截至 2026 年 5 月 7 日,大多数 Claude 任务应该先从 Sonnet 4.6 开始,而不是一上来就用 Opus 4.7。Sonnet 是速度、成本和规模更平衡的默认路线;Opus 是给高风险推理、复杂架构、长链路 agent、重文档综合,或 Sonnet 已经反复卡在同一验收标准上的任务准备的升级路线。
| 如果你的任务是这样 | 先试什么 | 什么时候升级 |
|---|---|---|
| 日常写代码、资料整理、内容草稿、办公分析、浏览器或电脑操作流程 | Sonnet 4.6 | 输出需要反复人工修补,或连续错过同一个验收点。 |
| 高调用量 API 生产任务 | Sonnet 4.6 | 失败、重试和人工复核的成本已经高过 Opus 溢价。 |
| 架构判断、根因排查、多文件复杂推理 | Opus 4.7 测试通道 | 如果 Opus 对真实结果没有明显提升,保留 Sonnet 作为基线。 |
| 长时间 agent 或多步骤工作流 | Sonnet 基线加 Opus 对照 | Opus 能明显减少绕路、丢计划或半途脆断。 |
| 机械抽取、简单分类、格式转换 | Haiku 4.5 旁路 | 先升到 Sonnet,不要直接跳到 Opus。 |
公开价格只是一层成本信号。Anthropic 当前文档中,Sonnet 4.6 的 API 价格是每百万输入 token 3 美元、每百万输出 token 15 美元;Opus 4.7 是每百万输入 token 5 美元、每百万输出 token 25 美元。真实账单还会被输出长度、缓存命中、批处理、thinking 设置、重试次数,以及 Opus 4.7 tokenizer 对同一固定文本可能计出更多 token 的说明影响。
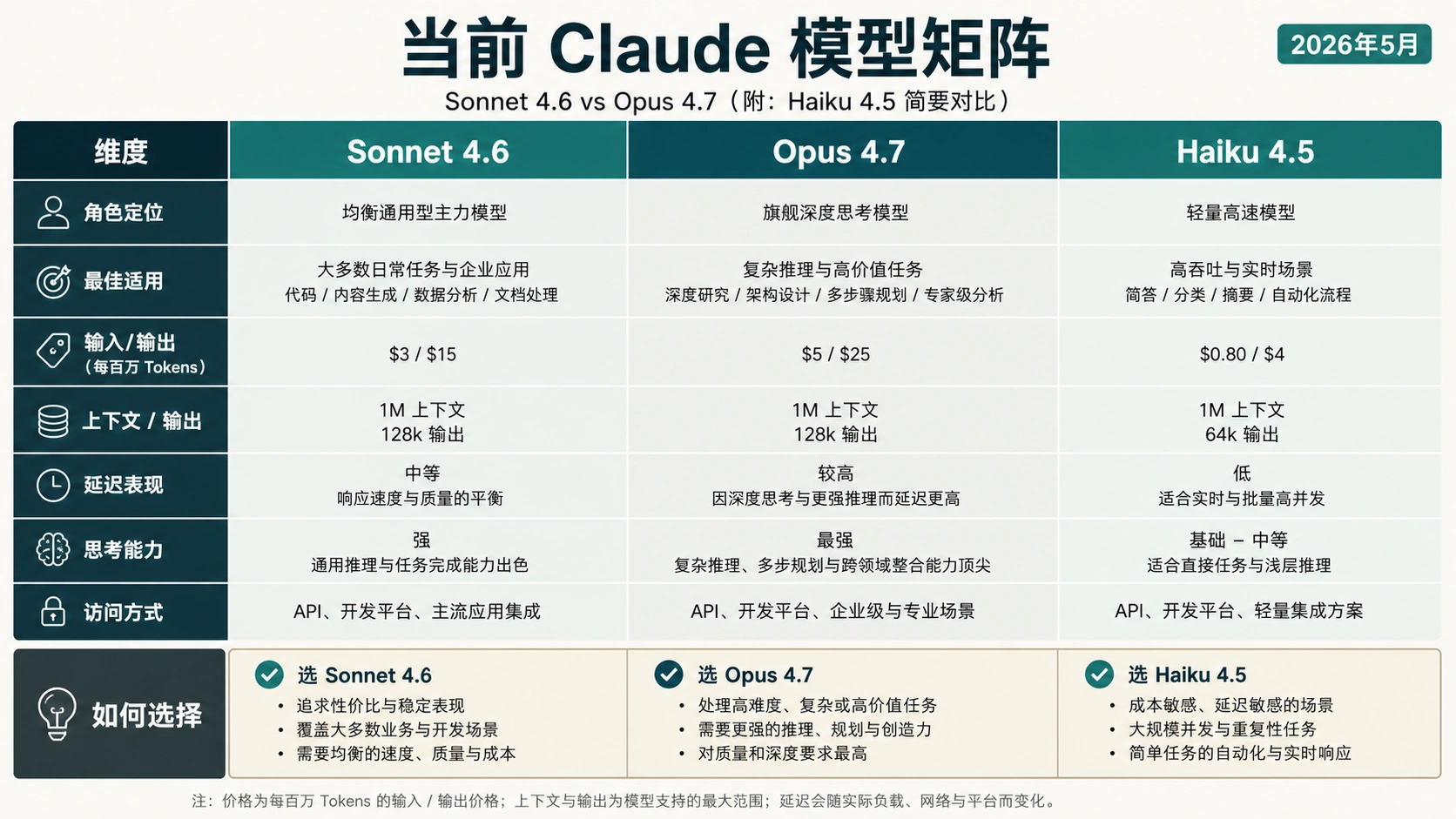
当前比较应该看 Opus 4.7 和 Sonnet 4.6
很多中文结果还停留在 Claude 4、Opus 4.5、Opus 4.6 或 Sonnet 4.5 的说法上,这会让读者误以为问题只是“哪个更强”。当前要解决的是另一个问题:你要不要把某个真实工作负载从 Sonnet 4.6 升到 Opus 4.7。
Anthropic 当前模型概览把 Opus 4.7、Sonnet 4.6 和 Haiku 4.5 放在主要模型层级里。Opus 4.7 被定位给专业软件工程、复杂推理、agentic 工作流和高风险企业任务。Sonnet 4.6 则是平衡型模型,面向日常使用、规模化生产、编码、agent、浏览器和电脑操作、长上下文推理以及成本敏感场景。
