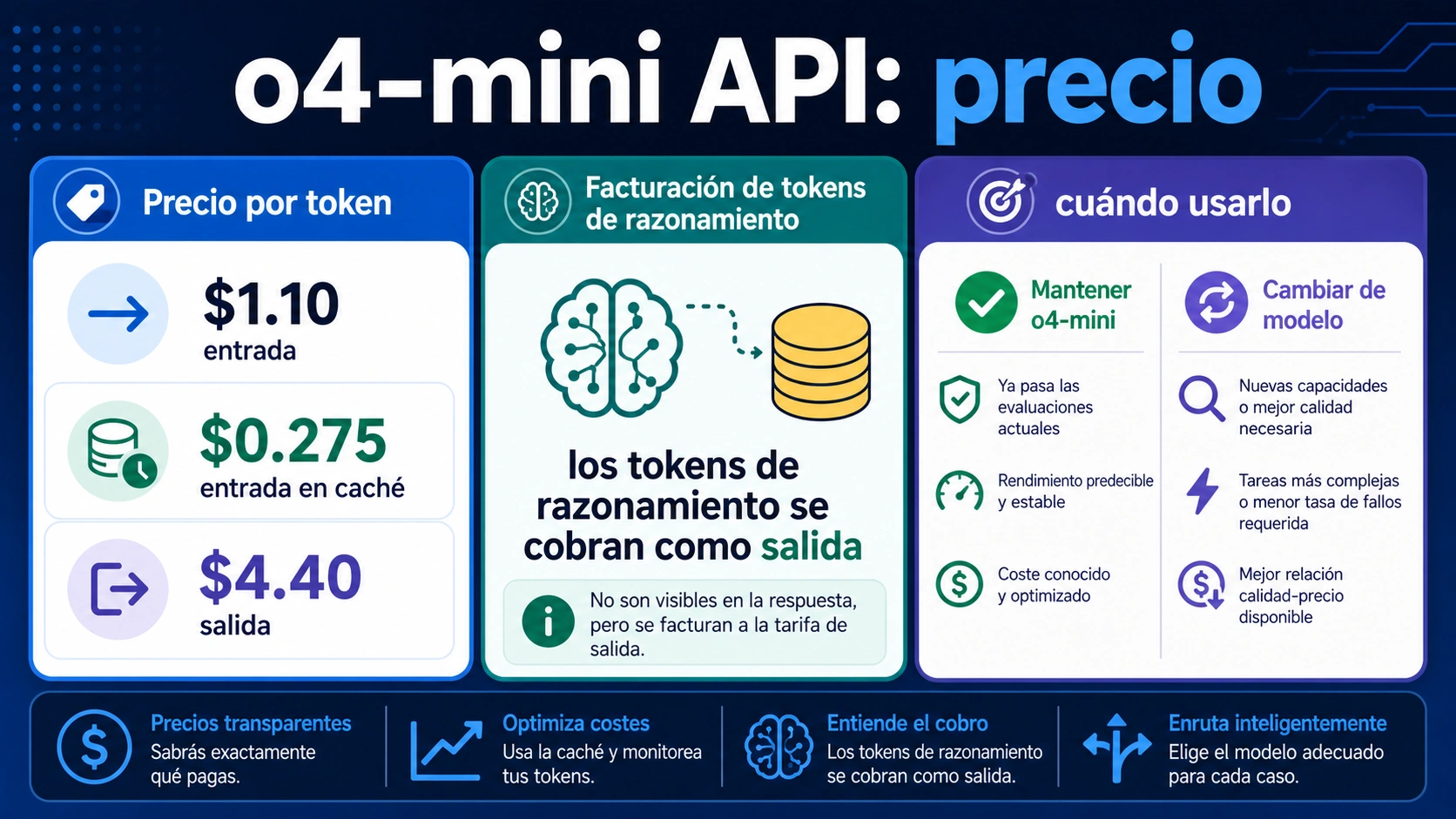
A 2 de julio de 2026, el precio Standard directo de OpenAI para o4-mini es $1.10 por 1M tokens de entrada, $0.275 por 1M tokens de entrada en caché y $4.40 por 1M tokens de salida. Esa fila no basta para estimar una factura real: los tokens de razonamiento invisibles se cobran como salida, Batch y Flex cambian la ruta operativa, y Priority muestra una fila más cara que no debe tratarse como precio normal.
