Gemini API速率限制完全指南:RPM、TPM、429错误处理与Tier升级(2026)
深入解析Gemini API的RPM、TPM、RPD、IPM四种速率限制机制,包含2026年1月最新配额数据、Free Tier与Paid Tier完整对比、429错误处理代码示例、生产环境最佳实践。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

你的Gemini API应用运行正常,突然间开始频繁返回429错误。检查代码没有问题,检查网络也没有问题,但请求就是被拒绝。这种情况在使用Google Gemini API的开发者中非常普遍,尤其是在2025年12月Google大幅收紧免费配额之后。问题的根源在于速率限制(Rate Limits)——一个很多开发者只有在触发时才会注意到的机制。
理解Gemini API的速率限制不仅能帮你避免429错误,更能让你合理规划API使用、优化成本、并在生产环境中构建弹性架构。本指南将系统性地解释RPM、TPM、RPD、IPM四种限制机制,提供2026年1月最新的配额数据,并给出从错误处理到架构设计的完整解决方案。

速率限制基础概念:RPM、TPM、RPD、IPM是什么
Gemini API的速率限制是Google为了保护服务稳定性和公平分配资源而设置的访问控制机制。不同于简单的"每天X次"限制,Gemini采用了多维度的限制体系,理解这些概念是有效使用API的基础。
RPM(Requests Per Minute) 是每分钟请求次数限制,这是最直观的指标。无论你的请求内容多长或多短,每次API调用都计为1次请求。如果你的RPM限制是15,那么每分钟最多只能发起15次API调用,超过就会触发429错误。
TPM(Tokens Per Minute) 是每分钟处理的token数量限制,这个指标更加细腻。Token是语言模型处理文本的基本单位,对于英文大约4个字符等于1个token,中文通常1个汉字占2-3个token。TPM限制意味着即使你的请求次数没超,但如果单次请求的内容太长(输入+输出token总和太大),同样会被限制。实际开发中,TPM往往比RPM更容易触发,因为一次包含长文档的请求可能消耗数万token。
RPD(Requests Per Day) 是每日请求总数限制,这是一个较长周期的约束。对于Free Tier用户,RPD通常是1500次,意味着即使你严格控制每分钟的请求频率,一天下来的总量也不能超过这个上限。
IPM(Images Per Minute) 是图片生成频率限制,专门针对Gemini的图片生成功能(如gemini-2.5-flash的图片生成能力)。由于图片生成比文本生成消耗更多计算资源,Google对此设置了独立的限制维度。
这四种限制是同时生效的关系,任何一个触发都会导致请求被拒绝。在实际应用中,开发者需要同时监控这四个指标,而不仅仅是其中一个。
Free Tier完整限制表:2026年1月最新数据
Google的Free Tier为开发者提供了零成本体验Gemini API的机会,但其配额限制在2025年12月经历了显著收紧。以下是2026年1月的最新官方数据,来自Google AI开发者文档:
| 模型 | RPM | TPM | RPD | IPM |
|---|---|---|---|---|
| gemini-2.5-pro | 5 | 250,000 | 100 | - |
