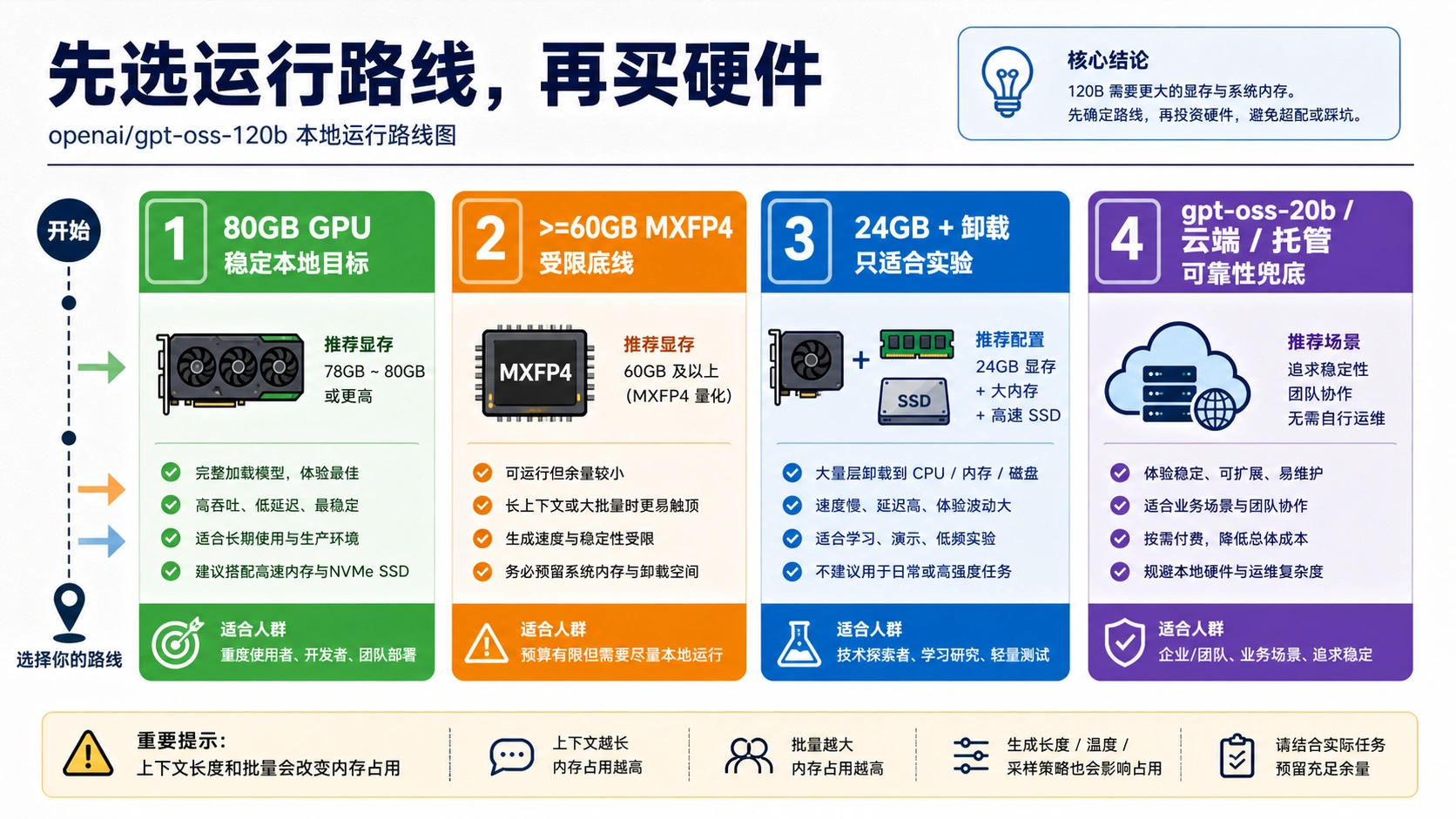
要稳定本地运行 gpt-oss-120b,先按 80GB GPU 级别规划。>=60GB 更像 MXFP4 路线下的受限加载门槛,不是舒适余量;24GB 显卡配 CPU 或 NVMe 卸载,只能当实验路线。只要你在意速度、长上下文、并发或可复现性,就应该把 gpt-oss-20b、云 GPU 或托管访问列入同一张决策表,而不是只盯一个“内存够不够”的数字。
| 硬件路线 | 该怎么理解 | 实际含义 |
|---|---|---|
| 80GB 级服务器 GPU | 干净本地路线 | 适合认真测试或内部使用 gpt-oss-120b,留出权重、运行时和普通上下文余量。 |
>=60GB VRAM 或统一内存 | 受限门槛 | 部分受支持运行时可以加载,但上下文、batch、KV cache 和实现开销仍会吃掉余量。 |
| 24GB GPU + CPU/NVMe 卸载 | 实验路线 | 可以学习模型格式和离线流程,不应当按生产本地 120B 方案采购。 |
gpt-oss-20b、云 GPU 或托管访问 | 后备路线 | 当本地内存、速度或稳定性才是真约束时,往往更省时间。 |
如果计划依赖“总内存够大”、单条社区截图、或者和你实际运行时不一致的 benchmark,先暂停采购。GPT-OSS 120B 的问题不是只把模型装进机器,而是让它在你的上下文长度、batch、并发和响应速度目标下持续工作。
先选运行路线,再谈显存数字
GPT-OSS 120B 的显存答案必须先绑定运行路线。OpenAI 模型资料把 gpt-oss-120b列为 117B 参数、5.1B active 参数、长上下文窗口的开放权重模型,并把单张 80GB GPU 作为清晰的本地目标。这个事实适合拿来做采购或租卡时的保守起点,因为它把权重、推理框架、普通上下文和运行时开销放在同一块更宽松的内存池里。
但这不表示每个 80GB 设备、每个运行时、每个上下文长度都表现一样。也不表示 60GB、64GB、96GB、128GB 这些说法互相矛盾。它们通常在回答不同问题:能否加载、能否比较顺畅地推理、能否服务多人、能否跑长上下文、能否避免大量 CPU 或磁盘搬运。先把目标写成“单人短 prompt 实验”“内部评估”“多用户服务”或“本地私有助手”,再决定硬件。
如果只是想体验开放权重和本地隐私,gpt-oss-20b 很可能更合适。如果必须验证 120B 的能力,短租 H100/MI300X 级云卡通常比买一套边缘配置更稳。只有当 120B 的本地反复使用、数据驻留和吞吐目标都成立时,80GB 级本地硬件才开始像合理投入。