| Qué necesitas decidir | Fila que debes mirar primero | Significado práctico |
|---|---|---|
| Coste directo normal | Standard: $1.10 entrada / $0.275 caché / $4.40 salida | Base para llamadas síncronas a OpenAI direct. |
| Trabajo masivo asíncrono | Batch: $0.55 entrada / $2.20 salida | Útil para backfills, evaluaciones y clasificación offline. |
| Trabajo online de baja prioridad | Flex: $0.55 entrada / $0.138 caché / $2.20 salida | Un service tier, no una garantía universal. |
| Procesamiento prioritario | Priority: $2.00 entrada / $0.50 caché / $8.00 salida | No copiarlo como estimación Standard. |
| Filas con nombres parecidos | Deep Research, fine-tuning, Azure, proveedores | Contratos separados, presupuestos separados. |
La regla de parada es separar entrada nueva, entrada en caché, salida visible y tokens de razonamiento antes de llamar barato a o4-mini. Mantén la ruta si tus evals ya demuestran calidad; prueba GPT-5.4 mini o GPT-5.5 para razonamiento nuevo; usa un modelo sin razonamiento para extracción, clasificación, formato y routing sencillo.
Qué es o4-mini ahora
La página de modelos de OpenAI sigue listando o4-mini como modelo de razonamiento, con model ID o4-mini y snapshot o4-mini-2025-04-16. Se presenta como una opción rápida y eficiente para razonamiento, coding y tareas visuales. Al mismo tiempo, ya tiene sucesores en la línea nueva, así que conviene leerlo como una opción usable en rutas verificadas, no como la primera elección automática para todo proyecto nuevo.
En español aparecen comparadores, proveedores y calculadoras que citan precios correctos junto a filas de Priority o información de Azure. Eso no es un problema si separas las superficies de facturación. Sí es un problema si una hoja de costes mezcla OpenAI direct, provider, Azure y Deep Research en una sola columna.
El coste útil no es el precio por token aislado. Importan la calidad, la tasa de reintentos, la longitud de salida, los tokens de razonamiento, la latencia y la reparación humana. Una fila más barata puede salir cara si necesita más razonamiento o falla más.
En español es frecuente ver calculadoras útiles junto a filas de Priority. La defensa es simple: model ID, ruta y superficie de facturación en columnas separadas.
Un proveedor puede ser conveniente por pago local, soporte o límites, pero su precio no sustituye a OpenAI direct. Conviene tener una hoja técnica y otra de procurement.
Los logs mínimos deberían incluir service tier y reasoning tokens. Sin eso, no puedes distinguir una mala elección de modelo de un prompt demasiado largo o un retry rate alto.
Para producción, la fila de precio debe ir acompañada de métricas por clase de solicitud: entrada nueva media, porcentaje de entrada en caché, salida visible, tokens de razonamiento, retry rate y reparación humana. Así puedes distinguir si el coste viene de prompts largos, mal cache hit, reasoning budget demasiado amplio o un modelo que necesita demasiados intentos.
El eval set conviene dividirlo en tres grupos: tareas antiguas estables, tareas difíciles de borde y negative samples que no necesitan razonamiento. El primer grupo decide si o4-mini se mantiene; el segundo decide cuándo subir a GPT-5.5; el tercero evita que extracción, clasificación y formato acaben usando razonamiento sin aportar calidad.
La conversación financiera también necesita capas. OpenAI direct es la estimación técnica por tokens. Batch, Flex y Priority son rutas operativas. Azure o un proveedor externo son procurement, moneda, soporte y límites. ChatGPT subscription no es API token billing. Mezclarlos impide saber qué optimizar.
Después de desplegar, vigila dos señales tempranas: aumento de reasoning tokens dentro de la parte de salida y caída del porcentaje de cached input. Lo primero puede indicar una tarea más ambigua o un prompt que deja demasiado margen; lo segundo suele indicar que se rompió el prefijo estable o que datos variables entraron demasiado pronto.
Filas oficiales de precio de o4-mini

La página de pricing de OpenAI es el punto de partida. Lee Standard, Batch, Flex y Priority como rutas distintas. Deep Research, fine-tuning, Azure y proveedores tienen contratos propios.
| Ruta | Entrada / 1M | Entrada en caché / 1M | Salida / 1M |
|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 |
Batch o4-mini | $0.55 | no listado aparte | $2.20 |
Flex o4-mini | $0.55 | $0.138 | $2.20 |
Priority o4-mini | $2.00 | $0.50 | $8.00 |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 |
Cómo estimar una solicitud real

hljs textcost = fresh_input / 1,000,000 * 1.10 + cached_input / 1,000,000 * 0.275 + (visible_output + reasoning_tokens) / 1,000,000 * 4.40
Para Standard, calcula entrada nueva / 1,000,000 * 1.10, entrada en caché / 1,000,000 * 0.275, y salida visible más tokens de razonamiento / 1,000,000 * 4.40. Los tokens de razonamiento no aparecen en la respuesta final, pero se cobran como salida y consumen presupuesto de contexto.
