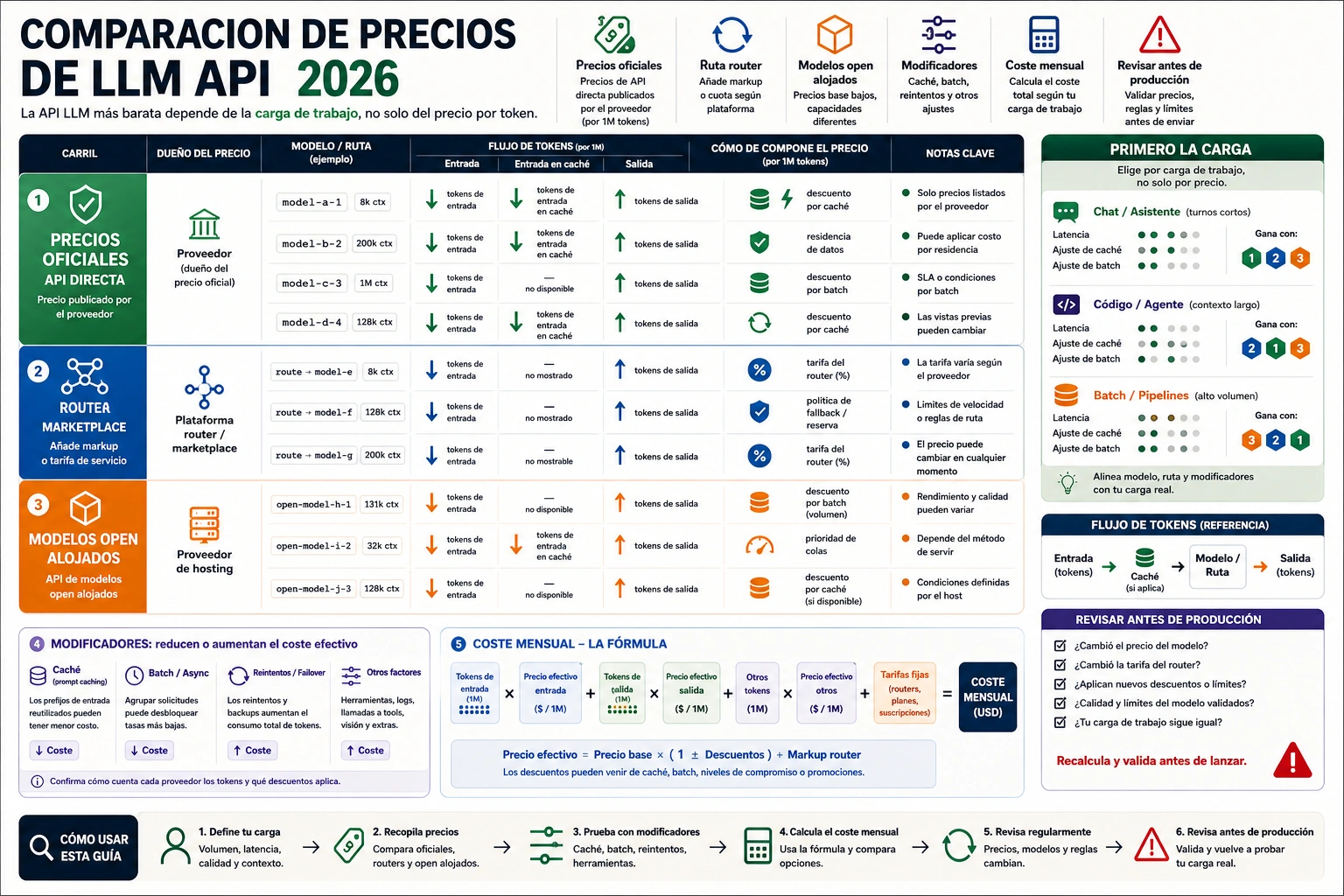
A 2 de julio de 2026, la API LLM más barata es la ruta que completa su workload al menor coste por resultado aceptado, no el modelo con menor precio de input token. Hay que sumar input, cached input, output, tool/search fees, router fee, retry overhead y coste de revisión. Una tabla o calculadora no basta para mover tráfico real. Hace falta saber quién posee cada precio, qué ruta de llamada cubre, cuándo se revisó, qué unidad usa y qué condiciones cambian la factura. Separar API directa oficial, hosted open-model serving y router economics evita comparar contratos distintos como si fueran la misma factura.