把路线放在前面还有一个好处:它让“能不能跑”和“值不值得这样跑”分开。前者是加载和 OOM 问题,后者是速度、成本、维护和可靠性问题。
为什么 80GB 和 60GB 可以同时成立
80GB 与 >=60GB 的差异来自问题边界。80GB 是干净硬件目标;>=60GB 是特定 MXFP4 路线和运行时支持下的加载门槛。OpenAI 的 Transformers、vLLM、Ollama 相关材料都把 120B 放在高内存或服务器级路径里,同时也说明某些量化路径可以把门槛压低到 60GB 左右。
受限门槛不等于舒适生产环境。模型权重之外还会有 tokenizer、运行时缓冲、allocator 预留、KV cache、上下文窗口、batch、并发和多 GPU 通信成本。短 prompt 能跑通,并不能证明 64k 或 128k 上下文下还能稳定;单用户能出 token,也不能证明多人同时请求时不会 OOM。
因此中文稿里最容易出错的说法是“120B 需要多少 RAM”。如果这里的 RAM 指系统内存,答案会误导;如果指显存,也要说明是否是单卡、统一内存、多卡、CPU 卸载或云 GPU。更稳的表达是:采购按 80GB GPU 级别思考,受限测试可看 60GB 路线,低于这个范围就先把任务降级为实验。
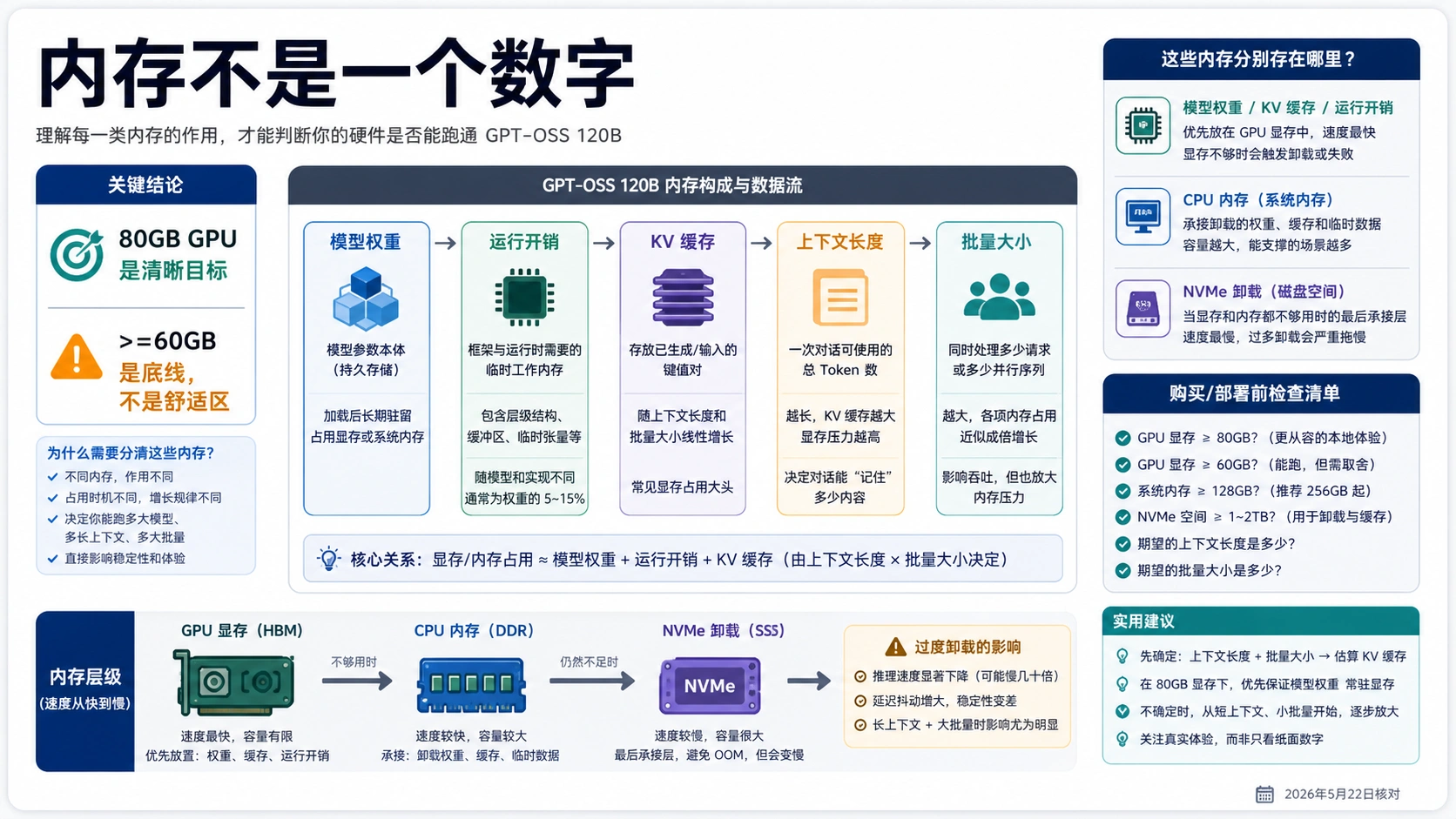
把 VRAM、统一内存、系统内存、磁盘和 KV cache 分开
同一个“内存”词会覆盖多种资源。VRAM 是 GPU 上真正承载权重和推理状态的高速内存;统一内存在某些本地设备或运行时里可以被模型使用,但速度和可用余量要按设备实测;系统内存能支撑 offload、进程、缓存和后台任务,却不能变成快速显存;NVMe 可以帮你把模型部分搬来搬去,但会把延迟问题暴露出来。
KV cache 是很多人漏掉的部分。上下文越长、同时请求越多,KV cache 和运行时状态就越能吃掉剩余空间。模型文件大约多大,只能说明下载和存储压力;运行时可能上采样部分操作、分配临时缓冲,或者因为 kernel 支持不完整而改变内存曲线。
购买机器前,要把每个资源池写在同一张表里。你的目标是单人本地聊天,还是 32k 文档分析,还是带工具调用的长上下文评估,还是给团队共享?这些目标的内存余量不一样。系统内存 128GB 加 24GB GPU 可能适合折腾卸载,但不能和一张 80GB 加速卡划等号。
| 内存词 | 对 gpt-oss-120b 的含义 | 硬件决策含义 |
|---|---|---|
| VRAM | GPU 上承载权重、运行时状态和部分 KV cache 的高速内存 | 干净单设备目标按 80GB 级别规划。 |
| 统一内存 | 某些设备共享给 CPU/GPU 的内存池 | 可按受限路线测试,但速度和余量要实测。 |
