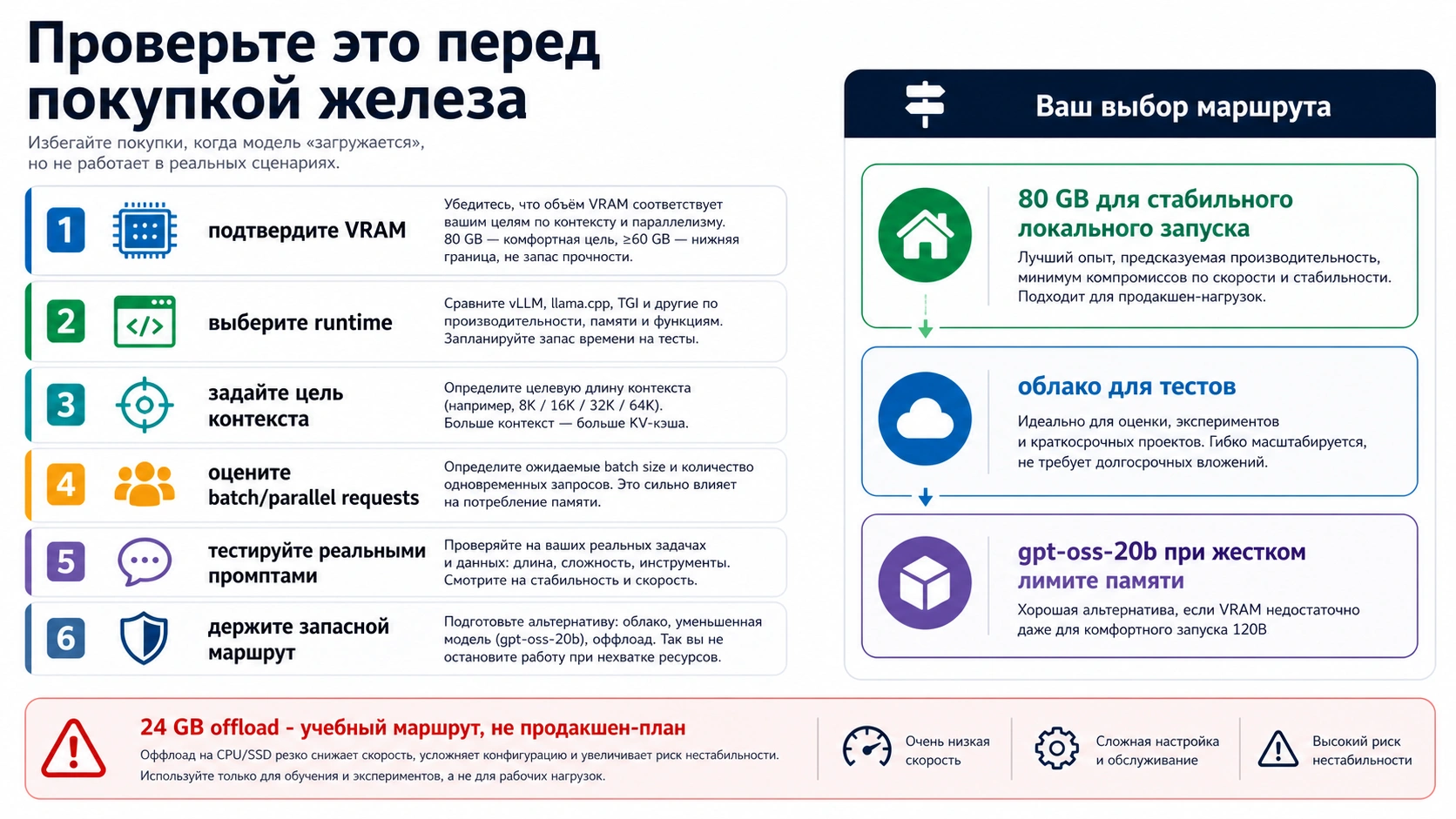
Для надежного локального запуска gpt-oss-120b планируйте модель как задачу уровня GPU на 80 GB. Число >=60GB означает ограниченный нижний порог для поддерживаемых MXFP4-маршрутов, а не комфортный запас. Конфигурация с 24 GB VRAM, CPU или NVMe offload годится для эксперимента, но не для спокойной эксплуатации. Если важны скорость, длинный контекст, несколько пользователей или повторяемость, сразу сравнивайте 120B с gpt-oss-20b, арендой облачного GPU и hosted-доступом.
