Claude Code 使用限制完全指南:5小时窗口机制与Rate Limit解决方案 [2026]
深度解析Claude Code的5小时滚动窗口机制、API Tier限制、订阅计划对比,提供完整的rate limit错误解决方案和优化策略。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

当你正在用Claude Code专注地解决一个复杂的编程问题时,突然收到一条令人沮丧的消息:"You've reached your usage limit"。这种体验几乎每个Claude Code用户都经历过。根据Anthropic官方数据,Claude Code采用独特的5小时滚动窗口机制来管理使用配额,而非传统的固定时间重置方式。这意味着你的可用额度是动态变化的,理解这一机制对于高效使用Claude Code至关重要。
自2025年8月Anthropic实施新的周限制系统以来,用户对使用限制的困惑明显增加。不同的订阅计划(Free、Pro、Max)有着截然不同的限制,而通过API访问时还涉及Tier 1到Tier 4的分级系统。本指南将深入解析所有这些限制机制,提供具体的解决方案和优化策略,帮助你在限制内最大化Claude Code的使用效率。
理解Claude Code使用限制的本质
Claude Code的使用限制本质上是一种资源管理机制,旨在确保所有用户都能获得稳定、可靠的服务体验。与传统的API调用次数限制不同,Claude Code的限制系统更加复杂,它综合考虑了计算资源消耗、模型复杂度和用户公平性等多个因素。
根据Anthropic官方文档的说明,限制系统主要分为两大类:Claude Code订阅限制和API访问限制。前者针对使用Claude Code客户端(如VS Code扩展、命令行工具)的用户,采用基于时间窗口的配额系统;后者针对直接调用Anthropic API的开发者,采用基于请求频率和token数量的分级限制。
两种限制机制的核心区别在于计量方式。Claude Code订阅限制以"使用时长"或"提示次数"为单位,而API限制则精确到每分钟的请求数(RPM)、输入token数(ITPM)和输出token数(OTPM)。这种差异直接影响了用户应该采取的优化策略。
理解这些限制存在的原因同样重要。Anthropic的大语言模型运行需要大量的GPU计算资源,而这些资源是有限的。通过合理的限制机制,Anthropic能够在保证服务质量的前提下,为尽可能多的用户提供服务。从用户角度来看,这意味着在高峰时段可能会更容易触发限制,而在低峰时段则有更大的使用空间。
5小时滚动窗口机制详解
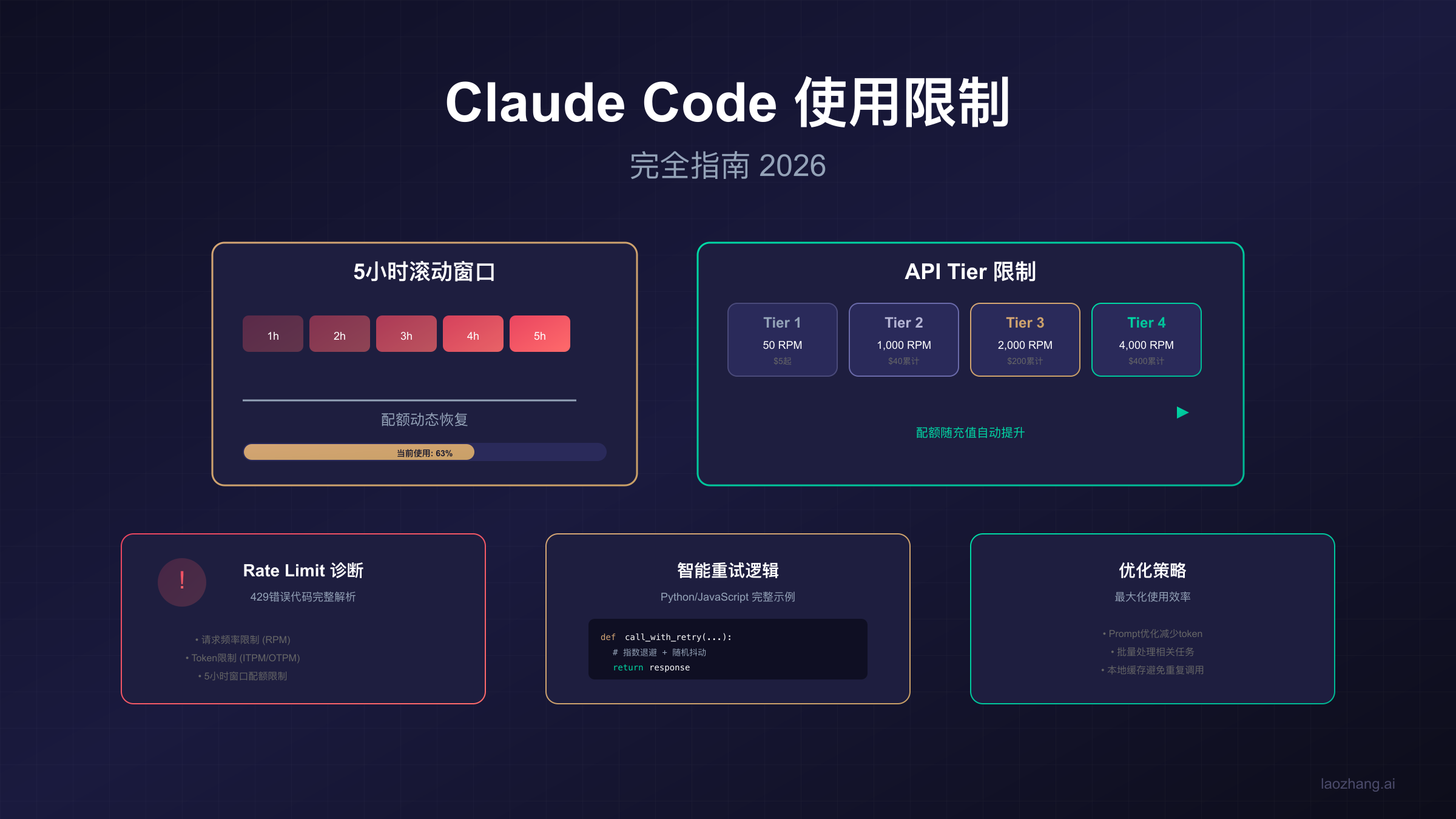
Claude Code最独特的设计之一就是其5小时滚动窗口机制。与传统的"每日重置"或"每月重置"不同,Claude Code的配额在任意5小时的时间段内进行计算和恢复。这种机制既带来了灵活性,也增加了理解的复杂度。
滚动窗口的工作原理可以这样理解:系统会持续追踪你过去5小时内的所有使用记录。当你发送一个新请求时,系统会检查从当前时刻往前推5小时内的累计使用量。如果这个累计量超过了你的计划配额,请求就会被拒绝。关键在于,随着时间推移,5小时前的使用记录会自动"滑出"计算窗口,从而释放出新的可用配额。
举个具体例子:假设你在上午9点使用了大量配额,到了下午2点(正好5小时后),这部分使用量就会从计算窗口中移除。这意味着你不需要等到"明天"或"下个月"才能恢复配额,而是可以在几小时后就获得新的使用空间。
