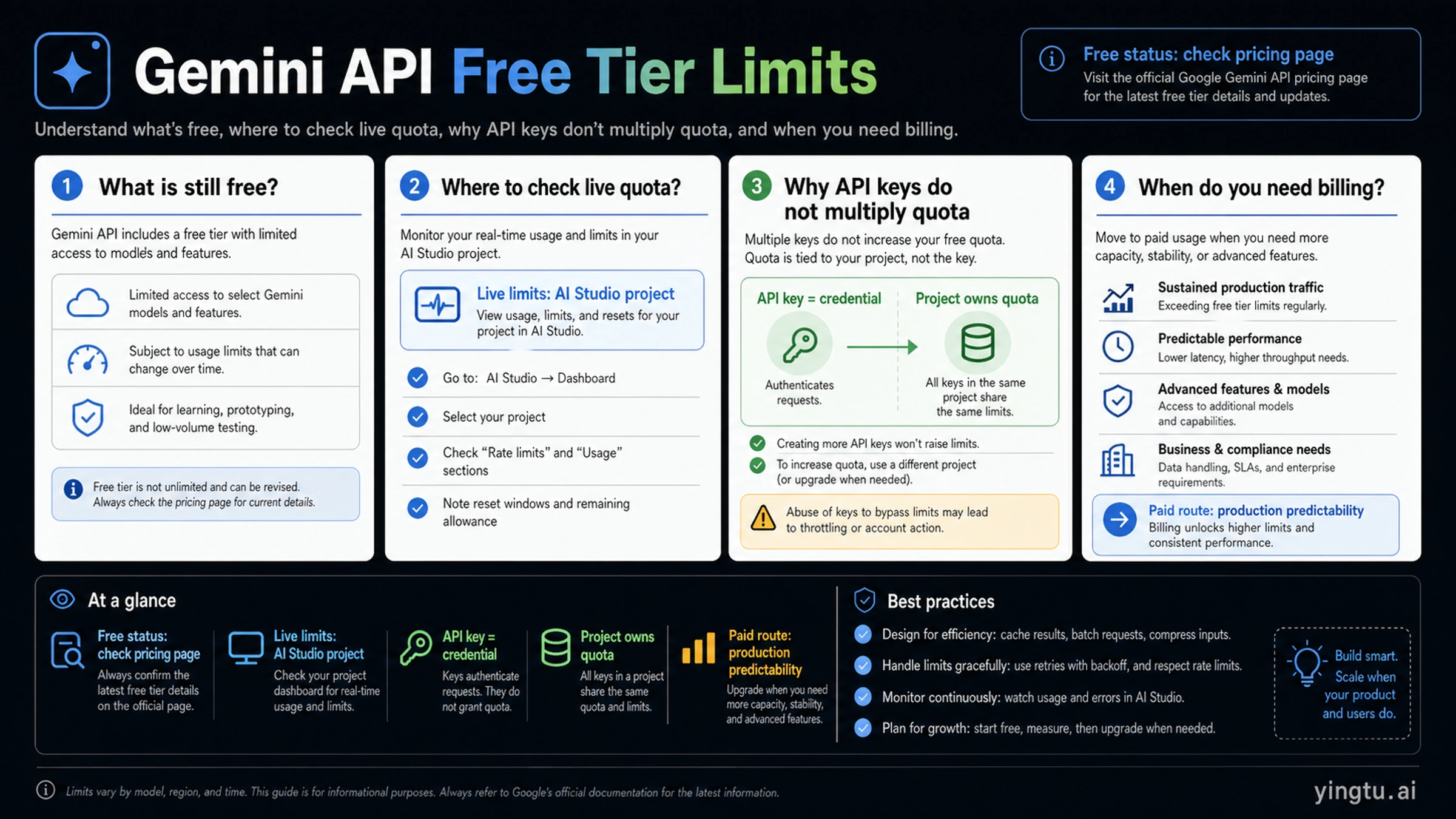
Gemini API still has free-tier access for selected model and surface rows, but the limit you can actually use is not one public number attached to an API key. It is a project-level quota that varies by model, tier, region, and current Google policy.
