Nano Banana Pro API不返回图片?8种原因和完整解决方案【2026最新】
详解Nano Banana Pro(Gemini 3 Pro Image)API不返回图片的8种常见原因,包括responseModalities配置、模型版本、安全过滤器、地区限制等,附完整代码示例和快速诊断流程。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

使用Nano Banana Pro(Gemini 3 Pro Image Preview)API进行图片生成时,最让开发者头疼的问题莫过于:请求发送成功,却没有图片返回。根据Google AI开发者论坛的统计,超过60%的API调用问题都与"无图片返回"相关,而这些问题往往源于8种不同的原因。
本文将系统性地分析Nano Banana Pro API不返回图片的所有可能原因,提供针对性的解决方案,并附带可直接使用的代码示例。无论你是刚接触Gemini图片生成API的新手,还是遇到间歇性故障的老手,都能在这里找到答案。
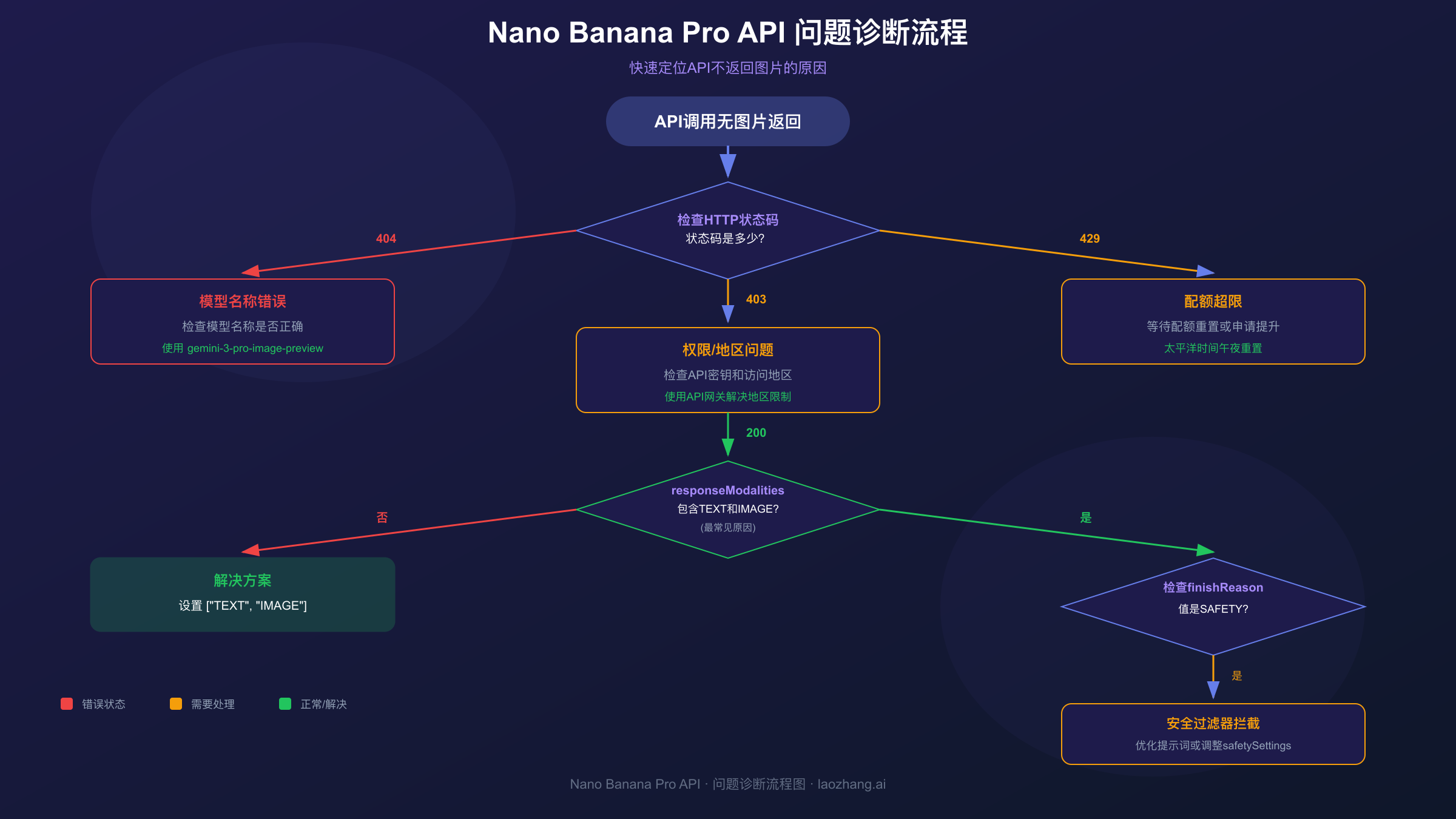
快速诊断流程
在深入每种问题的细节之前,先通过这个快速诊断流程定位你的问题类型。
Nano Banana Pro API不返回图片时,按以下顺序排查最为高效:
首先检查HTTP响应状态码。如果返回404错误,说明模型名称或API版本有误,需要核对当前有效的模型列表。如果返回403错误,可能是API密钥问题或地区限制,需要检查密钥状态和访问来源IP。如果返回429错误,表示触发了速率限制,需要等待配额重置或申请更高配额。
如果状态码是200但没有图片数据,重点检查以下三个方面:第一,responseModalities参数是否正确配置为["TEXT", "IMAGE"];第二,检查响应中的finishReason字段,如果显示SAFETY则表示触发了安全过滤器;第三,确认candidates数组不为空且包含inlineData字段。
如果请求根本无法发送(连接超时或DNS解析失败),则需要检查网络环境,特别是国内用户需要考虑地区限制的影响。
responseModalities配置错误(最常见)
这是导致API不返回图片的最常见原因,约占所有问题的40%以上。
根据Google官方文档的明确说明,Nano Banana Pro模型不支持仅返回图片,必须同时指定文本和图片两种输出模态。很多开发者想当然地认为既然是图片生成API,应该可以只返回图片,这个假设是错误的。
错误配置示例:
hljs python# 错误:只指定IMAGE模态
generationConfig = {
"responseModalities": ["IMAGE"] # 这样会导致请求失败或返回空
}
# 错误:完全不指定responseModalities
generationConfig = {
"temperature": 1
} # 默认只返回文本,不会生成图片
正确配置示例:
hljs python# 正确:必须同时包含TEXT和IMAGE
generationConfig = {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": "1:1",
"imageSize": "2K" # 支持2K/4K
}
}
另一个常见错误是参数名称拼写错误。responseModalities是驼峰命名法,不是response_modalities(下划线形式)。不同的SDK可能有不同的命名规范,使用官方Python SDK时请遵循其文档中的参数命名方式。
模型名称/版本错误(404错误)
当你收到404 NOT_FOUND - models/xxx is not found for API version v1beta错误时,说明使用了错误的模型名称或该模型已被弃用。
