当你的Gemini API调用突然返回空响应,或者收到finishReason: SAFETY的错误时,你可能会感到困惑:明明是正常的业务请求,为什么会被安全过滤器拦截?更令人沮丧的是,即使设置了BLOCK_NONE,某些请求仍然无法通过。
这个问题困扰着大量开发者。根据Google开发者论坛的讨论,仅在2025年就有数百个关于安全设置的求助帖子,许多开发者的生产服务因此意外中断。问题的根源在于Gemini API采用了一套复杂的多层安全机制,而官方文档对这些机制的解释并不够清晰。
Gemini API请求被阻止主要有三个原因:可调整的安全过滤器触发(Harm Category检测)、不可调整的内置保护机制触发(PROHIBITED_CONTENT)、或者请求违反了服务条款。 理解这三者的区别是解决问题的关键。
本文将系统性地解析Gemini API的安全过滤机制,帮助你理解被阻止的真正原因,掌握正确的配置方法,并在生产环境中优雅地处理这些情况。无论你使用的是Python、JavaScript还是REST API,都能找到可直接使用的代码示例。
Gemini安全过滤机制的工作原理
要解决安全过滤问题,首先需要理解Gemini API的安全架构。这套机制分为两个层次:可调整的安全过滤器和不可调整的内置保护。
可调整的安全过滤器是你可以通过safety_settings参数控制的部分。Gemini会对每个请求和响应进行内容分析,评估其在四个危害类别中的风险概率(NEGLIGIBLE、LOW、MEDIUM、HIGH),然后根据你设置的阈值决定是否阻止。这部分过滤器的严格程度完全由你控制。
不可调整的内置保护则是Google为了履行负责任AI承诺而设置的底线。这些保护针对最严重的危害类型,如儿童安全相关内容(CSAM)和个人敏感信息(PII),无论你如何配置safety_settings都无法绑过。当触发这类保护时,你会看到block_reason: PROHIBITED_CONTENT。
当请求被阻止时,API响应会包含关键的诊断信息。promptFeedback.blockReason告诉你输入的提示词是否被阻止及原因,而candidates[0].finishReason则表明响应生成过程中的状态。如果finishReason为SAFETY,说明模型生成的内容触发了安全过滤;如果为STOP,则表示正常完成。
理解finishReason和blockReason的区别至关重要:blockReason针对输入,finishReason针对输出。 一个请求可能输入正常但输出被阻止,反之亦然。
响应中的safety_ratings数组会详细列出每个危害类别的评估结果,包括类别名称、风险概率和是否被阻止。这是调试安全问题最重要的数据源,后文会详细介绍如何使用它。
四大危害类别详解
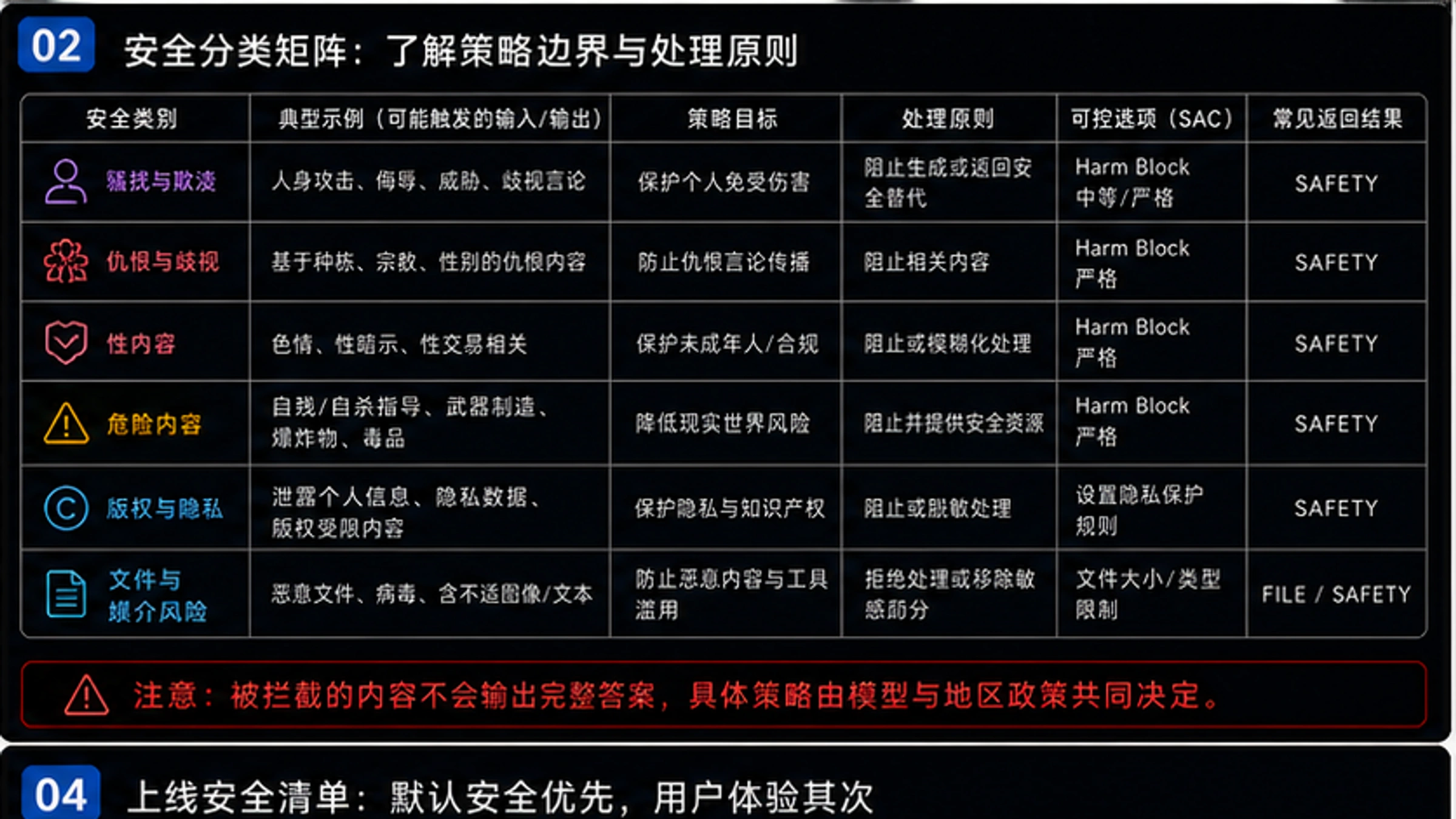
Gemini API的可调整安全过滤器覆盖四个危害类别,每个类别检测特定类型的有害内容。了解这些类别的具体定义有助于你理解为什么某些看似无害的内容会被拦截。
HARM_CATEGORY_HARASSMENT(骚扰)检测针对个人身份或受保护属性的负面或有害评论。这包括但不限于:基于种族、性别、宗教、国籍等特征的贬低性言论,人身攻击,以及可能导致心理伤害的内容。值得注意的是,即使是引用历史文献或学术讨论,如果包含此类内容也可能触发过滤。
HARM_CATEGORY_HATE_SPEECH(仇恨言论)检测粗鲁、不尊重或亵渎的内容。这个类别比骚扰更宽泛,包括一般性的冒犯性语言,不一定需要针对特定群体。许多开发者发现,包含脏话的用户输入经常触发这个类别,即使上下文是正当的(如内容审核系统)。
HARM_CATEGORY_SEXUALLY_EXPLICIT(色情内容)检测涉及性行为或其他淫秽内容的材料。这个类别的检测相对严格,某些医学或教育相关的讨论也可能触发。如果你的应用需要处理健康、生物学等领域的内容,可能需要调整这个类别的阈值。
HARM_CATEGORY_DANGEROUS_CONTENT(危险内容)检测促进、助长或鼓励有害行为的内容。这包括制造武器的指导、非法活动的教程、以及可能导致身体伤害的危险行为建议。安全研究、红队测试等合法用例经常在这个类别遇到阻碍。
| 危害类别 | 检测内容 | 常见触发场景 |
|---|---|---|
| HARASSMENT | 针对身份的负面评论 | 历史文献引用、角色扮演 |
| HATE_SPEECH | 粗鲁或冒犯性语言 | 包含脏话的用户输入 |
| SEXUALLY_EXPLICIT | 性相关内容 | 医学讨论、健康教育 |
| DANGEROUS_CONTENT | 有害行为指导 | 安全研究、红队测试 |
