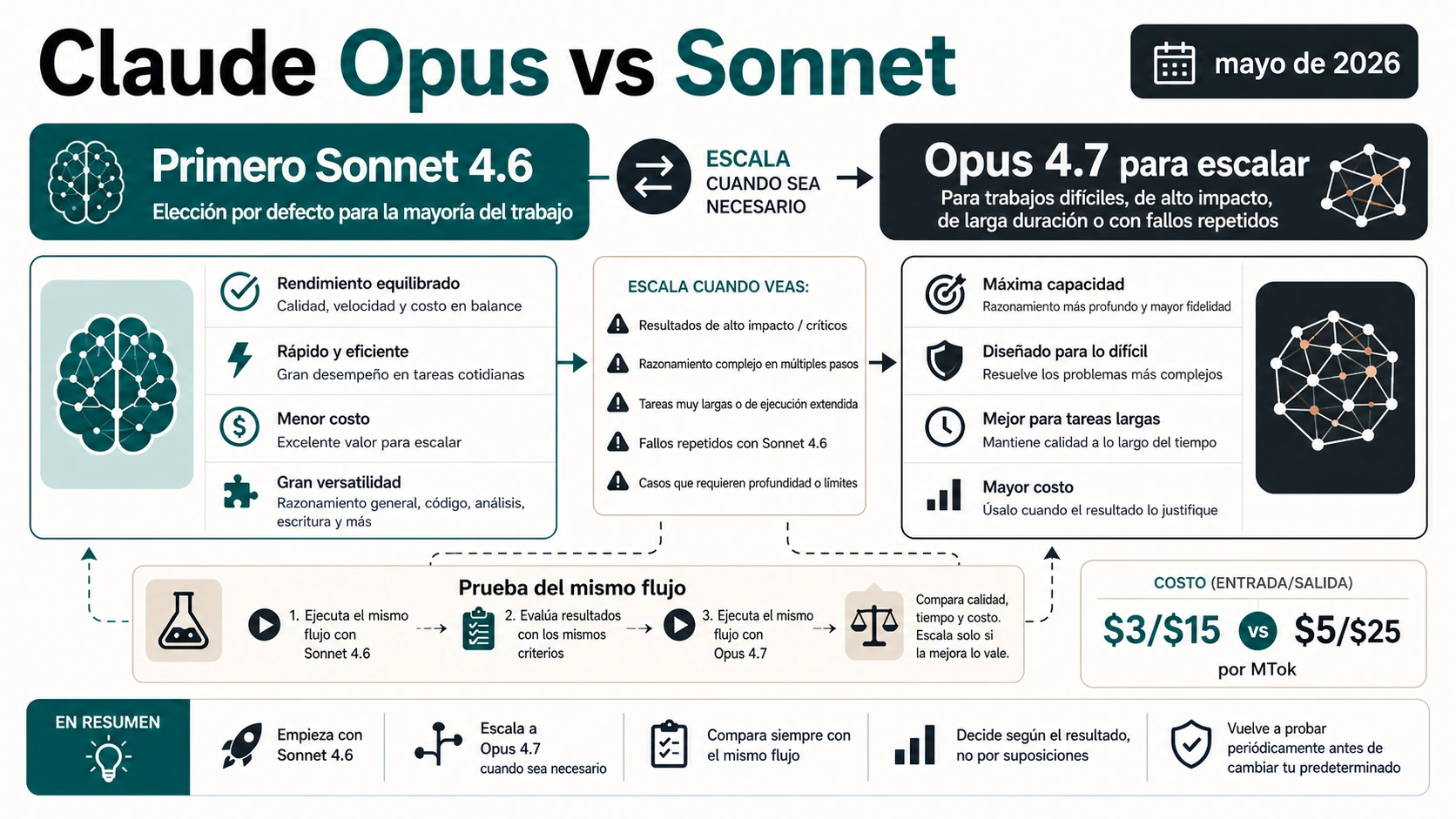
A 7 de mayo de 2026, la elección práctica es empezar con Claude Sonnet 4.6 para la mayoría de trabajos y mover solo los casos difíciles a Claude Opus 4.7. Sonnet es el mejor punto de partida cuando importan velocidad, coste, iteración y escala. Opus es el modelo de escalado para razonamiento de alto riesgo, arquitectura ambigua, agentes largos, síntesis de muchos documentos o tareas que ya fallan varias veces el mismo criterio de aceptación en Sonnet.
