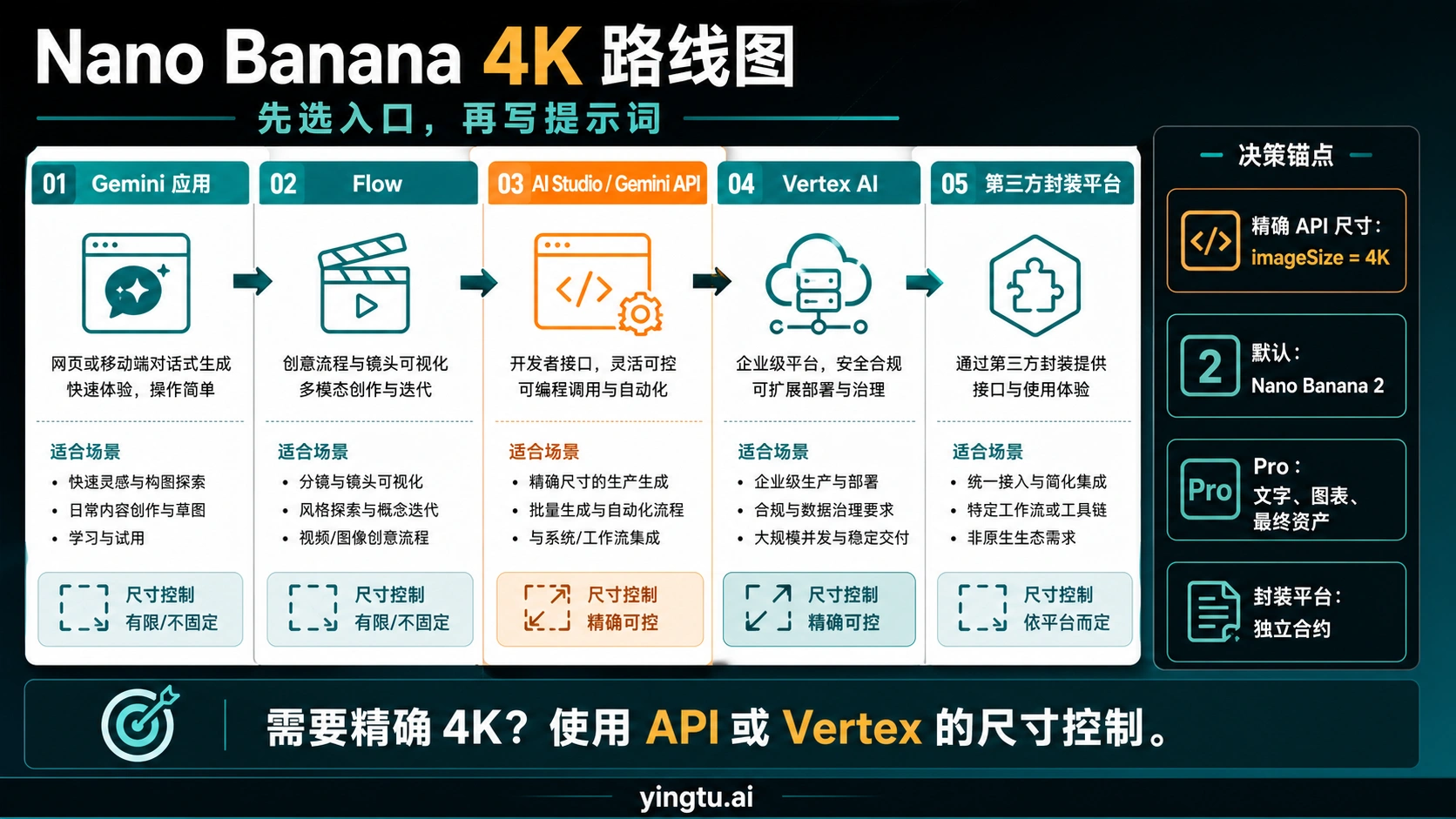
Nano Banana 生成 4K 图,关键不是把提示词写成“4K 高清”,而是先选对入口。想快速试图,可以用 Gemini 应用或 Flow;想精确控制像素尺寸,就应该走 AI Studio、Gemini API 或 Vertex AI,并在图像配置里设置 imageSize: "4K"。大多数 API 任务先用 Nano Banana 2 就够了;只有文字、图表、接地信息、品牌画面或最终交付质量很难时,才把 Nano Banana Pro 作为升级路线。
| 入口 | 适合谁 | 4K 边界 |
|---|---|---|
| Gemini 应用 | 想最快生成和编辑图片的普通用户 | 体验最快,但不要假设所有账号、地区、套餐和下载路径都给精确 4K 文件 |
| Flow | 做视频镜头、分镜、角色图和创意流程的人 | 导出能力取决于 Flow 的项目设置、额度和套餐 |
| AI Studio / Gemini API | 需要模型、比例、尺寸和日志可控的开发者 | 在图像配置里设置 imageSize: "4K" 或 image_size: "4K" |
| Vertex AI | 需要 Google Cloud 权限、账单、IAM 和生产部署的团队 | 仍然要通过对应模型和尺寸配置控制输出 |
| 第三方工具 | 想低门槛在线试图或用某个平台工作流的人 | 免费、积分、放大和下载尺寸都属于该平台自己的承诺 |
最稳的默认动作是:API 里先试 gemini-3.1-flash-image-preview,也就是 Nano Banana 2;如果画面包含复杂文字、信息图、真实地点线索、密集标注或客户交付,再切到 gemini-3-pro-image-preview,也就是 Nano Banana Pro。提示词可以描述画质,但真正请求 4K 的开关在图像配置里。
先选入口,而不是先改提示词
很多人卡在 1K 或 2K,是因为把“生成 4K”当成一个提示词问题。实际要先确认当前用的是哪一层入口:消费者界面、视频创作界面、开发者 API、云平台,还是包装过的第三方生成器。不同入口会使用相似的 Nano Banana 名称,但尺寸控制、账单、导出文件和失败排查完全不同。