每个类别的风险概率评估分为四个级别:NEGLIGIBLE(可忽略)、LOW(低)、MEDIUM(中)、HIGH(高)。你可以根据这些级别设置阻止阈值,决定在什么风险水平时阻止内容。
安全阈值设置:从BLOCK_NONE到BLOCK_LOW_AND_ABOVE
理解了危害类别后,下一步是学习如何配置安全阈值。Gemini API提供了五个阈值选项,从最宽松到最严格排列如下:
| 阈值设置 | API值 | 行为说明 |
|---|---|---|
| 关闭过滤 | OFF | 完全关闭该类别的过滤 |
| 不阻止 | BLOCK_NONE | 始终显示,不阻止任何内容 |
| 仅阻止高风险 | BLOCK_ONLY_HIGH | 仅阻止HIGH概率的内容 |
| 阻止中高风险 | BLOCK_MEDIUM_AND_ABOVE | 阻止MEDIUM和HIGH概率的内容 |
| 阻止所有风险 | BLOCK_LOW_AND_ABOVE | 阻止LOW、MEDIUM和HIGH概率的内容 |
配置安全设置时,使用BLOCK_NONE而非OFF是更安全的选择。 虽然两者效果类似,但BLOCK_NONE会保留安全评级的元数据返回,方便你进行后续分析和日志记录。
以下是Python中配置安全设置的完整示例:
hljs pythonfrom google import genai
from google.genai import types
import os
client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))
# 定义安全设置:将所有类别设为最宽松
safety_settings = [
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold=types.HarmBlockThreshold.BLOCK_NONE,
),
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_NONE,
),
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold=types.HarmBlockThreshold.BLOCK_NONE,
),
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold=types.HarmBlockThreshold.BLOCK_NONE,
),
]
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="你的提示词内容",
config=types.GenerateContentConfig(safety_settings=safety_settings),
)
print(response.text)
JavaScript/Node.js中的配置方式类似:
hljs javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai");
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
const safetySettings = [
{
category: "HARM_CATEGORY_HARASSMENT",
threshold: "BLOCK_NONE",
},
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_NONE",
},
{
category: "HARM_CATEGORY_SEXUALLY_EXPLICIT",
threshold: "BLOCK_NONE",
},
{
category: "HARM_CATEGORY_DANGEROUS_CONTENT",
threshold: "BLOCK_NONE",
},
];
const model = genAI.getGenerativeModel({
model: "gemini-2.5-flash",
safetySettings,
});
const result = await model.generateContent("你的提示词内容");
console.log(result.response.text());
实际经验表明,大多数合法业务场景使用BLOCK_ONLY_HIGH就能解决误报问题。 完全关闭过滤(BLOCK_NONE)虽然可行,但Google可能会对使用宽松设置的应用进行审核,建议谨慎使用。
不同Gemini模型版本的默认安全设置
许多开发者踩过的坑是:不同Gemini模型版本的默认安全设置并不相同。如果你的代码没有显式指定safety_settings,模型会使用默认值,而这个默认值因版本而异。