当前有效的图片生成模型(截至2026年1月):
| 模型名称 | 用途 | 状态 |
|---|---|---|
| gemini-2.5-flash-image | 快速图片生成 | ✅ 推荐 |
| gemini-3-pro-image-preview | 高质量图片生成(Nano Banana Pro) | ✅ 可用 |
已弃用的模型(使用会返回404):
gemini-2.0-flash-exp-image-generation(2025年10月退役)gemini-2.0-flash-preview-image-generation(已被替代)
如何检查可用模型:
hljs pythonimport requests
API_KEY = "your-api-key"
url = f"https://generativelanguage.googleapis.com/v1beta/models?key={API_KEY}"
response = requests.get(url)
models = response.json()
# 筛选支持图片生成的模型
for model in models.get("models", []):
if "generateContent" in model.get("supportedGenerationMethods", []):
print(f"模型: {model['name']}")
使用正确的API版本也很重要。图片生成功能目前处于Beta阶段,需要使用/v1beta/端点,而不是/v1/。
安全过滤器拦截(内容被阻止)
Google的安全系统有时会对看似无害的提示词做出过度谨慎的判断。官方曾承认过滤器变得"way more cautious than intended"(比预期更加谨慎),导致"dog"(狗)或"bowl of cereal"(一碗麦片)这样简单的提示词也可能被拒绝。
安全过滤器分为两类:
第一类是可调整的过滤器,包括骚扰、仇恨言论、色情内容和危险内容四个类别。你可以通过safetySettings参数调整阻止阈值,将BLOCK_MEDIUM_AND_ABOVE改为BLOCK_ONLY_HIGH或BLOCK_NONE。
hljs pythonsafetySettings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
第二类是不可调整的过滤器,无论如何设置都会生效,包括儿童安全相关内容、恐怖主义内容等。这些属于硬性限制,无法绑过。
常见的误触发情况和解决方法:
当你的提示词包含可能产生歧义的词汇时,添加上下文澄清词往往能解决问题。例如"kill the process"可能触发暴力相关过滤,改为"terminate the software process"就不会有问题。同样,"adult ticket"可能触发色情过滤,改为"museum admission ticket for adults"即可。
检查响应中的finishReason字段可以确认是否触发了安全过滤。如果值为SAFETY,说明内容被阻止;如果是STOP则表示正常完成。
地区限制与网络问题
中国大陆、俄罗斯、伊朗等地区无法直接访问Google服务,包括Gemini API。这是由于Google的服务政策和当地网络环境共同决定的。
如何确认是否受地区限制影响:
如果你收到Gemini isn't currently supported in your country错误,或者请求持续超时无法连接,很可能是地区限制问题。Google通过IP地址判断用户位置,即使你在支持地区注册的API密钥,从受限地区发起的请求仍会被阻止。
三种解决方案对比:
| 方案 | 成功率 | 月成本 | 适用场景 |
|---|---|---|---|
