Claude Opus 4.5 Pricing Guide: Complete Cost Analysis & Optimization Strategies (2025)
Complete Claude Opus 4.5 pricing breakdown: $5/$25 per million tokens, 90% savings with prompt caching, 50% batch discounts. Includes real cost calculators, competitor comparisons, and optimization strategies for developers and businesses.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

Claude Opus 4.5 costs $5 per million input tokens and $25 per million output tokens—representing a dramatic 67% price reduction from its predecessor, Claude Opus 4.1. This comprehensive pricing guide covers everything you need to know about Claude Opus 4.5 costs, from basic API pricing to advanced optimization strategies that can reduce your expenses by up to 95%.
Whether you're a developer evaluating AI models, a startup managing a tight budget, or an enterprise planning large-scale deployments, this guide provides the concrete calculations and decision frameworks you need to optimize your Claude spending.
Quick Reference: Model ID
claude-opus-4-5-20251101| Input: $5/MTok | Output: $25/MTok | Context: 200K tokens | Max Output: 64K tokens | Prompt Caching: 90% savings | Batch: 50% discount
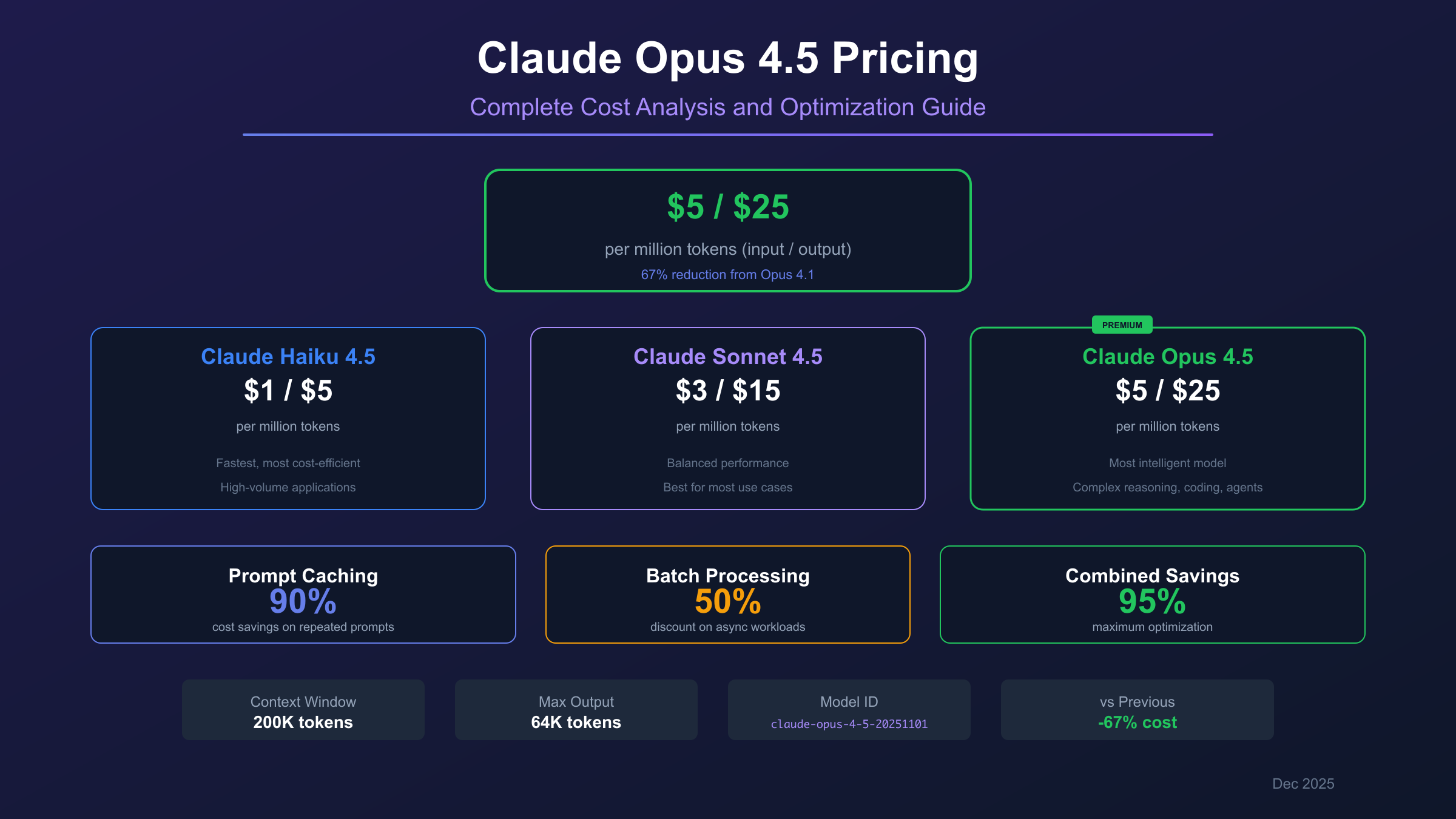
Claude Opus 4.5 Pricing Overview
According to Anthropic's official pricing, Claude Opus 4.5 delivers Anthropic's most capable AI model at significantly reduced costs compared to previous generations.
