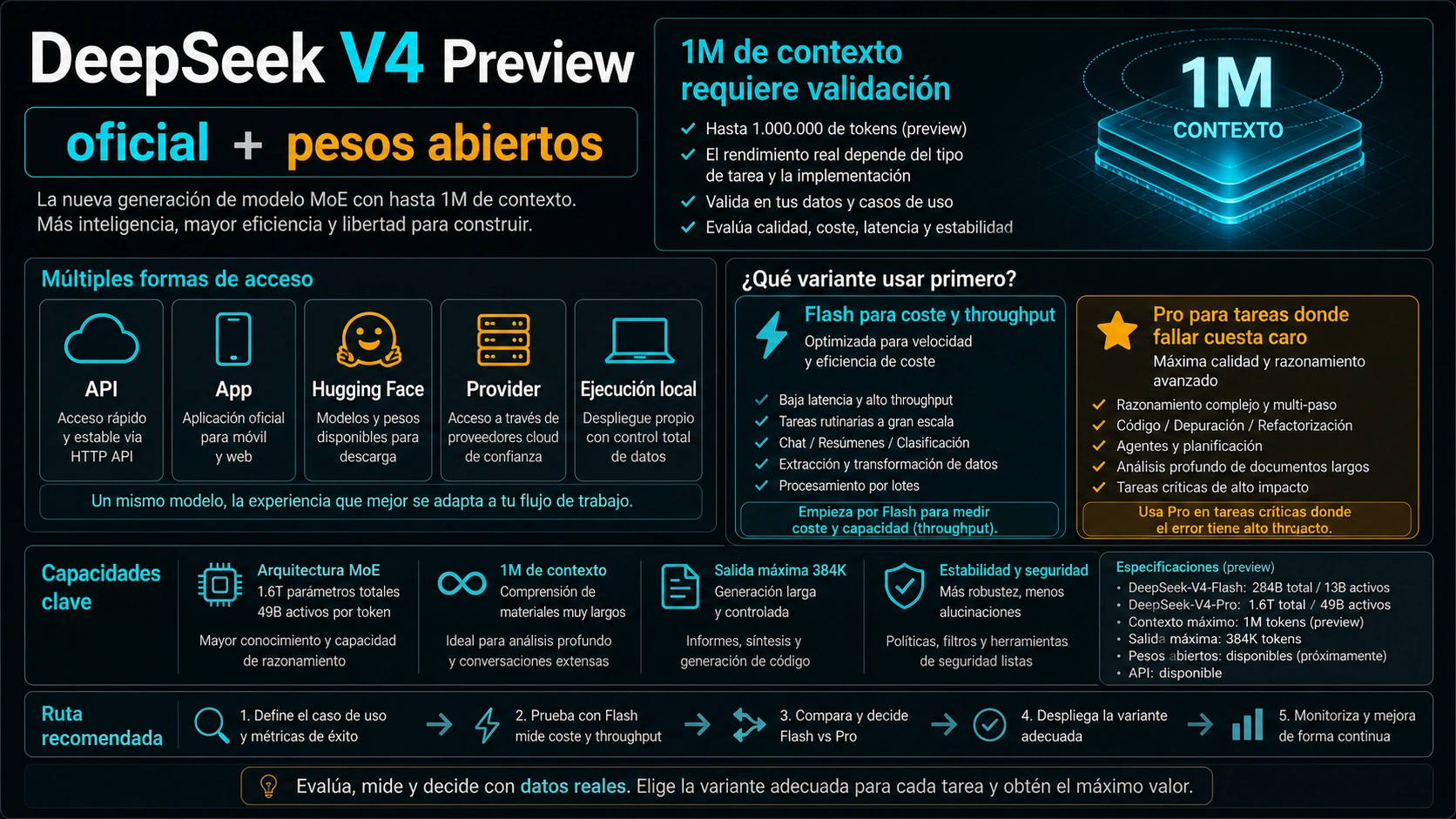
A 8 de mayo de 2026, DeepSeek V4 Preview ya es una ruta oficial, no solo un nombre que circula en redes. DeepSeek publicó la release del 24 de abril, documenta los model ID deepseek-v4-pro y deepseek-v4-flash, y mantiene pesos verificados en Hugging Face. La decisión práctica no es repetir que existe V4, sino decidir qué ruta prueba tu equipo primero.
| Ruta | Cuándo empezar aquí | Qué validar antes de producción |
|---|---|---|
| Chat o App | Quieres tocar el comportamiento rápido | límites de superficie, privacidad, si el resultado se replica en API |
| API oficial | Necesitas contrato hosted de DeepSeek | model ID, contexto 1M, max output 384K, precio con fecha, streaming, thinking mode |
| Hugging Face | Necesitas pesos abiertos o control local | hardware, serving stack, licencia, recall, latencia, diferencia frente a API hosted |
| Provider | Ya compras por gateway o ruta regional | precio, cuota, logs, fallback, frescura del modelo y soporte del provider |
| Ejecución local | Necesitas control máximo u offline-sensitive pilot | GPU, memoria, KV cache, observabilidad, mantenimiento y evaluación |
La primera regla es operativa. Si la tarea es masiva, medible, barata de revisar y sensible a latencia, prueba deepseek-v4-flash. Si la tarea exige razonamiento difícil, código, agentes, síntesis de documentos largos o revisión humana cara, prueba deepseek-v4-pro. No uses deepseek-v4-preview como model ID y no trates el contexto 1M como garantía de recall perfecto.
