GPT Image 2 出图如果发糊、发脏、铺纹、噪点多、细节像被压缩过,先不要急着重写提示词。quality: "low" 本来就是草稿档,但脏纹、重复纹理、参考图残留、长对话上下文和导出压缩属于另一组问题,处理顺序不一样。
先按这个分支看:
| 看到的问题 | 先查什么 | 第一步处理 | 证据归属 |
|---|---|---|---|
| 整张图发软、细节少 | quality、size、是否被二次压缩 | 用 medium 或 high 跑一次对照 | OpenAI 参数文档 |
| 画面有脏纹、铺纹、灰蒙蒙的覆盖感 | 新聊天或新 API 请求,去掉参考图 | 在干净上下文里复现一次 | 社区症状和自己的复现 |
| 局部编辑越改越脏 | 参考图、mask、上一轮图片、会话状态 | 换干净底图或去掉继承图片 | 同一路径对照 |
| 高分辨率图看起来更不稳 | 目标尺寸、宽高比、原始文件 | 先保存原图,在最终显示尺寸下检查 | 官方尺寸边界加本地检查 |
| 只有某个入口效果差 | ChatGPT、Image API、Responses API、封装平台 | 保持提示词和模型不变,只换入口 | 同 prompt 路由对比 |
停止规则:没有保存原始生成文件、没有至少对比一次 medium 或 high、没有在干净上下文里复现持续脏纹或铺纹之前,不要把图当成最终素材。问题如果在干净复现里仍然存在,再保存 prompt、模型、quality、size、入口、时间和原始输出文件。
先把“低档设置”和“看起来差”分开
中文里说“画质差”很容易混在一起。第一种是真用了低档设置:API 请求里把 quality 设成了 low,或者封装工具默认给了草稿档。第二种是结果看起来差:细节糊、局部脏、重复纹理、边缘压缩、文字发虚、参考图噪点被带进新图。
这两个问题不能用同一个答案。quality: "low" 的意义是快、便宜、适合出草稿和缩略预览,不适合直接验收商品图、海报、UI 信息板或投放素材。它可能解释“整体不够精细”,但不能自动解释“为什么有脏纹、铺纹、奇怪覆盖层”。
如果请求确实用了 low,先把它当成草稿输出,而不是模型事故。改到 medium,保持 prompt、size、参考图和入口不变,跑一次。如果 medium 仍然出现同样的脏纹或重复纹理,再进入伪影排查。如果 medium 干净,说明之前的问题主要是质量档位,不需要重写整套 prompt。
如果一开始用的是 medium、high 或 auto,就不要只盯着“把提示词写得更细”。先把 size、导出格式、参考图、编辑状态和入口查完。很多失败看起来像语义没听懂,实际是旧上下文、参考图压缩痕迹或 CMS 二次压缩把图变差了。
先查 quality、size 和导出链路
最快的干净测试是机械检查,而不是改文案。先看真实发出的请求。很多封装工具会把 UI 里的“高清”映射成自己的默认值,或者只显示模型名,不显示 quality。如果你走 Image API 或 Responses API 图像工具,记录完整请求体;如果你在 ChatGPT 里生成,至少记录看到的入口、是否带参考图、是否在长对话里继续生成。

第二步看 size。高分辨率和高质量不是一回事。尺寸变大,会让纹理、文字、边缘和重复图案更容易暴露;质量档位改变的是生成投入或细节等级;导出格式和压缩改变的是最终文件。大图不一定更干净,小图也可能因为压缩后看起来更糊。
第三步保存原始输出。不要只看网页预览,也不要先上传到 CMS、社交平台或转换 WebP/JPEG 后再判断模型。把原始文件、发布后的文件和无损导出放在一起比。如果原图干净、发布图变糊,应该修导出链路,而不是继续烧生成次数。