| Si la carga de trabajo se parece a esto | Prueba primero | Escala cuando |
|---|---|---|
| Código diario, investigación, contenido, análisis de oficina, flujos de navegador o computer use | Sonnet 4.6 | La respuesta exige reparación manual repetida o falla el mismo test. |
| Producción API con mucho volumen | Sonnet 4.6 | Los fallos, reintentos y revisiones cuestan más que la prima de Opus. |
| Decisiones de arquitectura, depuración raíz, razonamiento en muchos archivos | Canal de prueba Opus 4.7 | Mantén Sonnet si Opus no mejora el resultado aceptado. |
| Agentes largos o workflows de varias etapas | Baseline Sonnet más comparación Opus | Opus conserva mejor el plan o evita más callejones sin salida. |
| Extracción mecánica, clasificación, formato, routing sencillo | Vía lateral Haiku 4.5 | Sube a Sonnet antes de saltar a Opus. |
La fila de precios pública es solo el primer dato. En la documentación actual de Anthropic, Sonnet 4.6 figura a 3 dólares por millón de tokens de entrada y 15 dólares por millón de tokens de salida, mientras que Opus 4.7 figura a 5 y 25 dólares. La factura real cambia con la longitud de salida, prompt caching, batch, nivel de thinking, reintentos, tiempo de revisión humana y la nota de tokenizer de Opus 4.7: el mismo texto fijo puede consumir más tokens según su contenido.
La comparación actual es Opus 4.7 frente a Sonnet 4.6
En español todavía aparecen muchas páginas sobre Claude 4, Opus 4.5, Opus 4.6, Sonnet 4.5 o comparativas de familia muy generales. Sirven como contexto, pero la decisión actual no es “cuál suena más potente”. La decisión útil es qué trabajo debe quedarse en Sonnet 4.6 y qué trabajo merece una prueba controlada en Opus 4.7.