Checked April 25, 2026, the practical rule is simple: use Google's Gemini API pricing page to confirm whether the model row still has a Free Tier, then open AI Studio for the project behind your key to see the live RPM, TPM, RPD, reset behavior, and usage. Creating more keys inside the same project does not create more free quota; those keys share the same project limits.
If you are prototyping, the free tier can still be useful. If you need predictable production traffic, higher quota, specific data-handling terms, or a model row that is paid-only, move the workload to a billed project instead of trying to stretch the free path.
| Question | Current answer | Source to check |
|---|---|---|
| Is Gemini API still free? | Some model and surface rows still expose Free Tier access. | Google Gemini API pricing page |
| What are my exact limits? | They are project, model, tier, and region specific. | AI Studio project rate-limit view |
| Does each API key get separate quota? | No. Keys authenticate requests; the project owns quota and billing. | API key and billing docs |
| What happens after quota is hit? | Expect 429 or RESOURCE_EXHAUSTED; reduce load, wait for reset, or move to billing. | Rate-limit and troubleshooting docs |
| Should production use the free tier? | Only for very low-risk, low-volume use. Paid projects are safer for production. | Billing, data handling, and usage-tier docs |
What Gemini API free tier limits mean now
The safest way to understand Gemini API free tier limits is to split the phrase into three separate decisions.
First, a model or feature has to be eligible for Free Tier use. That eligibility belongs on Google's pricing surface, not in a blog table. A model that is free for one surface can be paid-only for another surface, and preview or specialized capabilities can move between rows as Google changes product packaging.
Second, quota is measured against a project and a usage tier. Google's rate limits documentation describes RPM, TPM, and RPD as the core dimensions: requests per minute, tokens per minute, and requests per day. Those dimensions still matter, but the public documentation is not a promise that every project sees the same values forever.
Third, the number that matters for your application is the live number attached to the project you are actually using. If the project, model, region, usage tier, or billing state changes, the effective limit can change too. That is why AI Studio is the operating surface for live limits, while the pricing page is the operating surface for model-level free status.
Use static numbers only as historical context. If a spreadsheet, forum answer, or older article gives a universal RPM/RPD table, treat it as a starting clue, not as the current contract for your project.
The source map: pricing, rate limits, API keys, and billing
Each part of the free-tier answer has a different owner.
| Claim you need to verify | Best source | How to use it |
|---|---|---|
| Whether a model or feature has Free Tier access | Gemini API pricing | Look for the current model row and surface. |
| How rate limits are defined | Gemini API rate limits | Confirm RPM, TPM, RPD, usage tiers, and reset behavior. |
| Which project your key belongs to | Gemini API key documentation | Confirm that the key is tied to a project context. |
| What billing changes | Gemini API billing documentation | Understand paid project setup, tier movement, data handling, and credit exclusions. |
| Why a request failed | Gemini API troubleshooting | Map errors such as 429, quota exhaustion, region limits, and billing requirements to the next action. |
This source map matters because most free-tier mistakes come from mixing those owners. A pricing page can tell you whether the model is free, but it does not replace the live project dashboard. A rate-limit page can explain the dimensions, but it does not mean your API key owns a separate quota bucket. Billing docs can explain how to upgrade, but they do not make a free-only project suitable for sensitive production data.
If you only remember one rule, remember this: model free status, project live quota, and billing state are different surfaces.