| Carril de precio | Úselo para | Cómo leer la evidencia actual |
|---|---|---|
| API directa oficial | Soporte, facturación, ruta de datos y términos del modelo del provider | OpenAI, Anthropic, Gemini, DeepSeek, Mistral y xAI solo poseen sus propias filas directas. |
| Hosted open-model API | Servir modelos open-weight sin operar GPUs propias | Groq-hosted GPT OSS, Llama y Qwen son precios de Groq route, no precios oficiales del autor del modelo. |
| Router o marketplace | Una cuenta para switching, fallback o comparación de providers | OpenRouter-style rows son router economics: platform fee, request limits y routing behavior importan junto al token price. |
Empiece con esta fórmula:
monthly API cost = uncached input + cached input + output + route/tool/search/request fees + retry overhead - batch/cache savings
Bulk extraction, support chatbot, coding agent, long-context analysis, regulated workflow y offline batch pueden tener ganadores distintos. Antes de mover tráfico, revalide availability, preview labels, cache/batch discounts, free tier, data residency uplift, router fees y deprecations.
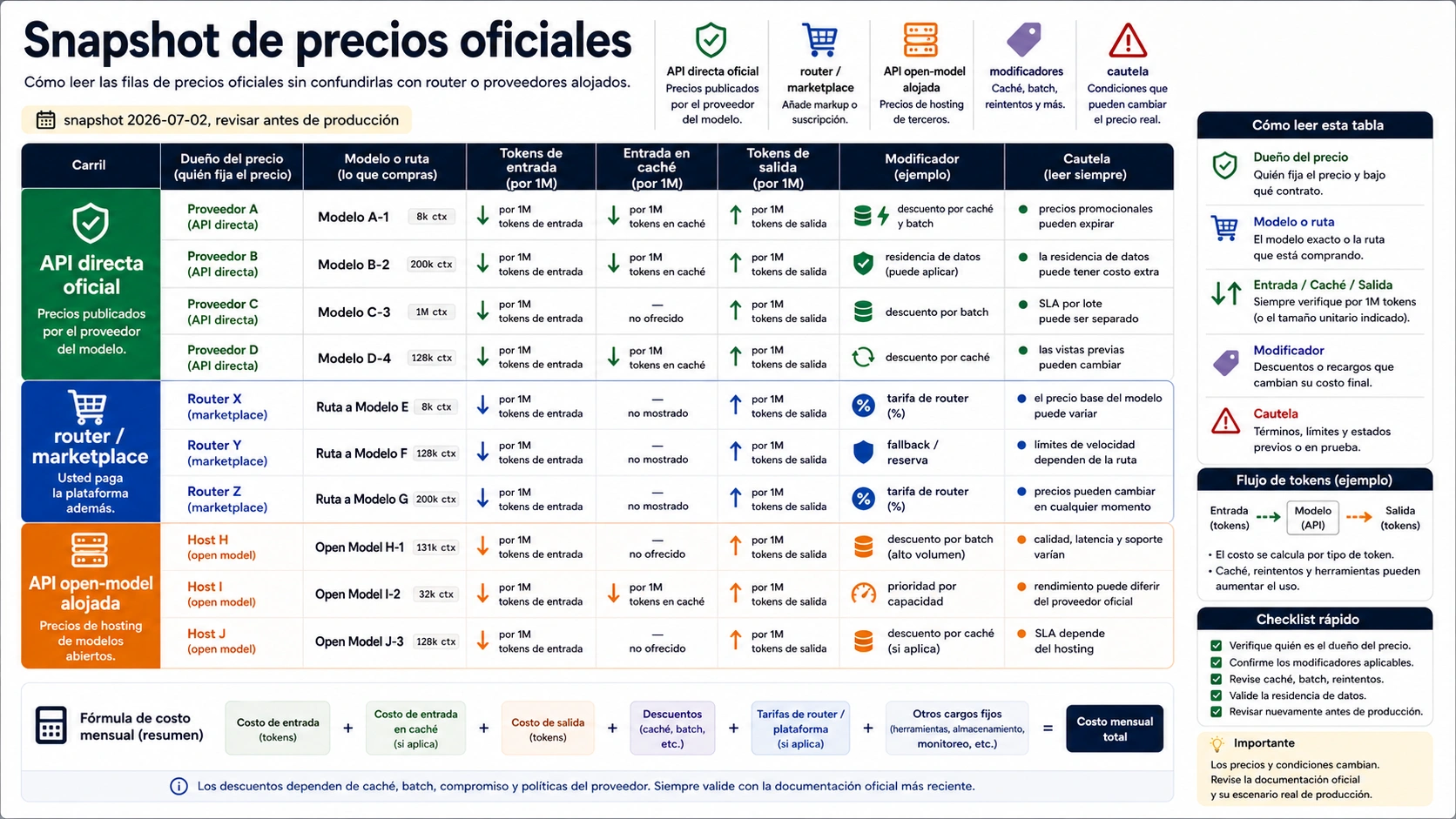
Snapshot de precios oficiales directos
La tabla es un punto de partida fechado, no un ranking permanente. Los precios son USD por 1M tokens salvo indicación distinta. Input, cached input y output van separados porque las apps output-heavy cambian el resultado.