| gemini-2.5-flash | 15 | 250,000 | 500 | 10 |
| gemini-2.5-flash-lite | 15 | 250,000 | 1,000 | - |
| gemini-3-pro-preview | ~10 | ~250,000 | ~500 | - |
| gemini-3-flash-preview | ~15 | ~250,000 | ~1,000 | - |
几个关键观察点值得注意。首先,Gemini 2.5系列的配额相比此前有显著调整,gemini-2.5-pro的RPM仅为5次,RPD仅100次,这意味着Pro模型在Free Tier下几乎只能用于极轻量的测试,无法支撑任何实际业务。其次,Gemini 3系列已进入Preview阶段,gemini-3-pro-preview和gemini-3-flash-preview提供了与2.5系列相近的配额限制,建议开发者提前适配。
⚠️ 重要提醒:Gemini 2.0系列(包括gemini-2.5-flash)将于2026年3月3日正式退役。如果你的应用仍在使用2.0版本,请尽快迁移到Gemini 2.5或3.0系列。
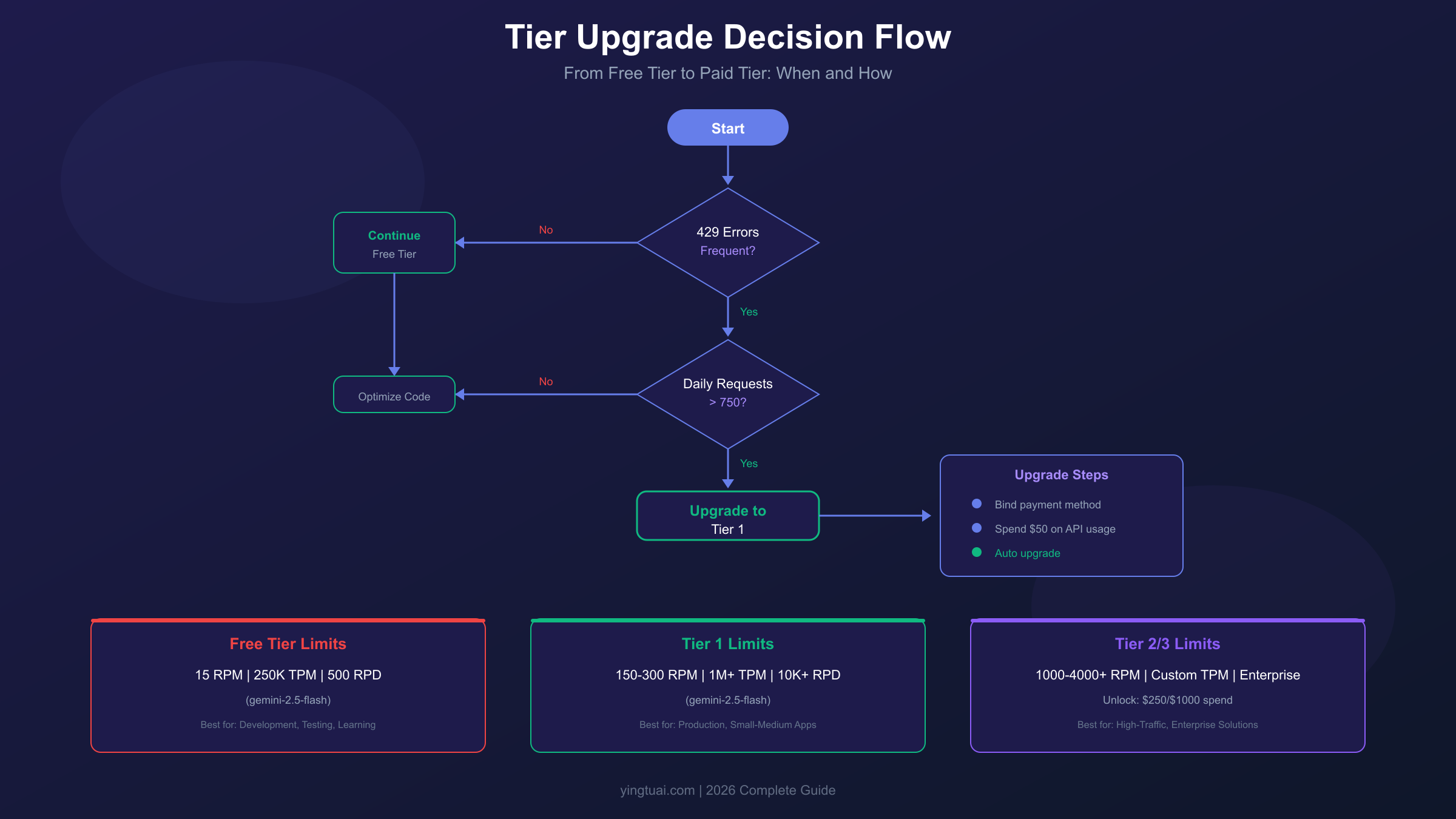
Free Tier的适用场景非常明确:开发测试、概念验证、个人学习项目。如果你的应用需要每分钟处理超过10个请求,或者日请求量超过1000,那么Free Tier很可能无法满足需求,应该考虑升级到付费层级。
值得一提的是,所有Free Tier的限制都是按Google Cloud项目计算的,而不是按API Key。这意味着即使你创建多个API Key,它们共享同一个项目的配额上限。如果需要隔离配额,必须创建独立的Google Cloud项目。
Paid Tier层级对比:Tier 1到Tier 3全解析
当Free Tier无法满足需求时,升级到Paid Tier是自然的选择。Google为Gemini API设计了三个付费层级,每个层级的配额和解锁条件都不同:
| 层级 | 解锁条件 | gemini-2.5-flash RPM | gemini-2.5-pro RPM | 特点 |
|---|---|---|---|---|
| Tier 1 | 绑定付款方式 + $50消费 | 150-300 | 50-100 | 入门付费,适合小型项目 |
| Tier 2 | $250累计消费 + 30天 | 1,000+ | 300+ | 进阶付费,适合中型应用 |
| Tier 3 | $1,000消费或企业申请 | 4,000+ | 1,000+ | 企业级,可申请更高配额 |
Tier 1是大多数开发者的第一站。只需要在Google Cloud Console中绑定有效的付款方式(信用卡或银行账户),然后累计消费达到$50,系统会自动将你的项目升级到Tier 1。升级后最明显的变化是gemini-2.5-flash的RPM从15提升到150-300——这是10-20倍的提升,基本能支撑中小型应用的需求。同时,RPD限制被大幅放宽,你不再需要频繁担心每日请求总量的上限。
Tier 2适合已经验证产品市场匹配、开始规模化的应用。当累计消费达到$250时自动解锁,配额再次翻倍。对于需要高并发处理的场景(如批量文档分析、实时聊天应用),Tier 2提供了更大的缓冲空间。
Tier 3是企业级方案,除了累计消费$1000外,也可以通过填写配额申请表单主动申请。Tier 3的特点是配额可以根据业务需求定制,适合有特殊需求的大型企业。