| Маршрут | Как трактовать | Практический смысл |
|---|---|---|
| GPU серверного класса 80 GB | Чистый локальный маршрут | Лучший ориентир для серьезной локальной работы с 120B. |
>=60GB VRAM или unified memory | Ограниченный нижний порог | Возможен на поддерживаемом стеке, но контекст, batch и overhead остаются важными. |
| GPU 24 GB плюс CPU/NVMe offload | Эксперимент | Полезно для обучения и проверки формата, но не как production-план. |
gpt-oss-20b, облачный GPU или hosted-доступ | Запасной маршрут | Рациональнее, когда локальная память, скорость или надежность являются настоящим ограничением. |
Не покупайте железо, если расчет держится на слове «RAM» без уточнения пула памяти, на одном сообщении с Reddit или на benchmark, который не повторяет ваш runtime, длину контекста и concurrency.
Сначала выберите маршрут запуска, затем считайте память
Полезный ответ по памяти GPT-OSS 120B начинается не с одного числа, а с маршрута. В справочных материалах OpenAI модель gpt-oss-120b описывается как open-weight MoE модель с 117B параметрами, 5.1B active parameters и длинным контекстным окном. Запуск в классе одного H100 или другого accelerator на 80 GB является самым понятным ориентиром для локального планирования, потому что в эту рамку помещаются веса, runtime overhead, обычный контекст и запас на реальные запросы.
Но одна и та же модель может вести себя по-разному в Transformers, vLLM, Ollama, multi-GPU setup или offload. Если задача состоит в коротком локальном чате для одного пользователя, требования одни. Если задача состоит в проверке 64k контекста, tool calls, batch-тестах или общем сервисе для команды, запас нужен другой. Поэтому сначала запишите job: локальная приватность, оценка качества 120B, внутренний сервис, демонстрационный эксперимент или production API.
После этого числа становятся управляемыми. 80 GB означает чистый локальный ориентир. 60 GB означает ограниченный нижний порог. 24 GB означает эксперимент. 20B, cloud GPU или hosted route становятся не поражением, а нормальными ветками решения, если они быстрее приводят к полезному результату.
Такой порядок помогает отделить вопрос загрузки модели от вопроса полезной эксплуатации. Рабочая конфигурация должна проходить не только load test, но и ваш контекст, batch, latency и повторяемость.
Почему 80 GB и 60 GB не противоречат друг другу
80 GB и >=60GB отвечают на разные вопросы. 80 GB отвечает на вопрос: какой класс железа планировать, если нужен чистый локальный запуск 120B без постоянного балансирования на краю. >=60GB отвечает на другой вопрос: какой нижний порог может сработать на конкретном MXFP4 runtime path, если контролировать контекст, batch и overhead.
OpenAI runtime материалы для Transformers, vLLM и Ollama показывают именно такую разницу. Transformers route может говорить о 60 GB VRAM или multi-GPU setup, vLLM чаще выглядит как серверный маршрут с H100-class hardware, а локальные инструменты используют формулировку VRAM или unified memory. Эти слова нельзя переносить в универсальное обещание для любой рабочей станции.
Дополнительная память нужна не только под файл весов. Runtime может резервировать буферы, хранить KV cache, использовать temporary allocations, распределять модель по GPU или менять precision в зависимости от kernel support. Демонстрация с коротким prompt не доказывает, что тот же setup выдержит длинный документ, несколько simultaneous requests или строгую latency target.