这种机制与固定重置时间相比有明显优势。固定重置(如每天凌晨重置)会导致"月初用完、月底干等"的尴尬情况,而滚动窗口则让配额的使用更加平滑和可预测。但它也带来了一个挑战:你需要记住自己何时使用了大量配额,以便预估何时能够恢复。
在实际使用中,滚动窗口机制的影响体现在几个方面。首先,突发使用后的恢复时间更短:即使你在短时间内耗尽了配额,最多只需等待5小时就能开始恢复。其次,使用策略需要更精细:与其在一天的某个时段集中使用,不如将使用分散到一天的不同时段。最后,监控变得更加重要:由于配额是动态变化的,实时了解自己的剩余配额可以帮助更好地规划使用。
不同订阅计划的限制对比
Anthropic为Claude Code提供了多个订阅计划,每个计划的限制差异显著。了解这些差异对于选择合适的计划和优化使用策略至关重要。
| 计划 | 月费 | 5小时内提示次数 | 可用模型 | 周限制 | 适用场景 |
|---|---|---|---|---|---|
| Free | $0 | 2-5次 | Sonnet 4 | ~10小时 | 轻度体验用户 |
| Pro | $20 | 10-40次 | Sonnet 4 | 40-80小时 | 日常开发者 |
| Max 5× | $100 | 50-200次 | Sonnet 4 + Opus 4 | 200-400小时 | 重度用户 |
| Max 20× | $200 | 200-800次 | Sonnet 4 + Opus 4 | 800+小时 | 专业团队 |
Free计划的限制最为严格,每5小时仅允许2-5次提示,且只能使用Sonnet 4模型。这个计划主要面向想要体验Claude Code功能的新用户,不适合作为日常开发工具使用。每周约10小时的总使用时长意味着平均每天只有不到1.5小时的使用时间。
Pro计划是大多数个人开发者的首选。每月$20的价格提供了10-40次/5小时的提示配额,周限制在40-80小时之间。这个范围的波动主要取决于使用模式——如果你的提示通常较短且简单,可能接近上限;如果经常处理复杂的代码分析任务,则可能接近下限。如果你对Claude AI的免费使用方案还不太了解,建议先阅读相关指南。
Max计划分为5×和20×两个档位,主要区别在于配额倍数和价格。Max计划最大的优势是可以使用Opus 4模型——这是Anthropic目前最强大的模型。但需要特别注意的是,使用Opus 4会消耗约5倍于Sonnet 4的配额。这意味着如果你在Max 5×计划下全程使用Opus 4,实际的提示次数会降低到接近Pro计划的水平。
选择计划时需要考虑几个关键因素:首先是使用频率——如果你每天都需要使用Claude Code数小时,Pro计划可能不够用;其次是模型需求——如果你的任务必须使用Opus 4才能获得满意结果,则只能选择Max计划;最后是成本效益——Max 20×计划虽然价格是Pro的10倍,但配额提升远超10倍,对于重度用户来说性价比反而更高。
API Tier限制完整解析
除了Claude Code订阅限制外,通过API直接访问Claude模型还涉及另一套限制系统——Tier分级限制。这套系统基于用户的充值金额自动升级,提供逐渐增加的请求配额。
| Tier | RPM (请求/分钟) | ITPM (输入token/分钟) | OTPM (输出token/分钟) | 升级条件 |
|---|---|---|---|---|
| Tier 1 | 50 | 30,000 | 8,000 | 充值$5 |
| Tier 2 | 1,000 | 450,000 | 90,000 | 累计$40 |
| Tier 3 | 2,000 | 800,000 | 160,000 | 累计$200 |
