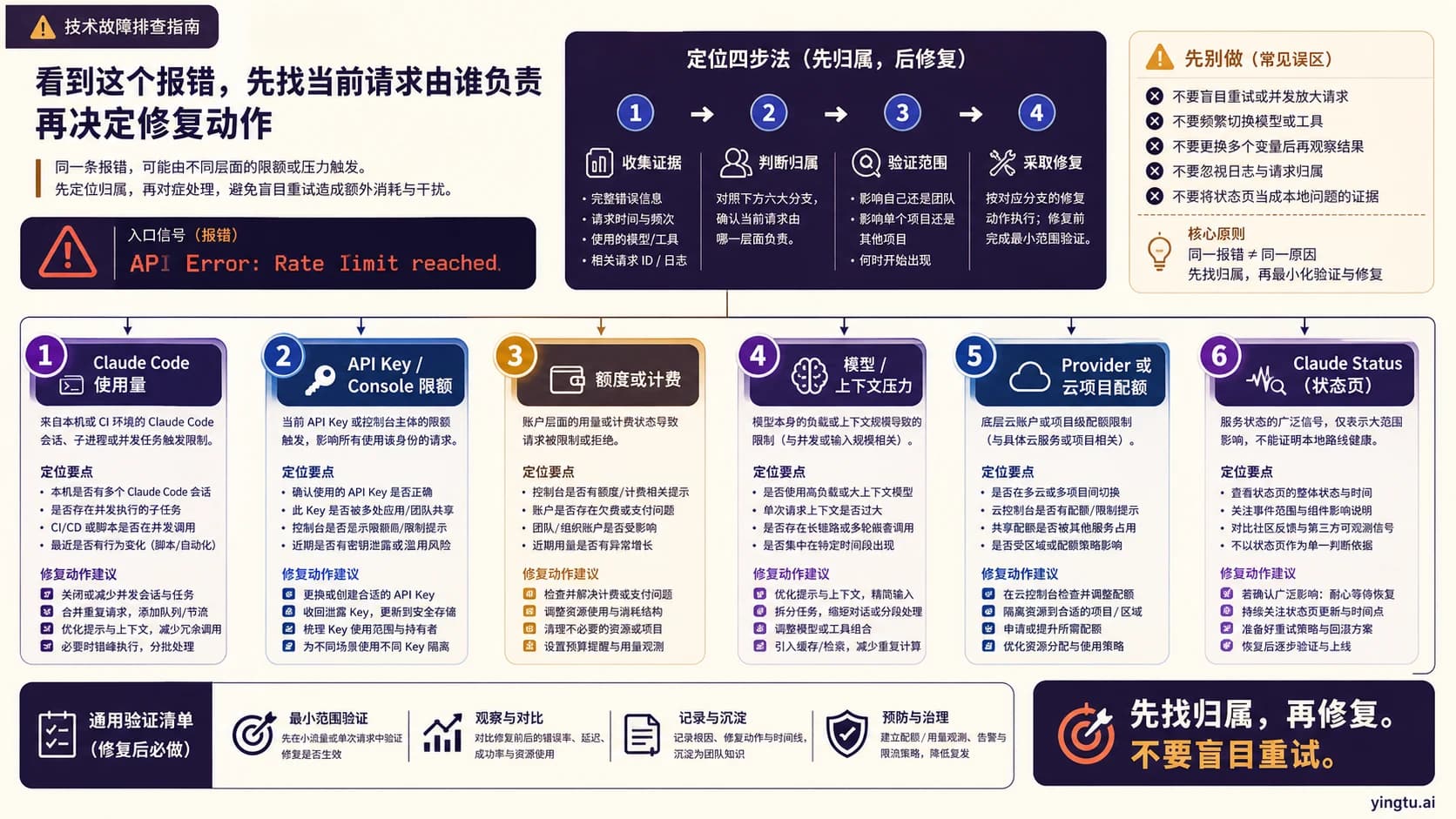
如果 Claude API 返回 HTTP 529,并且错误类型是 overloaded_error,先把它当成 Anthropic 侧的容量分支,而不是自己的账号触发了 429 限流。第一步是打开 Claude Status,停止连续重试,降低并发和队列压力,再用有上限的指数退避加随机抖动重试。测试时保持同一个端点、模型、workspace、时间戳和 request_id,不要同时换 key、换模型、换代理和改代码。
| 响应信号 | 可能归属 | 先做什么 | 什么时候停 |
|---|---|---|---|
HTTP 529 + overloaded_error | Anthropic 容量紧张 | 查状态页、慢速重试、暂停新任务 | 达到重试预算后保留证据 |
HTTP 429 + rate_limit_error | 账号或 workspace 限流 | 看限流 header,降低请求压力 | 等 reset 信号或额度状态变化 |
| HTTP 500 或 504 | 服务端异常或处理超时 | 查状态页,发更小的同路径请求 | 持续复现再带证据升级 |
| Claude Code 显示 repeated 529 | Claude Code 已经自动重试过 | 查状态、等待、必要时换模型继续 | 不要当成 quota 用尽 |
核心规则很窄:529 可以重试,但必须慢、必须有上限、必须伴随降压。立刻循环、反复换 key 或套用 429 额度修复,只会让排查更乱。
529 表示容量分支,不是 429 额度分支
Anthropic 的 API 错误文档把 529 和组织限流分开描述:429 对应账号或 workspace 的 rate limit,500 是内部 API 错误,504 是处理超时,529 是 API 暂时过载。这个区别直接决定第一步。429 需要看限流 header、请求数、token 量和 reset 时间;529 则需要确认当前服务状态,限制重试次数,并把新流量排入队列等待容量恢复。
状态页也要分层阅读。2026-04-30 13:42 +08:00,Statuspage API 显示 Claude API 组件为 operational,但同一天早些时候和前一天都有相关事故记录。对容量问题来说,这种组合并不矛盾:广义组件可能已经恢复,某个模型、某条路由或某个中间层仍然会在短窗口里返回 529。
不要过早把症状改名。保留完整响应体、HTTP 状态、错误类型、request_id、模型、端点、workspace、调用路径和本地时间。后续如果请求成功,这些记录还能说明成功来自等待、降并发、缩小 payload,还是改了路由。
前五分钟先稳定调用路径
先收证据,再改代码。复制完整响应体和响应 header,记录 request id、模型、端点、workspace、供应商路由、输入规模、并发设置和带时区的时间戳。打开 Claude Status,确认 Claude API、Claude Code 或模型层是否有事故。如果中间还有网关、自动化平台或托管 agent,要把这一层单独记下,避免把上游 529 误判成 wrapper 超时。
然后发一个同路径的小请求。保持同一个 API key、组织、模型、端点和 client library,只把输入缩小为已知可用的短 prompt,并降低输出上限。如果小请求成功而生产突发失败,主要修复点是流量整形。如果小请求也返回 529,证据更偏向容量或供应商路由压力。
必须有停止规则。前台请求通常三到五次指数退避就够了;后台任务可以等待更久,但应该进入持久队列,而不是占住 worker 继续打同一个端点。达到预算后,把任务标记为临时容量等待,并向调用方返回清晰的暂时失败状态。