Разделяйте VRAM, unified memory, RAM, диск и KV cache
Слово «память» слишком широкое. VRAM находится на accelerator и отвечает за веса, runtime state и часто KV cache. Unified memory может быть общей областью для CPU/GPU на некоторых системах, но ее скорость и доступный запас нужно проверять отдельно. System RAM помогает операционной системе, tokenizer, offload buffers и background tasks, но не становится быстрой VRAM. NVMe offload помогает загрузить модель, однако превращает задержку в главный риск.
KV cache заслуживает отдельной строки в плане. Чем длиннее active context и чем больше одновременных запросов, тем сильнее растет давление на память. Поэтому цифра из model file size не равна runtime requirement. Даже quantized модель может потребовать больше пространства из-за allocator reserve, temporary buffers и serving settings.
Хороший hardware plan описывает каждый пул отдельно: сколько VRAM доступно, сколько unified memory реально может использовать runtime, сколько system RAM остается после ОС и процесса, есть ли swap, как ведет себя NVMe, какой context target выбран и сколько запросов должно идти параллельно.
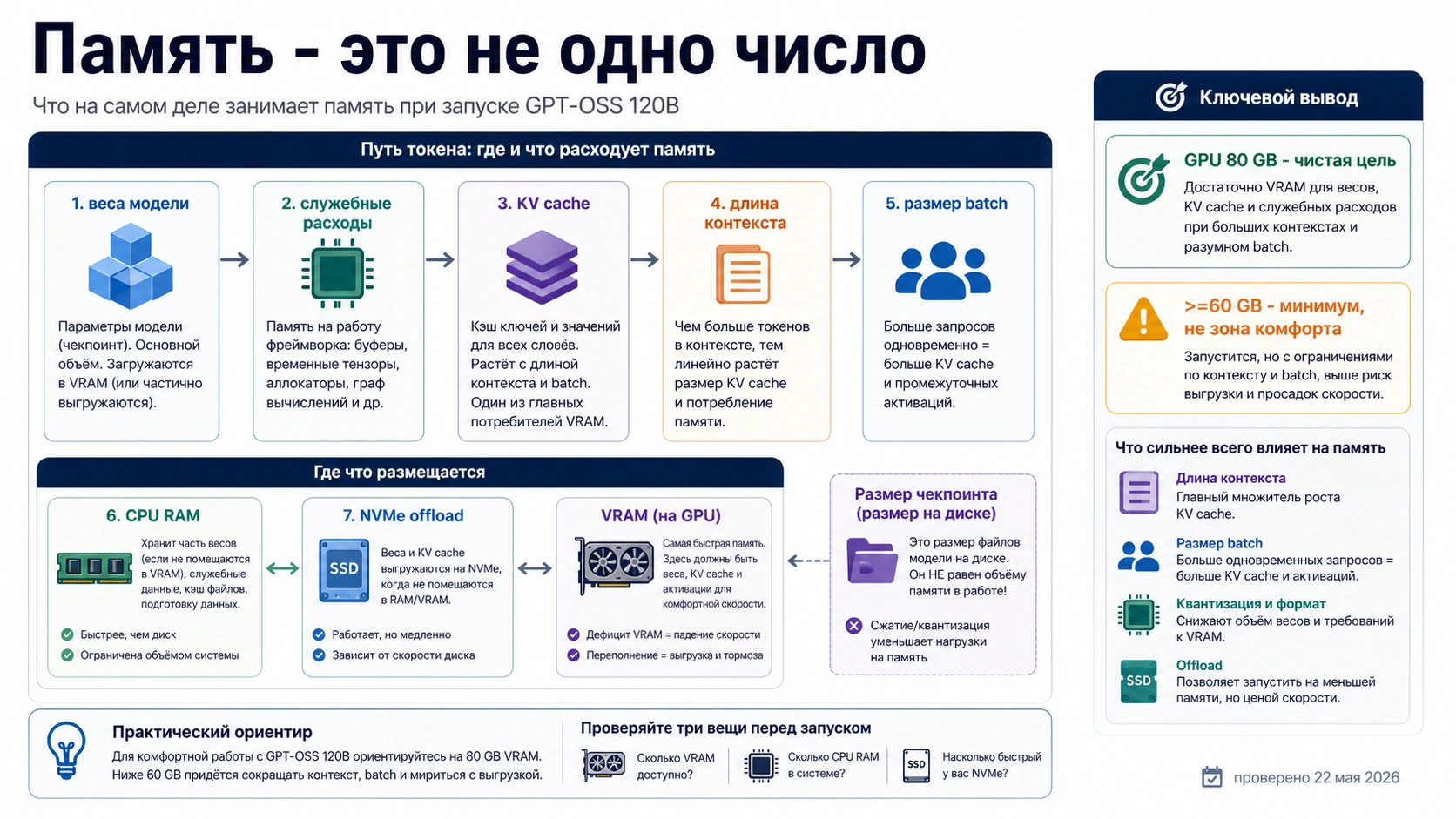
| Тип памяти | Что значит для gpt-oss-120b | Что это меняет в покупке |
|---|---|---|
| VRAM | Память accelerator для весов, runtime state и часто KV cache | Чистый single-device target — 80 GB class. |
| Unified memory | Общая память CPU/GPU на некоторых системах | Можно тестировать как constrained route, но скорость нужно мерить. |
| System RAM | CPU-side память для ОС, runtime, buffers и offload | Помогает experiment, но не заменяет VRAM. |
| Disk/NVMe offload | Перенос части состояния через storage | Загрузка возможна, latency рискованна. |
| KV cache | Память active context во время генерации | Длинный контекст быстро съедает запас. |
| Batch/concurrency | Количество tokens или requests вместе | Serving требует большего запаса, чем single chat. |
Эта таблица предотвращает типичную ошибку: приравнять system RAM к GPU VRAM или считать checkpoint size достаточным доказательством runtime memory.
Runtime меняет реальный бюджет памяти
Runtime определяет, где окажется узкое место. Transformers удобен для прямого Python-эксперимента, но hardware support, kernel path и precision choice могут резко изменить память. vLLM больше похож на serving route: max model length, batched tokens, tensor parallelism и KV cache policy прямо влияют на запас. Ollama и desktop runners проще для первого запуска, но текст про VRAM или unified memory относится именно к поддерживаемому маршруту.
