По состоянию на 7 мая 2026 года для большинства задач Claude стоит начинать с Sonnet 4.6 и переходить к Opus 4.7 только тогда, когда сложность задачи оправдывает более дорогой запуск. Sonnet лучше подходит как рабочая модель по умолчанию: он быстрее, дешевле и удобнее для масштабирования. Opus нужен как модель эскалации для задач с высокой ценой ошибки, сложной архитектурой, длинными агентными цепочками, тяжелыми документами или повторяющимися провалами одного и того же критерия приемки.
| Как выглядит задача | Что пробовать сначала | Когда переходить выше |
|---|---|---|
| Обычный кодинг, ресерч, документы, офисная аналитика, браузерные или computer-use сценарии | Sonnet 4.6 | Ответ требует постоянной ручной правки или снова не проходит тот же тест. |
| Высокочастотный API-продакшен | Sonnet 4.6 | Ошибки, повторы и ревью стоят дороже, чем премия за Opus. |
| Архитектура, root-cause debugging, сложное рассуждение по многим файлам | Тестовый канал Opus 4.7 | Оставьте Sonnet базой, если Opus не улучшает итоговый результат. |
| Долгие агенты и многошаговые workflow | Sonnet как baseline плюс Opus как сравнение | Opus лучше держит план и дает меньше тупиков на том же запуске. |
| Простое извлечение, маршрутизация, форматирование | Боковая дорожка Haiku 4.5 | Сначала повышайте до Sonnet, не прыгайте сразу в Opus. |
Публичная строка цены — только первый сигнал. В текущих документах Anthropic Sonnet 4.6 указан по $3 за миллион входных токенов и $15 за миллион выходных токенов, а Opus 4.7 — по $5 и $25. Реальная стоимость меняется из-за длины ответа, кэширования prompt, batch-режима, thinking-настроек, повторов и примечания о tokenizer Opus 4.7: один и тот же фиксированный текст может считаться большим числом токенов в зависимости от содержания.
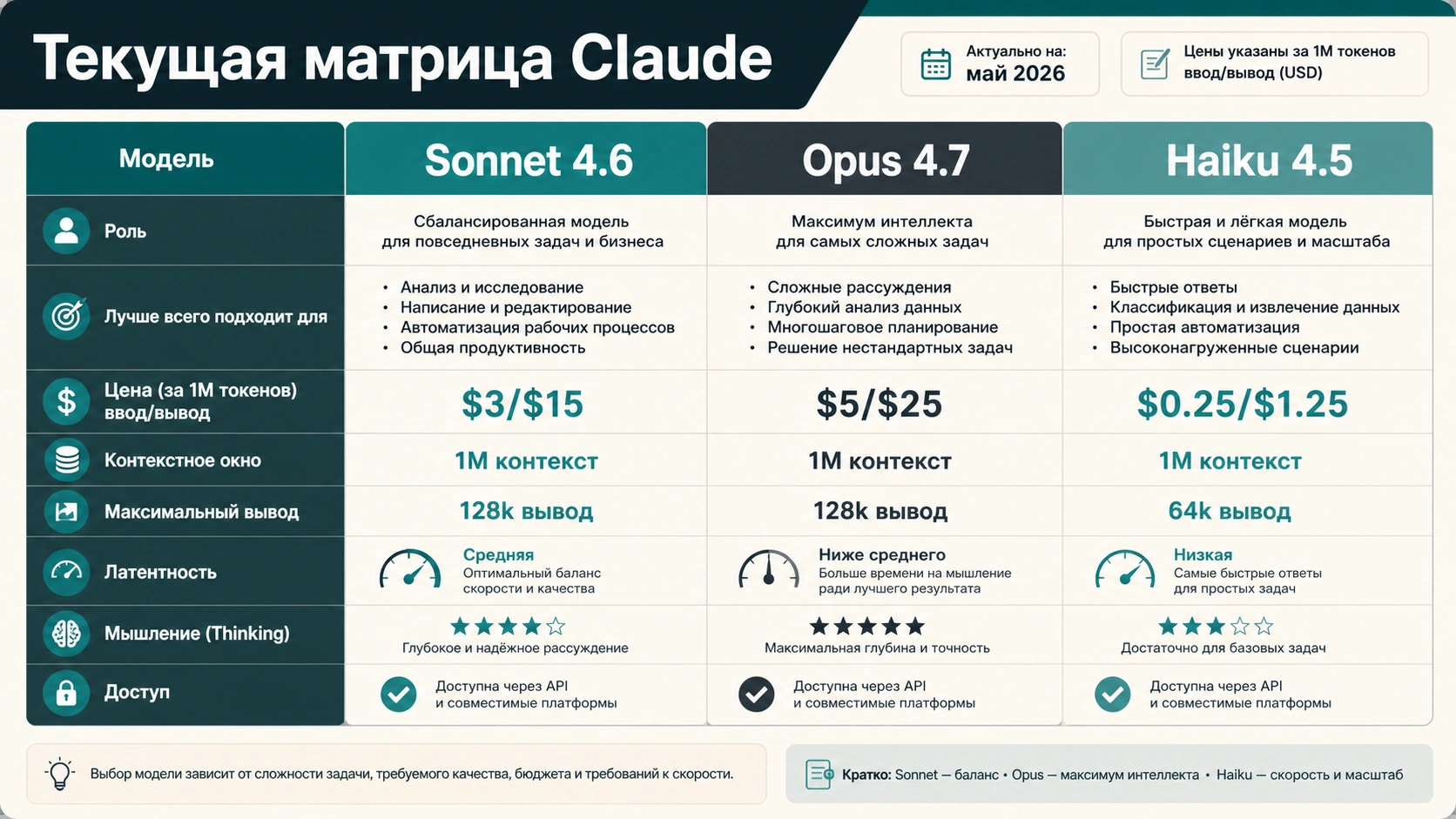
Текущее сравнение — это Opus 4.7 против Sonnet 4.6