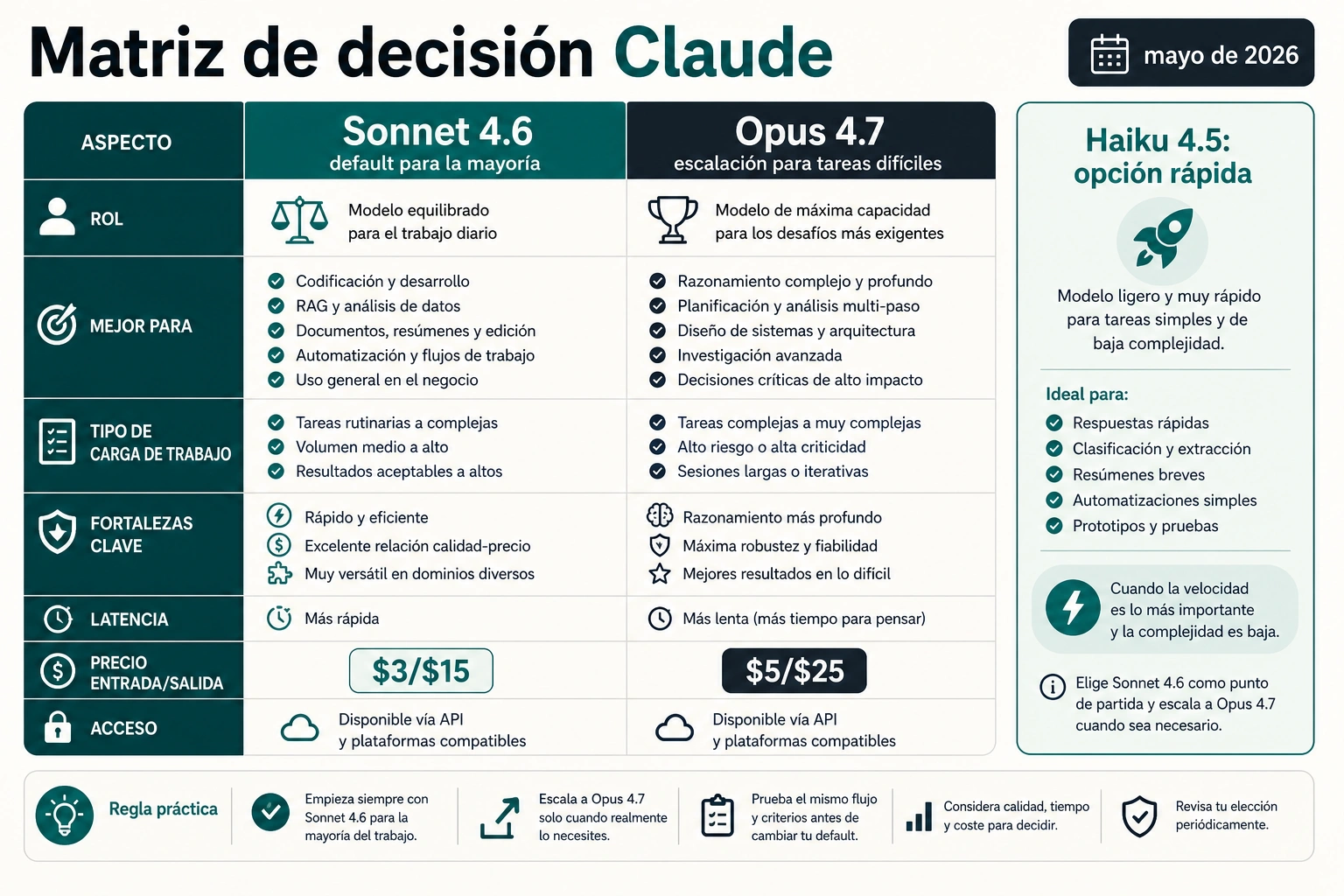
El overview actual de Anthropic lista Opus 4.7, Sonnet 4.6 y Haiku 4.5 como niveles principales. Opus 4.7 está orientado a ingeniería de software profesional, razonamiento complejo, flujos agentic, coding avanzado y tareas empresariales de alto riesgo. Sonnet 4.6 está orientado a uso diario, producción a escala, coding, agentes, uso de navegador y ordenador, razonamiento con contexto largo y eficiencia de coste.
| Fila oficial actual | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| Rol práctico | Modelo por defecto para la mayoría de trabajos | Modelo de escalado para los casos más difíciles |
| Precio API, comprobado el 7 de mayo de 2026 | $3 input / $15 output por MTok | $5 input / $25 output por MTok |
| Latencia | Fast | Moderate |
| Context window | 1M | 1M |
| Max output | 64k | 128k |
| Thinking | Extended thinking más adaptive thinking | Adaptive thinking |
| Primer uso | Trabajo diario, coding loops, producción | Razonamiento duro, agentes, decisiones críticas |
Haiku 4.5 entra solo como vía rápida y barata para tareas mecánicas. Es útil para extracción, routing, formato o batch de bajo riesgo, pero no debe adueñarse de una guía sobre Opus y Sonnet.
Cuándo Sonnet 4.6 debería ser el modelo por defecto
Sonnet gana el puesto por defecto cuando el workflow necesita velocidad, control de coste y capacidad de repetición. Eso cubre gran parte del uso real de Claude: ayuda de código, revisión de PR, documentación, limpieza de datos, resúmenes estructurados, soporte, redacción, análisis de oficina, automatización de navegador y muchos caminos de producción API.