| 当前官方行 | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| 实际角色 | 大多数任务的默认模型 | 最难任务的升级模型 |
| API 价格,2026-05-07 核对 | $3 输入 / $15 输出 每百万 token | $5 输入 / $25 输出 每百万 token |
| 延迟层级 | 快 | 中等 |
| 上下文窗口 | 1M | 1M |
| 最大输出 | 64k | 128k |
| thinking 支持 | extended thinking 与 adaptive thinking | adaptive thinking |
| 第一用途 | 日常工作、编码循环、规模化生产 | 深推理、agent 编码、高风险判断 |
Haiku 4.5 只需要作为旁路出现。它适合简单抽取、路由、格式化或低风险批量任务,但当前选择的核心不是三模型百科,而是 Sonnet 与 Opus 的默认路线和升级边界。
什么时候 Sonnet 4.6 应该是默认选择
Sonnet 的优势不是“便宜”两个字,而是足够强、响应快、成本更容易控制。日常编码、PR 辅助、文档改写、资料整理、结构化摘要、客服分流、表格分析、浏览器自动化和多数 API 生产路径,都应该先给 Sonnet 一个公平的基线。
如果一个任务有清晰指令、可自动验证的输出、低失败代价和明确 schema,那么用 Opus 起步经常只是把预算花在模型标签上。生产系统里,真正重要的是可接受输出成本:一次 Opus 的答案未必比 Sonnet 加测试、重试、校验和第二遍复核更划算。
优先用 Sonnet 的情况包括:
- 输出可以被测试、schema、规则或人工快速核查;
- 调用频率高,单次 token 成本会放大;
- 工作流需要快速迭代,而不是最长思考;
- prompt 已经清楚,验收标准也能写出来;
- 模型主要是在执行流程,不是在发明策略;
- 失败可以通过 retry、review、lint、单元测试或人工二审拦住。
对 Claude app 用户来说,Sonnet 通常也是自然入口,因为它承担了平衡路线。对 API 用户来说,它更应该是第一个生产候选,因为官方价格行更低,也更适合高频调用和稳定吞吐。
什么时候 Opus 4.7 值得测试
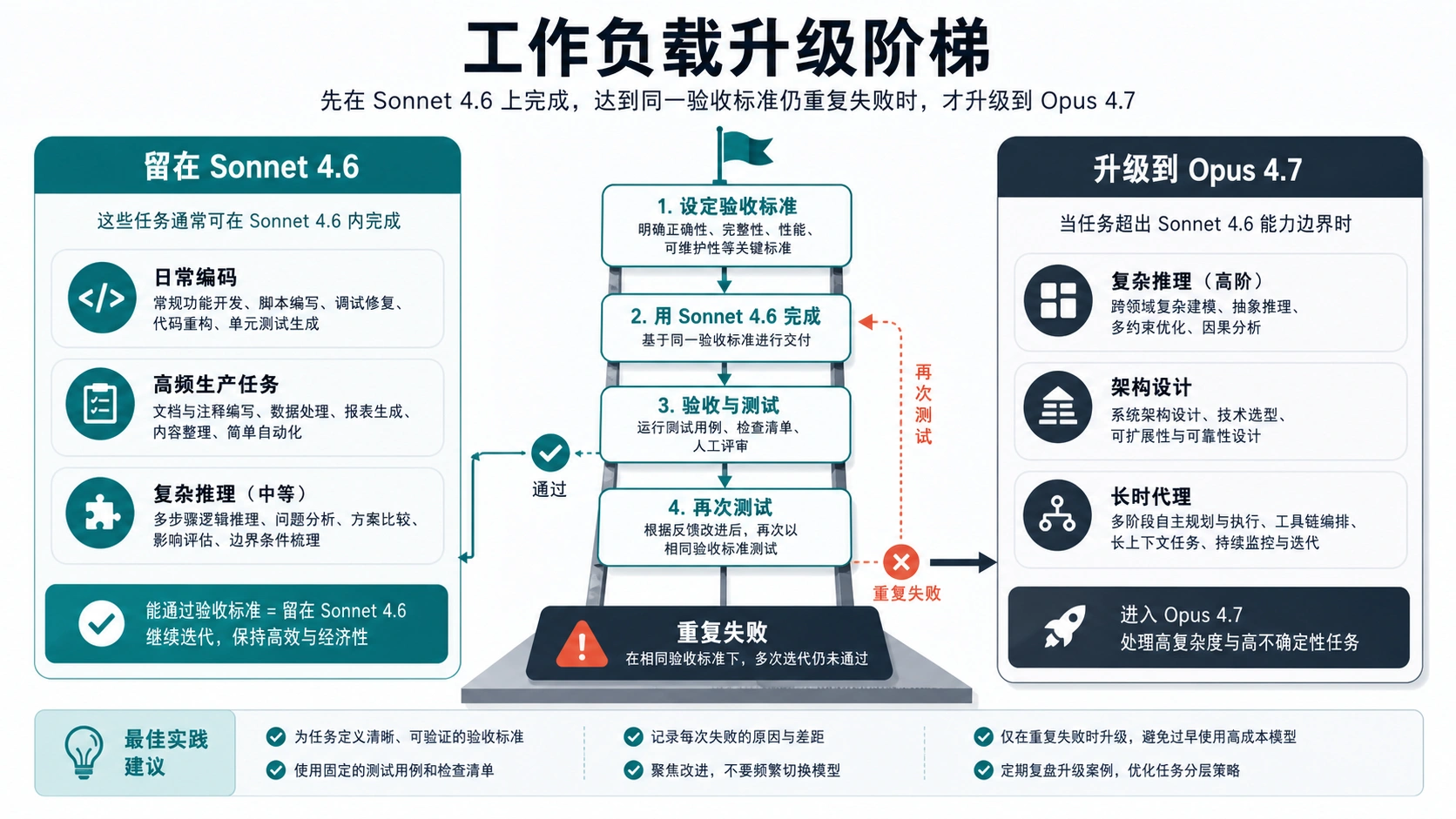
Opus 的价值出现在失败成本高、上下文脏、判断空间大,或者便宜重试不能解决问题的时候。它不只是“更贵的模型”,而是给需要更深推理、更稳计划、更少绕路的任务准备的升级通道。
可以开 Opus 测试通道的情况包括:
- Sonnet 清理 prompt 后仍反复漏掉同一验收标准;
- 任务横跨多个文件、系统、约束或团队决策;
- 模型要读很多文档,并保留细节、口径和例外;
- 长时间 agent 经常丢计划、循环、提前收工或走脆弱捷径;
- 结果会影响架构、法律、财务、合规或企业级决策;
- 根因排查中,一个看似合理的捷径会带来更大损失;
- 人工 review 才是最大成本,而更好的第一稿能明显省人力。
Opus 不是每个 prompt 的道德升级。如果它只把答案写得更漂亮,却没有减少错误、缩短复核、解决 Sonnet 无法稳定完成的步骤,就应该继续用 Sonnet。只有当它真的避免坏决策、发现隐藏依赖,或把长链路流程跑通时,溢价才有理由存在。
成本差异不只是价目表
Anthropic 的价格页是 API 单价的事实源,但价目表不是完整预算。Sonnet 4.6 的 $3/$15 和 Opus 4.7 的 $5/$25 只是基础差距。真实成本会因为输出长度、上下文重复、缓存写入和命中、batch 是否适用、thinking 强度、工具 schema、失败重试、人工复核时间而变化。
当前价格页还说明,Opus 4.7 使用新的 tokenizer,同一固定文本在某些内容上可能多计最多 35% token。这不等于每一次 Opus 调用都会额外贵 35%,但它提醒你不能拿上个月 Sonnet 的 token 数量直接乘 Opus 单价来做迁移预算。
| 成本层 | 为什么会改变选择 |
|---|---|
| 输入与输出基础单价 | Opus 每 token 更贵。 |
| 输出长度 | 更深的答案可能更长,除非你限制输出预算。 |
| prompt caching | 缓存命中能降重复输入成本,但写入和策略也要算。 |
| batch | 可异步处理的任务可能用 batch 降成本。 |
| thinking | 可能提高难题质量,也可能增加成本和延迟。 |
| tokenizer | Opus 4.7 对同一文本的 token 计数可能不同。 |
| 人工复核 | 更贵模型若减少返工,反而可能降低总成本。 |
所以正确问题不是“哪个模型单价低”,而是“哪个模型在这个工作负载上给出最低的可接受输出成本”。
换默认模型前,先用同一工作流测试

不要因为模型名字听起来更强就切换默认模型。公平测试必须尽量固定 prompt、上下文、输出预算、工具和验收标准。否则你测到的可能是 prompt 改写效果,而不是模型差异。
一个小型测试计划可以这样做:
- 从真实工作流里选三到五个代表性任务。
- 去掉敏感数据,或只在批准环境里运行。