Ejemplo: 10,000 tokens de entrada nueva, 0 en caché, 2,000 tokens visibles y 3,000 tokens de razonamiento. La entrada cuesta $0.011, la parte de salida cuesta $0.022, total aproximado $0.033. A volumen alto, la variación de reasoning tokens deja de ser un detalle.
Con prompts largos, la caché cambia mucho la cuenta. Si 80,000 tokens de entrada incluyen 60,000 cached tokens, solo 20,000 se cobran como entrada nueva. Pero 5,000 tokens visibles y 10,000 de razonamiento siguen entrando en la tarifa de salida. La caché ayuda, pero no sustituye límites y medición.
Cuándo sigue teniendo sentido o4-mini
o4-mini tiene sentido cuando ya hay evals que lo respaldan. Puede funcionar bien para apoyo de coding con salida acotada, chequeos lógicos, matemáticas verificables, razonamiento visual y decisiones de router donde un modelo mayor sería excesivo.
Mantenerlo no significa dejar de medir. Registra accuracy, latency, salida visible, reasoning tokens, retry rate, coste de corrección y fallos downstream. La comparación debe ser por tarea terminada, no por token barato.
En producción, o4-mini debería ser una lane definida. Las tareas complejas pueden subir a GPT-5.5, el razonamiento nuevo de bajo coste se compara con GPT-5.4 mini y las transformaciones simples van a un modelo sin razonamiento.
Cuándo cambiar de modelo
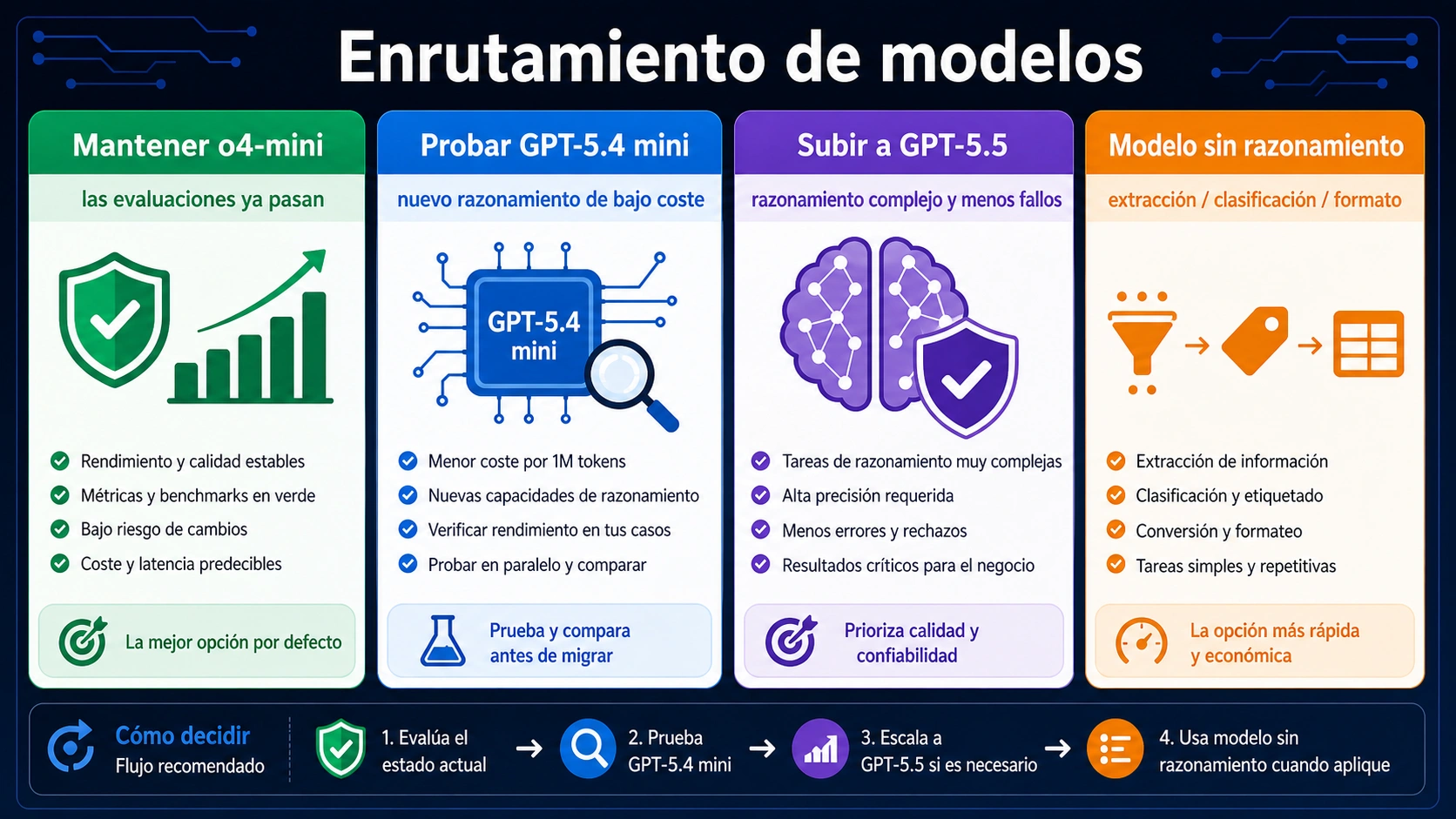
Para razonamiento nuevo, prueba primero los candidatos actuales de GPT-5.x. GPT-5.4 mini es el punto natural para coste sensible; GPT-5.5 tiene sentido cuando la dificultad, la fiabilidad o la reducción de reintentos pesan más que el precio por token.