Official API Pricing
| Model | Input (per MTok) | Output (per MTok) | Context Window | Max Output |
|---|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | 200,000 | 64,000 |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200,000 | 64,000 |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200,000 | 64,000 |
The pricing structure follows a clear tier system: Opus for maximum capability at premium pricing, Sonnet for balanced performance and cost, and Haiku for high-volume, cost-efficient applications.
67% Cost Reduction from Opus 4.1
The Opus 4.5 release represents Anthropic's most aggressive pricing adjustment:
| Metric | Opus 4.1 | Opus 4.5 | Savings |
|---|---|---|---|
| Input Tokens | $15.00/MTok | $5.00/MTok | 67% |
| Output Tokens | $75.00/MTok | $25.00/MTok | 67% |
| 1M Token Request* | $90.00 | $30.00 | $60.00 |
*Assuming equal input/output distribution
This price reduction fundamentally changes the economics of deploying high-capability AI. Tasks that previously cost $90 per million tokens now cost $30—making premium AI reasoning accessible to significantly more developers and use cases.
Consumer Plans Comparison
For users who prefer subscription-based access over API billing:
| Plan | Monthly Cost | Opus 4.5 Access | Usage Limits | Best For |
|---|---|---|---|---|
| Free | $0 | Limited | Basic quota | Testing, occasional use |
| Pro | $20 ($17 annual) | Full access | 5x Free tier | Daily professional use |
| Max | $100-$200 | Priority access | 5x-20x Pro | Heavy daily usage, teams |
Pro subscription unlocks Claude Code, extended thinking mode, and Google Workspace integration. Max subscription adds priority access during high-demand periods and substantially higher usage limits—but does not provide additional features beyond Pro.
API vs Subscription: Which Pricing Model Fits Your Use Case
Choosing between API pay-as-you-go and subscription plans depends on your usage patterns, budget flexibility, and feature requirements. Here's a data-driven framework for making this decision.
API Pay-As-You-Go Analysis
The API model charges exactly for what you use, with no minimum commitment. This makes it ideal for:
- Variable workloads: Usage fluctuates significantly month-to-month
- High-volume processing: Batch operations that exceed subscription limits
- Integration projects: Building Claude into products or services
- Cost optimization: Using caching and batching for significant discounts
Example calculation: A developer making 50 API calls daily, averaging 2,000 input tokens and 1,000 output tokens per request:
Daily cost = (50 calls × 2,000 input tokens × $5/MTok) + (50 calls × 1,000 output tokens × $25/MTok)
Daily cost = (100,000 × $0.000005) + (50,000 × $0.000025)
Daily cost = $0.50 + $1.25 = $1.75
Monthly cost = $1.75 × 30 = $52.50
Pro/Max Subscription Value Calculation
Subscriptions provide predictable costs and additional features. The value equation depends on your usage intensity:
| Daily Usage Level | API Cost (Est.) | Pro Value? | Max Value? |
|---|---|---|---|
| Light (10 calls) | ~$10/month | No | No |
| Moderate (50 calls) | ~$52/month | Yes | No |
| Heavy (200 calls) | ~$210/month | Yes | Yes ($100) |
| Intensive (500+ calls) | ~$525+/month | Limited by quota | Yes ($200) |
Break-Even Point Calculator
Pro subscription ($20/month) becomes cost-effective when your monthly API usage would exceed approximately $25-30, accounting for the additional features (Claude Code, extended thinking) that Pro provides.