重试要慢,而且要有硬上限
529 的可重试含义是:容量恢复后同一路径可能成功。它不表示更多即时请求会带来成功。正确策略是分散流量、限制努力、保护后续任务。
hljs tsfunction classifyClaude(status: number, type?: string) {
if (status === 529 || type === "overloaded_error") return "slow_retry";
if (status === 429 || type === "rate_limit_error") return "wait_for_limit";
if (status === 500 || status === 504) return "server_or_timeout";
return "do_not_retry_blindly";
}
重点不是代码多复杂,而是上限清楚。Web 请求可以尝试三次后返回临时失败;批处理 worker 可以把任务放回队列并记录下次执行时间;流式界面应该提示模型路径暂时过载,而不是让用户看到长时间无响应。
不要把 529 和 429 混在一个修复分支里。Anthropic 的 rate limit 文档说明 429 可能带有 retry-after 和限流 header;529 通常不是你的账号桶给出的 reset 时间。收到 529 时,调度依据是自己的退避策略和服务状态,而不是额度倒计时。
降低压力,但不要破坏诊断
降压要保持诊断干净。降低 worker 并发,暂停推测性并行调用,把新任务放入队列,缩短上下文,避免每一层都自带一套激进重试。如果 SDK 已经会自动重试临时错误,外层 wrapper 就不能再无限循环,除非你能证明合并后的策略仍然有严格上限。
长任务不要都压在同步请求上。用户不需要即时返回时,用队列或批处理。需要长输出时,优先考虑 streaming,减少空闲连接带来的超时混淆。反复复用大上下文时,prompt caching 可以降低账号侧 token 压力;它主要帮助 429 和 burst 行为,不能保证 529 消失。
换模型只是连续性策略,不是根因证明。Claude Code 文档把 repeated 529 视为容量问题,并建议某个模型高负载时切换模型继续工作。API 产品也可以设 fallback 模型,但前提是业务允许质量或风格变化;如果必须使用原模型,就等待并稍后重试。
升级前用同路径验证
最干净的验证是同路径小负载测试。保持 key、组织、workspace、端点、模型、client library、代理和网络路径一致,先发小请求,再用较低并发发送生产形态。这个对照能区分供应商路径、请求规模、并发突发和 wrapper 层问题。
单独保存 overload log。字段至少包括 request id、状态码、错误类型、模型、端点、workspace、供应商路由、attempt、delay、输入 token 估算、输出上限和最终结果。Anthropic 错误文档说明 request id 有助于支持定位请求;带着 request id、时间戳、状态页记录和同路径复现,比一张终端截图更可操作。
持续、广泛、可复现时再升级。如果只有 Zapier、Make、代理或某个网关失败,而直连 Anthropic 成功,应先查中间层。如果直连的小请求也连续 529,而状态页没有对应事故,就带 request id 和时间窗口提交支持。如果状态页已有事故,优先保留证据、排队等待恢复。
Claude Code、网关和自动化平台要分开看