- 用当前 prompt 和预算跑 Sonnet 4.6。
- 用同样 prompt、上下文和预算跑 Opus 4.7。
- 用同一组验收标准评分。
- 记录 token 成本、延迟、重试次数、人工复核时间和最终可接受结果。
- 只把 Opus 提升明显、且能抵消成本的任务切过去。
这个测试也能防止反向错误:一直用 Sonnet 省单价,却在重试、返工、人工检查和失败结果上花更多钱。多数团队更适合混合策略:普通流量走 Sonnet,硬任务或失败切片走 Opus。
落到团队实践时,可以把模型选择写成一条显式路由规则,而不是依靠个人感觉临时切换。默认队列先走 Sonnet,并且保留输入、输出、验收失败点和人工修改记录;只有当失败类型符合“同一标准反复失败”“跨系统判断不足”“人工 review 成本过高”这些条件时,才把同一任务复制到 Opus 测试通道。这样做的好处是,Opus 的使用理由会留在日志里,后续预算讨论也能围绕真实任务,而不是围绕某个模型在社交媒体上的口碑。
还要把“更好”拆成可测指标。编码任务可以看测试是否通过、修改是否局部、是否引入隐藏依赖;文档任务可以看事实是否完整、例外是否保留、结论是否能直接执行;agent 任务可以看是否保持计划、是否减少无效工具调用、是否在同样预算内完成。只有这些指标改善,Opus 才算真的更好。否则它只是更贵、更长、看起来更有把握。
对 API 生产来说,最稳的设计通常不是单一默认模型,而是分层路由。低风险、高频、易验证的任务留在 Sonnet;简单机械任务可以下沉到 Haiku;高风险、长上下文、反复失败的切片才进入 Opus。这个分层也能让团队在模型升级时更容易回滚:如果 Opus 后续价格、限制或 tokenizer 行为变化,只需要调整升级通道,不必重写整个系统。
最后要把样本保留下来。每次把任务从 Sonnet 升到 Opus,都应该记录原始输入、固定后的 prompt、两个模型的输出、验收结果和人工修改点。几周以后,团队可以看到哪些任务真的因为 Opus 变好了,哪些只是因为当时 prompt 不够清楚。这个复盘比单次主观感受可靠得多。
Claude app、API 和 Claude Code 不是同一个问题
Claude app 里能不能选某个模型、API 能不能调用某个模型、Claude Code 当前会走哪个模型,是三个相关但不同的表面。app 用户关心订阅、消息额度和产品入口;API 用户关心 model ID、token 单价、缓存、batch、速率限制和集成行为;Claude Code 用户还要区分订阅登录、API key、本地配置和项目工作流。
边界要保持清楚:
- 如果问题是要不要买 Pro、Max 或走 API 计费,那是订阅与计费问题。
- 如果问题是 Claude Code 能不能免费用、能不能走 Pro,那是访问路线问题。
- 如果问题是某个任务该跑哪个模型,这里才是 Sonnet、Opus、Haiku 或测试通道的选择。
买到访问权并不等于已经解决模型路由。Pro 用户也可能大多数任务继续用 Sonnet;API 用户即使能调 Opus,也可能只把失败切片升级;Claude Code 用户也应该先确认当前会话走的是订阅还是 API key,再谈成本。
常见问题
Opus 一定比 Sonnet 更好吗?
Opus 4.7 是更强的升级模型,但不是所有任务的默认答案。Sonnet 4.6 对速度、成本和规模更友好,通常应该先试。只有当任务难度或失败成本足以覆盖溢价时,Opus 才值得测试。
我应该先用 Opus 还是 Sonnet?
先用 Sonnet 4.6。任务高风险、长链路、架构复杂、文档很重,或者 Sonnet 清理 prompt 后仍过不了同一验收标准时,再开 Opus 4.7 对照。
Opus 比 Sonnet 贵多少?
截至 2026 年 5 月 7 日,官方 API 行列出 Sonnet 4.6 为每百万输入 3 美元、每百万输出 15 美元;Opus 4.7 为每百万输入 5 美元、每百万输出 25 美元。真实成本还要看输出长度、缓存、batch、thinking、重试和 tokenizer 行为。
Sonnet 写代码够用吗?
多数编码循环、PR 检查、重构、测试和日常 agent 工作,Sonnet 4.6 已经够用。架构判断、跨模块根因排查、复杂约束推理或反复失败的编码任务,再用 Opus 对照。
Claude Code 用的是 Opus 还是 Sonnet?
Claude Code 的模型行为可能受产品、计划、设置和路由影响。把 Claude Code 当作工作负载表面,而不是 Opus 与 Sonnet 的替代答案。普通编码先测 Sonnet,难题再测 Opus。
Haiku 放在哪里?
Haiku 4.5 是速度和成本旁路,适合抽取、路由、格式化和低风险批量处理。先从 Haiku 升到 Sonnet,再决定要不要用 Opus。
旧的 Opus 4.5 或 Sonnet 4.5 建议还能看吗?
可以当历史参考,但不要当当前选择依据。当前模型路由要按 Opus 4.7 和 Sonnet 4.6 的官方事实重新判断。
团队什么时候该同时使用两个模型?
当工作负载有便宜常规路径和困难例外路径时,就该同时使用。Sonnet 处理默认流量,Opus 处理失败切片、高风险推理和人工复核成本最高的任务。