第四步确认入口支持你以为自己使用的设置。ChatGPT、Image API、Responses API 的图像工具和第三方封装都可能叫 GPT Image 2,但它们周围的上下文、默认尺寸、压缩方式、参考图处理、prompt 重写和失败重试并不完全一样。只有入口相同,设置相同,prompt 相同,才适合比较“这次为什么差”。
如果团队里多人协作,最好把这组设置写进素材备注或任务单:谁生成、从哪个入口生成、哪一档 quality、原图存在哪里、发布图经过了什么转换。否则设计、运营和开发看到的可能不是同一张文件,后续讨论会把模型问题、压缩问题和上传问题混在一起。
这个记录还会让下一次复用更稳定:能复现的好图才值得做成模板,不能复现的好图只能算一次运气,也不应该进入批量生产或对外交付使用,更不能作为参数标准。
用干净上下文复现一次
如果 medium 或 high 仍然不干净,下一步不是给 prompt 加十个形容词,而是清空上下文。上下文污染很容易被误判成模型质量差,因为它的表现常常是“风格总是脏”“纹理一直残留”“怎么说都像上一张图”。
在 ChatGPT 里,开一个新聊天。不要沿着已经失败十几轮的线程继续改,那里面可能有旧参考图、旧截图、旧修正、失败输出和你不再想要的风格要求。用同一个核心 prompt 在新聊天里生成。如果新聊天明显更干净,旧线程就是诊断对象之一。
如果你必须继续使用原线程,也要先做一次缩小范围的对照:删掉所有不必要的参考图,只保留一句核心任务;不要同时要求换风格、修文字、扩尺寸和改变构图;先确认主体、背景和材质是否恢复正常。这个动作的目的不是产出最终图,而是判断旧上下文是否仍然在影响下一张图。只要对照结果变干净,后续就应该迁移到新上下文,而不是在旧线程里继续堆指令。
在 API 里,发一个新请求,不带参考图,只保留核心 prompt、模型、quality 和 size。再把参考图加回来。如果问题只在参考图回来后出现,说明参考图把噪点、压缩、边缘、光照或不想要的材质带进了结果。此时应该清理参考图、换 mask、重做底图,而不是继续写“更高清、更干净、更专业”。

如果你用的是封装平台或中转入口,尽量拿一个可控的第一方入口做对照。保持 prompt、模型、宽高比、quality 不变,只换入口。封装入口变差并不能直接证明 GPT Image 2 本身变差,它也可能是默认压缩、模型映射、prompt 改写或后处理不同。
干净复现本身就是价值。一个窄复现比一句“又糊了”更有用:同一个 prompt、无参考图、model: "gpt-image-2"、quality、size、入口、时间、原始文件。后面无论是升级设置、换入口还是反馈问题,都需要这组证据。
脏纹、铺纹和噪点持续出现时
有些用户会把 GPT Image 2 的问题描述成脏纹、灰尘感、重复铺纹、奇怪覆盖层、噪点块或类似压缩过的纹理。没有第一方说明之前,这类表述只能当作“已报告的伪影症状”,不能直接写成官方确认的模型级缺陷。
可操作的重点是复现边界。如果脏纹只在某个编辑任务里出现,先移除参考图、换 mask、重新生成底图。如果噪点只在发布后出现,先比较原图和压缩后的图。如果问题只在大尺寸出现,先试一个较小 master,确认构图后再决定原生高分辨率、后期放大或换生产路线。
| 症状 | 先做 | 暂时不要做 |
|---|---|---|
| 无关 prompt 都有灰蒙蒙覆盖感 | 新聊天或新 API 请求,medium 质量,无参考图 | 不要先买 prompt 包 |
| 某个局部编辑反复铺纹 | 去掉参考图或换干净 mask | 不要继续在同一张污染底图上修 |
| 发布后才变糊 | 对比原始输出和发布文件 | 不要先怪模型 |