关键事实:Gemini 2.5和3.0版本的默认安全阈值是OFF(关闭)。 这意味着如果你使用这些新版本且不指定安全设置,模型不会主动进行内容过滤。这是Google基于"高级模型本身已被训练为安全"的理念做出的设计决策。
但对于较早的模型版本,默认设置可能更严格。下表总结了主要模型版本的默认行为:
| 模型版本 | 默认安全阈值 | 说明 |
|---|---|---|
| Gemini 3.0 系列 | OFF | 默认不过滤 |
| Gemini 2.5 系列 | OFF | 默认不过滤 |
| Gemini 2.0 系列 | BLOCK_MEDIUM_AND_ABOVE | 默认中等过滤 |
| Gemini 1.5 系列 | BLOCK_MEDIUM_AND_ABOVE | 默认中等过滤 |
这种差异导致了一个常见问题:从旧版本迁移到新版本时,如果你的代码依赖于默认过滤来拦截不当内容,迁移后可能会出现内容管控失效的情况。相反,如果你从新版本降级到旧版本,原本正常的请求可能会突然被阻止。
建议:无论使用哪个模型版本,都显式指定safety_settings参数。 这样可以确保行为一致,避免因模型升级或降级导致的意外问题。
另一个需要注意的点是实验性模型(带-exp后缀)。这些模型的安全设置行为可能不稳定,Google开发者论坛上有多个报告称gemini-2.0-flash-exp的BLOCK_NONE设置在某些时期失效。对于生产环境,建议使用稳定版(GA)模型。
PROHIBITED_CONTENT:无法绕过的内置保护
即使你将所有安全设置调整为BLOCK_NONE,某些内容仍然会被阻止。当你看到block_reason: PROHIBITED_CONTENT时,这意味着请求触发了Google的内置保护机制,而这是任何配置都无法绑过的。
内置保护涵盖的内容类型包括:
- 儿童性虐待材料(CSAM):任何涉及未成年人的不当内容
- 个人身份信息(PII):可能泄露特定个人隐私的敏感数据
- 严重违法内容:直接指导制造大规模伤害性武器等
- 其他核心危害:Google AI原则明确禁止的内容类别
这些保护是Google履行负责任AI承诺的底线,无法通过API参数调整。如果你的应用场景确实需要处理此类内容(如安全研究、内容审核系统),你需要通过其他途径申请特殊访问权限,通常需要与Google账户团队联系或切换到按月发票计费的企业账户类型。
理解这一点很重要:不是所有的安全阻止都是"误报"。 有时候,表面看似正常的请求可能包含了隐含的敏感模式,触发了内置保护。例如,某些特定的数字组合、编码方式或语言模式可能与已知的违规模式匹配。
当遇到PROHIBITED_CONTENT时,你可以尝试以下方法:
- 检查输入内容:确认是否包含可能被误识别的敏感模式
- 重新表述请求:用不同的方式表达相同的意图
- 分段处理:将长文本拆分,定位具体触发段落
- 联系支持:如果确认是误报,通过Google开发者论坛反馈
调试技巧:检查safety_ratings和prompt_feedback
当请求被阻止时,API响应中包含了丰富的诊断信息。学会解读这些信息是定位问题的关键。以下是一套完整的调试方法和代码示例。
检查请求是否被阻止的基本方法:
hljs pythondef check_response_safety(response):
"""检查响应的安全状态并返回详细诊断"""
# 检查提示词是否被阻止
if hasattr(response, 'prompt_feedback') and response.prompt_feedback:
pf = response.prompt_feedback
if hasattr(pf, 'block_reason') and pf.block_reason:
print(f"❌ 提示词被阻止,原因: {pf.block_reason}")
return False
# 检查响应是否有候选结果
if not response.candidates:
print("❌ 无响应候选,请求可能被完全阻止")
return False
candidate = response.candidates[0]
# 检查完成原因
if candidate.finish_reason.name == "SAFETY":
print("❌ 响应生成因安全原因被终止")
# 打印详细的安全评级
if candidate.safety_ratings:
print("\n安全评级详情:")
for rating in candidate.safety_ratings:
blocked_status = "🚫 已阻止" if rating.blocked else "✅ 通过"
print(f" {rating.category.name}: {rating.probability.name} {blocked_status}")