Multi-GPU route требует не только суммы памяти. Две или три карты по 24 GB могут выглядеть достаточно по арифметике, но interconnect, sharding, driver versions и manual placement могут превратить запуск в длительную отладку. Один accelerator правильного размера часто дешевле по времени, чем несколько пограничных consumer cards.
Cloud GPU полезен как контрольная ветка. Если 120B нужен для оценки проекта, аренда H100-class инстанса на день может показать реальную длину контекста, throughput и OOM point раньше, чем покупка workstation. Hosted route нужен там, где важнее надежность и time-to-delivery, чем владение инфраструктурой.
Стоп-линии для потребительских GPU
Consumer GPU с 24 GB VRAM меняет обещание. Он может быть хорошим учебным стендом: понять формат модели, проверить prompts, посмотреть tool behavior, попробовать offload. Но как только CPU или NVMe становятся основным путем движения данных, это уже не clean GPU inference.
48 GB workstation card серьезнее, но все еще ниже clean 80 GB target. Две карты по 24 GB или несколько старых GPU можно рассматривать как advanced experiment, если runtime умеет распределять модель без хрупкой ручной схемы. Apple unified memory setup тоже требует измерений throughput, thermal behavior и real prompts, а не только чтения total memory.
Стоп-линия проста: если модель только загружается, но first token latency неприемлема, маршрут не подходит для интерактива. Если короткий prompt работает, а реальные документы ломаются, setup еще не доказан. Если один запрос проходит, но batch или team usage рушится, это все еще эксперимент.
| Железо | Разумный маршрут | Стоп-линия |
|---|---|---|
| Один GPU 24 GB | Offload experiment или gpt-oss-20b | Если latency задается CPU/NVMe movement, это не production 120B. |
| Два GPU 24 GB | Advanced experiment | Остановитесь, если placement хрупкий или runtime не держит context target. |
| GPU 48 GB | Серьезный test route | Short demo не доказывает real workload. |
| High unified memory system | Local test route | Capacity без throughput measurements недостаточна. |
| CPU-only | Education/offline inspection | Не подходит для интерактива или team serving. |
Запасной маршрут экономит деньги. Часто дешевле проверить 120B в облаке, а локально оставить 20B, чем пытаться превратить marginal consumer hardware в production system.