| 大图更容易露出问题 | 先验收较小 master,再决定是否上 4K | 不要默认原生高分辨率最稳 |
| 只有某个入口坏 | 换可控入口同 prompt 对比 | 不要把入口问题写成官方模型事故 |
如果干净请求里仍然出现相同伪影,记录要窄。好的记录包括:同 prompt、无参考图、模型、quality、size、入口、时间和原始输出。弱记录是:改了五次 prompt 后说“它还是不行”。前者能帮助定位,后者只会让排查回到猜测。
也不要把所有视觉失败都叫“低画质”。文字错位、人物手部错误、构图不按要求、产品标识不准、品牌色跑偏、背景多出物体,这些更像提示词约束、编辑范围或模型理解问题;脏纹、重复纹理、灰蒙蒙覆盖、局部压缩块和边缘糊化才更适合进入画质链路。先把问题命名准确,后面的修复路径才不会互相干扰。
分清 ChatGPT、Image API、Responses API 和封装入口
手动探索时用 ChatGPT 没问题。它适合快速试概念、比较风格、做少量编辑。但 ChatGPT 里你看不到所有底层参数,长对话也可能带入旧上下文,所以它的第一排查动作是新聊天、短 prompt、去掉参考图、保存原图和人工对照。
开发排查更适合 Image API。你能显式写 gpt-image-2、quality、size,能控制输入图片,能保存返回的图像数据,也能把请求体和输出文件留档。要判断“是不是某个参数导致差”,Image API 的证据链更清楚。
Responses API 图像工具适合放在更大的助手流程里,比如多步生成、工具调用或自动化应用。但它也会让画质排查更复杂,因为外围助手可能改写 prompt、追加上下文或自动选择工具选项。质量问题出现时,先把流程降到最小图像调用,再看问题是否仍然存在。
第三方封装入口只有在看得见足够细节时才适合比较。至少要知道模型映射、quality 支持、size 支持、是否压缩、是否改 prompt、是否重试、是否带自己的后处理。否则它只能证明“这个入口的结果不好”,不能证明“GPT Image 2 必然不好”。
如果排查后发现真正的问题是换模型、换价格路线、免费入口或高分辨率生产,就交给相邻主题处理。模型选择看 GPT Image 2 vs Nano Banana Pro 路线对比,成本入口看 GPT Image 2 API 低成本路线,不要把这些选择混进当前质量排查。
高分辨率不是万能修复
很多人把“画质差”直接等同于“分辨率不够”。这会误导排查。分辨率决定画布和输出尺寸,quality 决定生成细节档位,格式和压缩决定最终交付文件。三者任何一个出错,都可能让结果看起来差。
高分辨率还会放大问题。细密文字、UI 信息板、商品边缘、皮肤纹理、重复图案和高反光材质,在大尺寸下更容易看到瑕疵。原生高分辨率尝试如果不稳,先用 medium 或 high 做一个较小 master,确认构图、光线、文字和主体,再决定是否原生高分辨率、后期放大或重做生产路线。
生产场景还要区分“看起来清楚”和“可交付”。社交图在手机上能看,不代表落地页首屏、广告物料、海报印刷或应用商店截图都能过。真正的验收应该按最终使用场景打开:网页就看实际 CSS 尺寸,印刷就看目标 DPI,电商图就放到商品卡片和详情页里看边缘,信息板就检查标题、数字和小字。只有在最终场景里仍然干净,才算画质问题被排除。
如果你真正的问题是“GPT Image 2 能不能出 4K、该用什么尺寸、怎么验文件”,请看 GPT Image 2 4K 尺寸和验证指南。低画质排查只问一个更窄的问题:同一缺陷是否只在大尺寸出现。如果缺陷在所有尺寸都出现,就不要把分辨率当成唯一答案。
上线前的验收清单
最终验收应该简单、重复、可交接。不要靠一张小预览决定能不能上线。
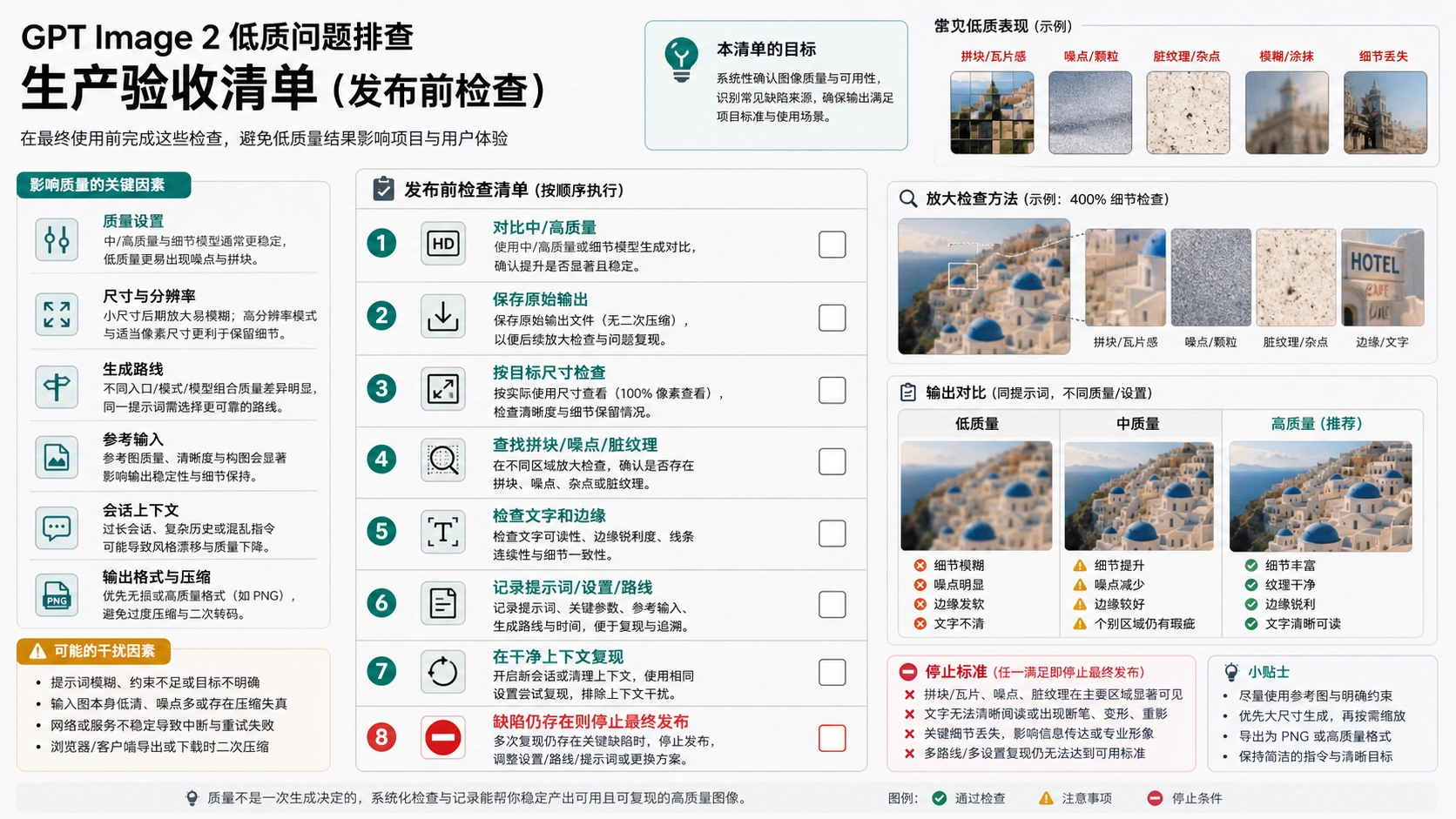