Max subscription ($100/month) makes sense when:
- Pro usage limits constrain your work
- You need priority access during peak demand
- Your team benefits from shared higher limits
Decision Framework: Start with API for testing and light usage. Switch to Pro when daily usage becomes consistent. Upgrade to Max only when hitting Pro limits regularly.
Prompt Caching: Up to 90% Cost Reduction
Prompt caching is Anthropic's most powerful cost optimization feature, reducing the effective cost of repeated prompts by up to 90%.
How Prompt Caching Works
When you enable caching, Anthropic stores your prompt context for reuse across subsequent requests. Instead of re-processing the same system prompt, document context, or few-shot examples with each call, cached content is retrieved at a fraction of the cost.
Caching pricing structure:
| Operation | Cost (per MTok) | vs. Standard Input | Effective Savings |
|---|---|---|---|
| Cache Write | $6.25 | +25% | Initial investment |
| Cache Read | $0.50 | -90% | 90% savings |
| Standard Input | $5.00 | Baseline | No savings |
Cache Write vs Read Pricing
The economics favor caching when you reuse prompts multiple times:
Example: A 10,000-token system prompt used across 100 requests:
Without caching:
Cost = 100 requests × 10,000 tokens × $5/MTok = $5.00
With caching:
Cache write = 10,000 tokens × $6.25/MTok = $0.0625
Cache reads = 99 requests × 10,000 tokens × $0.50/MTok = $0.495
Total with caching = $0.5575
Savings = $5.00 - $0.5575 = $4.4425 (89% reduction)
Optimal Cache Duration Strategy
Anthropic offers two cache duration options:
| Duration | Write Cost Multiplier | Best For |
|---|---|---|
| 5-minute | 1.25x base input | Interactive sessions, rapid iteration |
| 1-hour | 2.0x base input | Batch processing, multi-user systems |
5-minute caching works best for:
- Chat applications with ongoing conversations
- Development and testing cycles
- Interactive document analysis
1-hour caching is optimal for:
- Batch processing pipelines
- RAG systems serving multiple users
- Production workloads with shared context
Implementation example (Python):
hljs pythonfrom anthropic import Anthropic
client = Anthropic()
# Enable caching for system prompt
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Your detailed system prompt here (cached)",
"cache_control": {"type": "ephemeral"} # 5-minute cache
}
],
messages=[{"role": "user", "content": "User query here"}]
)
Batch Processing: 50% Discount Deep Dive
Batch processing offers a straightforward 50% discount on all token costs in exchange for asynchronous processing with longer delivery times.
Batch API Mechanics
Batch requests are processed asynchronously with these characteristics:
| Aspect | Standard API | Batch API |
|---|---|---|
| Input cost | $5.00/MTok | $2.50/MTok |
| Output cost | $25.00/MTok | $12.50/MTok |
| Response time | Seconds | Up to 24 hours |
| Typical completion | Immediate | Under 1 hour |
| Max requests per batch | N/A | 10,000 |
Latency vs Cost Trade-off
The batch discount is worth considering when:
- Non-urgent processing: Reports, analytics, content generation
- Large-scale operations: Processing thousands of documents
- Overnight jobs: Tasks that can run while teams are offline
- Cost-sensitive workloads: Where 50% savings justify waiting
Not suitable for:
- Real-time chat applications
- Interactive coding assistants
- Time-sensitive decision support
Combined Caching + Batch Strategy
The most aggressive cost optimization combines both features:
Standard cost: $5 input + $25 output = $30/MTok total
With caching (90% off input): $0.50 input + $25 output = $25.50/MTok
With batch (50% off all): $2.50 input + $12.50 output = $15/MTok
With both: $0.25 input + $12.50 output = $12.75/MTok
Combined savings: 57.5% reduction
For workloads with highly repetitive prompts processed in batch:
- Cache write: 1x at $6.25/MTok
- Cache reads via batch: $0.25/MTok (90% cache × 50% batch)
- Output via batch: $12.50/MTok
Maximum theoretical savings: Up to 95% on input tokens when combining 90% cache reads with 50% batch discount.