API key vs project quota
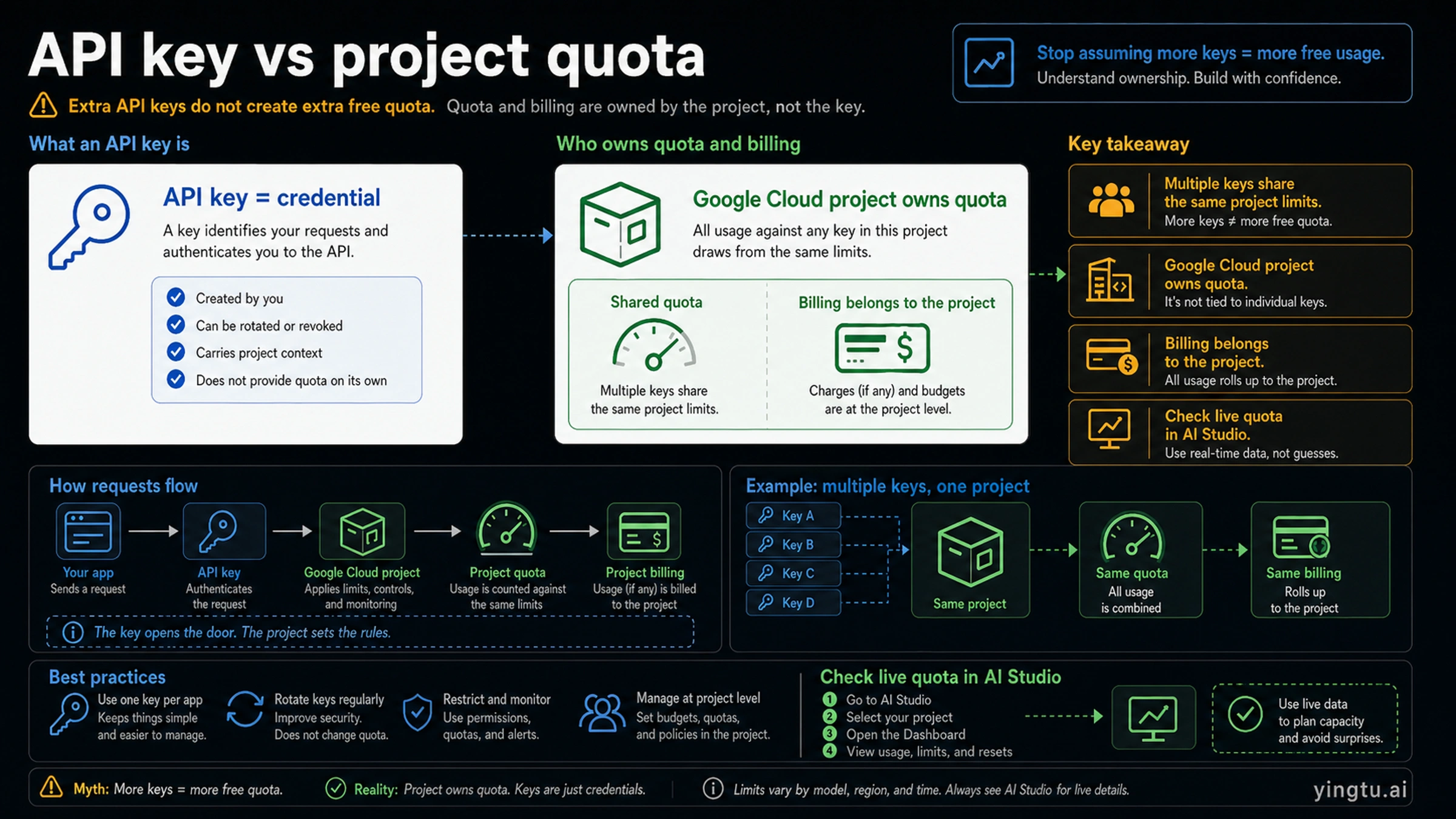
An API key is a credential. It identifies the project context and authenticates your request, but it does not create an independent quota pool.
That distinction changes how you debug free-tier limits. If Key A and Key B are both created inside the same project, they draw from the same project limits. Creating Key C in that same project is useful for rotation, environment separation, or security hygiene, but it is not a quota multiplier.
The project is the unit that matters for quota, billing, usage reporting, and many policy boundaries. That is also why a team should avoid passing loose keys around without knowing which project owns them. A key copied from a teammate's project can behave differently from a key created in your own project, even when both keys appear to call the same model.
Use this quick ownership checklist before you compare limits:
| Check | Why it matters |
|---|---|
| Which Google account created the key? | It helps identify the management surface. |
| Which Google Cloud project is behind the key? | Quota and billing attach to the project. |
| Is billing enabled on that project? | Paid tiers and data handling can change with billing. |
| Which model ID are you calling? | Different rows can have different eligibility and limits. |
| Are you looking at AI Studio for that same project? | A different project dashboard gives the wrong limit. |
Do not try to bypass limits by generating more keys. That can produce confusing usage reports and can create abuse risk without solving the underlying capacity problem. If one project needs more quota, move the workload to a correctly billed and monitored project.