| Tier 4 | 4,000 | 2,000,000 | 400,000 | 累计$400 |
Tier 1是所有新用户的起点,仅需充值$5即可激活。这个级别的限制相当严格:每分钟50次请求、30,000输入token和8,000输出token。对于开发测试来说基本够用,但无法支撑任何生产级应用。
Tier 2将所有限制提升了约15-20倍,是大多数小型项目的理想选择。累计充值$40即可自动升级,这意味着即使是$5/次地慢慢充值,只要总额达到$40就会自动解锁。每分钟1,000次请求足以支撑中等流量的应用。
Tier 3和Tier 4面向有较大流量需求的应用。Tier 4的限制(每分钟4,000请求、200万输入token)已经能够支撑相当规模的商业应用。但需要注意的是,这些限制是针对账户级别的,而非单个请求或单个应用。
关于不同模型的限制差异,需要特别说明。上表中的数据主要针对Claude Sonnet 4.x系列。Opus 4模型的限制通常更低——在Tier 1级别,Opus 4的RPM限制只有10,ITPM和OTPM也相应降低。这是因为Opus 4需要更多的计算资源,Anthropic需要通过更严格的限制来平衡资源分配。
升级Tier的策略相对简单:只需要持续充值即可。系统会自动追踪你的累计充值金额,一旦达到相应阈值就会立即升级。值得注意的是,这个累计金额是终身累计的,不会因为时间流逝而重置。

诊断你遇到的限制类型
当Claude Code返回错误时,准确判断你遇到的是哪种限制类型是解决问题的第一步。不同类型的限制需要不同的应对策略。
最常见的错误信息是"You've reached your usage limit"或"Rate limit exceeded"。虽然这两个错误看起来相似,但它们指向不同的限制机制。前者通常指Claude Code订阅配额耗尽,后者则指API请求频率超限。
HTTP状态码是判断限制类型的重要依据。429 Too Many Requests是最常见的限制错误码,但其含义需要结合错误信息具体分析:
| 错误类型 | HTTP码 | 错误信息关键词 | 含义 |
|---|---|---|---|
| 请求频率限制 | 429 | "rate_limit_exceeded" | RPM超限 |
| Token限制 | 429 | "token_limit_exceeded" | ITPM/OTPM超限 |
| 订阅配额限制 | 429 | "usage_limit_reached" | 5小时窗口配额耗尽 |
| 周限制 | 429 | "weekly_limit_reached" | 周配额耗尽 |
| 服务过载 | 529 | "overloaded" | 系统临时过载 |
查看剩余配额的方法因使用方式而异。如果你使用Claude Code客户端,通常可以在设置或状态栏中看到当前的使用情况。对于API用户,可以通过检查响应头中的x-ratelimit-remaining字段来了解剩余配额。
如果你之前遇到过Claude用户配额超限的问题,可能对这些错误信息已经比较熟悉。但需要注意的是,Claude Code的限制机制与网页版Claude有所不同,解决方案也需要相应调整。
区分不同限制类型的关键在于观察错误发生的模式。如果错误在短时间内反复出现(如几秒钟内连续触发),很可能是请求频率限制;如果错误在使用一段时间后才出现,且等待几小时后恢复,则很可能是5小时窗口配额限制;如果错误持续整整一周,那就是触发了周限制。
即时解决方案(5分钟内)
当你遇到rate limit错误时,以下几个即时解决方案可以帮助你快速恢复工作。