如果只是想生成一张社交图、头像、概念图或灵感草图,Gemini 应用和 Flow 的优势是快。它们适合边聊边改、直接看效果、顺手做变体。但这类界面不等于 API 合同。按钮上写着高清,不代表每个账号都能下载精确 4096 级文件,也不代表你能拿到模型 ID、尺寸参数、日志和错误码。
如果你要做产品图生成、营销素材流水线、批量海报、设计工具或自动化创意系统,就应该使用 AI Studio、Gemini API 或 Vertex AI。开发者入口可以把模型、宽高比、输出尺寸和账单记录下来。后续只要某张图没有达到 4K,就能查到底是模型不对、参数缺失、比例不支持,还是额度或计费边界触发了限制。
第三方生成器可以作为试用入口,但不要把它们的“免费 4K”当成 Google 官方 API 事实。有的平台会先生成 2K 再放大,有的平台会压缩下载图,有的平台会把不同模型包装成同一个按钮。使用前要看清积分、隐私、输出尺寸、是否原生生成以及失败后如何扣费。
当前模型应该怎么理解
截至 2026 年 4 月 25 日,Google 的 Gemini API 图像文档把 Nano Banana 家族分成三条常用理解:
| 公开名称 | API 模型 ID | 最适合的默认任务 |
|---|---|---|
| Nano Banana 2 | gemini-3.1-flash-image-preview | 成本和速度更均衡的 4K API 默认路线 |
| Nano Banana Pro | gemini-3-pro-image-preview | 专业成片、复杂指令、强文字、图表、接地细节和最终润色 |
| 原版 Nano Banana | gemini-2.5-flash-image | 较旧的 1024px 级别快速生成路线,不是当前 4K API 默认选择 |
这会改变旧教程里的 Pro-only 判断。Nano Banana Pro 仍然是高质量路线,但它不是唯一应该和 4K 绑定的路线。很多开发任务更适合先用 Nano Banana 2:例如商品主图、网站 hero 图、社媒素材、编辑配图、批量候选图和需要多次迭代的创意流程。它能把 4K 能力和更可控的成本、速度放在一起。
Nano Banana Pro 的价值在高失败成本任务里更明显。画面里有小字、表格、品牌包装、中文海报、多角色一致性、真实世界知识、图解结构或客户最终审稿时,低价模型多试几次未必划算。此时直接上 Pro,可以减少后期修图、重试和人工校对。