What is still free, and when should you pay?
The free tier is best treated as a development and low-volume testing lane. It can be the right place to learn the API, compare prompts, validate a small prototype, or run occasional internal tools. It is the wrong place to promise reliable throughput to customers unless the application can tolerate throttling, changing limits, and free-tier data handling.
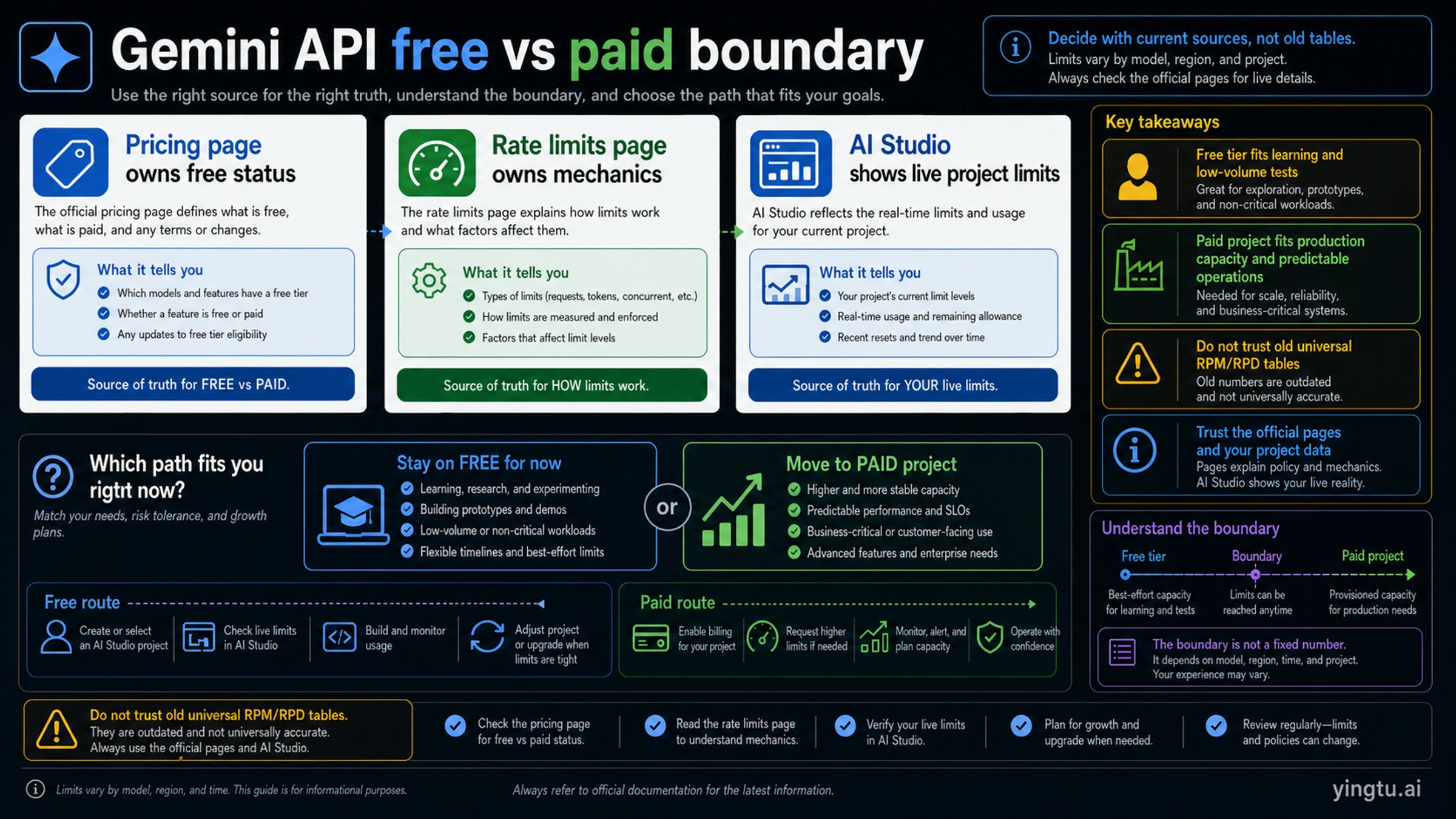
Use this decision table before you build around the free path:
| Workload | Free tier fit | Paid project fit |
|---|---|---|
| Learning the API | Good fit | Usually unnecessary |
| Small prototype with synthetic data | Good fit if usage is low | Useful when testing production-like throughput |
| Internal demo | Good fit if failures are acceptable | Better if stakeholders expect reliability |
| Customer-facing feature | Risky | Usually the correct route |
| Sensitive, regulated, or proprietary data | Avoid free tier unless policy explicitly allows it | Safer because paid terms and data handling differ |
| High-volume batch processing | Poor fit | Use paid tiers or batch-oriented routes where appropriate |
| Paid-only model or feature | Not available on free tier | Required |
Google's billing documentation also matters for budgeting assumptions. New Google Cloud free-trial credits created after March 2026 do not cover Gemini API or AI Studio usage according to the current billing page, so do not design a "free" production plan around generic Cloud credits unless the current billing docs explicitly support that use.
The upgrade threshold is not a moral line. It is an operational line. If free limits are enough for a throwaway test, stay free. If users depend on the result, if the app processes sensitive inputs, if rate-limit errors appear during normal usage, or if the model row you need is not free, turn on billing and monitor spend intentionally.
How to check your live Gemini API free limit
The action path is short, but it needs to be done against the right project.
- Open AI Studio with the Google account that manages the API key.
- Select the project that owns the key used by your application.
- Open the usage or rate-limit view for that project.
- Confirm the model ID your code is calling.
- Record RPM, TPM, RPD, reset behavior, and any tier label shown by the dashboard.
- Re-check before launches, demos, migrations, and traffic changes.