方案一:等待窗口滚动。如果你触发的是5小时滚动窗口限制,最简单的方法就是等待。由于是滚动窗口机制,你不需要等待整整5小时。回想一下你最早的大量使用是在什么时候,从那个时间点往后推5小时,配额就会开始恢复。通常等待30-60分钟就能获得足够的配额继续工作。
方案二:切换到不同模型。如果你正在使用Opus 4模型,切换到Sonnet 4可以大幅减少配额消耗。由于Opus 4消耗约5倍资源,切换模型相当于将你的可用配额提升5倍。对于大多数编程任务,Sonnet 4已经足够胜任。
方案三:减少请求复杂度。长提示和复杂任务会消耗更多配额。尝试将大任务拆分成小任务,或者精简你的提示内容。例如,与其让Claude Code分析整个项目,不如只分析当前正在处理的文件。
方案四:添加请求延迟。如果你在使用脚本或自动化工具调用Claude API,添加适当的延迟可以避免触发请求频率限制。以下是一个简单的Python示例:
hljs pythonimport time
import anthropic
client = anthropic.Anthropic()
def call_claude_with_delay(prompt, delay_seconds=2):
"""带延迟的Claude API调用"""
time.sleep(delay_seconds) # 请求前等待
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
# 批量处理时使用
prompts = ["任务1", "任务2", "任务3"]
for prompt in prompts:
result = call_claude_with_delay(prompt)
print(result)
这个简单的延迟机制可以有效避免短时间内发送过多请求,但它不够智能——无论是否真的触发了限制,都会等待固定时间。下一节我们将介绍更高级的智能重试逻辑。
实现智能重试逻辑
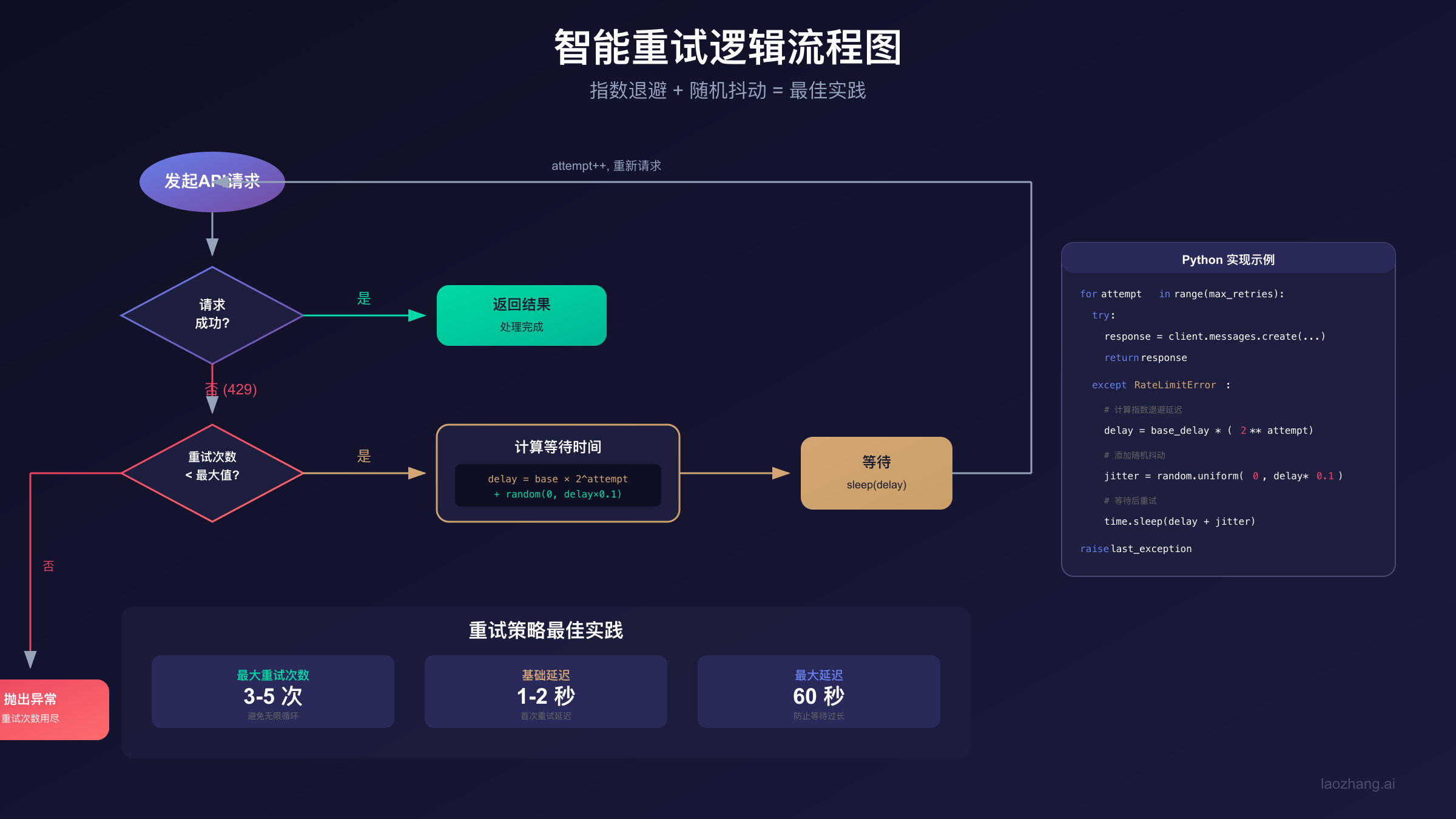
对于需要可靠性的生产环境,实现智能的指数退避重试逻辑是最佳实践。这种机制可以在遇到rate limit时自动等待并重试,同时避免无限循环和资源浪费。
指数退避的核心思想是:每次重试失败后,等待时间翻倍。例如,第一次重试等待1秒,第二次等待2秒,第三次等待4秒,以此类推。这种策略既给了服务器恢复的时间,又避免了频繁重试造成的额外负担。
以下是一个完整的Python实现示例:
hljs pythonimport time
import random
import anthropic
from anthropic import RateLimitError, APIError
def call_claude_with_retry(
client: anthropic.Anthropic,
prompt: str,
max_retries: int = 5,
base_delay: float = 1.0,
max_delay: float = 60.0
) -> str:
"""
带指数退避重试的Claude API调用
Args:
client: Anthropic客户端实例
prompt: 用户提示
max_retries: 最大重试次数
base_delay: 基础延迟时间(秒)
max_delay: 最大延迟时间(秒)
Returns:
Claude的响应文本
"""
last_exception = None
for attempt in range(max_retries + 1):
try:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