| 官方直连 | 100%(仅限支持地区) | $0.025/次 | 海外服务器部署 |
| VPN代理 | 70-80% | VPN费用+官方价格 | 个人开发测试 |
| API网关服务 | 95%+ | 约$0.05/次 | 生产环境、需要稳定性 |
下图展示了三种方案的详细对比,帮助你根据自身需求选择最合适的方案:
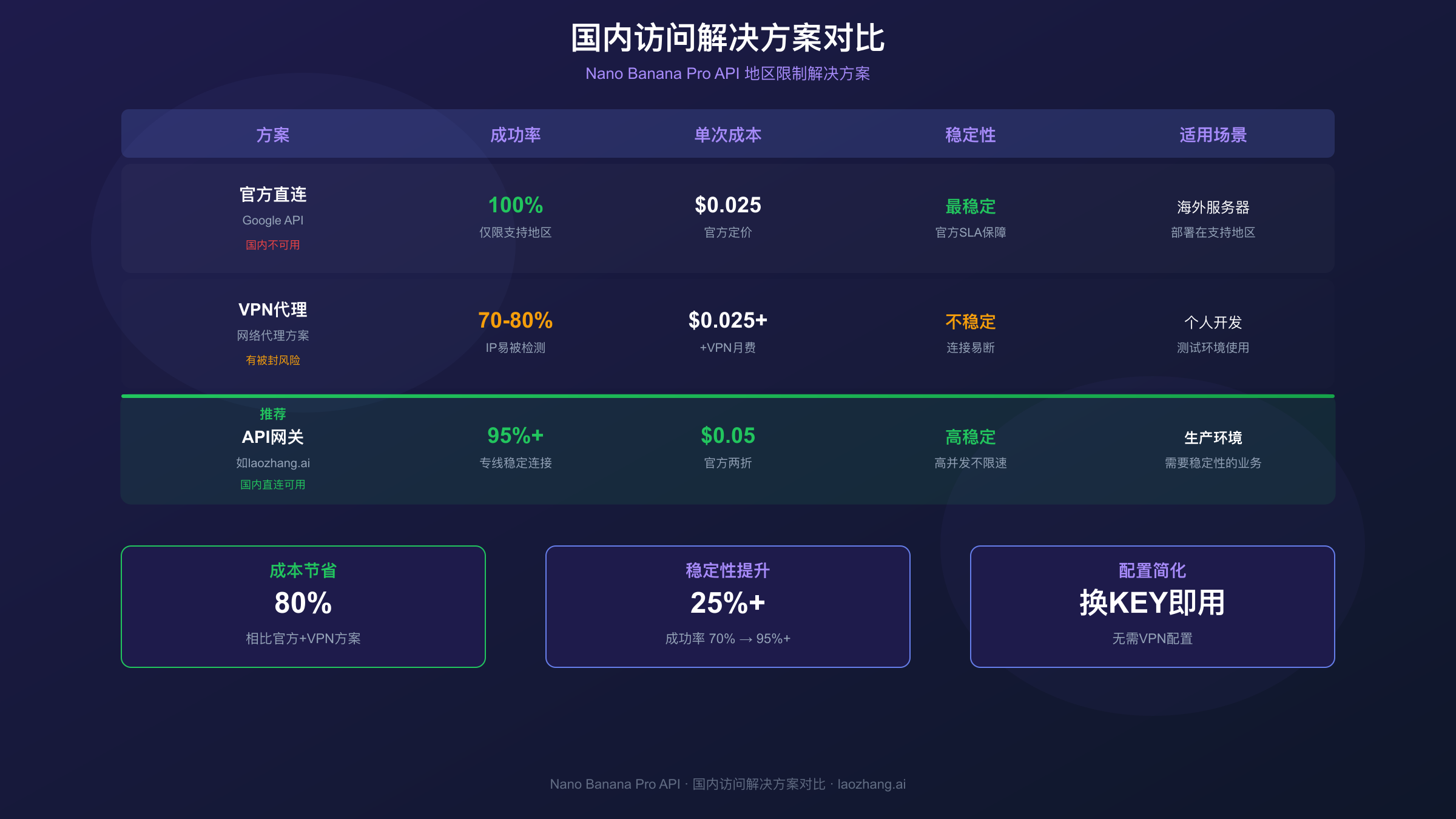
对于需要在生产环境中稳定使用Nano Banana Pro的国内开发者,API网关服务是更实际的选择。以laozhang.ai为例,提供国内直连节点,无需配置代理即可调用,成功率可达95%以上。相比之下,VPN方案容易出现IP被封、连接不稳定等问题,不适合对可用性有要求的业务场景。
更多关于国内访问Gemini API的方案,可以参考Gemini国内访问完整指南。
配额限制与429错误
当你收到429 RESOURCE_EXHAUSTED - Rate limit exceeded错误时,表示已超出API调用配额。
不同用户类型的配额限制:
| 用户类型 | 每日限制 | 每分钟限制 |
|---|---|---|
| 免费用户 | 2-100张(动态调整) | 2-15次 |
| Google AI Pro订阅者 | 1000张 | 60次 |
| Vertex AI付费用户 | 按配额配置 | 按配额配置 |
配额重置时间:API用户的配额在太平洋时间(PT)午夜重置。对于北京时间用户,这大约是下午3点或4点(取决于夏令时)。
如何查看当前配额使用情况:
响应头中会包含配额相关信息。当遇到429错误时,检查Retry-After头可以知道需要等待多久。实现指数退避重试是处理速率限制的最佳实践。
如果业务需要更高的配额,有两个选择:一是通过Google Cloud Console申请配额提升(需要付费账户),二是使用支持高并发的API网关服务。详细的配额管理策略可以参考Gemini API配额超限解决方案。
API密钥与网络超时问题
API密钥被封禁:
Google会主动封禁检测到泄露的API密钥。如果你收到Your API key was reported as leaked错误,需要在Google AI Studio中重新生成密钥。常见的泄露途径包括将密钥提交到公开的GitHub仓库、在前端代码中暴露密钥等。
网络超时问题:
图片生成是计算密集型任务,通常需要10-60秒才能完成。默认的请求超时设置可能不够,建议设置为180秒。
hljs pythonimport requests
response = requests.post(
url,
headers=headers,
json=payload,
timeout=180 # 设置180秒超时
)
服务器端错误(500/503):
这类错误通常是Google服务端的临时问题,实现重试逻辑是最有效的应对方式。使用指数退避策略,避免在服务恢复时产生突发流量。
完整代码示例与最佳实践
以下是一个包含完整错误处理和重试逻辑的生产级代码示例:
hljs pythonimport requests
import base64
import time
from typing import Optional, Dict, Any
class NanoBananaProClient:
"""Nano Banana Pro API客户端,包含完整错误处理"""
def __init__(self, api_key: str, base_url: str = "https://generativelanguage.googleapis.com"):
"""
初始化客户端
Args:
api_key: API密钥
base_url: API基础URL,默认为Google官方地址
国内用户可替换为支持的API网关地址