No se trata de que Sonnet sea “barato”. Se trata de que muchas tareas no necesitan el modelo más caro para llegar a un resultado aceptable. Si la instrucción es clara, el contrato de salida es medible y el fallo se puede detectar con pruebas, schemas o revisión, empezar con Opus puede aumentar el coste sin cambiar el resultado.
Usa Sonnet primero cuando:
- la salida puede validarse con tests, schema, reglas o revisión rápida;
- el trabajo ocurre con frecuencia suficiente para que el coste por token importe;
- la iteración rápida pesa más que la máxima profundidad;
- el prompt y los criterios de éxito ya están claros;
- el modelo debe seguir un proceso, no inventar una estrategia;
- los fallos pueden capturarse con retry, lint, unit tests, validación o revisión humana.
Para usuarios de la app de Claude, Sonnet suele ser la entrada natural. Para equipos API, también debería ser el primer candidato de producción porque la fila oficial de precio es menor y el modelo está pensado para uso escalado.
Cuándo merece la pena probar Opus 4.7
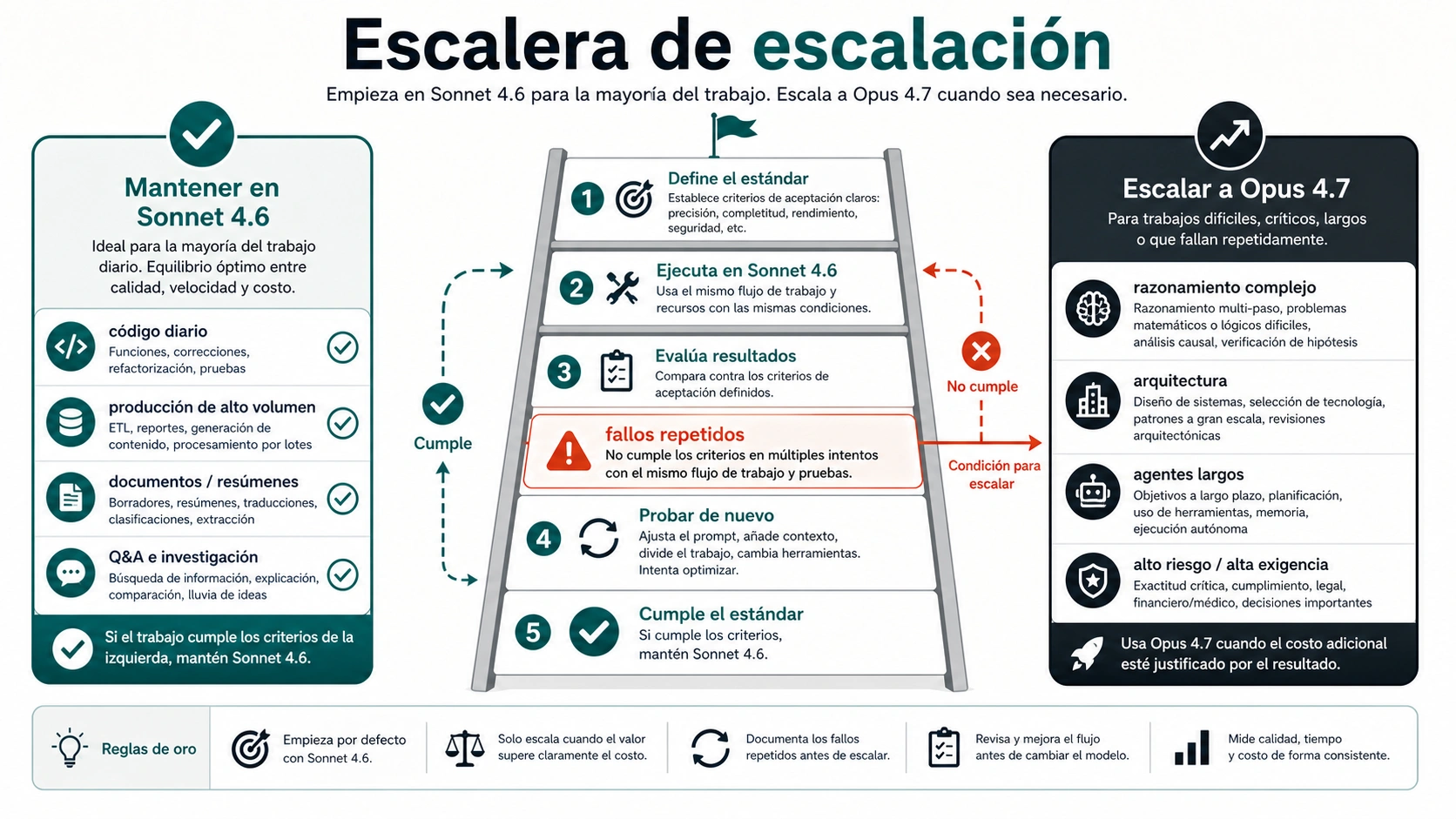
Opus merece una prueba cuando el fallo es caro, la tarea es ambigua o un bucle barato de reintentos no mejora el resultado. Sus mejores casos no son simplemente “tareas importantes”; son tareas donde más razonamiento, mejor planificación de largo recorrido o mejor manejo de contexto sucio cambian la salida final.