except RateLimitError as e:
last_exception = e
if attempt == max_retries:
break
# 计算延迟时间:指数退避 + 随机抖动
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1) # 10%抖动
wait_time = delay + jitter
print(f"遇到rate limit,等待{wait_time:.1f}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(wait_time)
except APIError as e:
# 其他API错误,根据情况决定是否重试
if e.status_code >= 500: # 服务器错误,可重试
last_exception = e
if attempt < max_retries:
time.sleep(base_delay)
continue
raise # 客户端错误,直接抛出
raise last_exception # 重试次数用尽,抛出最后的异常
# 使用示例
client = anthropic.Anthropic()
try:
result = call_claude_with_retry(client, "解释Python装饰器的工作原理")
print(result)
except RateLimitError:
print("重试次数用尽,请稍后再试")
对于JavaScript/TypeScript用户,以下是等效的实现:
hljs typescriptimport Anthropic from '@anthropic-ai/sdk';
async function callClaudeWithRetry(
client: Anthropic,
prompt: string,
maxRetries: number = 5,
baseDelay: number = 1000,
maxDelay: number = 60000
): Promise<string> {
let lastError: Error | null = null;
for (let attempt = 0; attempt <= maxRetries; attempt++) {
try {
const response = await client.messages.create({
model: 'claude-sonnet-4-20250514',
max_tokens: 1024,
messages: [{ role: 'user', content: prompt }]
});
return response.content[0].type === 'text'
? response.content[0].text
: '';
} catch (error: any) {
lastError = error;
if (error.status === 429) { // Rate limit error
if (attempt === maxRetries) break;
const delay = Math.min(baseDelay * Math.pow(2, attempt), maxDelay);
const jitter = Math.random() * delay * 0.1;
const waitTime = delay + jitter;
console.log(`遇到rate limit,等待${(waitTime/1000).toFixed(1)}秒后重试`);