关于升级决策,这里有一个简单的判断框架:如果429错误开始影响用户体验,或者你的日请求量稳定超过Free Tier的50%(约750次/天),那么是时候考虑升级了。详细的成本与定价分析可以帮助你做出更精确的预算规划。
429错误处理实战:从理解到解决
当你触发速率限制时,Gemini API会返回HTTP 429状态码,错误信息通常包含RESOURCE_EXHAUSTED。理解这个错误的结构是正确处理它的第一步:
hljs json{
"error": {
"code": 429,
"message": "You exceeded your current quota, please check your plan and billing details.",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"@type": "type.googleapis.com/google.rpc.RetryInfo",
"retryDelay": "30s"
}
]
}
}
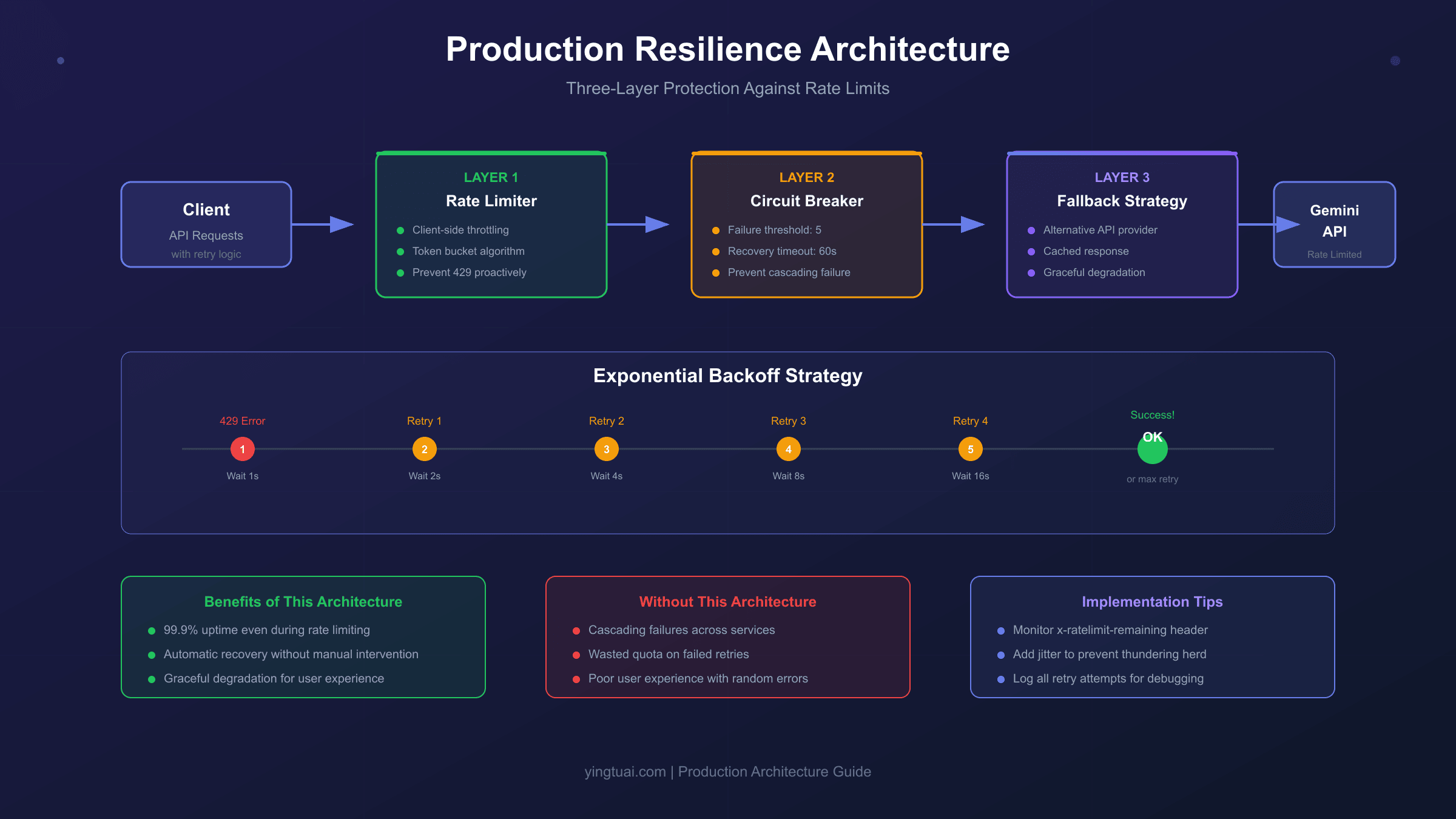
错误响应中的retryDelay字段非常重要,它告诉你建议等待多久再重试。但更好的做法是实现指数退避(Exponential Backoff)策略,这是处理速率限制的行业标准方案。
以下是Python实现的生产级429错误处理:
hljs pythonimport google.generativeai as genai
import time
import random
def call_gemini_with_retry(prompt, max_retries=5):
"""带指数退避的Gemini API调用"""
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-2.5-flash")
base_delay = 1 # 初始等待1秒
max_delay = 32 # 最大等待32秒
for attempt in range(max_retries):
try:
response = model.generate_content(prompt)
return response.text
except Exception as e:
error_str = str(e)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
if attempt == max_retries - 1:
raise Exception(f"重试{max_retries}次后仍然失败: {e}")
# 指数退避 + 随机抖动
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1)
wait_time = delay + jitter
print(f"触发速率限制,等待{wait_time:.1f}秒后重试(第{attempt + 1}次)")
time.sleep(wait_time)
else:
raise # 非429错误直接抛出
# 使用示例
result = call_gemini_with_retry("解释量子计算的基本原理")
print(result)
JavaScript/Node.js的实现如下:
