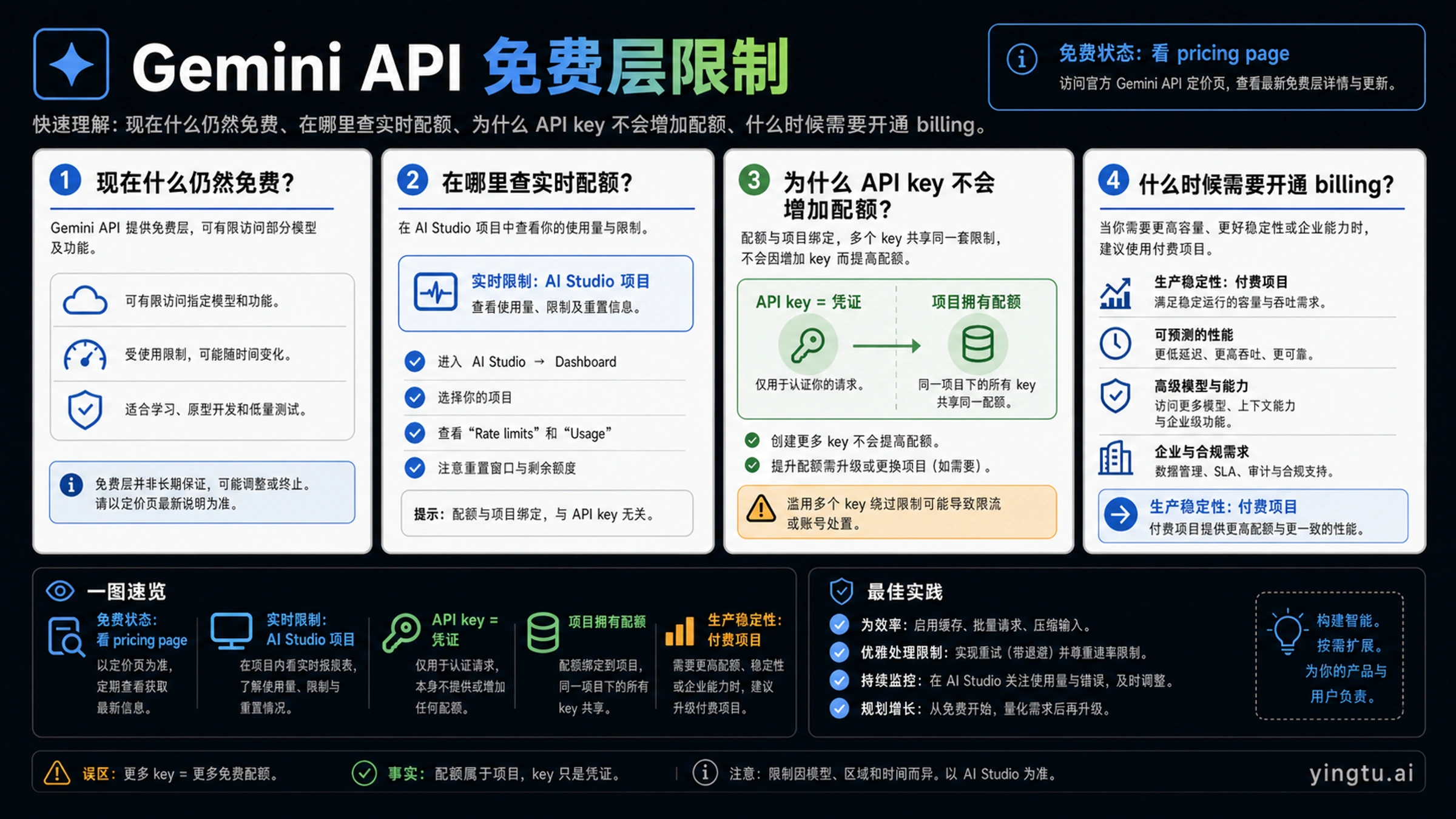
Gemini API 现在仍然有部分模型和功能行可以走免费层,但“Gemini API 免费层限制”不能再理解成一个写死在公开表格里的统一数字。真正会影响你应用能不能继续调用的,是 API Key 背后的 Google Cloud 项目、正在调用的模型、使用层级、地区、计费状态,以及 Google 当前的产品策略。
截至 2026 年 4 月 25 日,最稳妥的判断方式是:先用 Google 的 Gemini API pricing page 看目标模型或功能行是否仍标注 Free Tier,再打开 AI Studio,切到创建这个 API Key 的项目,查看该项目当前显示的 RPM、TPM、RPD、重置规则和使用量。多创建几个同项目的 API Key 不会多出几份免费额度;Key 只是凭证,项目才是额度和计费的归属单元。
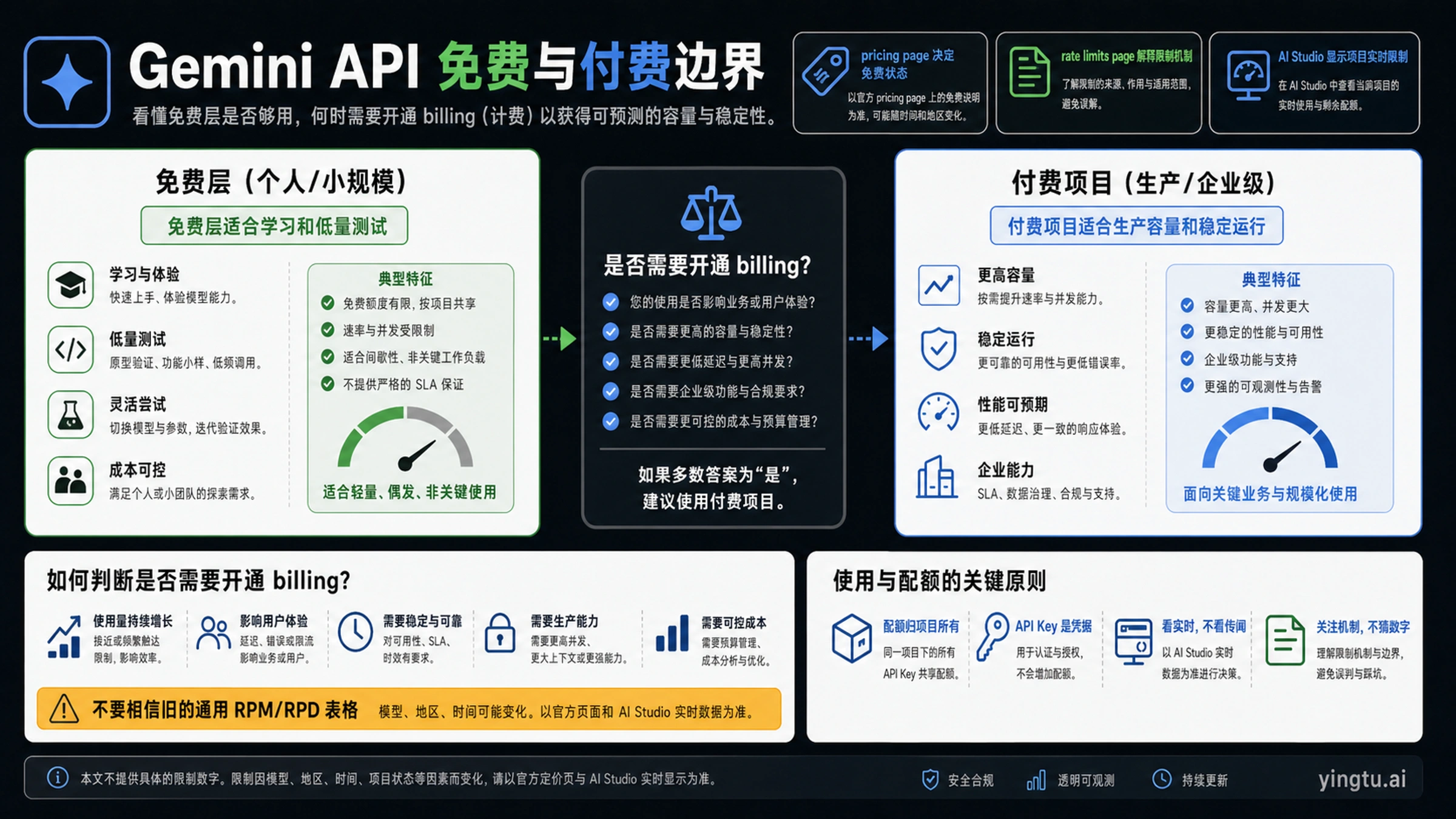
如果你只是学习 API、验证提示词、做小型原型,免费层依然有价值。若你的服务要面向用户、处理敏感或商业数据、需要稳定吞吐、经常遇到 429,或者你要用的模型行本来就不是免费层,就应该把工作负载迁到启用计费的项目,而不是继续围绕免费额度做生产承诺。
| 你真正想问的问题 | 现在的回答 | 应该检查哪里 |
|---|---|---|
| Gemini API 还免费吗? | 仍有部分模型和功能行有 Free Tier。 | Google Gemini API 价格页 |
| 我的精确免费额度是多少? | 取决于项目、模型、层级、地区和计费状态。 | AI Studio 中对应项目的使用量 / 速率限制视图 |
| 每个 API Key 都有独立额度吗? | 没有。Key 负责认证,项目拥有额度和账单边界。 | API Key 文档、项目和计费设置 |
| 超出额度会怎样? | 常见表现是 429 或 RESOURCE_EXHAUSTED。 | Rate limits 与 troubleshooting 文档 |