API 里真正控制 4K 的参数
在 API 里,尺寸来自图像配置,不来自一句“请输出 4K”的愿望。提示词里的“4K quality”“高清细节”可以帮助模型理解风格和细节密度,但如果没有设置尺寸字段,输出仍可能停在默认尺寸。
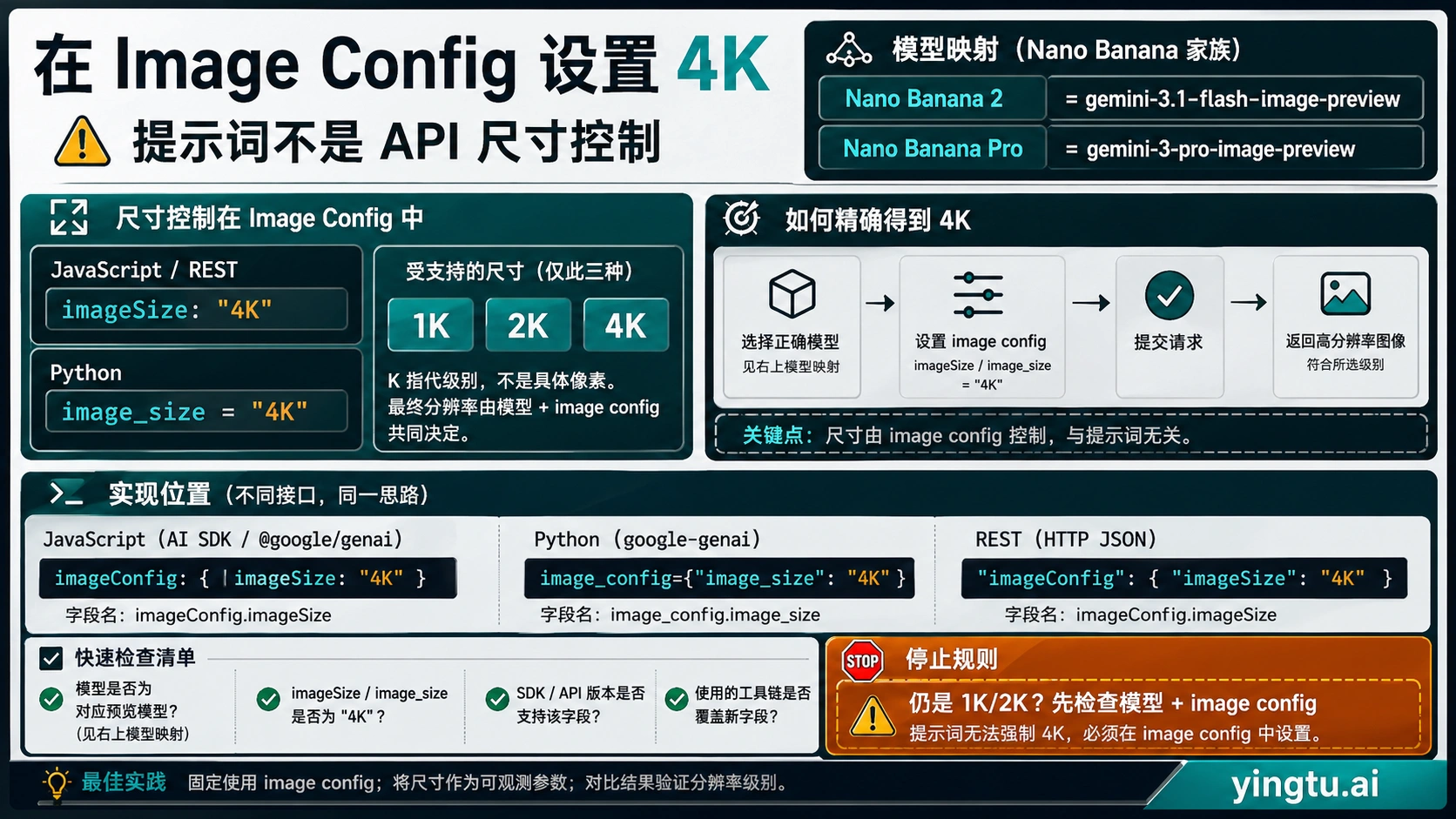
JavaScript 风格的配置里,关键字段是 imageConfig.imageSize:
hljs jsconst result = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: [{ role: "user", parts: [{ text: prompt }] }],
config: {
responseModalities: ["IMAGE"],
imageConfig: {
imageSize: "4K",
aspectRatio: "16:9",
},
},
});
Python 风格的配置里,同一件事通常写成 image_config.image_size:
hljs pythonresponse = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=prompt,
config={
"response_modalities": ["IMAGE"],
"image_config": {
"image_size": "4K",
"aspect_ratio": "16:9",
},
},
)
如果任务需要 Nano Banana Pro,把模型 ID 换成 gemini-3-pro-image-preview,尺寸字段仍然是同一个核心控制点。排查低分辨率输出时,先看模型和 image config,再改提示词。只在 prompt 里堆“ultra HD、4K、sharp details”,通常解决不了尺寸问题。
4K 尺寸与官方价格边界
截至 2026 年 4 月 25 日,Google 文档列出的 4K 示例尺寸包括:
| 宽高比 | 4K 输出尺寸 |
|---|---|
| 1:1 | 4096 x 4096 |