If you are comparing multiple keys, repeat the check by project rather than by key. Two keys inside the same project should be treated as one quota owner. Two projects can have different states, especially if one has billing enabled, different eligibility, or different account history.
For a deeper explanation of the rate-limit dimensions, use the dedicated Gemini API rate limits guide. The short version is enough for most decisions: RPM protects request frequency, TPM protects token throughput, and RPD protects daily volume. Hitting any one of them can stop a request even when the other two look available.
What to do after 429 or RESOURCE_EXHAUSTED
A 429 is not always proof that the free tier is gone. It usually means one rate dimension is exhausted, the wrong project is being checked, the wrong model is being called, or the app is retrying in a way that makes throttling worse.

Use this order:
| Step | Action | Why it comes first |
|---|---|---|
| 1 | Check AI Studio for the project behind the key. | It confirms the live limit owner. |
| 2 | Confirm the model ID and surface. | Paid-only or different model rows can change behavior. |
| 3 | Compare RPM, TPM, and RPD usage. | The exhausted dimension decides the fix. |
| 4 | Add backoff and reduce concurrent requests. | Retrying too fast can extend the problem. |
| 5 | Cache repeated outputs and shorten prompts. | TPM and request volume often fall immediately. |
| 6 | Move to a billed project when normal traffic keeps hitting limits. | Production capacity should not depend on fragile free quota. |
If the error is RESOURCE_EXHAUSTED, treat it as a quota event first. If the error mentions billing, region, unsupported model, or a failed precondition, it may not be solved by waiting. Use Google's troubleshooting page to separate quota exhaustion from account setup, model eligibility, and location restrictions.
The important stop rule is simple: do not create extra keys to evade limits. Fix the workload, verify the project, or upgrade the project.
Free tier design rules that age well
Because free-tier limits can change, design your integration so it survives without a static number.
Use the free tier for measurement, not promises. During development, record real request counts, prompt sizes, token usage, and failure rate. That tells you whether the free tier is enough for the actual workload, not just whether an older table looks generous.