| 系统内存 | CPU 侧进程、offload、缓存和后台任务使用 | 能帮助实验,不等于快速显存。 |
| 磁盘/NVMe 卸载 | 把部分状态通过存储搬运 | 能加载不代表可交互。 |
| KV cache | 长上下文和并发请求使用的注意力状态内存 | 上下文越长,余量越需要保守。 |
| batch/并发 | 一次处理的 token 或请求量 | 服务多人时显存需求高于单人聊天。 |
这张拆分表比单个显存数字更接近真实决策,因为它强迫你说明瓶颈到底在显存、统一内存、系统内存、磁盘,还是上下文和并发。
不同运行时会改变内存预算
运行时会决定同一模型到底怎么占用内存。Transformers 路线适合直接 Python 实验,但硬件、kernel 和精度支持不够时,内存和速度都会变形。vLLM 更像服务端路线,max_model_len、batch token、tensor parallel、KV cache 策略会直接决定还能剩多少显存。Ollama 和桌面工具启动更容易,但“VRAM 或统一内存”的提示必须按工具实际支持理解。
多 GPU 不是自动解决方案。两张或三张 24GB 卡可能在某些社区方案里跑通,但它会引入 PCIe、通信、手动切分、驱动和运行时兼容问题。单张正确大小的 GPU 往往比多张边缘消费卡更少调试成本。云 GPU 则适合先验证 workload shape:你可以先用真实 prompt、上下文和并发跑一天,再决定是否买硬件。
还有一个容易被忽略的路线:托管访问。它不满足完全本地,但能把模型评估和基础设施归属拆开。需要上线服务时,先用托管或云 GPU 验证需求,再决定是否自托管,通常比先买卡后找用例更稳。
消费级显卡的停止线
24GB 显卡不要被写成“也能跑 120B”的采购结论。它可以是学习路线:下载权重、理解 MXFP4、测试 prompt、观察工具调用、看 CPU/NVMe 卸载怎么影响延迟。但只要 offload 成为主路径,任务就从“干净 GPU 推理”变成“受限实验”。
48GB 工作站卡比 24GB 更接近严肃测试,但仍低于干净 80GB 目标。两张 24GB 卡或三张 24GB 卡可能看起来显存总数够,但通信和分片是否可用要由运行时证明。Apple 统一内存机器也要以实测吞吐和热稳定为准,不能只看统一内存总量。
真正的停止线很简单:短 prompt 演示成功,不代表真实上下文成功;加载成功,不代表 tokens/sec 可用;单次回复成功,不代表团队共享可用。只要你的目标是稳定长上下文或多人服务,消费级路线就应该先被标为实验,而不是购买建议。
| 硬件情况 | 合理路线 | 停止线 |
|---|---|---|
| 单张 24GB NVIDIA 卡 | 卸载实验或 gpt-oss-20b | CPU/NVMe 搬运主导延迟时,不再称为生产级 120B。 |