Abre un canal de prueba con Opus 4.7 cuando:
- Sonnet sigue fallando el mismo criterio después de limpiar el prompt;
- la tarea exige decisiones de arquitectura entre varios archivos, sistemas o restricciones;
- el modelo debe leer muchos documentos y preservar matices;
- un agente largo pierde el plan, se repite o toma atajos frágiles;
- la respuesta impulsa una decisión de ingeniería, legal, financiera o empresarial;
- la depuración de causa raíz se encarece si se acepta una hipótesis superficial;
- el mayor coste es la revisión humana y un mejor primer resultado ahorraría tiempo.
Opus no es una mejora moral para todos los prompts. Si ofrece la misma respuesta que Sonnet, o solo mejora el estilo, conserva Sonnet. Si evita una mala decisión de arquitectura, encuentra una dependencia oculta o termina un flujo largo que Sonnet no sostiene, la prima puede estar justificada.
La diferencia de coste no cabe en una fila de precios
La página de pricing de Anthropic es la fuente correcta para las filas de precio, pero no describe todo el coste del workflow. La diferencia base es clara: Sonnet 4.6 cuesta $3/$15 y Opus 4.7 cuesta $5/$25 por millón de tokens. Aun así, el gasto real depende de longitud de salida, cache write, cache hit, batch pricing, thinking effort, tool schemas, contexto repetido, reintentos y tiempo de revisión.
La página actual también señala que Opus 4.7 usa un tokenizer nuevo y puede contar hasta un 35% más de tokens para el mismo texto fijo, según el contenido. No significa que todas las llamadas sean 35% más caras. Significa que no debes estimar una migración multiplicando los tokens históricos de Sonnet por el precio de Opus.
| Capa de coste | Por qué cambia la decisión |
|---|---|
| Precio base de input y output | Opus cuesta más por token. |
| Longitud de salida | Las respuestas profundas pueden ser más largas si no se limita el presupuesto. |
| Prompt caching | Un cache hit reduce input repetido, pero cache write también cuenta. |
| Batch | Trabajo asíncrono puede ser más barato. |
| Thinking | Puede mejorar tareas difíciles, pero añade coste o latencia. |
| Tokenizer | Opus 4.7 puede contar distinto el mismo texto. |
| Revisión humana | Un modelo más caro puede ahorrar dinero si reduce retrabajo. |
La pregunta correcta no es “qué modelo es más barato por token”, sino “qué modelo produce el menor coste por salida aceptada en este workflow”.