| 生产环境能不能靠免费层? | 只有低风险、低流量、可失败的场景才适合。 | 计费、数据处理和使用层级文档 |
现在说 Gemini API 免费层限制,实际是在说三件事
第一件事是模型或功能本身是否仍然允许免费使用。这个答案不应该从旧博客、截图或论坛表格里抄,而应该看 Google 当前的价格页。一个模型可能在某个 API 路径上有免费层,在另一个功能、预览能力、图像或批处理路径上没有免费层;同一个 Gemini 品牌下的不同模型行也可能处在不同的可用状态。
第二件事是速率限制怎么定义。Google 的 rate limits documentation 仍然把 RPM、TPM、RPD 作为核心维度:每分钟请求数、每分钟 token 数、每日请求数。它告诉你该怎样理解限制,但不等于承诺所有项目都永远看到同一组数字。
第三件事是你的项目现在实际能用多少。这个数字要回到 AI Studio 里看项目视图,因为项目、模型、地区、使用层级、计费状态或 Google 政策变化,都可能改变实际可用额度。换句话说,价格页回答“这个模型行是否免费”,AI Studio 回答“这个项目此刻能用多少”,API Key 本身不负责给你一份新额度。
旧的 RPM/RPD 表只能当历史线索。只要某份资料直接告诉你“Gemini API 免费层就是一组固定 RPM/RPD 数字”,但没有让你检查 AI Studio 项目视图,就不能把它当成当前生产合同。
哪些来源分别负责哪些答案
免费层问题容易出错,是因为很多人把几个不同来源混在一起看。最安全的做法是把每类判断交给对应来源。
| 要确认的说法 | 最合适的来源 | 怎么使用 |
|---|---|---|
| 某个模型或功能是否有 Free Tier | Gemini API pricing | 找到当前模型行、API 表面和免费/付费状态。 |
| RPM、TPM、RPD 这些限制维度怎么理解 | Gemini API rate limits | 确认速率维度、使用层级和重置逻辑。 |
| Key 属于哪个项目 | Gemini API key documentation | 确认调用凭证背后的项目上下文。 |