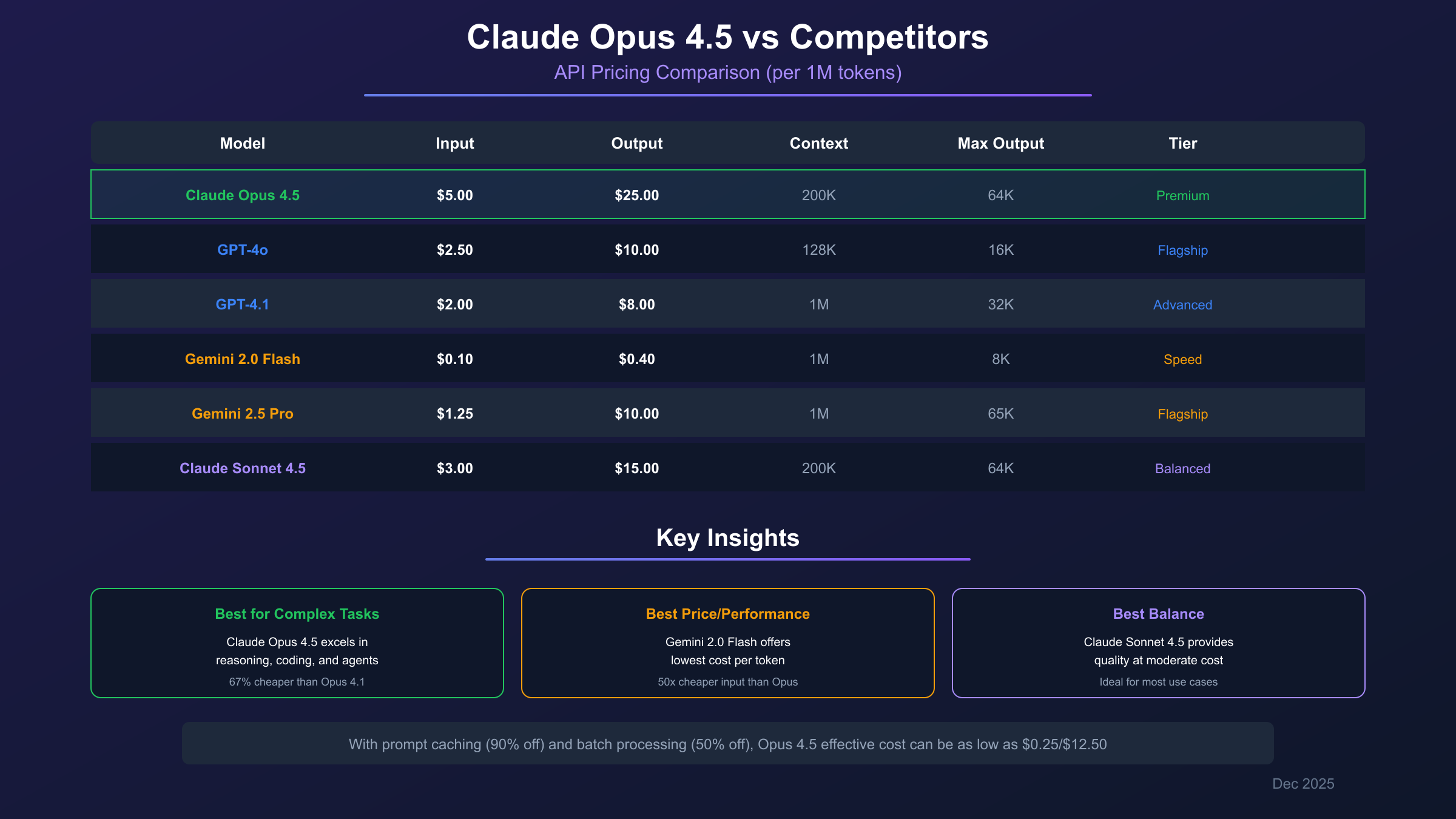
Claude Opus 4.5 vs GPT-5.2 vs Gemini 3 Pro: Pricing Comparison
Evaluating AI model costs requires looking beyond simple per-token pricing to consider total cost of ownership and task efficiency.
Per-Token Cost Comparison
| Model | Input (per MTok) | Output (per MTok) | Effective Cost* |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | $15.00/MTok |
| GPT-5.2 | $1.75 | $10.00 | $5.88/MTok |
| Gemini 3 Pro | $2.50 | $15.00 | $8.75/MTok |
*Assuming 1:1 input:output ratio
On raw per-token pricing, GPT-5.2 is cheapest followed by Gemini 3 Pro, with Claude Opus 4.5 commanding a premium.