await new Promise(resolve => setTimeout(resolve, waitTime));
} else if (error.status >= 500) { // Server error
if (attempt < maxRetries) {
await new Promise(resolve => setTimeout(resolve, baseDelay));
continue;
}
} else {
throw error; // Client error
}
}
}
throw lastError;
}
实现智能重试时需要注意几个最佳实践:首先,设置合理的最大重试次数,通常3-5次足够;其次,添加随机抖动(jitter),避免多个客户端同时重试造成"惊群效应";最后,区分不同类型的错误,只对可重试的错误(如rate limit、服务器过载)进行重试。
优化使用效率的策略
除了被动地处理rate limit错误,主动优化使用效率可以从根本上减少触发限制的频率。以下是几个经过验证的优化策略。
策略一:Prompt优化减少token消耗。Claude API按token计费和计算配额,因此减少不必要的token可以显著提升效率。具体做法包括:移除冗余的上下文信息、使用简洁明了的指令、避免重复说明相同的要求。例如,与其说"请帮我写一个Python函数,这个函数需要接收一个列表作为参数,然后对列表中的元素进行排序,最后返回排序后的结果",不如简化为"写一个Python函数,对列表排序并返回"。
策略二:合理使用系统提示(System Prompt)。System Prompt会在每次请求中重复发送,过长的System Prompt会快速消耗token配额。建议将通用的指令放在System Prompt中,将具体任务放在用户消息中。同时,考虑使用Prompt Caching功能——这是Anthropic提供的优化特性,可以缓存重复的提示内容,减少token消耗和API调用延迟。
策略三:批量处理相关任务。如果你有多个相关的小任务,将它们合并成一个较大的请求通常比多次小请求更高效。这不仅减少了请求次数(避免RPM限制),还减少了重复上下文的开销。例如,与其分10次请求让Claude分析10个函数,不如一次请求分析所有10个函数。
策略四:实施本地缓存。对于可能重复的查询,在本地实现缓存可以完全避免重复调用API。以下是一个简单的缓存实现思路:
hljs pythonimport hashlib
import json
from functools import lru_cache
# 使用内存缓存
@lru_cache(maxsize=1000)
def cached_claude_call(prompt_hash: str) -> str:
# 实际的API调用逻辑
pass
def call_with_cache(client, prompt: str) -> str:
# 生成提示的哈希值作为缓存键
prompt_hash = hashlib.md5(prompt.encode()).hexdigest()
# 检查缓存
cached = cached_claude_call(prompt_hash)
if cached:
return cached
# 缓存未命中,调用API
response = client.messages.create(...)
result = response.content[0].text
# 更新缓存
cached_claude_call.cache_clear() # 简化示例,实际应更新特定键