"""
self.api_key = api_key
self.base_url = base_url
self.endpoint = f"{base_url}/v1beta/models/gemini-3-pro-image-preview:generateContent"
def generate_image(
self,
prompt: str,
aspect_ratio: str = "1:1",
image_size: str = "2K",
max_retries: int = 3
) -> Optional[bytes]:
"""
生成图片
Args:
prompt: 图片描述提示词
aspect_ratio: 宽高比,支持1:1, 16:9, 9:16等
image_size: 图片尺寸,支持2K或4K
max_retries: 最大重试次数
Returns:
图片的二进制数据,失败返回None
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 关键:必须同时指定TEXT和IMAGE
payload = {
"contents": [{
"parts": [{"text": prompt}]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": aspect_ratio,
"imageSize": image_size
}
},
# 放宽安全过滤(可选)
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_ONLY_HIGH"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_ONLY_HIGH"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_ONLY_HIGH"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_ONLY_HIGH"}
]
}
for attempt in range(max_retries):
try:
response = requests.post(
self.endpoint,
headers=headers,
json=payload,
timeout=180
)
# 处理不同的HTTP状态码
if response.status_code == 200:
return self._extract_image(response.json())
elif response.status_code == 429:
# 速率限制,等待后重试
wait_time = int(response.headers.get("Retry-After", 60))
print(f"触发速率限制,等待{wait_time}秒后重试...")
time.sleep(wait_time)
elif response.status_code == 404:
print("模型不存在,请检查模型名称")
return None
elif response.status_code == 403:
print("权限被拒绝,请检查API密钥或地区限制")
return None
else:
print(f"请求失败: {response.status_code} - {response.text}")
except requests.exceptions.Timeout:
print(f"请求超时,第{attempt + 1}次重试...")
except requests.exceptions.ConnectionError:
print(f"连接失败,第{attempt + 1}次重试...")