| 开通计费会改变什么 | Gemini API billing documentation | 理解付费项目、使用层级、数据处理和 Cloud credit 边界。 |
| 为什么请求失败 | Gemini API troubleshooting | 把 429、额度耗尽、地区、计费或模型不可用分开处理。 |
这个来源分工比静态数字更重要。价格页可以告诉你模型是否免费,但不能替代项目实时仪表盘。速率限制文档可以解释 RPM、TPM、RPD,但不能说明你的 API Key 单独拥有一桶额度。计费文档可以说明升级边界,但并不意味着免费项目适合处理真实用户数据。
如果只记一条规则,就记这一条:模型免费状态、项目实时额度、计费状态是三个不同表面。
API Key 不是额度池,项目才是额度归属
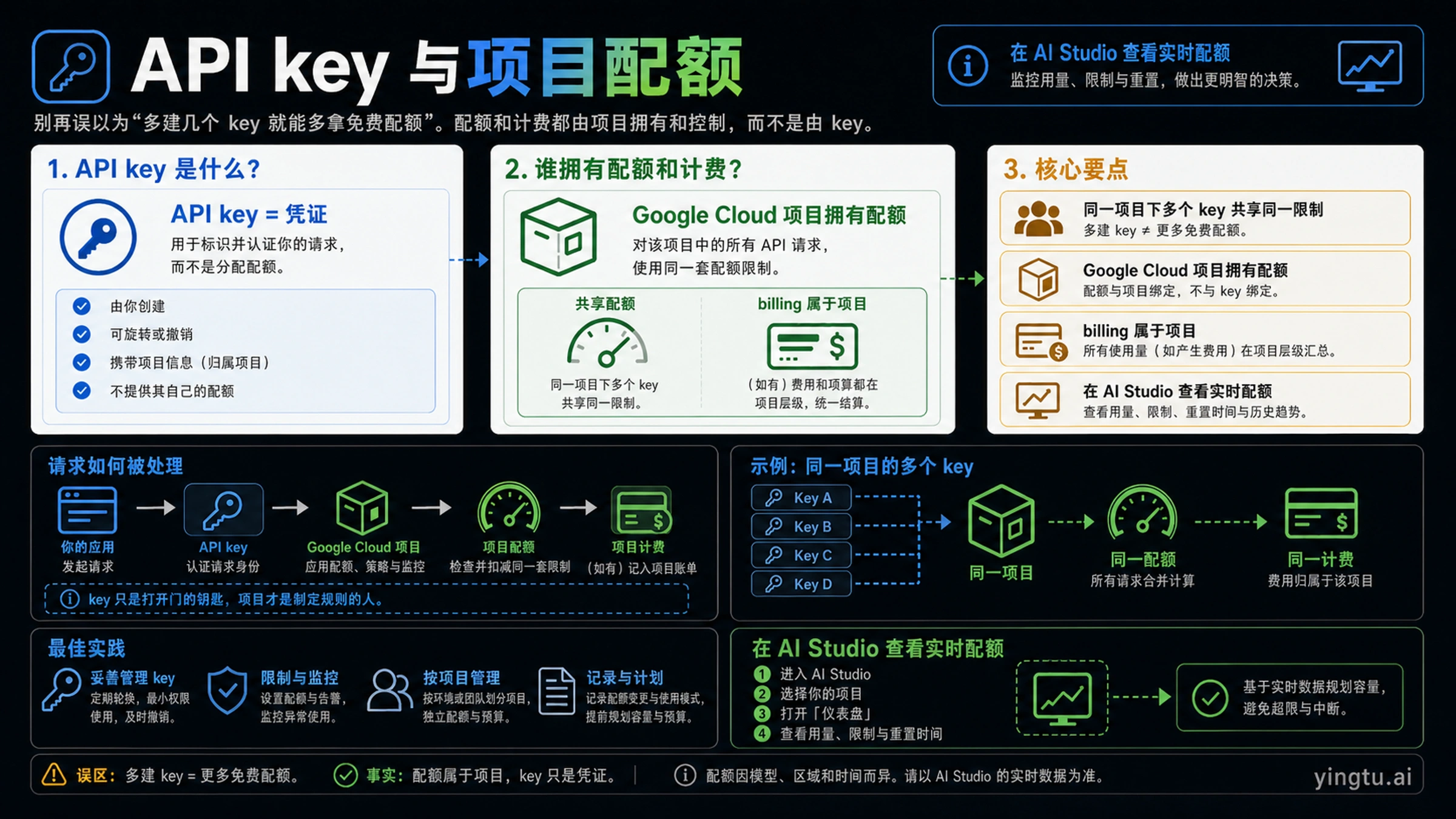
API Key 是凭证。它让请求被识别并通过认证,但它不会凭空创建独立的免费额度池。你把同一个项目里的 Key A、Key B、Key C 分别放到开发、测试、生产环境,这些 Key 仍然消耗同一个项目的额度。
这会直接影响排查方式。很多人看到一个 Key 已经 429,就想再创建一个新 Key 继续跑。如果新 Key 仍然来自同一个项目,问题通常不会消失。新 Key 适合做轮换、环境隔离、安全管理,不适合当作扩大免费额度的办法。
真正应该检查的是项目:谁创建了项目,哪个 Google 账号管理它,是否启用了计费,调用的模型 ID 是否正确,AI Studio 里打开的是不是同一个项目。团队协作时尤其要注意,一个同事发来的 Key 可能属于他的项目,不一定属于你的预算、额度或合规边界。
| 检查项 | 为什么重要 |
|---|---|
| 创建 Key 的 Google 账号是谁 | 决定你能否进入正确管理界面。 |
| Key 背后是哪一个 Google Cloud 项目 | 额度、计费、使用记录都挂在项目上。 |
| 这个项目是否启用计费 | 使用层级、数据处理和可用模型可能变化。 |
| 代码里调用的模型 ID 是什么 | 不同模型行的免费状态和限制不同。 |
| AI Studio 里看的是否同一项目 | 看错项目会得到完全错误的额度判断。 |