return result
如果你想深入了解更多Claude Code的最佳实践,建议阅读我们的专题指南。
升级还是优化?成本效益分析
面对频繁的rate limit错误,用户往往面临一个选择:是升级到更高的订阅计划,还是继续优化使用策略?这个决策需要基于具体的使用场景和成本效益分析。
首先来看各计划的性价比。Pro计划每月$20提供约40-80小时的使用时长,平均成本为$0.25-0.50/小时。Max 5×计划每月$100提供200-400小时,平均成本为$0.25-0.50/小时——与Pro计划相当,但上限更高。Max 20×计划的平均成本进一步降低,约为$0.20-0.25/小时。
从成本角度来看,升级的拐点在于你的月使用量是否超过当前计划的上限。如果你每月稳定使用超过80小时Claude Code,升级到Max 5×是合理的选择,因为继续使用Pro计划只会导致频繁中断而无法提高生产力。
然而,升级并非总是最佳选择。如果你的使用量波动较大——某些月份高,某些月份低——那么灵活的API按量付费可能更经济。API的定价是按实际使用的token数量计费,不存在"月费浪费"的问题。
| 使用场景 | 推荐方案 | 理由 |
|---|---|---|
| 每周<10小时 | Free或Pro | 配额充足,无需额外投入 |
| 每周10-40小时 | Pro | 性价比最佳 |
| 每周40-100小时 | Max 5× | 避免频繁限制 |
| 每周>100小时 | Max 20×或API | 最高配额或按量付费 |
| 波动较大 | API按量付费 | 灵活性最高 |
| 需要Opus 4 | Max计划 | 仅Max支持Opus 4 |
对于需要高频使用但预算有限的用户,还有一个选择:使用第三方API中转服务。这些服务通常提供更灵活的定价和更高的配额,但需要权衡服务稳定性和数据安全性。
中国用户的替代方案
对于中国大陆用户来说,直接访问Claude Code面临额外的挑战。由于网络限制,直接连接Anthropic的API服务可能不稳定或完全不可用。这一节将介绍几种可行的替代方案。
方案一:使用VPN或代理服务。这是最直接的方法,但存在连接不稳定、延迟较高等问题。对于生产环境来说,这种方案的可靠性难以保证。
方案二:使用API中转服务。一些第三方服务商提供Claude API的中转访问,将Anthropic的API通过国内可访问的服务器进行转发。这种方案的优点是连接稳定、延迟较低,但需要选择可靠的服务商。
以laozhang.ai为例,这是一个提供多种AI模型API访问的平台。相比直接使用官方API,它的优势在于:
- 国内直连:服务器部署在国内可访问的位置,延迟约20ms(官方API延迟200ms+)
- 统一接口:兼容OpenAI API格式,便于现有项目迁移
- 灵活计费:按实际使用量付费,适合使用量波动的场景
- 新用户福利:注册即送测试额度
但需要明确的是,使用第三方服务存在一些限制:首先,这不是官方渠道,技术支持和服务保障与官方不同;其次,对于涉及敏感数据的应用,需要评估数据安全风险;最后,第三方服务的定价和功能可能随时变化。
如果你的项目对数据安全要求极高,或者需要官方级别的技术支持,建议通过合规渠道使用官方服务。更多关于中国用户如何使用Claude Code的详细指南可以参考我们的专题文章。
方案三:使用Claude的企业版本。Anthropic为企业用户提供了定制化的部署方案,包括私有云部署等选项。这种方案成本较高,但提供最高级别的服务保障和合规支持,适合大型企业和对数据安全有严格要求的组织。
常见问题解答
Q1:5小时窗口是从什么时候开始计算的?