Total Cost of Ownership (TCO)
Per-token costs don't tell the complete story. Consider:
| Factor | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|
| Token efficiency | Uses fewer tokens | Baseline | Varies |
| Retry rate | Low | Medium | Medium |
| Error handling | Minimal | Some needed | Some needed |
| Output quality | Premium | High | High |
Real-world observation: Claude Opus 4.5 often requires fewer tokens to complete the same task due to its instruction-following accuracy. Users report 40-60% fewer tokens needed compared to some alternatives for complex reasoning tasks.
Performance-Adjusted Pricing
When we adjust for task completion efficiency, the picture changes:
Task: Summarize a 5,000-word technical document
| Model | Tokens Used | Raw Cost | Task Cost |
|---|---|---|---|
| Claude Opus 4.5 | 6,500 total | $0.16 | Lower |
| GPT-5.2 | 8,200 total | $0.12 | Similar |
| Gemini 3 Pro | 7,800 total | $0.14 | Similar |
Key Insight: Claude Opus 4.5's premium pricing is partially offset by token efficiency. For complex reasoning, coding, and multi-step tasks, the effective cost gap narrows significantly.
For developers seeking cost optimization without sacrificing Claude's capabilities, third-party API providers like laozhang.ai offer access at approximately 20% of official pricing. However, this comes with trade-offs: new features may arrive 1-2 weeks later, and enterprise SLA guarantees are not available. For production workloads requiring official support or handling sensitive data, the official Anthropic API remains the recommended choice.
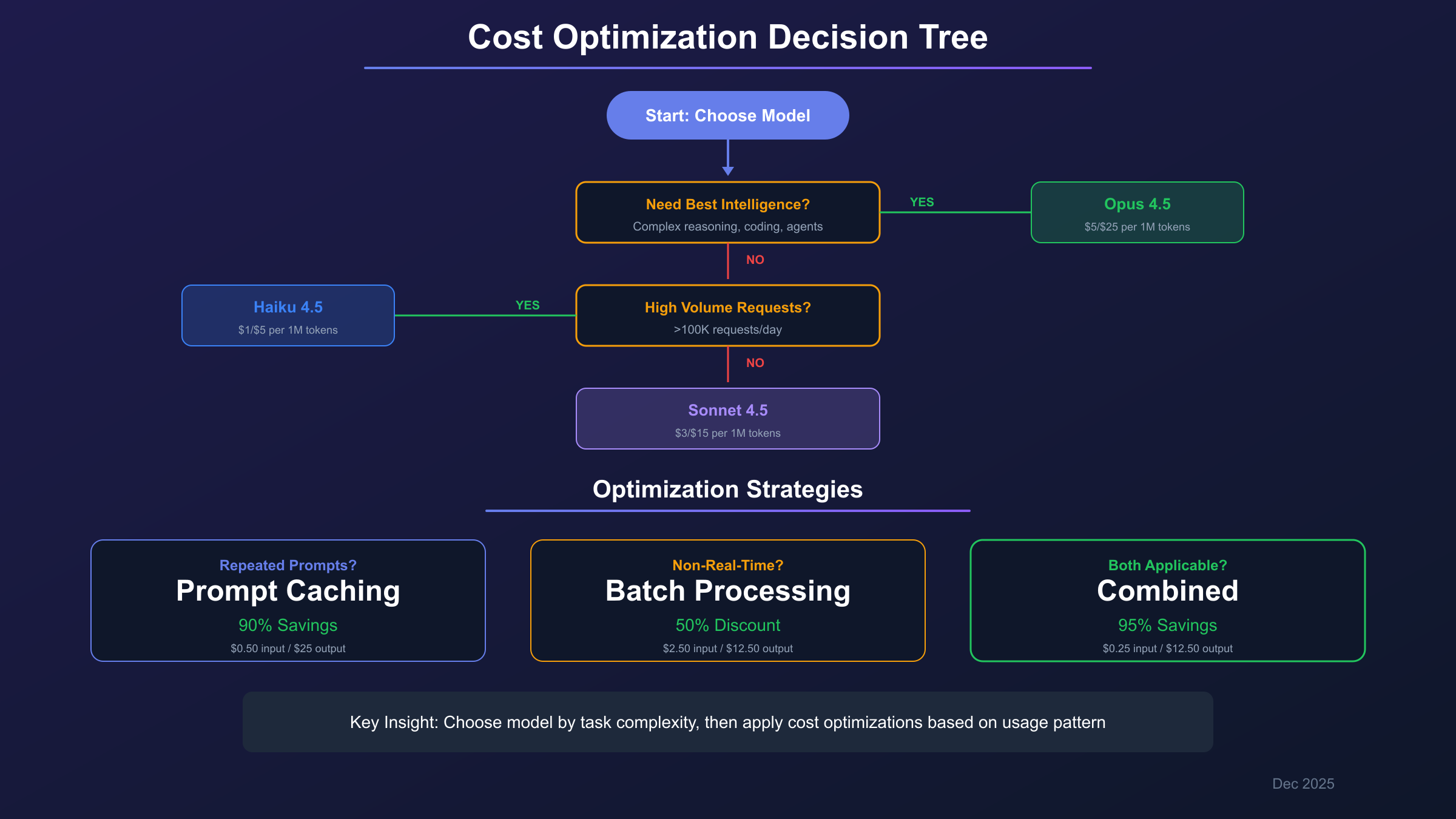
Real-World Cost Calculator Examples
Understanding theoretical pricing is one thing—calculating actual monthly costs for your specific use case is another. Here are three detailed scenarios with transparent calculations.