不要用“多建 Key”绕额度。正确做法是减少请求、检查模型和项目、优化重试,或者把需要稳定容量的应用迁到计费项目。
免费层适合什么,不适合什么
免费层最适合开发、学习和低流量测试。你可以用它熟悉 Gemini API、比较提示词、验证小型原型、跑偶发的内部工具。它不适合在没有退路的情况下承诺客户吞吐,也不适合处理不能被免费层数据政策覆盖的内容。
| 工作负载 | 免费层是否合适 | 付费项目是否合适 |
|---|---|---|
| 学习 API 调用 | 合适 | 通常不必要 |
| 使用合成数据的小型原型 | 合适,但要低频 | 需要接近真实吞吐测试时更合适 |
| 内部演示 | 可以,但要接受失败 | 会议、客户演示或稳定体验更适合 |
| 面向真实用户的功能 | 风险较高 | 通常是正确路径 |
| 敏感、合规或商业数据 | 不建议默认使用免费层 | 应核对付费数据处理条款 |
| 高流量批处理 | 不适合 | 使用付费层或适合批处理的路径 |
| 只在付费层开放的模型或功能 | 不可用 | 必须付费 |
还要注意预算假设。Google 当前计费文档说明,2026 年 3 月之后创建的新 Google Cloud 免费试用额度不适用于 Gemini API 或 AI Studio。因此不要把“Cloud 有免费试用金”直接写进 Gemini API 成本计划,除非当前计费文档明确支持。
升级不是失败,而是边界变清楚了。免费层够用时就用免费层;一旦正常使用频繁触发 429、模型行需要付费、用户不能接受失败、数据处理要求变高,就应该开通计费并设置预算监控。
如何检查你的实时免费额度
实际操作不复杂,但必须对准项目。
- 用管理 API Key 的 Google 账号打开 AI Studio。
- 切到应用正在使用的项目。
- 打开该项目的 usage 或 rate limit 视图。
- 确认代码里调用的模型 ID。
- 记录 RPM、TPM、RPD、重置规则、使用层级和计费状态。
- 在发布、演示、迁移和流量变化前重新检查。