hljs javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai");
async function callGeminiWithRetry(prompt, maxRetries = 5) {
const genAI = new GoogleGenerativeAI("YOUR_API_KEY");
const model = genAI.getGenerativeModel({ model: "gemini-2.5-flash" });
const baseDelay = 1000; // 初始等待1秒
const maxDelay = 32000; // 最大等待32秒
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
const result = await model.generateContent(prompt);
return result.response.text();
} catch (error) {
const errorStr = error.toString();
if (errorStr.includes("429") || errorStr.includes("RESOURCE_EXHAUSTED")) {
if (attempt === maxRetries - 1) {
throw new Error(`重试${maxRetries}次后仍然失败: ${error}`);
}
// 指数退避 + 随机抖动
const delay = Math.min(baseDelay * Math.pow(2, attempt), maxDelay);
const jitter = Math.random() * delay * 0.1;
const waitTime = delay + jitter;
console.log(`触发速率限制,等待${(waitTime/1000).toFixed(1)}秒后重试(第${attempt + 1}次)`);
await new Promise(resolve => setTimeout(resolve, waitTime));
} else {
throw error; // 非429错误直接抛出
}
}
}
}
// 使用示例
callGeminiWithRetry("解释量子计算的基本原理")
.then(result => console.log(result))
.catch(err => console.error(err));
指数退避的核心逻辑是:第一次失败等待1秒,第二次等待2秒,第三次等待4秒,以此类推直到达到上限。添加随机抖动(jitter)是为了避免多个客户端在同一时刻重试导致的"惊群效应"。
如果你的应用频繁触发429错误,除了改进错误处理,更应该检查是否需要升级配额层级或优化请求策略。
配额监控与优化:主动管理你的API使用
被动等待429错误发生再处理是下策,主动监控配额使用才是上策。Gemini API的响应头中包含了配额状态信息,善用这些信息可以实现预防性限流。
hljs pythonimport google.generativeai as genai
import requests
def check_quota_from_response(response_headers):
"""从响应头解析配额信息"""