| 16:9 | 5504 x 3072 |
| 9:16 | 3072 x 5504 |

价格也要分清合约所有者。第三方工具可以说自己提供免费额度或免费 4K 试用,但 Google 官方 API 价格行是另一回事。2026 年 4 月 25 日核对到的官方标准 4K 图像输出价格是:
| 模型 | 标准 4K 图像输出价格 | 适合场景 |
|---|---|---|
Nano Banana 2 / gemini-3.1-flash-image-preview | $0.151 / 张 | API 里多数 4K 任务的效率默认值 |
Nano Banana Pro / gemini-3-pro-image-preview | $0.24 / 张 | 文字、图表、接地信息和最终交付质量更重要 |
相关图像价格行在同日显示 Free Tier 不可用。Batch 或 Flex 可能改变成本,搜索接地等能力也可能单独计费。生产报价前,不要只引用一个截图或平台宣传语,而要重新打开官方价格页,记录日期、模型、尺寸、是否批处理、是否使用 grounding,以及实际输出数量。
2K、4K 和 Pro 怎么取舍
4K 不是每次都该作为第一步。它适合最终资产、大屏展示、印刷、客户交付、后续裁剪、多尺寸复用和会被压缩的平台上传。4K 的好处是留给后处理更多像素余量,坏处是成本、等待时间和失败损失都会上升。
2K 更适合探索构图、内部评审、提示词试错和网页小卡片。一个实用流程是先用 Nano Banana 2 在 1K 或 2K 跑多个方向,选出最好的构图、主体和视觉语言,再把最终提示词升到 4K。如果图里没有复杂文字或精细结构,这样通常比一开始全用 4K 更省。
Pro 的判断不只看分辨率,而看失败成本。简单背景图、生活方式图、概念草稿和普通社媒图,Nano Banana 2 往往先够用。包装图、带文字海报、信息板、UI 模拟、商品细节、可交付商业视觉和需要真实地点线索的图,Pro 更值得直接测试。
| 任务 | 建议起点 |
|---|---|
| 快速 API 4K 迭代 | Nano Banana 2 + 4K |
| 复杂文字或最终客户稿 | Nano Banana Pro + 4K |
| 大量提示词候选 | Nano Banana 2 + 1K/2K,再挑选升 4K |