如果你在比较多个 Key,不要按 Key 比较,而要按项目比较。两个 Key 只要属于同一个项目,就应该视为同一个额度归属。两个项目即使调用同一模型,也可能因为计费、地区、账号历史或当前层级不同而看到不同结果。
想理解 RPM、TPM、RPD 的细节,可以看 Gemini API rate limits guide。这里的重点是决策:RPM 控制请求频率,TPM 控制 token 吞吐,RPD 控制每日总量;任意一个维度耗尽,都可能导致请求失败。
遇到 429 或 RESOURCE_EXHAUSTED 后先做什么
429 不等于免费层消失了。它更常见的含义是:某个速率维度耗尽了、你看错了项目、调用了错误模型、模型行需要计费、地区或账号状态不匹配,或者应用重试方式把限流放大了。
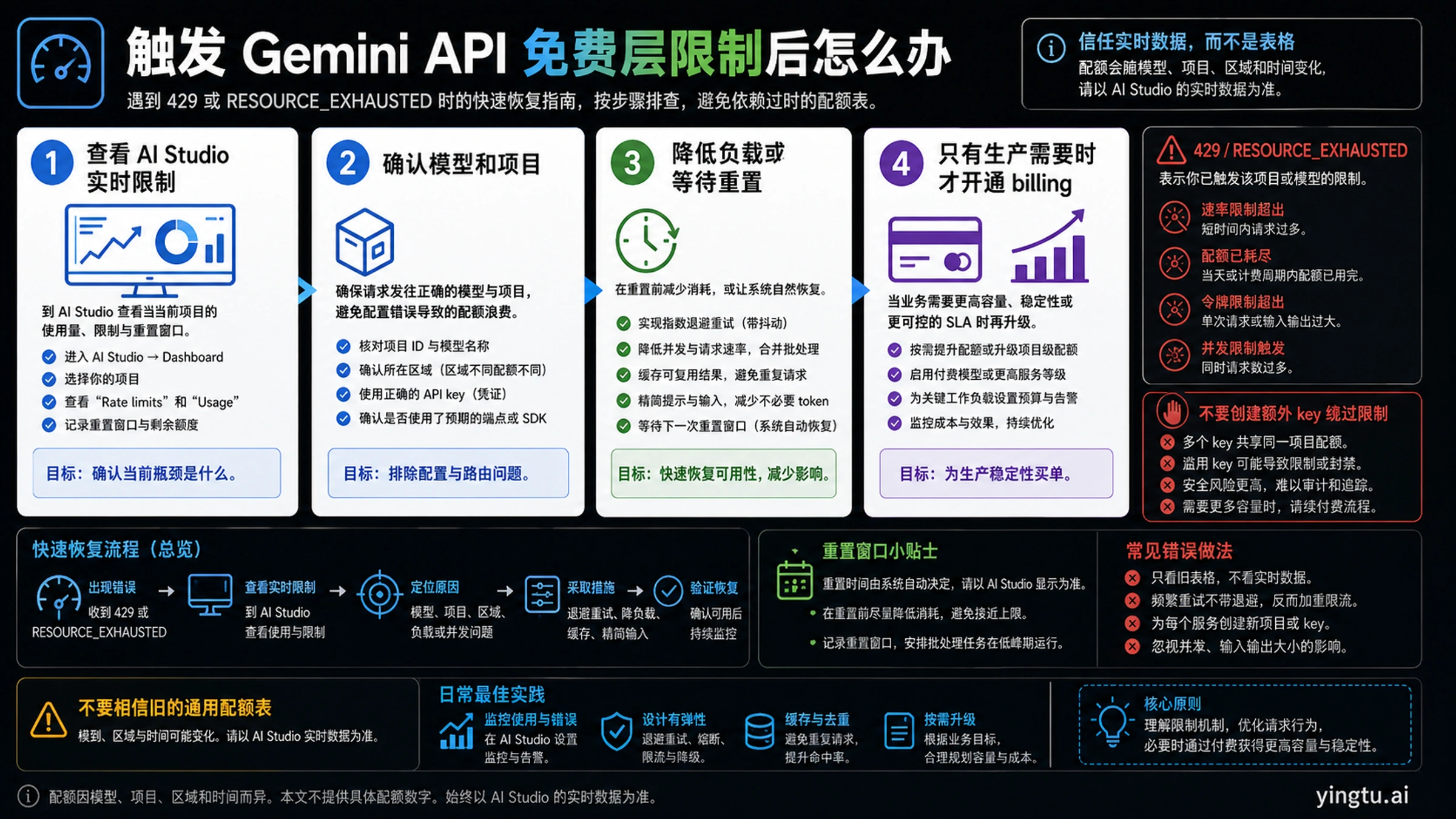
按这个顺序排查:
| 步骤 | 动作 | 为什么先做 |
|---|---|---|
| 1 | 在 AI Studio 检查 Key 背后的项目 | 先确认真实额度归属。 |
| 2 | 核对模型 ID 和 API 表面 | 付费模型、预览模型或不同功能行会改变结果。 |
| 3 | 分别看 RPM、TPM、RPD | 只有知道耗尽哪个维度,才能决定修复方式。 |
| 4 | 减少并发并加入退避重试 | 过快重试会让限流更严重。 |
| 5 | 缩短提示词、缓存重复结果 | 立刻降低 token 和请求消耗。 |
| 6 | 正常流量仍触顶时迁到计费项目 | 生产容量不应依赖脆弱免费额度。 |
如果错误是 RESOURCE_EXHAUSTED,先当作额度事件处理;如果错误信息提到 billing、region、unsupported model 或 failed precondition,就不要只等待重置。需要回到 troubleshooting 文档,把额度、计费、地区和模型资格分开。
停止线也很清楚:不要为了绕限制创建更多同项目 Key。要么优化负载,要么确认项目,要么升级项目。
设计上怎样避免被免费层变化打断
免费层会变,所以系统不要依赖一个写死数字。
把免费层用于测量,而不是承诺。开发阶段记录真实请求数、提示词长度、token 消耗、失败率和重试次数。这样你能知道实际负载是否适合免费层,而不是只看旧表格上某个数字够不够大。