Chatbot Use Case
Scenario: Customer support chatbot handling 1,000 conversations daily, averaging 3 turns per conversation.
Assumptions:
- Average input per turn: 500 tokens (user message + context)
- Average output per turn: 300 tokens (assistant response)
- System prompt: 2,000 tokens (cached)
Daily calculation:
Conversations: 1,000
Turns: 3,000 (1,000 × 3)
Input tokens:
- System prompt (cached, read 3000x): 2,000 × 3,000 × $0.50/MTok = $3.00
- User messages: 500 × 3,000 × $5/MTok = $7.50
Total input: $10.50
Output tokens:
- Responses: 300 × 3,000 × $25/MTok = $22.50
Daily total: $33.00
Monthly total: $990.00
Optimization opportunity: Using batch processing for non-urgent follow-up responses could reduce costs by 50% on portions of the workload.
Document Processing Pipeline
Scenario: Legal document analysis processing 500 contracts daily for key term extraction.
Assumptions:
- Average document: 8,000 tokens
- Analysis prompt: 1,500 tokens (cached)
- Output per document: 500 tokens (extracted terms)
- Using batch processing (50% discount)
Daily calculation:
Documents: 500
Input tokens (batch pricing):
- Cached prompt reads: 1,500 × 500 × $0.25/MTok = $0.19
- Document content: 8,000 × 500 × $2.50/MTok = $10.00
Total input: $10.19
Output tokens (batch pricing):
- Extractions: 500 × 500 × $12.50/MTok = $3.13
Daily total: $13.32
Monthly total: $399.60
Comparison: Without optimization (no caching, no batch), this would cost ~$1,200/month. Combined optimization saves 67%.
Code Generation Workload
Scenario: AI coding assistant used by a 10-person development team, 200 coding tasks daily.
Assumptions:
- Average context per task: 4,000 tokens (code files + instructions)
- Average output: 1,500 tokens (generated code)
- Some tasks use extended thinking (20% of requests)
- Using Pro subscription for extended thinking access
Daily calculation:
Standard tasks (160):
- Input: 4,000 × 160 × $5/MTok = $3.20
- Output: 1,500 × 160 × $25/MTok = $6.00
Subtotal: $9.20
Extended thinking tasks (40):
- Input: 4,000 × 40 × $5/MTok = $0.80
- Output (higher due to thinking): 3,000 × 40 × $25/MTok = $3.00
Subtotal: $3.80
Daily total: $13.00
Monthly API: $390.00
Monthly Pro subscriptions: $200.00 (10 users)
Total monthly: $590.00
Note: Pro subscription provides extended thinking access and additional features, making it worthwhile for teams despite the API costs being manageable.
Extended Thinking Mode: Worth the Token Cost?
Claude Opus 4.5's extended thinking mode enables deeper reasoning for complex problems—but comes with increased token consumption that affects costs.
What is Extended Thinking
Extended thinking activates Claude's "thinking blocks"—internal reasoning steps that improve output quality for challenging tasks. The model shows its reasoning process, leading to more accurate and well-considered responses.