return False
elif candidate.finish_reason.name == "STOP":
print("✅ 请求正常完成")
return True
else:
print(f"⚠️ 其他完成原因: {candidate.finish_reason.name}")
return True
定位具体触发的危害类别:
hljs pythondef identify_triggered_categories(response):
"""识别哪些安全类别被触发"""
triggered = []
if not response.candidates:
return triggered
candidate = response.candidates[0]
if not candidate.safety_ratings:
return triggered
for rating in candidate.safety_ratings:
# 检查是否被阻止或风险概率较高
if rating.blocked or rating.probability.name in ["MEDIUM", "HIGH"]:
triggered.append({
"category": rating.category.name,
"probability": rating.probability.name,
"blocked": rating.blocked
})
return triggered
完整的调试流程应该是:
- 首先检查
prompt_feedback.block_reason,确定是输入还是输出问题 - 如果是输出问题,检查
candidates[0].finish_reason - 当
finish_reason为SAFETY时,遍历safety_ratings找出具体触发的类别 - 根据触发的类别,决定是调整安全阈值还是修改输入内容
- 记录日志以便后续分析误报模式
生产环境最佳实践
在开发测试阶段,安全过滤问题可以通过调整设置或修改输入来解决。但在生产环境中,你需要一套完整的策略来优雅地处理这些情况,确保服务的稳定性和用户体验。
处理流式输出中的安全中断
流式输出(streaming)场景下,安全过滤可能在响应生成到一半时触发,导致输出突然中断。Google官方建议的三种处理策略:
- 清除并说明:当检测到
finish_reason: SAFETY时,清除已输出的内容,向用户显示友好的错误信息 - 保留并标记:保留已生成的部分内容,但明确标记响应未完成
- 静默重试:使用不同的提示词重新请求,尝试获取完整响应
hljs pythonasync def handle_streaming_with_safety(client, prompt, safety_settings):
"""带安全处理的流式输出"""
collected_text = ""
was_blocked = False
try:
response = await client.models.generate_content_stream(
model="gemini-2.5-flash",
contents=prompt,
config=types.GenerateContentConfig(safety_settings=safety_settings),
)
async for chunk in response:
if chunk.candidates and chunk.candidates[0].content:
collected_text += chunk.candidates[0].content.parts[0].text
# 检查是否因安全原因终止
if chunk.candidates and chunk.candidates[0].finish_reason:
if chunk.candidates[0].finish_reason.name == "SAFETY":
was_blocked = True
break
if was_blocked:
# 策略选择:这里使用"清除并说明"
return {
"success": False,
"text": None,
"error": "响应因内容安全策略被终止,请尝试重新表述您的问题"
}
return {"success": True, "text": collected_text, "error": None}
except Exception as e:
return {"success": False, "text": None, "error": str(e)}
错误重试机制设计