| Owner y ruta | Fila revisada el 2026-07-02 | Input | Cached input | Output | Caveat |
|---|---|---|---|---|---|
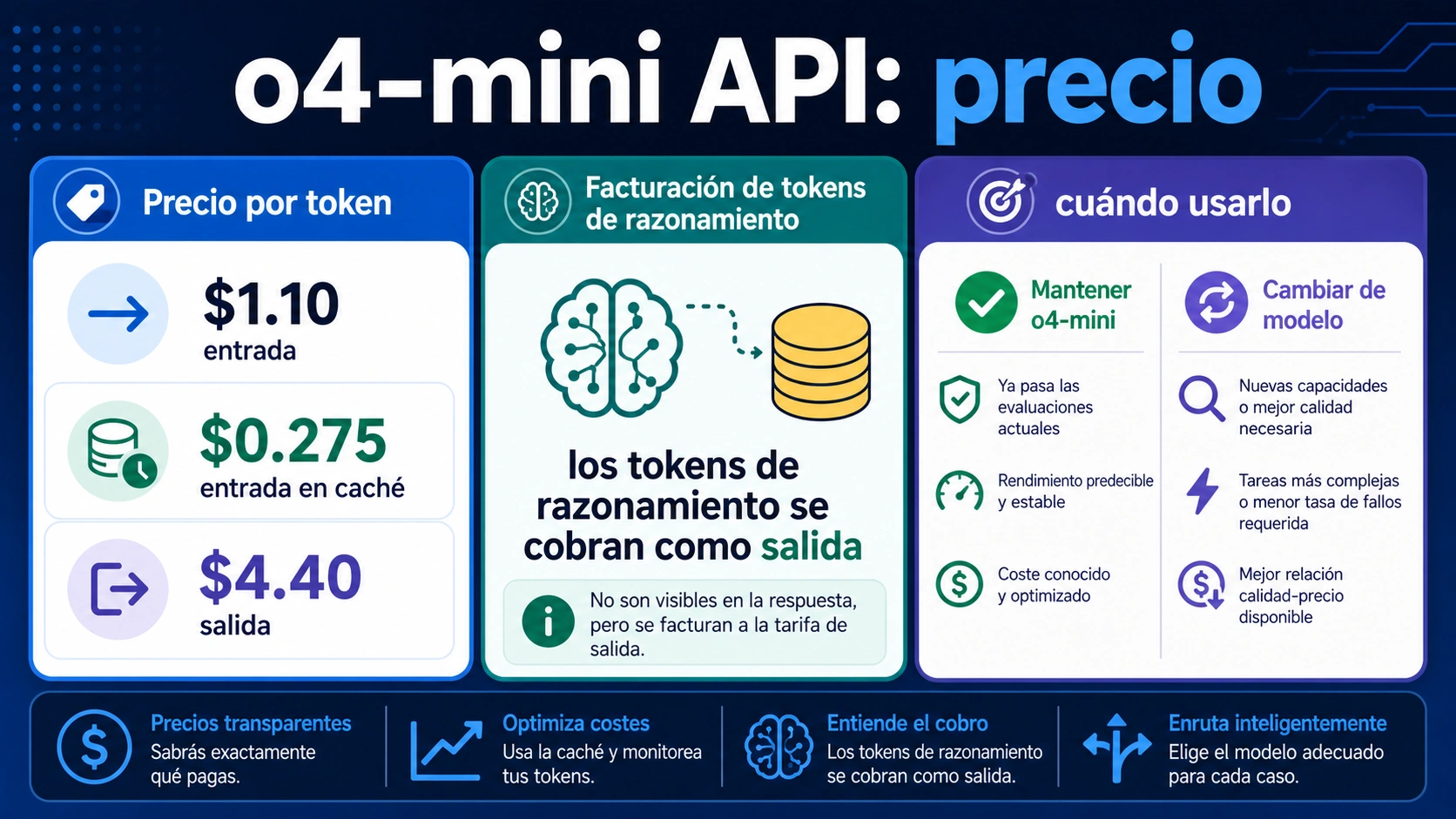
| API directa de OpenAI, Standard | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Standard, Batch, Flex y Priority son contratos distintos; algunos endpoints regionales pueden sumar recargo de residencia de datos. |
| API directa de OpenAI, Standard | gpt-5.4-mini | $0.75 | $0.075 | $4.50 | Buena fila candidata para tareas OpenAI de menor coste, no un ganador universal. |
| API directa de OpenAI, Standard | gpt-5.5 | $5.00 | $0.50 | $30.00 | Solo entra si la calidad justifica el salto, porque el coste de salida domina. |
| API directa de Anthropic | Claude Sonnet 5 intro row | $2.00 | según ruta de caché | $10.00 | El precio introductorio llega hasta 2026-08-31; después pasa a $3.00 input y $15.00 output. |
| API directa de Anthropic | Claude Haiku 4.5 | $1.00 | según ruta de caché | $5.00 | Cache writes, cache hits, Batch, Fast mode y data residency cambian la factura. |
| Google Gemini Developer API | gemini-3.1-flash-lite, Paid Tier Standard | $0.25 text/image/video, $0.50 audio | $0.025 text/image/video, $0.05 audio | $1.50 | El Free Tier sirve para explorar; producción debe presupuestarse con proyecto paid y términos de datos. |
| Google Gemini Developer API | gemini-3.5-flash, Paid Tier Standard | $1.50 | $0.15 | $9.00 | Grounding con Google Search o Maps puede añadir query fees después del cupo incluido. |
| Google Gemini Developer API | gemini-3.1-pro-preview, Paid Tier Standard | $2.00 <= 200k, $4.00 > 200k | $0.20 <= 200k, $0.40 > 200k | $12.00 <= 200k, $18.00 > 200k | La longitud del prompt cambia el tramo y el estado preview debe revisarse. |