quota_info = {
"remaining_requests": response_headers.get("x-ratelimit-remaining-requests"),
"remaining_tokens": response_headers.get("x-ratelimit-remaining-tokens"),
"reset_time": response_headers.get("x-ratelimit-reset")
}
return quota_info
class QuotaAwareGeminiClient:
def __init__(self, api_key, warning_threshold=0.2):
"""
warning_threshold: 当剩余配额低于此比例时发出警告
"""
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel("gemini-2.5-flash")
self.warning_threshold = warning_threshold
self.last_remaining = None
def generate(self, prompt):
response = self.model.generate_content(prompt)
# 检查是否接近配额上限(模拟,实际需要解析响应头)
if self.last_remaining and self.last_remaining < self.warning_threshold:
print(f"⚠️ 警告:配额剩余不足{self.warning_threshold*100}%,建议降低请求频率")
return response.text
# 客户端限流实现
import time
from collections import deque
class RateLimiter:
def __init__(self, max_requests_per_minute):
self.max_rpm = max_requests_per_minute
self.request_times = deque()
def wait_if_needed(self):
"""如果即将超出限制,则等待"""
now = time.time()
# 清理1分钟前的记录
while self.request_times and now - self.request_times[0] > 60:
self.request_times.popleft()
# 如果已达到限制,等待最早的请求过期
if len(self.request_times) >= self.max_rpm:
sleep_time = 60 - (now - self.request_times[0]) + 0.1
if sleep_time > 0:
print(f"主动限流:等待{sleep_time:.1f}秒")
time.sleep(sleep_time)
self.request_times.append(time.time())
# 使用示例
limiter = RateLimiter(max_requests_per_minute=8) # 留20%余量
for i in range(20):
limiter.wait_if_needed()
print(f"发送请求 {i+1}")