Antes de cambiar el modelo por defecto, prueba el mismo flujo
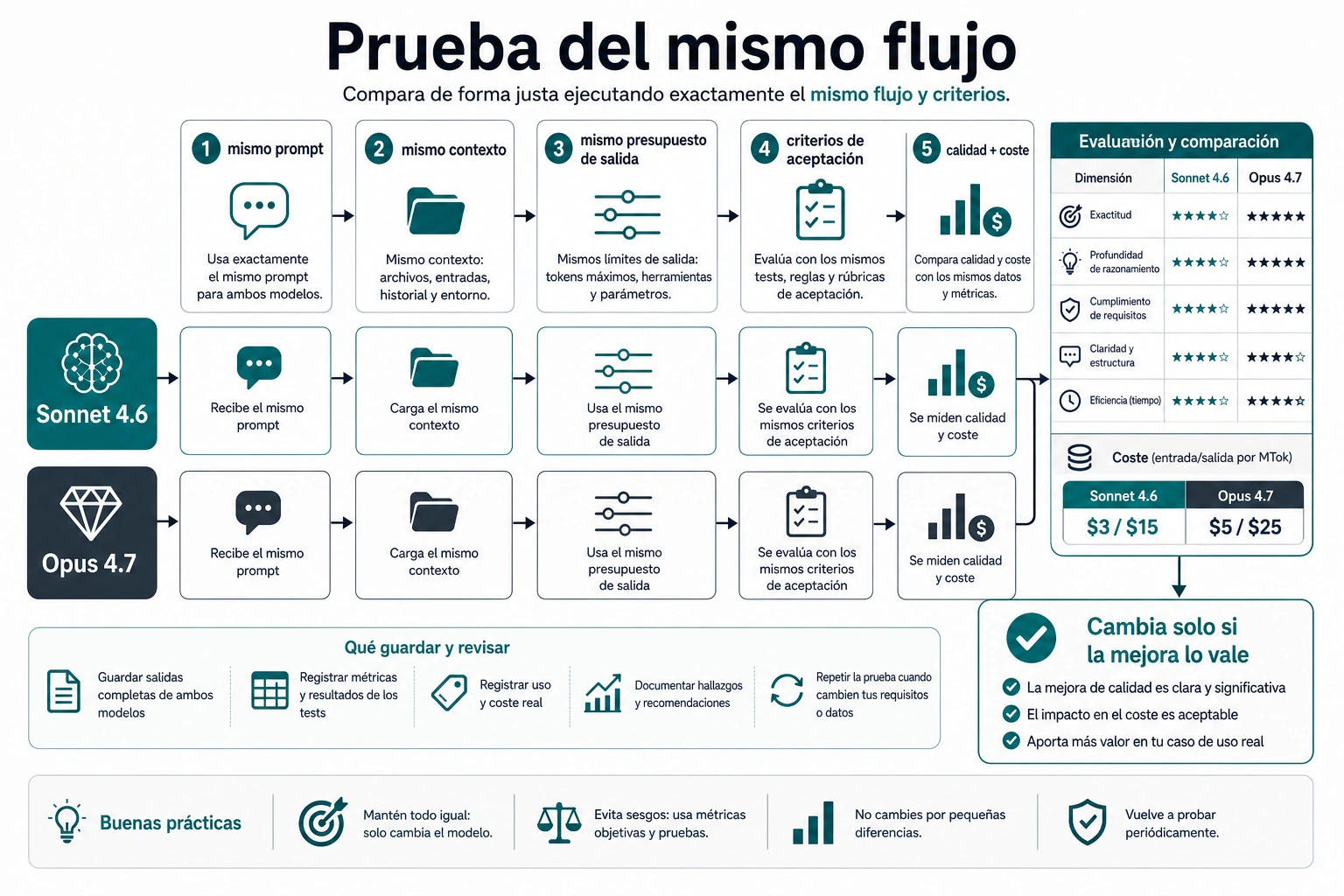
No cambies un default de producción porque la etiqueta del modelo suene más fuerte. Una comparación justa mantiene iguales el prompt, el contexto, el presupuesto de salida, las herramientas y los criterios de aceptación. Si cambias esas piezas, ya no estás midiendo el modelo.
Plan pequeño:
- Elige de tres a cinco tareas reales del workflow.
- Quita datos sensibles o ejecuta solo en el entorno aprobado.