| API directa de DeepSeek | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | deepseek-chat y deepseek-reasoner se asignan a modos V4 Flash y tienen deprecation prevista el 2026-07-24. |
| API directa de DeepSeek | deepseek-v4-pro | $0.435 cache miss | $0.003625 cache hit | $0.87 | La página oficial también lista contexto 1M; pruebe latencia y calidad antes de migrar tráfico. |
| precios de Mistral | Mistral Large example | $2.00 | no listado en public FAQ | $6.00 | Mistral cuenta input y output tokens y Batch tiene 50% discount. |
| Docs de modelos xAI | Grok 4.3 | $1.25 | no listado | $2.50 | Para coding mire Grok Build 0.1; voz, imagen y video usan otras unidades. |
Hosted open-model APIs y routers pueden ser más baratos, pero son contratos distintos:
| Route owner | Fila o contrato | Señal de precio | Uso correcto |
|---|---|---|---|
| precios de Groq | openai/gpt-oss-20b hosted by Groq | $0.075 uncached input, $0.0375 cached input, $0.30 output | Precio de serving de GroqCloud, no precio oficial del autor del modelo. |
| precios de Groq | openai/gpt-oss-120b hosted by Groq | $0.15 uncached input, $0.075 cached input, $0.60 output | Buen primer test barato para open-model workloads si calidad y latencia pasan. |
| precios de OpenRouter | Pay-as-you-go plan | 5.5% platform fee, 400+ models, 70+ providers | Contrato de router, no precio oficial de los providers subyacentes. |
| precios de OpenRouter | Free plan | 50 requests/day, free-model access | Sirve para exploración, no para producción. |
Si su modelo no aparece, vuelva a la página owner y añada model ID, ruta, unidad, fecha de revisión y caveat antes de estimar.