Qué confirma la release oficial
La release de DeepSeek del 24 de abril de 2026 dice que V4 Preview está oficialmente disponible y open-sourced. Presenta DeepSeek-V4-Pro y DeepSeek-V4-Flash. Pro aparece como un MoE de 1.6T parámetros totales y 49B activos; Flash aparece como 284B totales y 13B activos. Ambos se asocian con contexto 1M y modos thinking / non-thinking.
Eso fija el borde factual, pero no decide la arquitectura. Es fácil mezclar resumen automático, vídeos, medios, providers y Hugging Face como si fueran una sola fuente de verdad. Para implementar, conviene separar cuatro propietarios: DeepSeek para API oficial y release, Hugging Face para pesos y licencia, providers para su contrato propio, y tu infraestructura para ejecución local.
Si tu equipo ya usa DeepSeek, el primer paso no es reescribir todos los prompts. Primero inventaría el route owner: qué servicio llama a la API oficial, cuál pasa por gateway, dónde quedan deepseek-chat o deepseek-reasoner, y qué pruebas son locales. Sin ese mapa, cambiar el model ID puede ocultar cambios de precio, logging, fallback, soporte o comportamiento de cuota.
La diferencia Pro/Flash debe convertirse en una regla de ensayo. Flash no es solo una versión barata; es la ruta que permite medir más muestras cuando el error se detecta pronto. Pro no es solo una versión premium; es la ruta que puede reducir retrabajo cuando una mala respuesta consume tiempo humano.
Flash o Pro: primera prueba
Flash debe entrar primero en clasificación, extracción, routing, resumen masivo, salida estructurada, screening documental y trabajos donde una schema, un conjunto de tests o una cola de revisión detecta errores. Si Flash pasa el mismo listón de aceptación, el menor coste permite más validación y más capacidad de retry.

Pro debe entrar primero cuando el fallo cuesta caro: coding agents, depuración multiarchivo, decisiones de arquitectura, workflows con herramientas, documentos largos con conflictos, síntesis legal o técnica, y tareas donde revisar manualmente pesa más que los tokens. La comparación correcta es accepted-output cost, no solo precio por millón de tokens.
| Carga | Primer modelo | Motivo |
|---|---|---|
| Clasificación masiva | deepseek-v4-flash | fácil de validar y repetir |
| Resumen con control de calidad | deepseek-v4-flash | throughput y coste pesan más |
| Agente de código | deepseek-v4-pro | un fallo consume tiempo de ingeniería |
| Síntesis de documentos largos | Flash para lo fácil, Pro para lo difícil | no todo debe pagar el coste Pro |
| Tool calling | comparar ambos con el mismo schema | la disciplina de argumentos depende de la tarea |
API ID, alias antiguos y configuración
El código nuevo debe usar deepseek-v4-pro o deepseek-v4-flash. La release también explica que deepseek-chat y deepseek-reasoner son compatibility aliases y que quedarán inaccesibles después del 2026-07-24 15:59 UTC. Pueden ayudar a clientes antiguos, pero no son el nombre correcto para nueva configuración productiva.

Para clientes OpenAI-compatible, el base URL oficial de DeepSeek es https://api.deepseek.com. Ese dato no prueba el contrato de ningún provider. En configuración conviene separar model ID, route owner, fecha de precio, streaming, tools, JSON, thinking mode y rollback plan.
hljs tsimport OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: "https://api.deepseek.com",
});
const response = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [{ role: "user", content: "Summarize the document and cite evidence lines." }],
stream: true,
max_tokens: 4096,
});
Precio y descuento con fecha
La tabla oficial de DeepSeek, revisada el 8 de mayo de 2026, muestra para deepseek-v4-flash cache hit input de $0.0028, cache miss input de $0.14 y output de $0.28 por 1M tokens. Para deepseek-v4-pro, la fila con descuento muestra $0.003625, $0.435 y $0.87; la fila original muestra $0.0145, $1.74 y $3.48. DeepSeek indica que el descuento del 75% para V4-Pro se extiende hasta el 2026-05-31 15:59 UTC.
Estos números son volátiles. Un provider puede añadir margen, crédito, bundle, ruta regional, fallback, logging, límite o soporte propio. Una página de provider prueba solo ese contrato. Para claims de la API oficial, usa documentos de DeepSeek y coloca la fecha de revisión cerca de la cifra.