保留模型路由。简单分类、实体抽取、短回复可以用更快更便宜的模型;复杂推理、长上下文、代码分析再交给更强模型。这样不是绕额度,而是把有限额度用在真正需要的位置。
缓存可以重复的结果。FAQ、分类器、路由助手、内部知识问答经常重复相似请求。缓存能同时减少请求数和 token 数,而且不会降低模型质量。
按维度记录错误。每日额度问题、每分钟并发问题、token 吞吐问题的解决办法不同。日志里只写“Gemini failed”不够,至少要记录模型 ID、项目、错误码、请求大小、重试次数和当时的使用层级。
提前规划付费路径。小项目可以免费开始,但生产计划应该已经知道哪个项目会开通计费、谁负责预算、告警阈值是多少、哪些数据允许发送、什么时候必须切换。
常见误区
不要说“免费 API Key 额度”。Key 不是额度主体。团队文档、代码注释和排障手册里应该写“项目额度”。
不要把旧 RPM/RPD 表复制进需求文档。表格能帮助理解量级,但当前可用数值应该由 AI Studio 项目视图负责。
不要把 Gemini App 的使用限制当作 Gemini API 事实。消费端 App、AI Studio、Gemini API、Vertex AI 可能是不同合同。
不要默认 Google Cloud 免费试用金能覆盖 Gemini API。写预算前先看当前计费页。
不要因为免费就觉得它更安全。免费层的数据处理边界和付费层可能不同。只要提示词包含客户数据、商业秘密、合规材料或用户不会预期被用于产品改进的内容,就应该先确认数据条款。
最终判断规则
当工作负载低频、非敏感、可以重试,并且仍在 Key 背后项目的 AI Studio 实时限制内,继续使用免费层。
当正常流量频繁 429、应用需要稳定吞吐、目标模型或功能不在免费层、隐私合规重要,或者用户会因额度变化遭遇真实失败时,迁到付费项目。
免费层仍然有价值,但它不是生产权益。把它当作需要实时检查、持续测量、定期复核的项目限制,而不是一个永远有效的公开数字。
常见问题
Gemini API 免费层现在还存在吗?