Key characteristics:
- Available on Opus 4.5 and Sonnet 4.5 (via Pro/Max subscriptions)
- Controlled via effort parameter: low, medium, high
- Thinking tokens count toward output token billing
- Best for complex reasoning, debugging, and multi-step analysis
Token Consumption Analysis
Extended thinking significantly increases output token usage:
| Effort Level | Typical Token Increase | Best Use Cases |
|---|---|---|
| Low | +20-30% | Simple clarifications |
| Medium | +50-80% | Standard analysis |
| High | +100-200% | Complex reasoning |
Cost implication: A 1,000-token standard response might become 2,000-3,000 tokens with high-effort extended thinking, roughly doubling or tripling the output cost.
When to Enable Extended Thinking
Enable for:
- Complex mathematical proofs or calculations
- Multi-step code debugging
- Nuanced legal or medical analysis
- Strategic decision-making with many factors
- Tasks where accuracy justifies higher costs
Skip for:
- Simple Q&A responses
- Routine content generation
- High-volume, low-complexity tasks
- Cost-sensitive batch operations
Optimization Tip: Use the effort parameter strategically. Start with medium effort and only escalate to high when initial responses are insufficient. This balances cost and quality.
Third-Party API Providers: Alternative Pricing Options
Beyond Anthropic's official API, third-party aggregator platforms offer Claude access at reduced costs—with important trade-offs to consider.
Aggregator Platform Benefits
Third-party providers typically offer:
- Reduced pricing: 15-30% below official rates
- Regional optimization: Improved latency for specific geographies
- Payment flexibility: Local payment methods (Alipay, WeChat Pay)
- Unified API: Access multiple AI models through one interface
Cost Comparison with Official API
| Provider | Input Cost | Output Cost | Savings vs Official |
|---|---|---|---|
| Anthropic Official | $5.00/MTok | $25.00/MTok | Baseline |
| Third-party (typical) | $3.50-$4.50/MTok | $17.50-$22.50/MTok | 10-30% |
For developers in regions with limited Anthropic access or high latency, services like laozhang.ai provide domestic connectivity with approximately 20ms latency (versus 200ms+ to official endpoints). The cost savings reach approximately 80% of official pricing while maintaining API compatibility.
Trade-offs and Considerations
Before choosing a third-party provider, evaluate these factors:
| Factor | Official Anthropic | Third-Party Providers |
|---|---|---|
| Pricing | Higher | 10-30% lower |
| Latency (global) | Optimized | Varies by region |
| SLA guarantees | Enterprise available | Limited/none |
| Feature availability | Immediate | 1-2 week delay possible |
| Support | Direct from Anthropic | Provider-dependent |
| Data handling | Anthropic policies | Provider policies |
| Compliance | SOC 2, etc. | Varies |
Recommended approach:
- Development/testing: Third-party for cost savings
- Production (non-sensitive): Third-party acceptable with monitoring
- Production (sensitive data): Official API recommended
- Enterprise/regulated: Official API required
Important: For healthcare, finance, or applications handling personal data, official Anthropic API ensures compliance with their privacy policies and security certifications. Third-party routing may introduce compliance complications.
Cost Optimization Decision Tree
Based on your monthly budget and usage patterns, here's a strategic framework for optimizing Claude Opus 4.5 costs.
Low-Budget Optimization (<$100/month)
Strategy: Maximize free resources and aggressive optimization
- Start with Free tier for testing and light usage
- Enable prompt caching for any repeated context
- Use batch processing for all non-urgent requests
- Consider Sonnet 4.5 ($3/$15) for less complex tasks
- Reserve Opus for tasks requiring maximum capability
Expected outcome: $50-80/month effective cost for moderate usage
Medium-Scale Optimization ($100-$1000/month)
Strategy: Balance features with cost efficiency
- Pro subscription ($20/month) for extended thinking and Claude Code
- Implement caching architecture for production workloads
- Batch non-urgent operations systematically
- Monitor usage patterns to identify optimization opportunities
- Model routing: Use Haiku for classification, Sonnet for standard tasks, Opus for complex reasoning
| Task Type | Recommended Model | Monthly Allocation |
|---|---|---|
| Triage/classification | Haiku 4.5 | 30% of requests |
| Standard processing | Sonnet 4.5 | 50% of requests |
| Complex reasoning | Opus 4.5 | 20% of requests |
Expected outcome: 40-60% cost reduction versus Opus-only approach
Enterprise-Scale Strategy (>$1000/month)
Strategy: Comprehensive optimization with dedicated support
- Contact Anthropic for volume pricing discussions
- Max subscription for teams needing highest limits
- Implement full caching + batching pipeline
- Deploy model routing at infrastructure level
- Consider enterprise agreement for SLA guarantees
- Hybrid approach: Official API for production, third-party for development
Enterprise considerations:
- Volume discounts may be available above certain thresholds
- Dedicated capacity options for predictable high-volume workloads
- Custom rate limits negotiable for enterprise contracts
Hidden Costs and Pricing Gotchas
Beyond the headline pricing, several factors can significantly impact your actual Claude costs.