5小时滚动窗口是从当前时刻向前推算的,而不是从某个固定时间点开始。这意味着系统会持续追踪你过去5小时内的所有使用记录。例如,如果现在是下午3点,系统会计算从上午10点到下午3点之间的累计使用量。这种机制使得配额恢复更加平滑——你最早的使用会随时间自动"滑出"计算窗口。
Q2:使用Opus 4模型会消耗多少配额?
根据Anthropic的资源分配策略,使用Opus 4模型消耗约5倍于Sonnet 4的配额。这意味着如果你的计划允许每5小时100次Sonnet 4提示,切换到Opus 4后大约只能使用20次。这个比例是动态的,可能随Anthropic的策略调整而变化。建议非必要时使用Sonnet 4,只在需要最高质量输出时才使用Opus 4。
Q3:API的Tier升级需要多长时间?
API Tier升级是即时生效的。一旦你的累计充值金额达到相应阈值(Tier 2需$40,Tier 3需$200,Tier 4需$400),系统会自动提升你的Tier级别,无需等待或申请。需要注意的是,这个累计金额是终身有效的,不会因为时间推移而重置。
Q4:遇到429错误应该等待多久再重试?
这取决于你遇到的具体限制类型。对于请求频率限制(RPM),通常等待几秒钟即可;对于token限制,可能需要等待1分钟左右;对于5小时窗口配额限制,需要等待配额自然恢复,时间从几分钟到几小时不等。最佳实践是实现指数退避重试逻辑,从1秒开始逐步增加等待时间。
Q5:如何判断是触发了哪种限制?
最可靠的方法是检查API响应中的错误信息。不同类型的限制会返回不同的错误代码和描述。此外,可以通过观察错误发生的模式来判断:如果是几秒内连续触发,很可能是RPM限制;如果是使用一段时间后突然触发,很可能是token或配额限制;如果持续一整周无法使用,则是周限制。查看响应头中的x-ratelimit-*字段也能提供有用的诊断信息。
总结
Claude Code的使用限制体系虽然复杂,但理解其核心机制后就能有效应对。5小时滚动窗口提供了灵活的配额恢复机制,Tier分级系统为不同规模的用户提供了适合的选择,而智能重试逻辑则是生产环境的必备保障。
对于大多数个人开发者,Pro计划结合优化策略就能满足日常需求。如果频繁触发限制,首先应该审视自己的使用模式——是否可以通过精简提示、批量处理、本地缓存等方式减少API调用?只有在优化后仍然无法满足需求时,才考虑升级计划。
对于中国用户,可以考虑使用laozhang.ai等API中转服务获得更稳定的访问体验,或者阅读更多关于稳定低价Claude API的使用指南。
记住,限制的存在是为了保证服务质量,而不是为了阻止你使用。通过理解和适应这些限制,你可以在配额内实现更高效的工作流程。