La opción barata cambia por workload
Un modelo barato gana solo si completa el mismo job con calidad aceptable y retry rate razonable. El primer shortlist debe ser workload-based.
| Workload | Empiece probando | Por qué puede ser barato | Regla de parada |
|---|---|---|---|
| Bulk extraction, classification, normalization | DeepSeek V4 Flash, Gemini 3.1 Flash-Lite, Groq GPT OSS 20B, OpenAI GPT-5.4-nano | Low input/output rows importan porque la calidad suele medirse con labels o validators. | No llevar a producción hasta contar false positives, retries y human review. |
| Support chatbot y FAQ | Gemini 3.1 Flash-Lite, OpenAI GPT-5.4-mini/nano, Claude Haiku 4.5, DeepSeek V4 Pro | Output ratio medio y cached policy context pueden ayudar. | Si baja la calidad de escalation, la ruta barata no es la más barata. |
| Coding assistant o agentic tool use | Claude Sonnet 5, OpenAI GPT-5.4/GPT-5.5, xAI Grok Build, Gemini 3.5 Flash | Los fallos generan retries y developer time cost. | Exija same-repo evals, tool-call success y rollback cost. |
| Long-context analysis | Gemini Pro/Flash long-context, DeepSeek V4 1M context, Grok 4.3 | Una llamada grande puede ser más barata que chunking + retrieval. | Recalcule al cruzar context tier o cache storage. |
| Regulated o enterprise workflows | Direct provider API o contracted cloud route | Billing, data handling, audit logs y support pueden pesar más que token row. | No elija router solo porque la fila sea más baja. |
| Offline batch | OpenAI Batch, Google Batch, Mistral Batch, Groq Batch | Asynchronous workloads suelen tener descuento. | Batch no es ruta de baja latencia; revise completion window y output retrieval. |

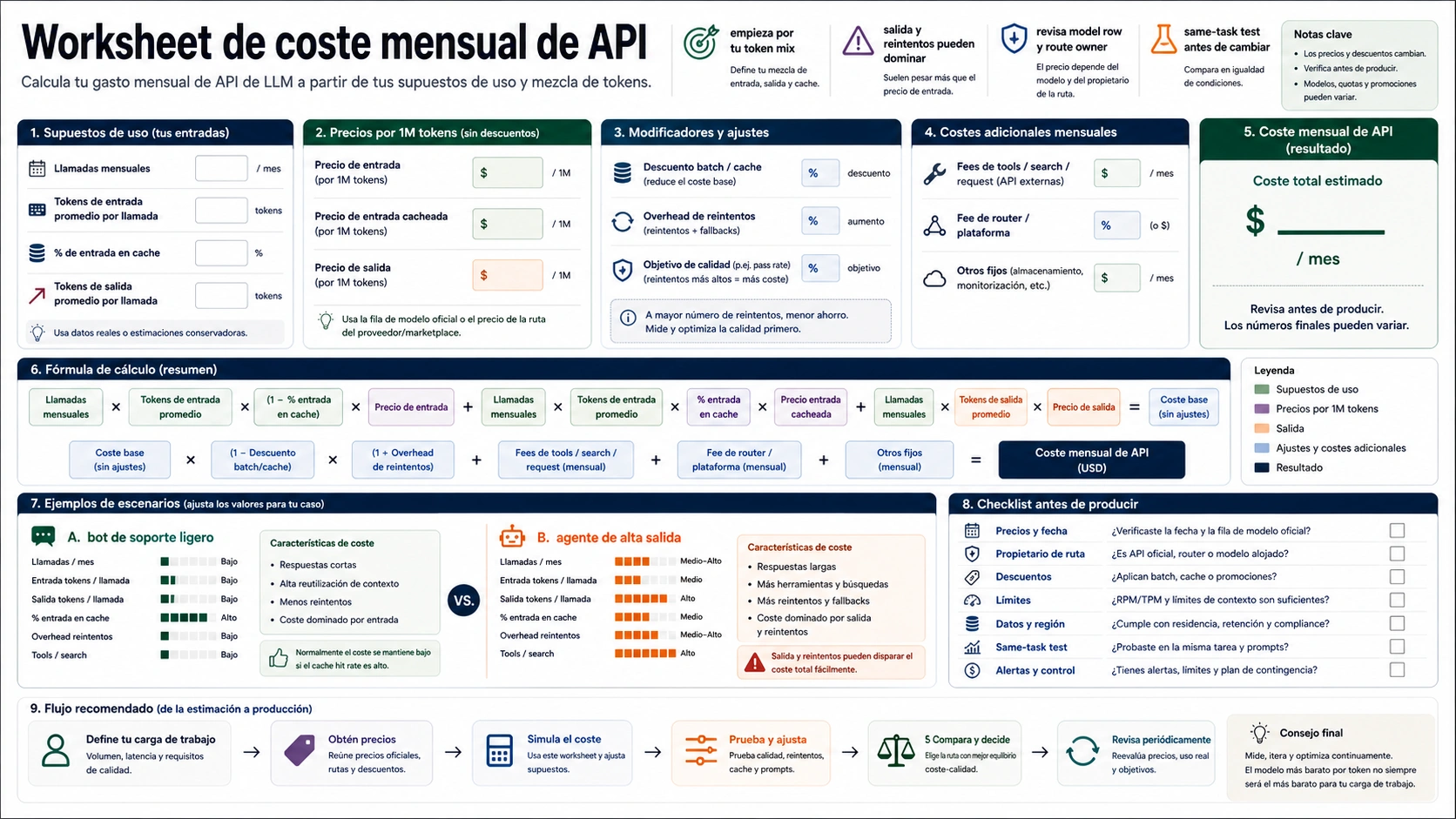
Worksheet de coste mensual
La factura real empieza con su token mix. Estime cada candidato con la misma forma de workload.
- Monthly uncached input tokens.
- Monthly cached input tokens o cache-hit rate.
- Monthly output tokens, incluyendo reasoning/thinking tokens si el provider los factura como output.
- Tool, search, request, route o platform fees.
- Retry and fallback overhead.
- Batch/cache savings.