存在,部分 Gemini API 模型和功能行仍有 Free Tier。准确状态要看 Google 当前价格页,不要假设每个模型、预览能力、图像、批处理或特殊功能都免费。
我的 Gemini API 免费层精确限制在哪里查?
在 AI Studio 里查 API Key 背后的项目。项目视图才是实时 RPM、TPM、RPD、重置规则和使用量的操作来源。公开表格不能替代项目视图。
每个 Gemini API Key 都有自己的免费额度吗?
没有。API Key 只是凭证。Key 背后的 Google Cloud 项目拥有额度和计费边界。同一项目里的多个 Key 共享同一项目限制。
多创建几个 Key 能提高免费额度吗?
不能。同项目新 Key 适合轮换和环境隔离,但不增加额度。需要更多容量时,应该减少负载、改架构或迁到付费项目。
429 或 RESOURCE_EXHAUSTED 代表什么?
通常代表某个速率限制维度耗尽。先检查同一项目的 AI Studio 使用量,确认模型 ID,再决定等待、降低并发、缩短提示词、缓存响应或开通计费。
Gemini 3 或 Gemini 3.1 API 免费吗?
不要凭模型昵称或旧资料回答。去当前 Gemini API 价格页查看精确模型行和 API 表面。部分新模型或预览能力可能是付费限定,即使其他 Gemini 行仍有免费层。
免费层能用于生产吗?
只有低风险、低流量、可失败、非敏感的生产场景才可以考虑。面向客户、处理敏感数据、高流量或需要稳定性的应用,应使用启用计费的项目。
Google Cloud 免费试用金能抵 Gemini API 吗?
当前计费页说明,2026 年 3 月之后的新 Google Cloud 免费试用额度不适用于 Gemini API 或 AI Studio。写预算前应重新检查计费页。
免费层和付费层的模型质量不同吗?
更重要的差异通常不是模型质量,而是额度、功能、数据处理和可预期性。具体模型和层级请以当前价格页和计费文档为准。
依赖免费层前应该记录什么?
记录项目 ID、模型 ID、使用层级、AI Studio 里显示的 RPM/TPM/RPD、重置规则、计费状态和检查日期。在发布、演示、迁移和流量变化前重新核对。