В русскоязычной выдаче много материалов про Claude 3, Claude 4, Opus 4.5, Opus 4.6 или Sonnet 4.5. Они полезны как контекст, но не отвечают на текущий практический вопрос. Сегодня выбор звучит так: какой workload оставить на Sonnet 4.6, а какой стоит проверить на Opus 4.7.
Anthropic в актуальном обзоре моделей показывает Opus 4.7, Sonnet 4.6 и Haiku 4.5 как основные уровни. Opus 4.7 позиционируется для профессиональной разработки, сложного рассуждения, агентных сценариев, advanced coding и задач enterprise-уровня с высокой ценой ошибки. Sonnet 4.6 позиционируется как сбалансированная модель для повседневной работы, production-масштаба, coding, agents, browser/computer use, long-context reasoning и затратных workflows.
| Текущая официальная строка | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| Практическая роль | Модель по умолчанию для большинства задач | Модель эскалации для самых сложных задач |
| API-цена, проверено 7 мая 2026 | $3 input / $15 output за MTok | $5 input / $25 output за MTok |
| Латентность в overview | Fast | Moderate |
| Context window | 1M | 1M |
| Max output | 64k | 128k |
| Thinking | Extended thinking плюс adaptive thinking | Adaptive thinking |
| Первый сценарий | Повседневная работа, coding loops, продакшен | Сложная логика, агенты, high-stakes решения |
Haiku 4.5 стоит держать в статье только как боковую дорожку. Он нужен для дешевых и быстрых механических задач: извлечения, классификации, форматирования, маршрутизации. Но если читатель спрашивает Opus или Sonnet, главный выбор — не энциклопедия семейства, а граница между базовым рабочим режимом и эскалацией.
Когда Sonnet 4.6 должен быть моделью по умолчанию
Sonnet выигрывает там, где нужна скорость, контролируемая стоимость и надежная масштабируемость. Это покрывает большую часть реального использования Claude: помощь в коде, ревью PR, подготовку документации, cleanup данных, структурные резюме, офисную аналитику, поддержку, контент, браузерные действия и многие production API-пути.