- Human-review o failure cost cuando el output no pasa.
| Scenario | Candidate route | Token mix | Simple monthly token cost | Interpretation |
|---|---|---|---|---|
| Bulk data cleanup | Groq GPT OSS 20B | 100M input, 10M output | $10.50 | Muy barato si el hosted open model pasa validation. |
| Bulk data cleanup | DeepSeek V4 Flash | 100M cache-miss input, 10M output | $16.80 | Fila directa baja, pero hay que probar calidad y latency. |
| Bulk data cleanup | OpenAI GPT-5.4-nano | 100M input, 10M output | $32.50 | Puede valer si OpenAI compatibility o output quality importan. |
| Bulk data cleanup | Gemini 3.1 Flash-Lite | 100M text input, 10M output | $40.00 | Cache o Batch pueden mejorar, pero Free Tier no es producción. |
| Output-heavy chatbot | Groq GPT OSS 20B | 20M input, 20M output | $7.50 | Output barato, con prueba de calidad open-model. |
| Output-heavy chatbot | DeepSeek V4 Flash | 20M cache-miss input, 20M output | $8.40 | Output bajo; mida hallucination y escalation cost. |
| Output-heavy chatbot | OpenAI GPT-5.4-nano | 20M input, 20M output | $29.00 | Output domina; úselo si la calidad supera rutas baratas. |
| Output-heavy chatbot | Gemini 3.1 Flash-Lite | 20M text input, 20M output | $35.00 | Interesante si Gemini ecosystem fit reduce retries. |
Añada modifiers reales. Si 40% de un system prompt repetido en OpenAI GPT-5.4-nano se convierte en cached input, esa parte baja de $0.20/M a $0.02/M. Si Gemini 3.1 Flash-Lite corre con Batch, input baja de $0.25/M a $0.125/M y output de $1.50/M a $0.75/M. Si OpenRouter cobra 5.5%, multiplique por 1.055 antes de comparar con billing directo.
Cierre con coste por tarea aceptada:
price per completed task = total monthly route cost / accepted task count
Si una ruta barata completa 94% de tareas y otra más cara 99.5%, la diferencia se convierte en retries, fallbacks, manual review, tickets o output perdido.
API directa, router, hosted open model o self-host
API directa y router resuelven problemas distintos de ownership. Direct provider API es más limpia cuando necesita soporte oficial, billing clarity, data route, enterprise controls e incident diagnosis.