Si la tarea es extracción, clasificación, formateo, normalización de metadatos o routing previo, no fuerces un modelo de razonamiento. Un modelo más barato sin reasoning puede dar una salida más predecible y una factura más estable.
| Carga | Primer modelo a probar | Motivo |
|---|---|---|
Lane existente de o4-mini con evals aprobados | Mantener o4-mini y retestear | Ya existe una línea base productiva. |
| Razonamiento nuevo de bajo coste | GPT-5.4 mini y o4-mini | El modelo nuevo puede ganar en quality per dollar. |
| Planificación compleja o coding repair | GPT-5.5 | Menos reintentos puede compensar la tarifa. |
| Extracción, clasificación, formato, routing | Modelo sin razonamiento | Reasoning tokens pueden no aportar valor. |
Controles de coste que sí importan
Prompt caching es la primera palanca. Coloca instrucciones estables, esquemas, políticas y bloques repetidos al principio; mueve datos variables al final. Así la parte reutilizable puede recibir la tarifa de caché.
max_output_tokens cubre salida visible y razonamiento. Si es demasiado bajo, la respuesta puede detenerse antes de mostrar algo útil. Si es demasiado alto, el coste invisible puede crecer sin señal clara para el usuario.
Batch reduce coste si aceptas asincronía. Flex puede reducir coste si la baja prioridad encaja. Priority sube la tarifa y debe usarse solo cuando tiene una razón operativa clara.
Si el bloqueo es 429 o cuota, empieza por la guía de OpenAI API rate limit; si el problema es key, billing o trial, empieza por la guía de OpenAI API key free trial.
Errores comunes
No uses una fila de fine-tuning/RFT como precio base de inferencia. Training hours y tuned-model inference son otra superficie.
No confundas o4-mini-deep-research con o4-mini. El nombre se parece, pero la fila y el uso son distintos.
No copies precios de Azure o proveedores como precio directo de OpenAI. Región, despliegue, soporte, margen y moneda pueden cambiar la cuenta.
No ignores los tokens de razonamiento. Una respuesta corta puede haber consumido una salida interna larga.
Lista antes de producción
- Confirma que el model ID en código y logs es
o4-mini. - Usa Standard para la estimación direct normal y separa Batch, Flex y Priority.
- Divide entrada nueva y entrada en caché.
- Suma salida visible y tokens de razonamiento para la tarifa de salida.
- Compara GPT-5.4 mini, GPT-5.5 y modelos sin razonamiento en el mismo eval set.
- Si el bloqueo es rate limit, revisa la guía local de OpenAI API rate limit; si es clave o billing, revisa la guía de API key free trial.
Preguntas frecuentes
Cuál es el precio actual de o4-mini API?
A 2 de julio de 2026, Standard OpenAI direct cuesta $1.10 entrada, $0.275 entrada en caché y $4.40 salida por 1M tokens.
Se cobran los tokens de razonamiento?
Sí. Los reasoning tokens ocultos se cobran como output tokens.
La entrada en caché se cuenta dos veces?
No. Es la parte de la entrada actual que coincide con un prefijo reutilizable y recibe una tarifa menor.
Batch es más barato?
La fila de precio es menor, pero Batch es asíncrono y tiene una ventana de 24 horas.
Flex es lo mismo que Batch?
No. Flex es un service tier de baja prioridad; Batch es una ruta batch asíncrona.
o4-mini está deprecated?
Los documentos lo siguen listando y también muestran sucesores. Eso obliga a comparar, no a borrar una lane productiva ya validada.
o4-mini o GPT-5.4 mini?
Si necesitas razonamiento de bajo coste, evalúa ambos. Para cargas nuevas, GPT-5.4 mini suele ser el primer candidato nuevo; para lanes existentes, decide con tus datos.
Cómo estimo el gasto mensual?
Calcula una solicitud con entrada nueva, caché, salida visible y reasoning tokens; multiplica por volumen, reintentos, fallos y reparto Batch/Flex/Priority.