Keep a model fallback plan. If a more capable model is too constrained for frequent calls, route only the hard cases to it and use a faster or cheaper model for simple classification, extraction, and short replies. This is not a trick to bypass limits; it is a way to spend limited quota on the calls that need it.
Cache aggressively when answers can repeat. FAQ bots, classification tools, routing helpers, and internal assistants often send similar prompts many times. Caching can reduce both requests and tokens without changing model quality.
Track errors by dimension. A daily quota problem, a token-throughput problem, and a per-minute concurrency problem need different fixes. Logging only "Gemini failed" is not enough.
Plan the paid path before you need it. A small app can start free, but the production plan should already know which project will be billed, who owns the budget, what alert threshold is acceptable, and which prompts are safe to send under the paid terms.
Common mistakes to avoid
Do not call it a "free API key limit." The key is not the quota owner. Use "project quota" in code comments, runbooks, and internal docs so the team checks the right surface.
Do not copy old RPM/RPD tables into production requirements. A table can help you understand the scale of free access, but AI Studio should own the current operational number.
Do not use consumer Gemini app limits as Gemini API facts. App usage, AI Studio, Gemini API, and Vertex AI can have different contracts.
Do not assume Google Cloud promotional credits cover Gemini API usage. Check the current billing page before you mention credits in a budget plan.
Do not treat the free tier as the safest privacy route because it costs nothing. Free-tier data handling can differ from paid data handling. If prompts contain customer data, business secrets, regulated material, or anything users would not expect to be used for product improvement, verify the paid data terms before sending it.
Decision rule
Stay on the free tier when the workload is low volume, non-sensitive, easy to retry, and still inside the live AI Studio limits for the project behind the key.
Move to a paid project when normal usage repeatedly hits 429, when the app needs predictable throughput, when the required model or feature is not free, when privacy or compliance matters, or when users would experience a real failure if quota changes.
The free tier remains useful, but it is not a production entitlement. Treat it as a live project limit that must be checked, measured, and revisited.
FAQ
Is the Gemini API free tier still available?
Yes, selected Gemini API model and surface rows still have Free Tier access, but the exact availability must be checked on Google's current pricing page. Do not assume every model, preview, image, batch, or specialized route is free.
Where do I check my exact Gemini API free tier limits?
Check AI Studio for the project that owns your API key. The project dashboard is the place to verify live RPM, TPM, RPD, reset behavior, and usage. Public tables are not a substitute for the active project view.
Does every Gemini API key get its own free quota?
No. An API key authenticates requests. The Google Cloud project behind the key owns quota and billing. Multiple keys in the same project share the same project limits.
Can I increase free quota by creating more keys?
No. Creating more keys inside the same project is useful for rotation and environment separation, but it does not multiply quota. If one project needs more capacity, reduce load, change architecture, or move to a paid project.
What does a 429 or RESOURCE_EXHAUSTED error mean?
It usually means a rate-limit dimension has been exhausted. Check the same project's AI Studio usage view, confirm the model ID, then decide whether to wait, reduce concurrency, shorten prompts, cache responses, or add billing.
Are Gemini 3 or Gemini 3.1 models free in the API?
Do not answer that from memory or from a nickname. Check the current Gemini API pricing page for the exact model row and surface. Some model families or previews can be paid-only even when other Gemini rows have Free Tier access.
Can I use the Gemini API free tier for production?
Use it only for very low-risk production where throttling, changing limits, and free-tier data handling are acceptable. Customer-facing, sensitive, high-volume, or reliability-sensitive workloads should use a billed project.
Do Google Cloud free-trial credits cover Gemini API usage?
Google's current billing page says new Google Cloud free-trial credits after March 2026 do not apply to Gemini API or AI Studio. Re-check the billing page before writing any budget assumption around credits.
Are free-tier model outputs lower quality than paid outputs?
The more important difference is not usually model quality; it is quota, feature access, data handling, and operational predictability. Check the pricing and billing docs for the specific model and tier you plan to use.
What should I record before relying on the free tier?
Record the project ID, model ID, usage tier, live RPM/TPM/RPD values from AI Studio, reset behavior, billing state, and the date checked. Re-check those values before launches, demos, and traffic changes.