| 普通无代码试图 | Gemini 应用或 Flow,并检查导出尺寸 |
| 第三方工具工作流 | 先验证平台合约、实际像素和是否放大 |
为什么输出还停在 1K 或 2K
看到低分辨率文件,不要立刻重写整段提示词。先按入口、模型、配置、导出路径和账单边界排查。
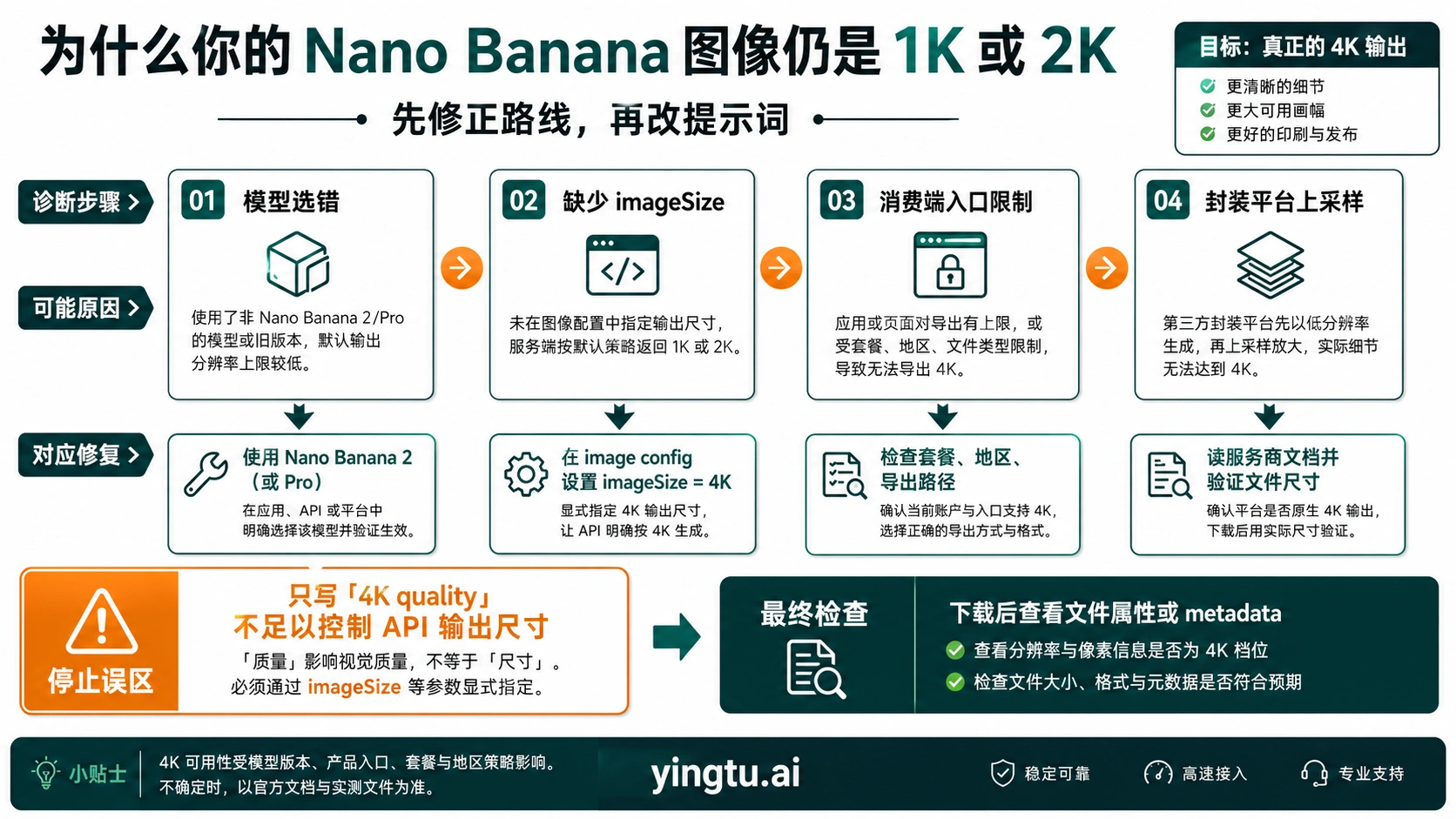
模型用错。 如果代码里还是 gemini-2.5-flash-image,那就是旧的 1024px 级别路线。当前 API 4K 应该检查 gemini-3.1-flash-image-preview 或 gemini-3-pro-image-preview。
缺少尺寸配置。 只写“生成 4K 图片”会提高画质倾向,但不一定改变输出像素。把 imageSize: "4K" 或 image_size: "4K" 放进图像配置。
消费者界面限制。 Gemini 应用和 Flow 的 UI、账号级别、地区、项目设置和导出流程可能决定最终文件。不要把 API 价格表直接套到应用下载按钮上。
第三方平台放大。 有的平台不是原生 4K,而是生成后放大、压缩或重新编码。下载后打开文件属性,查看像素尺寸、文件大小和压缩痕迹。
宽高比不支持。 如果请求的比例不被当前入口支持,系统可能回退到默认尺寸或返回错误。把 aspect ratio 和 image size 写清楚,并用受支持比例复测。
额度或计费边界。 如果高分辨率需要付费账单或特定额度,系统可能限制输出或报错。把 billing、quota、project 和 API key 所属账号一起检查。
提示词仍然重要,但排在尺寸控制之后
入口和尺寸正确后,提示词才开始真正影响 4K 成片质量。好的 4K 提示词应该说明主体、构图、需要保持清晰的细节、禁止出现的错误,以及最终用途。
产品图可以这样写:
hljs textCreate a 4K hero image of a matte black smart desk lamp on a walnut table, soft morning window light, clean background, accurate product geometry, sharp edge detail, no visible brand logos, no extra objects.