- Ejecuta cada tarea en Sonnet 4.6 con el prompt y presupuesto actuales.
- Ejecuta la misma tarea en Opus 4.7 con el mismo prompt, contexto y presupuesto.
- Evalúa ambas salidas con los mismos criterios.
- Registra coste de tokens, latencia, reintentos, tiempo de revisión y resultado aceptado.
- Promueve solo los cortes donde Opus mejora el resultado lo suficiente para pagar la diferencia.
También evita el error inverso: quedarse en Sonnet por precio y pagar más en reintentos, revisiones o fallos. Para muchos equipos, la estrategia correcta es mixta: Sonnet para tráfico normal y Opus para excepciones difíciles.
La app de Claude, la API y Claude Code no son la misma superficie
Elegir un modelo dentro de la app de Claude, llamar un model ID en Claude Platform y trabajar en Claude Code son decisiones relacionadas, pero no idénticas. El usuario de app mira plan, límites de mensajes y selector del producto. El desarrollador API mira precio por token, rate limits, caching, batch e integración. El usuario de Claude Code debe revisar si su sesión usa suscripción, API key o configuración local.
Mantén las fronteras:
- Si la duda es Pro, Max o API billing, estás en un problema de acceso y pago.
- Si la duda es si Claude Code entra por una suscripción, estás en un problema de ruta de uso.
- Si la duda es qué modelo debe ejecutar una tarea, entonces eliges Sonnet, Opus, Haiku o un canal de prueba.
Comprar acceso no resuelve el routing. Un usuario Pro puede seguir usando Sonnet para casi todo. Un equipo con acceso API a Opus puede enviarlo solo a tareas difíciles. Una sesión de Claude Code debería comprobar su ruta antes de sacar conclusiones de coste.
Preguntas frecuentes
¿Opus es siempre mejor que Sonnet?
Opus 4.7 es más fuerte para los casos más difíciles, pero no es el mejor default para todo. Sonnet 4.6 suele ser mejor punto de partida cuando importan velocidad, coste y escala.
¿Qué uso primero, Opus o Sonnet?
Usa Sonnet 4.6 primero para la mayoría de trabajos. Pasa a Opus 4.7 cuando la tarea sea crítica, ambigua, larga, de arquitectura, muy documental o falle repetidamente en Sonnet tras limpiar el prompt.
¿Cuánto más caro es Opus?
A 7 de mayo de 2026, las filas oficiales muestran Sonnet 4.6 a $3 input y $15 output por millón de tokens, y Opus 4.7 a $5 y $25. El coste real cambia por longitud de salida, caching, batch, thinking, reintentos y tokenizer.
¿Sonnet basta para programar?
Sonnet 4.6 basta para muchos coding loops, PR reviews, refactors, tests y agentes rutinarios. Usa Opus cuando el trabajo se vuelva arquitectónico, cruce muchas restricciones, exija causa raíz o falle el mismo test.
¿Claude Code usa Opus o Sonnet?
Claude Code puede depender del producto, plan, ajustes y ruta. Trátalo como una superficie de trabajo, no como una respuesta separada. Para coding normal prueba Sonnet; para tareas difíciles de repo compara Opus con el mismo trabajo.
¿Dónde encaja Haiku?
Haiku 4.5 es la vía rápida y barata para trabajo mecánico: extracción, routing, formato o batch de bajo riesgo. Si no basta, sube a Sonnet antes de saltar a Opus.
¿Qué hago con consejos antiguos sobre Opus 4.5 o Sonnet 4.5?
Úsalos como contexto histórico. Para una decisión actual, vuelve a comprobar Opus 4.7 y Sonnet 4.6 contra las páginas actuales de Anthropic.
¿Cuándo debería un equipo usar ambos modelos?
Cuando el workflow tiene una ruta normal barata y una ruta de excepción difícil. Sonnet maneja el tráfico por defecto; Opus recibe tareas que fallan pruebas, exigen razonamiento profundo o tienen alto coste de revisión.