Причина не в том, что Sonnet «дешевый». Причина в том, что он часто дает достаточно интеллекта при меньшей задержке и более низкой цене за токен. Если задача хорошо описана, имеет измеримый контракт результата и низкую цену ошибки, старт с Opus может не изменить результат, но заметно увеличить счет.
Используйте Sonnet первым, когда:
- результат легко проверить тестом, схемой, правилом или ревью;
- задача повторяется часто, и цена токенов быстро накапливается;
- workflow требует быстрой итерации больше, чем максимальной глубины;
- prompt уже хорошо структурирован, а критерии успеха ясны;
- модель должна выполнить процесс, а не изобрести стратегию;
- ошибку можно поймать retry, unit test, lint, schema validation или человеческой проверкой.
Для пользователей Claude app Sonnet обычно является естественной стартовой точкой. Для API-команд он почти всегда должен быть первым production-кандидатом, потому что официальная строка цены ниже, а модель рассчитана на масштабные сценарии.
Когда Opus 4.7 действительно стоит тестировать
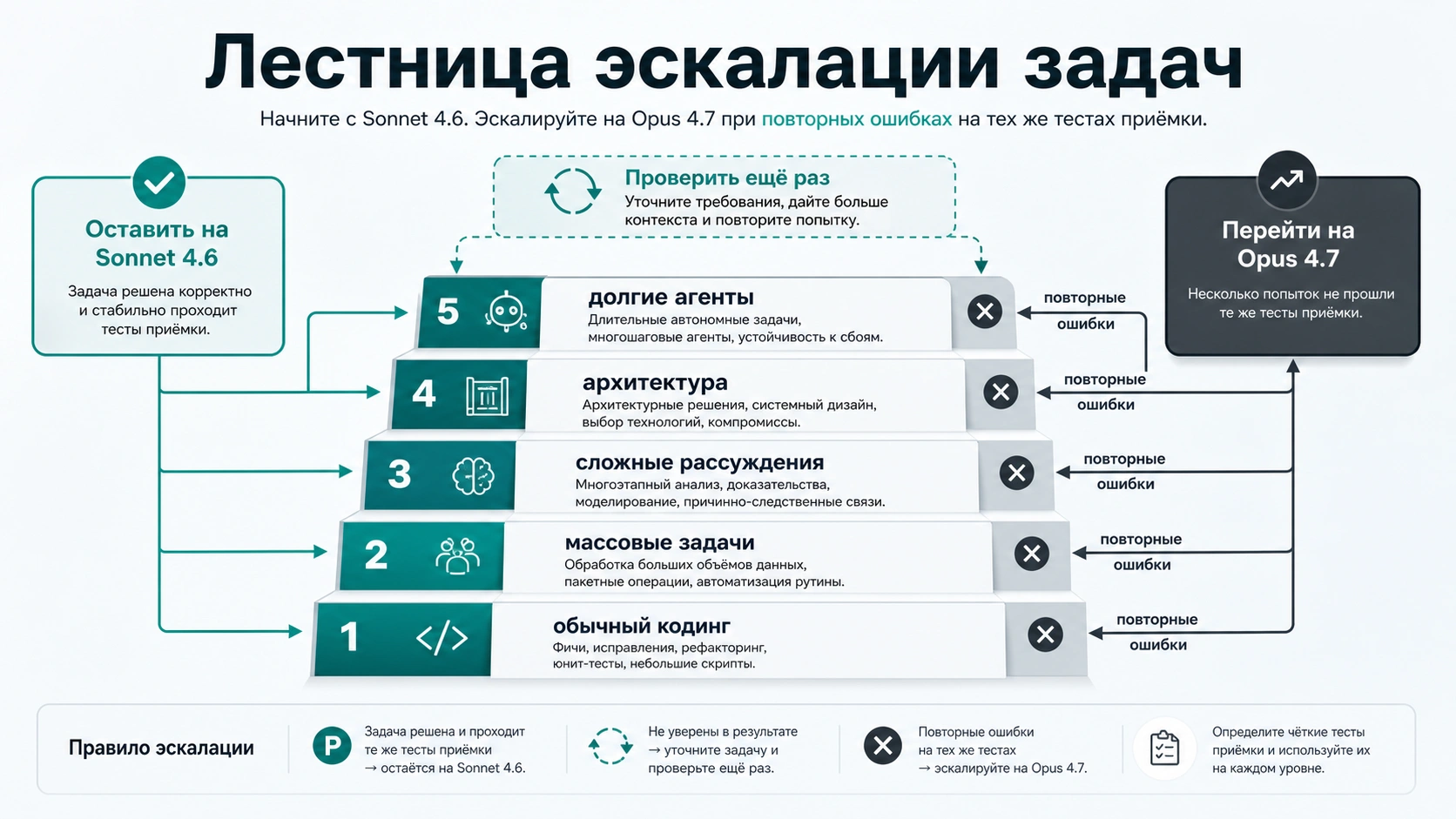
Opus становится интересен не потому, что он «старше», а потому, что некоторые ошибки стоят слишком дорого для дешевого retry loop. Его лучшие сценарии — не просто важные задачи, а задачи, где глубина рассуждения, устойчивость плана или работа с грязным контекстом меняет исход.
Проверяйте Opus 4.7, когда:
- Sonnet после очистки prompt все равно пропускает один и тот же критерий;
- задача требует архитектурного решения через несколько файлов, систем и ограничений;
- нужно читать длинный набор документов и сохранять нюансы;
- агентная цепочка теряет план, зацикливается или берет хрупкие shortcuts;
- ответ влияет на инженерное, юридическое, финансовое или enterprise-решение;
- root-cause debugging слишком дорог, чтобы принимать правдоподобную, но поверхностную гипотезу;