# 实际调用API...
除了代码层面的监控,Google Cloud Console提供了可视化的配额仪表板。在Console中导航到 APIs & Services > Quotas,可以看到实时的配额使用情况和历史趋势。建议设置告警规则,当使用量达到80%时触发通知,给你足够的缓冲时间来调整策略或申请更高配额。
Token优化也是降低配额消耗的有效手段。避免发送不必要的长上下文、使用system prompt时精简指令、合理设置max_output_tokens参数都能帮助你在相同配额下完成更多工作。
升级决策指南:何时从Free Tier迁移到付费
Free Tier适合探索和学习,但业务增长迟早会触碰它的天花板。判断是否需要升级,可以参考以下信号:
明确需要升级的信号:
- 429错误频率超过总请求的5%
- 用户反馈"响应太慢"或"经常失败"
- 日均请求量稳定超过1000次
- 需要使用gemini-2.5-pro但受限于5 RPM
可以继续使用Free Tier的场景:
- 个人学习项目,请求量低于100次/天
- 内部工具,使用者少于10人
- 概念验证阶段,尚未面向用户
升级到Tier 1的操作非常简单:
- 登录Google Cloud Console
- 进入 Billing 页面
- 添加有效的付款方式(信用卡/银行账户)
- 在启用了Gemini API的项目中产生$50消费
- 系统自动升级,通常在账单结算后生效
升级后立即生效的变化:gemini-2.5-flash的RPM从15提升到150-300,RPD限制大幅放宽,错误率显著下降。但需要注意,付费后的使用是按实际调用量计费的,务必做好成本监控。
生产环境最佳实践:构建弹性API调用架构
在生产环境中,仅靠指数退避是不够的。你需要一套完整的弹性架构来应对各种异常情况。以下是经过验证的三层防护策略:
第一层:熔断器(Circuit Breaker)
当错误率超过阈值时,熔断器会"断开",暂停所有请求,避免无效重试消耗配额和加剧服务压力。
hljs pythonimport time
from enum import Enum
class CircuitState(Enum):
CLOSED = "closed" # 正常状态,允许请求
OPEN = "open" # 熔断状态,拒绝所有请求
HALF_OPEN = "half_open" # 半开状态,允许少量请求测试
class CircuitBreaker:
def __init__(self, failure_threshold=5, recovery_timeout=60):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.failure_count = 0
self.last_failure_time = None
self.state = CircuitState.CLOSED
def can_execute(self):
if self.state == CircuitState.CLOSED:
return True
elif self.state == CircuitState.OPEN:
# 检查是否到了恢复时间
if time.time() - self.last_failure_time > self.recovery_timeout:
self.state = CircuitState.HALF_OPEN
return True
return False
else: # HALF_OPEN
return True
def record_success(self):
self.failure_count = 0
self.state = CircuitState.CLOSED
def record_failure(self):
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = CircuitState.OPEN
print("⚠️ 熔断器开启:暂停所有请求")
第二层:请求队列与优先级
并非所有请求都同等重要。通过请求队列区分优先级,确保关键请求在配额紧张时优先处理。
第三层:降级方案
当官方API持续不可用时,降级到备选方案可以保证业务连续性。对于需要高可用性的场景,可以考虑将API中转服务作为备选路径。以laozhang.ai为例,中转服务通常不受官方速率限制的约束,延迟约20ms(官方200ms+),适合作为关键业务的降级方案。但需要注意:中转服务更适合开发测试和中小流量场景,大规模生产环境建议直接使用官方企业级方案。
hljs pythonclass ResilientGeminiClient:
def __init__(self, primary_api_key, fallback_base_url=None, fallback_api_key=None):
self.circuit_breaker = CircuitBreaker()
self.primary_key = primary_api_key
self.fallback_url = fallback_base_url
self.fallback_key = fallback_api_key
def generate(self, prompt, priority="normal"):
# 检查熔断器状态
if not self.circuit_breaker.can_execute():
if self.fallback_url and priority == "high":
return self._call_fallback(prompt)
raise Exception("服务暂时不可用,请稍后重试")
try:
result = self._call_primary(prompt)
self.circuit_breaker.record_success()
return result
except Exception as e:
self.circuit_breaker.record_failure()
# 高优先级请求尝试降级
if self.fallback_url and priority == "high":
print("主服务失败,切换到降级方案")
return self._call_fallback(prompt)
raise
def _call_primary(self, prompt):
# 调用官方Gemini API
pass
def _call_fallback(self, prompt):
# 调用降级服务
pass
常见问题FAQ
Q1: RPM和TPM哪个更容易触发?