Cómo validar el contexto 1M
El contexto 1M significa que la ruta puede aceptar entradas largas; no significa que todas las respuestas largas sean correctas. Hay que medir recall de hechos lejanos, razonamiento entre secciones, conflictos, latencia, timeouts, max output 384K, coste tras retries y estabilidad de la ruta durante el periodo Preview.

| Prueba | Qué demuestra | Señal de fallo |
|---|---|---|
| Aceptación de entrada | admite el tamaño objetivo | rechazo, truncado, timeout |
| Recall lejano | recupera hechos de inicio, medio y final | cita solo el inicio |
| Razonamiento cruzado | combina evidencias distantes | ignora conflictos |
| Latencia | cabe en el SLA | p95 o timeout alto |
| Salida | max output 384K no rompe el flujo | respuesta cortada o excesiva |
| Estabilidad | Preview/provider no cambia la tarea | drift al cambiar ruta |
Pesos abiertos, providers y local
La colección verificada de DeepSeek en Hugging Face incluye Pro, Pro-Base, Flash y Flash-Base. Las model cards describen la Preview series, el split MoE, el contexto 1M, los thinking modes y la licencia MIT. Eso prueba disponibilidad de pesos abiertos, no que tu endpoint local se comporte como la API oficial.
Ejecutar localmente significa asumir runtime ownership: GPU, memoria, KV cache, serving stack, batching, observabilidad, seguridad, actualizaciones y evaluación. Usar un provider también cambia de dueño contractual. Si pasas de API oficial a provider o local, repite el mismo evaluation suite antes de asumir equivalencia.
Para local no conviene empezar directamente con 1M completo. Construye una escalera: 32K, 128K, 256K y después documentos más largos. En cada escalón registra memoria, p95 latency, recall lejano, tasa de salida aceptada y retries. Así separas el límite del modelo del límite de tu serving stack.
Cuándo usar la comparación con GPT
Cuando la decisión sigue dentro de DeepSeek V4 Preview, basta con resolver estado oficial, ID, Flash/Pro, contexto 1M, pesos, provider y local. Si la decisión real es OpenAI frente a DeepSeek, usa la comparación hermana GPT-5.5 vs DeepSeek-V4. Esa ruta resuelve un trabajo distinto: elección entre proveedores y límites.
Checklist de producción
- fija
deepseek-v4-flashodeepseek-v4-proen config; - registra si la ruta es API oficial, provider, Hugging Face o local;
- usa el mismo prompt/eval set en Flash y Pro;
- añade pruebas de recall lejano si 1M context motivó el cambio;
- mide accepted-output cost, no solo precio token;
- prueba streaming, JSON, tools y thinking mode solo donde la app los use;
- busca clientes antiguos con
deepseek-chatydeepseek-reasonerantes del retirement; - revisa precios, descuentos, provider terms y disponibilidad antes de claims públicos.
El paquete mínimo de evaluación debería tener tres capas. La regresión corta detecta cambios de modelo o provider. La capa de documentos largos mide lost-middle, recall lejano y cortes de salida. La capa de alto coste de fallo decide si una tarea puede quedarse en Flash o debe subir a Pro. Con esa separación, el periodo Preview se vuelve medible en lugar de depender de impresiones sueltas.
FAQ
¿DeepSeek V4 Preview es oficial?
Sí. La release de DeepSeek del 24 de abril de 2026 dice que V4 Preview está oficialmente disponible y open-sourced, y la documentación API lista model IDs V4. Mantén la etiqueta Preview porque precios, alias y comportamiento pueden cambiar.
¿Qué model ID debo usar en la API?
Usa deepseek-v4-pro o deepseek-v4-flash. No uses deepseek-v4-preview. deepseek-chat y deepseek-reasoner son compatibility aliases con retirada prevista después del 2026-07-24 15:59 UTC.
¿Flash o Pro primero?
Flash primero para tareas masivas, medibles, baratas de revisar y sensibles a latencia. Pro primero para razonamiento difícil, código, agentes, síntesis larga y trabajos donde corregir fallos cuesta caro.
¿El contexto 1M está listo para producción?
No automáticamente. Las fuentes oficiales respaldan la capacidad, pero producción exige pruebas de recall, latencia, coste, max output 384K, límites de provider y estabilidad de Preview.
¿Los pesos de DeepSeek V4 son abiertos?
La colección verificada de DeepSeek en Hugging Face incluye Pro, Pro-Base, Flash y Flash-Base, con model cards bajo licencia MIT. Eso no garantiza rendimiento local de producción.
¿OpenRouter u otro provider es API oficial?
No. Es un contrato de provider con precio, routing, fallback, logs, quota y soporte propios. Para first-party claims usa docs de DeepSeek.
¿Puedo correr 1M context localmente?
Puedes evaluarlo, pero depende de GPU, memoria, serving stack, latencia, recall y accepted-output cost. Empieza con una escalera de contexto antes de intentar 1M completo.