- человеческое ревью стало главным расходом, и лучший первый ответ экономит время команды.
Opus не обязан быть универсальным апгрейдом. Если он дает тот же ответ, что Sonnet, или улучшает только стиль, оставляйте Sonnet. Если Opus предотвращает плохую архитектурную развилку, находит скрытую зависимость или завершает длинный агентный запуск, который Sonnet не выдерживает, премия оправдана.
Разница в стоимости больше, чем строка цены
Страница pricing Anthropic — правильный источник для строк API-цен, но строка цены не равна полной стоимости workload. Базовая разница видна: Sonnet 4.6 стоит $3/$15, Opus 4.7 — $5/$25 за миллион токенов. Но итоговый счет зависит от output length, повторяемого контекста, cache write/cache hit, batch pricing, thinking effort, tool schemas, retries и времени ревью.
Текущая pricing-страница также указывает, что Opus 4.7 использует новый tokenizer и для одного и того же фиксированного текста может считать до 35% больше токенов в зависимости от контента. Это не значит, что каждый запуск станет ровно на 35% дороже. Это значит, что миграцию нельзя оценивать по прошлому объему Sonnet, просто умноженному на новую цену.
| Слой стоимости | Почему он меняет решение |
|---|---|
| Базовая цена input/output | Opus дороже за токен. |
| Длина ответа | Более глубокий ответ может быть длиннее, если не ограничить бюджет. |
| Prompt caching | Cache hit снижает повторный input, но cache write тоже стоит денег. |
| Batch | Асинхронные задачи могут быть дешевле при batch pricing. |
| Thinking | Может улучшить сложный ответ, но увеличить стоимость и задержку. |
| Tokenizer | Opus 4.7 может иначе считать тот же текст. |
| Время ревью | Более дорогая модель может быть дешевле, если уменьшает ручную правку. |
Главный вопрос бюджета: какая модель дает самый низкий accepted-output cost для конкретного workflow.