Claude Code 有自己的表现层。其错误参考说明,服务端错误、overloaded 响应、超时、临时 throttle 和连接中断会在展示给用户之前自动重试。因此你看到 repeated 529 时,通常已经不是第一次失败。下一步是查状态、等待,或为了继续工作临时切模型,而不是判断 Console API 额度耗尽。
网关和自动化平台会加入新的分支。Zapier、Make、自建代理或托管 agent 可能重放、延迟或改写错误。把 Anthropic 上游状态和 wrapper 状态分开。平台只给 generic failure 时,要补日志,捕获原始 HTTP status 和 Anthropic error type;否则 529、429、timeout 和 wrapper quota 都会变成同一种红色报错。
稳定的生产处理方式是小型状态机:分类错误、查服务状态、有限重试、降低压力、排队延期、保留 request id。它比换 key、立即循环或无提示降级模型可靠得多。
生产检查清单
| 控制点 | 为什么对 529 重要 | 实施方式 |
|---|---|---|
| 错误分类器 | 让 529 和 429、500、504 分开 | 同时看 HTTP status 和 error type |
| 有上限的随机退避 | 避免容量紧张时形成 retry storm | 前台和后台设置不同预算 |
| 并发限制 | 防止所有 worker 同时醒来 | 按模型、端点、供应商路由限流 |
| 持久队列 | 保护前台请求 | 记录下次重试时间和 attempt |
| 同路径探测 | 验证小请求是否可行 | key、workspace、模型和路由不变 |
| request id 日志 | 让升级有证据 | 保存 body 字段和 header |
| 状态观察 | 区分事故和本地压力 | 记录检查时间和组件 |
在服务恢复后还要做一次复盘。把当时的 attempt、delay、并发数、输入大小、输出上限、状态页记录和最终结果放在同一条事件里。下一次 529 出现时,值班同事就能直接判断是继续排队、扩大退避窗口、降低某个模型的并发,还是把证据交给平台支持。这个复盘不需要复杂系统,最少也要有结构化日志和一个可以按 request_id 查询的视图。
如果业务有多层重试,还要确认真正执行 retry 的位置。前端、API 网关、worker、SDK 和消息队列都可能各自重试一次,叠在一起就会把三次 retry 变成几十次。容量分支最怕这种隐藏放大。把 retry owner 固定在一层,其他层只传播 temporary capacity 状态,能够明显降低雪崩风险,也让后续支持沟通更清楚。若必须临时降级模型,还要把降级原因、允许范围和用户可见提示写进事件,避免后来把质量变化误判成正常成功。恢复后再抽样检查失败队列,确认没有任务因为过期上下文、重复扣费或幂等键缺失而被二次处理。
常见问题
Claude API 529 会算我的 quota 吗?
先按容量分支处理,而不是按 quota 分支处理。Claude Code 文档明确把 repeated 529 和用户用量限制分开。直连 API 时仍要独立看 Billing 和 Usage,但不要把 overloaded_error 当成 429 修复。
看到 overloaded_error 能马上重试吗?
不能马上循环。要指数退避、加 jitter,并设置硬上限。即时循环会在服务要求客户端放慢时制造更多压力。
换模型算修复吗?
它只是继续工作的办法。只有当业务允许不同模型输出时才适合;如果必须用原模型,就等待并稍后重试。
给支持需要哪些证据?
准备 request id、带时区时间戳、模型、端点、workspace、供应商路由、状态页状态、重试计划,以及一个同路径小请求的结果。