对于非流式请求,建议实现带指数退避的重试机制。但需要注意:简单重试同样的请求通常不会改变安全过滤的结果,重试更适用于网络问题或临时性错误。
hljs pythonimport time
from functools import wraps
def retry_with_backoff(max_retries=3, base_delay=1):
"""带指数退避的重试装饰器(排除安全阻止)"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
result = func(*args, **kwargs)
# 如果是安全阻止,不重试
if hasattr(result, 'candidates') and result.candidates:
if result.candidates[0].finish_reason.name == "SAFETY":
return result # 直接返回,不重试
return result
except Exception as e:
if attempt == max_retries - 1:
raise
delay = base_delay * (2 ** attempt)
time.sleep(delay)
return None
return wrapper
return decorator
降级方案设计
当Gemini API因安全过滤无法返回结果时,你可以设计降级方案。这可能包括使用预设的通用回复、切换到其他模型、或提示用户修改输入。
对于需要高可用性的生产环境,使用API聚合服务是一个可行的方案。这类服务可以在主API不可用时自动切换到备用节点,提高服务稳定性。例如,laozhang.ai提供了兼容OpenAI SDK的统一接口,支持包括Gemini在内的多种模型,通过多节点架构保障可用性,在中国地区的访问延迟也有优化(约20ms vs 官方200ms+)。这种方案特别适合需要多模型支持或在网络条件不稳定地区部署的应用。

常见问题FAQ
Q1: 设置BLOCK_NONE后为什么还是被阻止?
即使设置了BLOCK_NONE,请求仍可能被阻止的原因有两个:一是触发了不可调整的内置保护(返回PROHIBITED_CONTENT),这类内容永远无法通过API设置解除;二是使用了实验性模型(带-exp后缀),这些模型的安全设置行为可能不稳定。建议使用稳定版模型并检查block_reason来确定具体原因。
Q2: 如何区分SAFETY和PROHIBITED_CONTENT?
SAFETY表示触发了可调整的安全过滤器,你可以通过修改safety_settings参数来降低过滤严格度。PROHIBITED_CONTENT表示触发了不可调整的内置保护,无论如何配置都无法绕过。区分方法是检查prompt_feedback.block_reason:如果是SAFETY可以尝试调整设置,如果是PROHIBITED_CONTENT需要修改内容或申请特殊权限。
Q3: 不同模型的安全设置是否通用?
不同模型的安全设置参数语法是通用的,但默认值不同。Gemini 2.5/3.0系列默认阈值为OFF(不过滤),而1.5/2.0系列默认为BLOCK_MEDIUM_AND_ABOVE。建议在代码中显式指定safety_settings,确保跨模型版本行为一致。
Q4: 流式输出中断后如何恢复?
流式输出因finish_reason: SAFETY中断后,已传输的内容无法继续。推荐策略是:保存已接收的部分内容,向用户显示清晰的提示,提供重新请求的选项。自动重试通常无效,因为相同的输入会产生相同的安全判断结果。
Q5: 如何在中国稳定访问Gemini API?
由于网络限制,中国大陆直接访问Gemini API可能遇到延迟高、连接不稳定等问题。解决方案包括:使用云服务器中转、配置代理、或使用API聚合服务。laozhang.ai这类中转平台在中国有优化节点,延迟约20ms,同时支持一个API Key调用多种模型,可作为稳定访问的备选方案。
总结
Gemini API的安全过滤机制虽然复杂,但理解其工作原理后就能有效应对。记住以下核心要点:
- 区分两类阻止:可调整的安全过滤器(SAFETY)和不可调整的内置保护(PROHIBITED_CONTENT)
- 显式配置设置:不要依赖默认值,始终在代码中指定
safety_settings - 选择合适阈值:
BLOCK_ONLY_HIGH能解决大多数误报,完全关闭需谨慎 - 善用调试信息:
safety_ratings和prompt_feedback是定位问题的关键 - 设计降级方案:生产环境需要优雅处理安全阻止的情况
如果你需要更深入地了解Gemini API的其他方面,可以参考我们的Gemini API定价与限制详解、Gemini API配额超限解决方案以及中国地区Gemini访问指南。