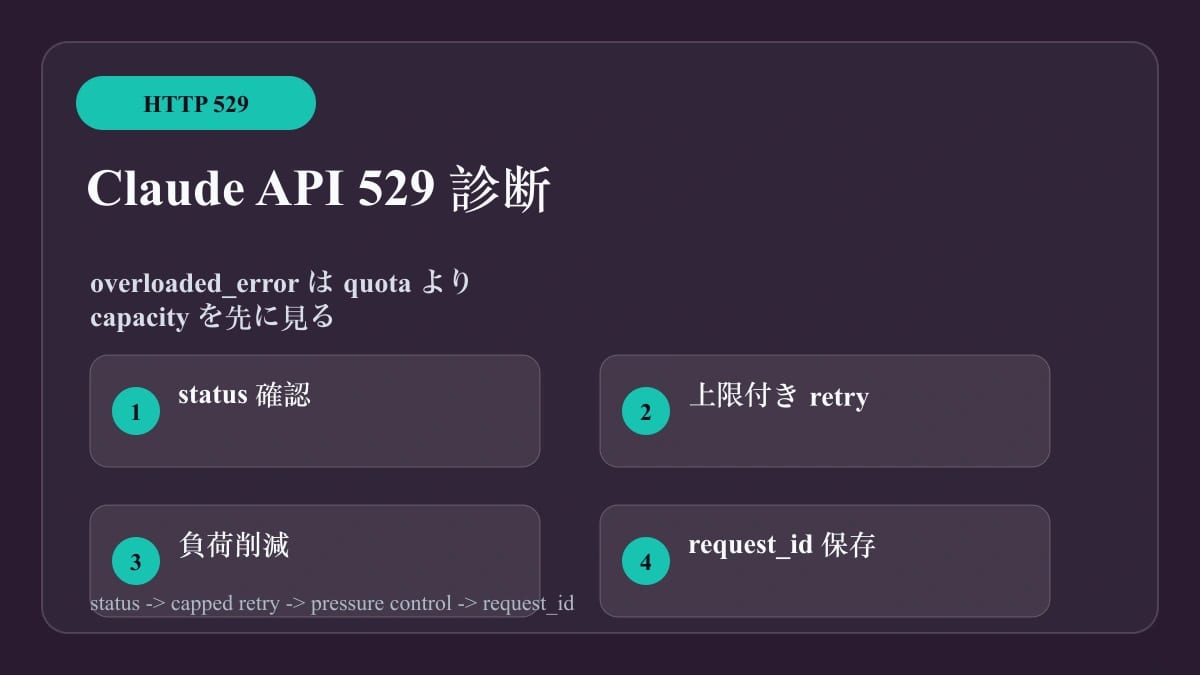
Claude API が HTTP 529 と overloaded_error を返したら、まず Anthropic 側の容量不足として扱います。自分のアカウントが 429 の rate limit に当たったと決めつけないでください。最初に Claude Status を確認し、即時リトライのループを止め、並列数を下げ、上限付きの指数バックオフと jitter で再試行します。検証中は endpoint、model、workspace、key、proxy、client library を同時に変えず、request_id と時刻を残します。
| レスポンスの手掛かり | 主な原因 | 最初の動き | 止めどころ |
|---|---|---|---|
HTTP 529 + overloaded_error | Anthropic の容量逼迫 | status 確認、遅い retry、新規処理を queue | retry 予算を使い切ったら証拠保存 |
HTTP 429 + rate_limit_error | 組織や workspace の limit | rate-limit header を読む | reset または limit 状態の変化まで待つ |
| HTTP 500 / 504 | server error または timeout | status と小さな同経路 request を確認 | 継続再現なら request evidence で相談 |
| Claude Code の repeated 529 | Claude Code が自動 retry 済み | status、待機、必要なら model 切替 | quota 消費と断定しない |
529 の扱いは狭く決めます。再試行は可能ですが、遅く、上限付きで、同時に負荷を下げる必要があります。密な loop、key の入れ替え、429 用の quota 修復は診断を悪化させます。
529 は容量不足の分岐であり、quota 分岐ではない
Anthropic の API error reference では、429 は rate limit、500 は内部 API error、504 は処理 timeout、529 は一時的な overload として分けられています。したがって最初の対応も違います。429 なら header、reset、workspace limit を読みます。529 なら status、同じ request path、制限付き retry、queue を優先します。
status ページは単なる緑か赤ではありません。2026-04-30T13:42:00+08:00 時点では public Statuspage API の Claude API component は operational でしたが、同日早朝と前日に related incident が記録されていました。容量問題では、全体表示が復旧済みでも、特定 model、route、wrapper、地域的な経路で短い 529 window が残ることがあります。
症状を早く消さないでください。response body、HTTP status、error type、request_id、model、endpoint、workspace、provider route、local timestamp を保存します。後で成功した時にも、その記録が「待ったから成功したのか」「concurrency を下げたからか」「payload を小さくしたからか」を示します。
最初の五分は request path を固定する
まず evidence を集めます。body と headers、request id、model、endpoint、workspace、provider route、input size、concurrency、timezone 付き timestamp を記録します。Claude Status を開き、Claude API、Claude Code、または model-specific incident を確認します。Zapier、Make、custom proxy、hosted agent が間にある場合は、その layer を別に記録します。
次に同じ path で小さな request を送ります。API key、organization、model、endpoint、client library は同じまま、prompt を短くし、output cap を下げます。小さい request が通り、production burst が落ちるなら、修復対象は traffic shaping です。小さい request も 529 なら、capacity または provider route pressure の可能性が高まります。
stop rule を決めます。foreground request は三から五回の backoff で十分です。batch job はより長く待てますが、worker を占有せず durable queue に戻すべきです。予算を使い切ったら、temporary capacity state を返し、job と evidence を残します。
retry は遅く、上限付きにする
529 が retryable という意味は、容量が戻れば同じ request が通る可能性がある、ということです。すぐ何度も送れば成功するという意味ではありません。retry policy は load を分散し、worker を守り、診断を保つ必要があります。
hljs tsfunction classifyClaude(status: number, type?: string) {
if (status === 529 || type === "overloaded_error") return "slow_retry";
if (status === 429 || type === "rate_limit_error") return "wait_for_limit";
if (status === 500 || status === 504) return "server_or_timeout";
return "do_not_retry_blindly";
}
重要なのは ceiling です。UI request は数回で temporary failure を返せます。batch worker は next retry time と attempt count を持って queue に戻せます。streaming UI は model path が一時的に overloaded であることを示し、沈黙したまま待たせないようにします。
529 と 429 を同じ修復に入れないでください。rate limit docs では 429 に retry-after や rate-limit headers が出ることがあります。529 では account bucket の reset が主役ではないため、backoff policy と service state で制御します。
診断を壊さずに負荷を下げる
負荷削減は、比較対象を保つ時に有効です。worker concurrency を下げ、speculative fan-out を止め、新規 job を queue に入れ、context を短くし、SDK と wrapper の二重 retry を避けます。SDK が transient failure を自動 retry するなら、外側の retry はさらに厳しい上限を持つべきです。
長い処理は synchronous request に押し込まないでください。即時応答が不要なら queue や batch に移し、長い出力では streaming を使うと idle timeout との混同を減らせます。大きな共有 context を繰り返すなら prompt caching は account-side token pressure に役立ちますが、529 の消滅を保証するものではありません。