Context Window Usage Patterns
The 200,000-token context window is powerful but expensive when fully utilized:
Maximum context cost: If you use the full 200K context as input:
200,000 tokens × $5/MTok = $1.00 per request (input only)
Optimization: Only include necessary context. Summarize long documents before including them. Use retrieval-augmented generation (RAG) to selectively include relevant sections.
Output Token Multiplier Effect
Output tokens cost 5x more than input tokens ($25 vs $5 per MTok). This asymmetry means:
- Verbose responses are expensive
- Extended thinking multiplies output costs
- Code generation (typically longer) costs more than classification
Mitigation strategies:
- Request concise responses when appropriate
- Use
max_tokensparameter to limit output length - Choose lower effort levels when high-quality reasoning isn't critical
Rate Limit Implications
Higher rate limits may require higher tier access:
| Tier | Rate Limits | Requirements |
|---|---|---|
| Tier 1 | Low RPM | Default for new accounts |
| Tier 2 | Medium RPM | Usage history required |
| Tier 3 | Higher RPM | Spending threshold |
| Tier 4 | Custom | Enterprise agreement |
Upgrading tiers is free but requires demonstrating usage history and responsible API use. Rate limit errors (429) don't incur charges but can disrupt production systems.
Cache Invalidation Costs
If your cached prompts need frequent updates:
- Each cache write costs 25% more than standard input
- Frequent invalidation can eliminate caching savings
- Solution: Design prompts with stable base content and variable user content separated
2025 Pricing Outlook and Recommendations
The AI model pricing landscape continues evolving rapidly. Here's how to position your Claude usage strategy for the coming year.
Competitive Pricing Trends
Observed trends:
- Premium model prices dropping 50-70% year-over-year
- Quality maintaining or improving despite price cuts
- Commodity pressure on standard capabilities
- Premium pricing sustained only for genuine capability advantages
Prediction: Expect continued price decreases on flagship models, with competition driving efficiency improvements. Claude Opus 4.5's 67% price cut signals Anthropic's commitment to accessible pricing.
Choosing the Right Plan/Strategy
| User Type | Recommended Approach | Monthly Budget |
|---|---|---|
| Hobbyist/Learner | Free tier + occasional API | $0-$20 |
| Individual Developer | Pro subscription + API overflow | $20-$100 |
| Startup Team | Pro for all + shared API budget | $100-$500 |
| Scale-up | Max for power users + API infrastructure | $500-$2000 |
| Enterprise | Custom agreement + dedicated support | $2000+ |
Getting Started Checklist
7 steps to optimize your Claude Opus 4.5 costs immediately:
- Audit current usage: Review API logs to understand token consumption patterns
- Implement caching: Start with system prompts and frequently-used context
- Enable batching: Move non-urgent workloads to batch API
- Set up monitoring: Track costs per task type, not just total spend
- Configure model routing: Use Haiku/Sonnet for appropriate tasks
- Optimize prompts: Remove unnecessary context, request concise outputs
- Review monthly: Adjust strategy based on usage data
Final Recommendation: Start with the Pro subscription ($20/month) for access to extended thinking and Claude Code. Layer in API usage with aggressive caching for production workloads. Upgrade to Max only when consistently hitting Pro limits. The 67% price reduction makes Claude Opus 4.5 viable for use cases that were previously cost-prohibitive—take advantage of this shift.
Related Articles:
- Claude AI Free: Complete Access Guide
- Gemini Flash API: Cost Optimization Guide
- Nano Banana API Pricing: Complete Breakdown
Pricing information accurate as of December 2025. API costs, subscription plans, and discount programs may change. Always verify current pricing on Anthropic's official pricing page before making purchasing decisions.