| 两张 24GB 卡 | 高级实验或部分分片 | 运行时需要脆弱手动 placement 时暂停。 |
| 48GB 工作站 GPU | 严肃测试但仍低于干净目标 | 短 demo 成功而真实 prompt 失败时暂停。 |
| 高统一内存设备 | 本地测试路线 | 只看容量、不看吞吐和热稳定时暂停。 |
| CPU-only | 教育和离线检查 | 目标是交互式使用或多人服务时暂停。 |
后备路线不是失败,而是减少浪费。把 20B、云 GPU、托管访问写在同一张决策表里,可以防止读者把“我想本地跑”误当成“必须立刻买一套边缘硬件”。
购买或租卡前的验证清单
验证顺序应该从 workload 开始,而不是从论坛截图开始。先写下运行时、硬件资源池、上下文目标、batch 或并发、精度/量化路径、真实 prompt 集、遥测指标和失败点。每一步都要有可复现记录:峰值 VRAM、系统内存、swap、NVMe 读写、tokens/sec、首 token 延迟和 OOM 时的设置。
租卡时,用同一个环境跑你的真实上下文和并发,不要只看短 demo。采购时,要求机器在你需要的运行时上完成验证,而不是只证明“能加载”。如果目标只是私有本地助手,20B 路线可能更快、更安静、更便宜;如果目标是 120B 能力评估,云卡先行更合理;如果目标是产品交付,托管路线可能先解决稳定性。
最终答案不应该只有一行显存数字。它应该是一张路线决策:80GB 本地干净跑、60GB 受限测试、24GB 卸载实验、20B 本地后备、云 GPU 验证、托管服务交付。把路线说清楚,硬件决策才不会被单个数字牵着走。

| 步骤 | 要记录什么 | 为什么重要 |
|---|---|---|
| 1. 运行时 | Transformers、vLLM、Ollama、本地 app、多 GPU、offload、托管 | 同一模型在不同路线下内存表现不同。 |
| 2. 内存池 | VRAM、统一内存、系统内存、磁盘卸载 | “RAM”一个词会隐藏真正瓶颈。 |
| 3. 上下文 | 短聊天、32k、64k、128k 或实际上限 | KV cache 会随上下文增长。 |
| 4. 并发 | 单人、本地批测、多人服务 | 单请求成功不能证明服务负载。 |
| 5. 精度/量化 | MXFP4、BF16、运行时转换 | 内存数字依赖真实加载格式。 |
| 6. 真实 prompt | 工具调用、长文档、代码或短对话 | 玩具 prompt 会掩盖延迟和 OOM。 |
| 7. 遥测 | 峰值 VRAM、RAM、swap、tokens/sec、OOM 点 | 可复现记录比截图更可靠。 |