Проверочный лист перед покупкой или арендой
Проверка начинается с workload. Запишите runtime, memory pool, context target, batch или concurrency, precision/quantization, real prompt set, telemetry и fallback. Метрики должны включать peak VRAM, system RAM, swap, NVMe activity, tokens/sec, time-to-first-token и OOM boundary.
Для аренды сначала прогоните exact runtime и exact context target. Для покупки требуйте тест на тех prompt и concurrency, которые действительно нужны. Если полезная цель — приватный локальный ассистент, gpt-oss-20b может дать лучший опыт на меньшем железе. Если цель — оценить 120B, cloud GPU снимает риск закупки. Если цель — продуктовый сервис, hosted route отделяет model evaluation от владения инфраструктурой.
Итоговое решение должно звучать как маршрут: купить 80 GB, тестировать 60 GB floor, оставить 24 GB как offload lab, перейти на 20B, арендовать cloud GPU или использовать hosted access. Одно число без маршрута не защищает от дорогой ошибки.
| Шаг | Что записать | Зачем |
|---|---|---|
| Runtime | Transformers, vLLM, Ollama, multi-GPU, offload, hosted | Memory behavior зависит от route. |
| Memory pool | VRAM, unified memory, system RAM, disk offload | Слово RAM скрывает bottleneck. |
| Context target | Short chat, 32k, 64k, 128k или свой лимит | KV cache растет с context. |
| Batch/concurrency | Single user, batch tests, multi-user serving | Single request не равен service load. |
| Precision/quantization | MXFP4, BF16, runtime conversion | Requirement зависит от representation. |
| Real prompts | Tools, long docs, code, short chat | Toy prompts скрывают latency. |
| Telemetry | Peak VRAM, RAM, swap, tokens/sec, OOM point | Повторяемость важнее screenshot. |
| Fallback | 20B, cloud GPU, hosted, shorter context | Escape route должен быть заранее. |
После такого теста нормальными ответами становятся разные варианты: покупать 80 GB, арендовать, оставить 20B локально, сократить context или не self-host эту задачу.
Часто задаваемые вопросы
Сколько VRAM нужно GPT-OSS 120B?
Для чистого локального маршрута используйте 80 GB GPU-class hardware как ориентир. >=60GB — это ограниченный нижний порог для некоторых MXFP4 runtime paths, а не универсальный комфортный запас.
Можно ли запустить GPT-OSS 120B на GPU 24 GB?
Да, как offload experiment. CPU или NVMe offload может помочь загрузить модель, но latency, context length и надежность меняют характер задачи.
Может ли большая system RAM заменить VRAM?
Нет. System RAM помогает buffers и offload, но не равна accelerator VRAM. Если состояние модели ходит через CPU или storage, маршрут становится ограниченным экспериментом.
Почему встречаются 80 GB, 60 GB, 64 GB и 96 GB?
Эти числа относятся к разным границам: clean GPU target, constrained load floor, unified memory/offload experiment или serving headroom. Без runtime и workload число неполно.
GPT-OSS 20B требует такого же железа?
Нет. gpt-oss-20b является меньшим local route и относится к 16GB-class сценариям. Он часто лучше для приватного local assistant.
Длинное контекстное окно означает, что 128k доступно на любом setup?
Нет. Long context увеличивает KV cache pressure. Планируйте по фактической длине контекста и concurrency.
Покупать H100-class карту, арендовать GPU или использовать hosted access?
Покупка имеет смысл при повторяемой локальной 120B работе. Аренда хороша для проверки workload. Hosted route лучше, когда delivery и reliability важнее владения железом.
Полезны ли Reddit и Habr отчеты о низкой памяти?
Полезны как идеи для тестов и предупреждения о краевых случаях. Владельцами требования должны оставаться official model/runtime docs и ваш собственный workload proof.