| 检查项 | 通过条件 |
|---|---|
| 原图已保存 | 有生成后的原始文件,早于压缩、上传和 CMS 转换 |
| 设置已记录 | 记录模型、入口、quality、size、参考图、是否编辑 |
| medium/high 已对比 | 最终验收前至少看过一个非 low 输出 |
| 目标尺寸已检查 | 在实际展示或印刷尺寸下看过图 |
| 伪影扫描完成 | 看过铺纹、脏纹、噪点、边缘、文字、重复纹理 |
| 干净复现已尝试 | 持续缺陷在新聊天或新 API 请求中复现过 |
| 停止规则已执行 | 干净复现仍坏时,不把素材批准为最终版 |
这个清单不是流程负担。它防的是两种最贵的错误:在被污染的上下文里反复生成,以为 prompt 再细一点就能好;或者因为小预览看着能用,就把压缩严重或带伪影的图发到生产环境。
不要过早下结论
不要因为某个入口的一张坏图,就说 GPT Image 2 对所有人都坏了。更有用的问题是:这次能控制的变量是哪一个?quality、size、参考图、聊天上下文、API 路由、封装默认值、导出压缩,还是高分辨率分支?
不要把 quality: "high" 当万能修复。它值得用于最终比较,但如果问题来自参考图继承、长聊天上下文、导出压缩或入口后处理,高质量档位也可能保留同样的脏纹。
不要用免费入口或第三方生成器来证明官方模型好坏。免费体验、浏览器测试、API 计费、平台额度、免登录工具是不同合同。如果真正要判断免费或无限入口,看 GPT Image 2 免费与不限路线指南。如果只问官方 API 是否有免费档,看 GPT Image 2 API 免费档说明。
不要从单张小预览直接上线。保存原图、在目标尺寸检查、至少比较一个非 low 输出、对持续问题做干净复现,再决定继续生成、换入口、换尺寸、清参考图或保留证据反馈。
常见问题
quality: "low" 会让 GPT Image 2 看起来差吗?
会。quality: "low" 适合草稿、缩略预览和快速迭代,不适合最终验收。它能解释整体发软或细节不够,但如果 medium 或 high 在干净上下文里仍然出现脏纹、铺纹、重复纹理,就要按伪影症状排查。
是不是永远应该用 quality: "high"?
不是。草稿阶段用 low,工作预览用 medium,高价值素材或最终对照再用 high。高质量档位不能自动修复参考图污染、长对话上下文、导出压缩或封装入口默认值。
为什么新聊天能改善图像质量?
新聊天会移除旧提示词、失败图片、参考图、修正记录和不再需要的风格上下文。同一个核心 prompt 在新聊天里更干净时,旧线程就是问题的一部分。
为什么会有脏纹、铺纹或灰蒙蒙的质感?
这类现象应先当作已报告的伪影症状处理。去掉参考图,开新聊天或新 API 请求,比较 medium/high,保存原图。如果干净复现仍然出现,再保留窄证据,不要直接宣布官方模型级原因。
4K 会不会让 GPT Image 2 更容易出问题?
会暴露不同问题。高分辨率让纹理、文字、边缘和重复图案更容易被看到,也让失败成本更高。先验收较小 master,再决定是否原生高分辨率或后期放大。
Image API 是否比 ChatGPT 更适合排查?
对开发者排查来说,是。Image API 能记录模型、quality、size、输入图和原始输出,证据更清楚。ChatGPT 适合手动探索,但底层参数和会话上下文不一定完全可见。
反馈 GPT Image 2 画质问题前要保存什么?
保存原始输出文件、prompt、模型标签、入口、quality、size、参考图、编辑 mask、时间,以及问题是否能在新聊天或新 API 请求中复现。这比几轮改写后的截图更有用。