Routers sirven para model switching, fallback, traffic comparison o single integration. OpenRouter's 5.5% fee, free limits y routing behavior entran en la cost model.
Hosted open-model APIs están entre ambos mundos. Groq owns serving price, limits, latency y roster. El label openai/gpt-oss no lo convierte en OpenAI official API price.
Self-hosting solo entra si volume, data locality, hardware access y operations capacity lo justifican. Free weights esconden GPU utilization, serving, monitoring y on-call.
Factores que rompen una tabla simple
Output ratio es la primera trampa. Un chatbot o report generator puede gastar más en output que input.
Caching es la segunda. OpenAI, Google, Anthropic, DeepSeek y Groq tienen semantics y rows distintos.
Batch es la tercera. Es para extraction, eval generation y enrichment offline, no para realtime chat.
Tool/search fees son la cuarta. Web search, Google Grounding, compound tools y router features pueden ser gran parte de la factura.
Preview, intro y tier thresholds son la quinta. Sonnet intro tiene fecha final, Gemini Pro Preview cambia por prompt length y DeepSeek aliases tienen deprecation.
Retry overhead no es opcional. Si la ruta barata necesita 1.3 attempts por respuesta aceptada, calcule 1.3 attempts.
Notas por provider
OpenAI pricing page owns OpenAI direct API token rows y separa Standard, Batch, Flex y Priority.
Anthropic pricing page owns Claude direct rows y cache, Batch, Fast mode, data residency modifiers. Para API vs subscription vea Claude API pricing versus subscription.
Google Gemini pricing owns Developer API rows, Free Tier, Batch y grounding fees. Para free quota vea Gemini API free tier.
DeepSeek pricing now presents deepseek-v4-flash and deepseek-v4-pro; legacy chat/reasoner names map to V4 Flash.
Mistral permite citar Mistral Large example y 50% Batch discount; no invente otras rows.
xAI docs point chat to Grok 4.3 and coding to Grok Build 0.1; voice/image/video units stay out.
Groq is a hosted open-model serving lane.
OpenRouter owns router/marketplace economics.
Checklist antes de mover producción
| Check | Qué registrar |
|---|---|
| Price owner | Official provider, hosted provider, router, cloud marketplace o self-hosted route. |
| Model ID | Exact model string, alias/preview/dated/deprecation status. |
| Token mix | Input, cached input, output, reasoning tokens, average output ratio. |
| Route fees | Platform fee, request fee, search/tool fee, cache storage, data residency, marketplace uplift. |
| Quality threshold | Pass rate, retry rate, fallback rate, human-review rate, failed-output cost. |
| Latency and limits | RPM, TPM, context limit, batch window, timeout, provider status behavior. |
| Data route | Retention, training use, region, enterprise terms, audit needs. |
| Spend controls | Hard caps, alerts, project budgets, tenant attribution, rollback route. |
Preguntas frecuentes
¿Cuál es la LLM API más barata ahora?
Para tareas de texto simples y masivas, Groq GPT OSS 20B o DeepSeek V4 Flash pueden verse más baratos. El ganador real aparece al sumar output ratio, cache, batch, retries, route fees y quality threshold.
¿OpenAI es más barato que Claude o Gemini?
Depende del model y workload. GPT-5.4-nano/mini, Claude Sonnet 5 y Gemini 3.1 Flash-Lite tienen ventajas distintas.
¿Debo usar un router como OpenRouter?
Sí si switching, fallback, one account o provider comparison ahorran engineering time. Incluya platform fee y routing behavior.
¿Sirven los Free tiers para producción?
Normalmente no. Sirven para exploration y prototypes. Producción necesita predictable quota, billing owner, data terms y support path.
¿Por qué importa tanto el output price?
Muchos providers cobran output tokens varias veces más caro que input. Chatbots, agents y reports suelen ser output-heavy.
¿Cache y batch cambian el ranking?
Cache ayuda repeated prompts y stable prefixes; batch ayuda offline workloads. Cambian el ranking solo cuando la tarea cumple condiciones.
¿Puedo confiar en tablas de terceros?
Úselas para discovery. Final pricing debe verificarse en official owner pages.
¿Cada cuánto actualizar esta comparación?
Antes de una production decision y antes de cada refresh publicado. Model names, preview status, cache rules y router fees cambian rápido.