Перед сменой модели по умолчанию проверьте обе на одном workflow
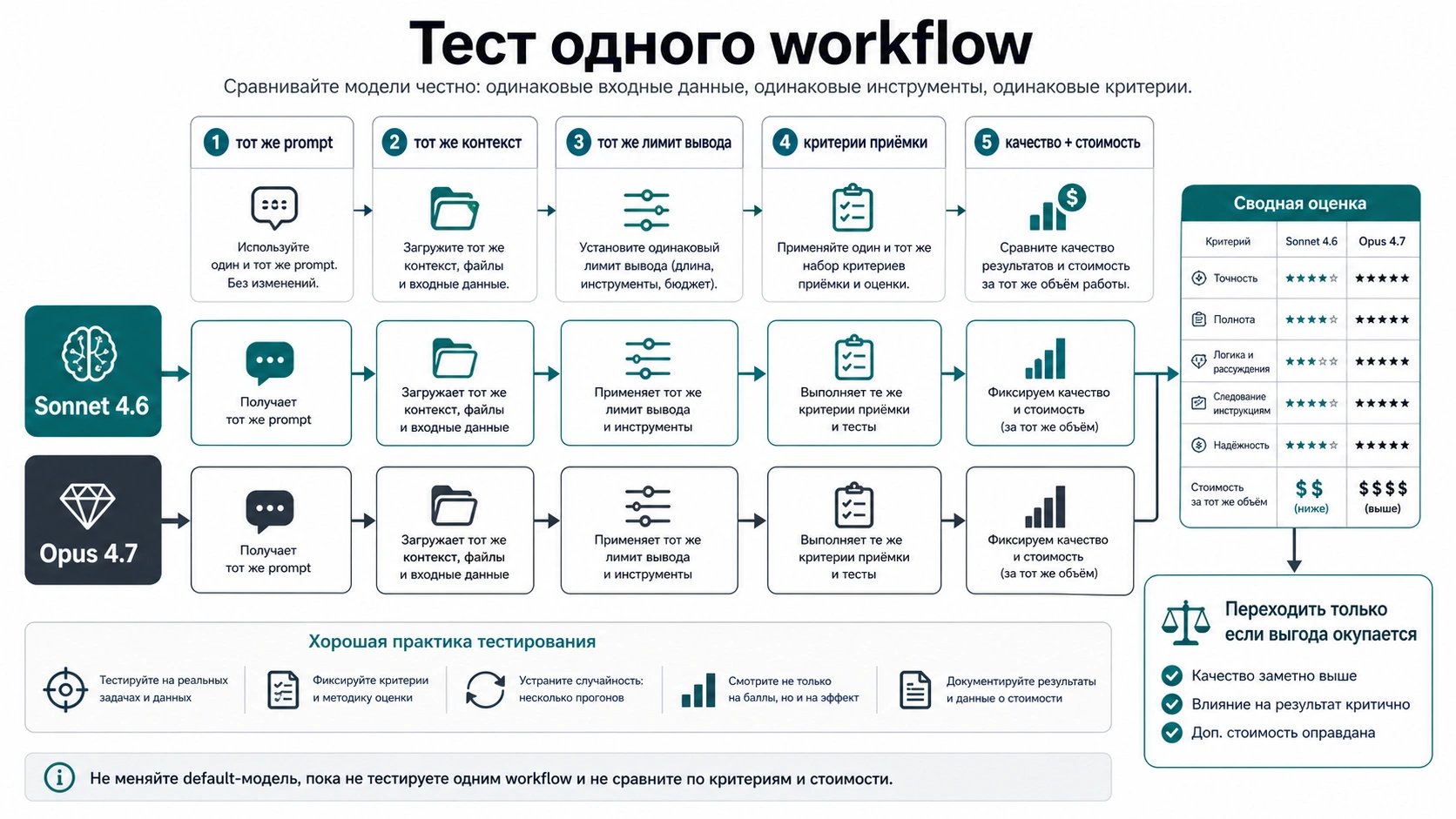
Не меняйте production default из-за названия модели. Проверка должна держать одинаковыми prompt, context, output budget, tools и критерии приемки. Иначе вы сравниваете не модели, а разные задания.
Мини-план:
- Выберите три-пять реальных задач из workflow.