# 指数退避
if attempt < max_retries - 1:
time.sleep(2 ** attempt)
return None
def _extract_image(self, result: Dict[str, Any]) -> Optional[bytes]:
"""从API响应中提取图片数据"""
try:
candidates = result.get("candidates", [])
if not candidates:
# 检查是否被安全过滤
if result.get("promptFeedback", {}).get("blockReason"):
print(f"提示词被安全过滤: {result['promptFeedback']['blockReason']}")
return None
# 检查完成原因
finish_reason = candidates[0].get("finishReason")
if finish_reason == "SAFETY":
print("内容被安全过滤器阻止")
return None
# 提取图片数据
parts = candidates[0].get("content", {}).get("parts", [])
for part in parts:
if "inlineData" in part:
image_data = part["inlineData"].get("data")
if image_data:
return base64.b64decode(image_data)
print("响应中未找到图片数据")
return None
except (KeyError, IndexError) as e:
print(f"解析响应失败: {e}")
return None
# 使用示例
if __name__ == "__main__":
# 替换为你的API密钥
client = NanoBananaProClient(api_key="your-api-key")
image_data = client.generate_image(
prompt="A cute robot cat in cyberpunk style, highly detailed, 4K quality",
aspect_ratio="1:1",
image_size="4K"
)
if image_data:
with open("output.png", "wb") as f:
f.write(image_data)
print("图片生成成功!")
else:
print("图片生成失败,请检查日志")
最佳实践清单:
- 始终设置
responseModalities: ["TEXT", "IMAGE"] - 使用最新的模型名称,定期检查是否有更新
- 设置足够长的超时时间(建议180秒)
- 实现指数退避重试逻辑
- 检查响应中的
finishReason判断是否被安全过滤 - 妥善保管API密钥,避免泄露
更多API集成技巧请参考Nano Banana Pro API集成完整指南。
常见问题FAQ
为什么有时候返回图片,有时候不返回?
间歇性问题通常有三个原因:一是安全过滤器的判断具有一定随机性,同样的提示词可能有时通过有时被拦截;二是服务端负载波动导致部分请求超时;三是如果使用VPN,IP不稳定可能导致部分请求被地区限制阻止。建议实现重试逻辑,并检查每次失败的具体错误信息。
如何检查API密钥是否有效?
最简单的方法是调用ListModels接口。如果返回200和模型列表,说明密钥有效;如果返回403和"API key was reported as leaked",说明密钥已被封禁,需要重新生成。也可以在Google AI Studio的API Keys页面查看密钥状态。
免费用户每天能生成多少张图片?
免费用户的每日配额是动态的,通常在2-100张之间,取决于当时的服务负载。Google AI Pro订阅用户($19.99/月)可获得每天1000张的配额。如果需要更高配额,可以使用Vertex AI付费服务或第三方API网关服务。
安全过滤器能完全关闭吗?
不能完全关闭。你可以通过safetySettings参数将四个可调整类别设为BLOCK_NONE,但涉及儿童安全、恐怖主义等的不可调整过滤器始终生效。这是Google的强制性安全策略,任何SDK或API网关都无法绑过。
国内使用需要VPN吗?
不一定。有三种方案:第一,将代码部署到海外服务器直接调用官方API;第二,使用VPN(成功率约70-80%,可能遇到IP被封问题);第三,使用支持国内访问的API网关服务(成功率95%+)。对于生产环境,推荐第一或第三种方案,具体选择可参考本文"地区限制与网络问题"章节的详细对比。
总结
Nano Banana Pro API不返回图片的问题看似复杂,但核心原因主要集中在8个方面:responseModalities配置错误、模型名称版本错误、安全过滤器拦截、地区限制、API密钥问题、配额限制、网络超时和响应解析错误。
快速排查建议:
首先检查HTTP状态码,如果是404检查模型名称,403检查密钥和地区,429检查配额。如果状态码是200但无图片,重点检查responseModalities配置和finishReason字段。
对于大多数开发者,确保responseModalities正确设置为["TEXT", "IMAGE"]就能解决问题。如果遇到地区限制或需要稳定的生产环境访问,使用支持国内访问的API网关服务是最实际的解决方案。
遇到具体问题时,可以参考本文对应章节的详细解决方案,或查阅Google官方故障排查文档获取最新信息。