信息板可以这样写:
hljs textCreate a clean technical information board about Nano Banana 4K routing, large readable labels, grouped panels, teal and graphite palette, icons for app, API, cloud, and wrapper routes, no tiny text, no fake UI.
中文项目里常见的错误是把提示词写得像愿望清单,却没有告诉模型哪些内容不能错。比如“做一张科技感 4K 海报”太宽;“16:9,深色背景,主体是一台银色折叠屏手机,屏幕文字只保留三行大字,边缘锐利,无多余 logo”更可控。要让 4K 有价值,像素之外的布局、可读文字、主体边界和后续用途也要被定义。
稳定生产 4K 的三步流程
可重复的生产流程应该降低每次失败的成本:
- 先用 Nano Banana 2 在 1K 或 2K 生成多个候选,探索主体、光线、构图和风格。
- 选出最强候选后,固定提示词、宽高比、禁止项和用途说明。
- 最终稿再用 Nano Banana 2 输出 4K;如果文字、图表、真实信息或客户审稿压力很高,再切 Nano Banana Pro。
生成后一定要验文件。检查像素尺寸、文件格式、压缩痕迹、文字可读性、边缘锐度和裁剪余量。自动化系统还应该保存模型 ID、尺寸字段、宽高比、提示词版本、输出尺寸、费用和错误信息。这样下次突然只出 2K 时,团队能知道是模型、参数、额度、导出路径还是第三方平台改变了行为。
常见问题
哪些当前模型支持 4K 输出?
当前 Gemini 3 图像路线里,Nano Banana 2(gemini-3.1-flash-image-preview)和 Nano Banana Pro(gemini-3-pro-image-preview)都可以作为 4K API 路线。原版 Nano Banana(gemini-2.5-flash-image)不是当前 4K API 默认选择。
哪个 API 参数控制输出尺寸?
使用图像配置里的尺寸字段。JavaScript 或 REST 风格通常是 imageSize: "4K",Python 风格通常是 image_size: "4K"。提示词里的“4K”不能替代这个字段。
官方 API 的 4K 输出免费吗?
2026 年 4 月 25 日核对到的相关官方图像价格行显示 Free Tier 不可用,4K 输出属于付费 API 合同。Gemini 应用、Flow 积分和第三方工具的免费额度要分别核对。
什么时候要从 Nano Banana 2 换到 Pro?
当图片包含复杂文字、表格、图解、真实地点线索、多角色一致性、品牌包装或最终客户交付时,Pro 更值得测试。普通构图探索和多数 API 4K 候选图,先用 Nano Banana 2 更合理。
输出为什么仍然是 1K 或 2K?
最常见原因是模型仍是旧路线、没有设置 image config、消费者界面导出受限、第三方平台做了放大或压缩、宽高比不支持,或账单与额度不满足高分辨率输出。
第三方生成器可以用吗?
可以用于快速试图,但要把它当作独立平台。上线前核对模型路由、积分、价格、隐私、文件像素、是否原生 4K、是否压缩,以及失败时如何扣费。