- Уберите чувствительные данные или запускайте только в разрешенной среде.
- Запустите каждую задачу на Sonnet 4.6 с текущим prompt и бюджетом.
- Запустите ту же задачу на Opus 4.7 с тем же prompt, контекстом и бюджетом.
- Оцените оба результата по одной и той же шкале.
- Запишите token cost, latency, retries, review time и финальный accepted result.
- Переносите только те slice, где Opus улучшает результат достаточно, чтобы оплатить премию.
Этот тест защищает и от обратной ошибки: оставаться на Sonnet только из-за цены за токен, но терять больше на повторах и ручной проверке. Обычно лучшая стратегия — смешанная: Sonnet держит обычный поток, Opus получает сложные исключения.
Claude app, API и Claude Code — разные поверхности
Доступ в Claude app и выбор модели в API связаны, но не совпадают. Пользователь app думает о подписке, лимитах и переключателях в продукте. API-разработчик думает о model ID, token price, rate limits, caching, batch и интеграции. Пользователь Claude Code думает о сессии кодинга, но billing и availability могут зависеть от подписки, API key и локальной конфигурации.
Держите границы:
- Если вопрос о Pro, Max или API billing, это не вопрос Opus против Sonnet, а вопрос доступа и оплаты.
- Если вопрос о Claude Code бесплатно или через подписку, это отдельный access guide.
- Если вопрос о том, какую модель поставить на конкретную задачу, выбирайте между Sonnet, Opus, Haiku и тестовым каналом.
Покупка доступа не решает routing. Pro-пользователь может продолжать держать Sonnet как default. API-команда с доступом к Opus может отправлять туда только high-risk slices. Команда с Claude Code должна сначала понять, по какому маршруту работает конкретная сессия.
Часто задаваемые вопросы
Opus всегда лучше Sonnet?
Opus 4.7 сильнее как модель эскалации для самых трудных задач, но это не делает его лучшим default. Sonnet 4.6 чаще лучше как старт, когда важны скорость, стоимость и масштаб. Opus стоит проверять, когда сложность или цена ошибки перекрывают премию.
Что использовать первым: Opus или Sonnet?
Начинайте с Sonnet 4.6. Переходите к Opus 4.7, если задача high-stakes, ambiguous, long-running, architecture-heavy, document-heavy или снова проваливается на Sonnet после улучшения prompt.
Насколько Opus дороже Sonnet?
На 7 мая 2026 года официальные строки указывают Sonnet 4.6 по $3 input и $15 output за миллион токенов, а Opus 4.7 по $5 и $25. Реальная стоимость зависит от output length, caching, batch, thinking, retries и tokenizer behavior.
Sonnet достаточно хорош для кодинга?
Sonnet 4.6 достаточен для многих coding loops, PR review, refactoring, tests и агентных задач. Opus нужен, когда кодинг становится архитектурным, связан с несколькими системами, требует root-cause analysis или повторно проваливает acceptance tests.
Claude Code использует Opus или Sonnet?
Поведение Claude Code зависит от продукта, плана, настроек и маршрута. Считайте Claude Code поверхностью workload, а не отдельным ответом на Opus vs Sonnet. Для обычного coding loop тестируйте Sonnet; для трудной архитектуры сравнивайте Opus на том же repo task.
Где здесь Haiku?
Haiku 4.5 — быстрый и дешевый off-ramp для механических задач. Используйте его для извлечения, маршрутизации, форматирования и low-risk batch work. Если Haiku слаб, поднимайтесь к Sonnet, а не сразу к Opus.
Что делать со старыми советами про Opus 4.5 или Sonnet 4.5?
Используйте их как историческую ориентацию, но текущий выбор строьте на Opus 4.7 и Sonnet 4.6, проверенных по актуальным страницам Anthropic.
Когда команде нужны обе модели?
Когда есть дешевый обычный путь и сложный exception path. Sonnet обслуживает default traffic, а Opus обрабатывает slices, где Sonnet проваливает тесты, требуется глубокое рассуждение или review cost становится главным расходом.