model switch は continuity tactic です。品質や出力特性の変化を許容できる場合だけ使います。元の model が必須なら、静かに別 model に変えるより、待って後で同じ path を retry する方が安全です。
escalation 前に同じ path で検証する
最もきれいな検証は same-path small-load test です。key、organization、workspace、endpoint、model、client library、proxy、network path を固定し、小さい request と低 concurrency の production shape を比較します。これで provider pressure、payload size、burst pattern、wrapper layer を切り分けられます。
overload log は通常ログと分けます。request id、status、error type、model、endpoint、workspace、provider route、attempt、delay、input token estimate、output cap、final disposition を残します。Anthropic docs は request id が support の調査に役立つと説明しています。request ids、timestamps、status snapshot、same-path reproduction がある相談は、単なる terminal screenshot より強いです。
継続的で広範囲に再現する時だけ escalation します。Zapier、Make、proxy だけが落ち、direct Anthropic call が通るなら中間層を先に見ます。direct small request も 529 で、status が clean なら request id と時間帯を添えて support に出します。active incident があるなら、証拠を残し、queue が回復を待つようにします。
Claude Code、gateway、automation platform
Claude Code は独自の surface behavior を持ちます。error reference では server errors、overloaded responses、timeouts、temporary throttles、dropped connections が表示前に自動 retry されると説明されています。terminal に repeated 529 が出る時点で、すでに複数回試した後です。次は status、待機、必要なら model switch であり、Console API quota が尽きたと結論づける段階ではありません。
gateway と automation product は別分岐を増やします。Zapier、Make、proxy、hosted agent は error を replay、delay、transform することがあります。upstream Anthropic status と wrapper status を分けてください。platform が generic failure しか出さないなら、元の HTTP status と Anthropic error type を記録する logging を追加します。
production では小さな state machine が安定します。classify error、check service status、retry with cap、reduce pressure、queue deferred work、preserve request evidence。この順序の方が、key 変更、即時 loop、無言の model downgrade より安全です。
Production checklist
| Control | 529 での意味 | 実装 |
|---|---|---|
| Error classifier | 529 と 429/500/504 を分ける | HTTP status と error type を見る |
| Capped jittered retry | retry storm を防ぐ | foreground と batch で予算を分ける |
| Concurrency limits | worker が同時に起きない | model、endpoint、route 別に cap |
| Durable queue | foreground を守る | next retry time と attempt を保存 |
| Same-path probe | 小さい request の可否を見る | key、workspace、model、route を固定 |
| Request id logging | support evidence になる | body と header の id を保存 |
| Status observation | incident と local pressure を分ける | checked time と component を記録 |
復旧後には短い postmortem も必要です。attempt、delay、concurrency、input size、output cap、status snapshot、final disposition を同じ event に残します。次に 529 が出た時、担当者は queue を維持するのか、backoff window を広げるのか、特定 model の concurrency を下げるのか、support evidence を出すのかをすぐ判断できます。複雑な監視でなくても、request_id で検索できる structured log は最低限必要です。
複数の retry layer も確認してください。frontend、API gateway、worker、SDK、message queue がそれぞれ retry すると、三回のつもりが数十回になります。capacity branch で最も危険なのはこの隠れた増幅です。retry owner を一箇所に固定し、ほかの layer は temporary capacity state を伝えるだけにすると、負荷も診断も安定します。
よくある質問
Claude API 529 は quota を消費しますか?
まず capacity branch として扱います。Claude Code reference は repeated 529 を usage limit とは分けています。direct API では Billing と Usage も別途確認しますが、overloaded_error に 429 の修復を当てないでください。
overloaded_error はすぐ retry してよいですか?
いいえ。backoff、jitter、ceiling が必要です。即時 retry は、サービスが減速を求めている時に負荷を増やします。
model switch は修復ですか?
継続作業のための手段です。別 model の品質を許容できる場合だけ使い、元 model が必要な処理では待って retry します。
support には何を送るべきですか?
request ids、timezone 付き timestamps、model、endpoint、workspace、provider route、status-page state、retry schedule、same-path small request の結果を送ります。