| 8. 后备 | 20B、云 GPU、托管或缩短上下文 | 先定逃生路线,再花钱。 |
验证完成后,答案可能是买 80GB、本地跑 20B、先租云卡,或者暂时不要自托管。只有真实 workload 让结论收敛,硬件数字才有意义。如果验证里出现 swap 增长、NVMe 读写持续偏高、first token 明显变慢、长上下文掉速、并发时 OOM 或 tokens/sec 不稳定,就不要把这套配置写成“已经够用”。把失败点写进采购备注,先缩短 context、降低 batch、换 20B、租更大 GPU,或者改走托管路线。这样的记录比单次成功截图更能保护预算。对中文读者尤其要把“能加载”“能聊天”“能长文档”“能服务团队”拆开记录:前三分钟的成功不等于一周后的稳定。预算表里也应写明谁负责维护驱动、runtime 升级、模型文件迁移和故障回滚,否则硬件费用只是第一笔成本。若团队没有维护人,托管或云端短租往往更稳,也更容易复盘。
常见问题
GPT-OSS 120B 需要多少显存?
按干净本地路线规划,使用 80GB GPU 级别作为安全目标。>=60GB 可以是部分 MXFP4 路线的受限门槛,但仍要受上下文、batch、KV cache 和运行时开销影响。
24GB 显卡能运行 GPT-OSS 120B 吗?
可以把 24GB 看成 offload 实验路线,不应当当成干净部署。它适合学习流程、验证 prompt 和观察延迟,不适合长上下文或多人服务。
系统内存够大能替代显存吗?
不能。系统内存能帮助 CPU/NVMe 卸载和缓存,但速度、延迟和可靠性都不同于 GPU 显存。一旦模型状态频繁经过 CPU 或磁盘,路线性质就变了。
为什么官方和社区会同时出现 80GB、60GB、64GB、96GB?
这些数字通常来自不同问题:干净单 GPU 目标、受限加载门槛、统一内存/CPU 卸载实验、或多人服务余量。必须把数字绑定到运行时、上下文和并发。
GPT-OSS 20B 的硬件要求一样吗?
不一样。gpt-oss-20b 是更小的本地路线,官方资料把它放在 16GB 级别。内存紧张或只需要本地助手时,20B 往往更合理。
128k 上下文是不是任何配置都能用?
不是。长上下文会增加 KV cache 压力。硬件规划应按实际会用的上下文长度、batch 和并发,而不是只按模型参考页上的理论窗口。
应该买 H100 级显卡、租云 GPU,还是走托管?
反复、长期、本地数据驻留需求明确时才考虑购买。还在验证 workload 时先租云 GPU。上线稳定性比基础设施所有权更重要时,托管路线更适合先行。
Reddit 或论坛的低显存成功案例有用吗?
有用,但只能当实验线索。需求边界仍应以官方模型和运行时资料为主,社区经验用来决定要测试什么、避免什么,而不是直接当采购依据。