通常TPM更容易触发。因为RPM限制的是请求次数,而TPM限制的是token总量。一次包含长文档的请求可能消耗10万token,而Free Tier的TPM限制只有25万(gemini-2.5-flash),仅2-3次这样的请求就会触发限制,远早于RPM的15次限制。建议在处理长内容时特别注意TPM消耗。
Q2: Free Tier的限制是每个API Key还是每个项目?
限制是按Google Cloud项目计算的,不是按API Key。这意味着在同一个项目中创建多个API Key不会增加总配额,它们共享同一个上限。如果需要更多配额,要么升级到付费层级,要么创建多个独立的Google Cloud项目(但这违反服务条款,不建议)。
Q3: 超过限制会被封号吗?
不会。触发速率限制只会导致请求被拒绝(返回429错误),不会导致API Key或账号被封禁。但如果你通过不当手段(如创建大量项目)规避限制,可能会违反Google的服务条款。正当使用范围内,超限只是临时拒绝,配额重置后就会恢复。
Q4: 如何申请更高配额?
有两种方式:一是通过增加消费自动升级Tier($50→Tier 1,$250→Tier 2,$1000→Tier 3);二是在Google Cloud Console中提交配额申请表单,说明业务需求。企业用户还可以联系Google销售团队获取定制方案。Tier 3用户申请额外配额的通过率较高。
Q5: 中国用户如何稳定使用Gemini API?
中国大陆直接访问Gemini API存在网络不稳定的问题,除了使用VPN外,API中转服务是另一个选择。例如laozhang.ai提供了国内可直连的中转服务,延迟约20ms,兼容OpenAI SDK格式,切换成本低。中转服务适合开发测试和对延迟敏感的场景,但需要注意选择可靠的服务商并了解数据处理政策。更多中国访问Gemini的方案可以参考专题指南。
Q6: Batch API和实时API的配额是共享的吗?
部分共享。Batch API有独立的配额池(通常更高),但某些限制(如每日请求总量)可能与实时API共享。使用Batch API处理非实时任务是优化配额使用的有效策略,因为Batch API的价格通常只有实时API的50%,且配额更宽松。
Q7: 为什么我没到RPM限制就被429了?
可能是触发了TPM或RPD限制,而不是RPM。429错误信息不一定明确指出是哪种限制,建议检查:(1) 最近的请求是否包含大量token;(2) 今日总请求是否接近RPD上限;(3) 是否在使用图片生成功能(会触发IPM限制)。
Q8: 从Free Tier升级到Tier 1需要多久?
升级是准实时的。一旦你的账户满足条件(绑定付款方式+$50消费),系统通常在几分钟到几小时内自动升级。如果超过24小时仍未升级,可以联系Google Cloud支持确认账户状态。
Gemini API的速率限制看似复杂,但理解其设计逻辑后就会发现它是可预测、可管理的。RPM/TPM/RPD/IPM四种限制各有侧重,Free Tier适合起步,Paid Tier支撑增长,而生产环境需要熔断器、队列、降级的三层防护。从本指南出发,你可以构建出既稳定又经济的Gemini API应用架构。