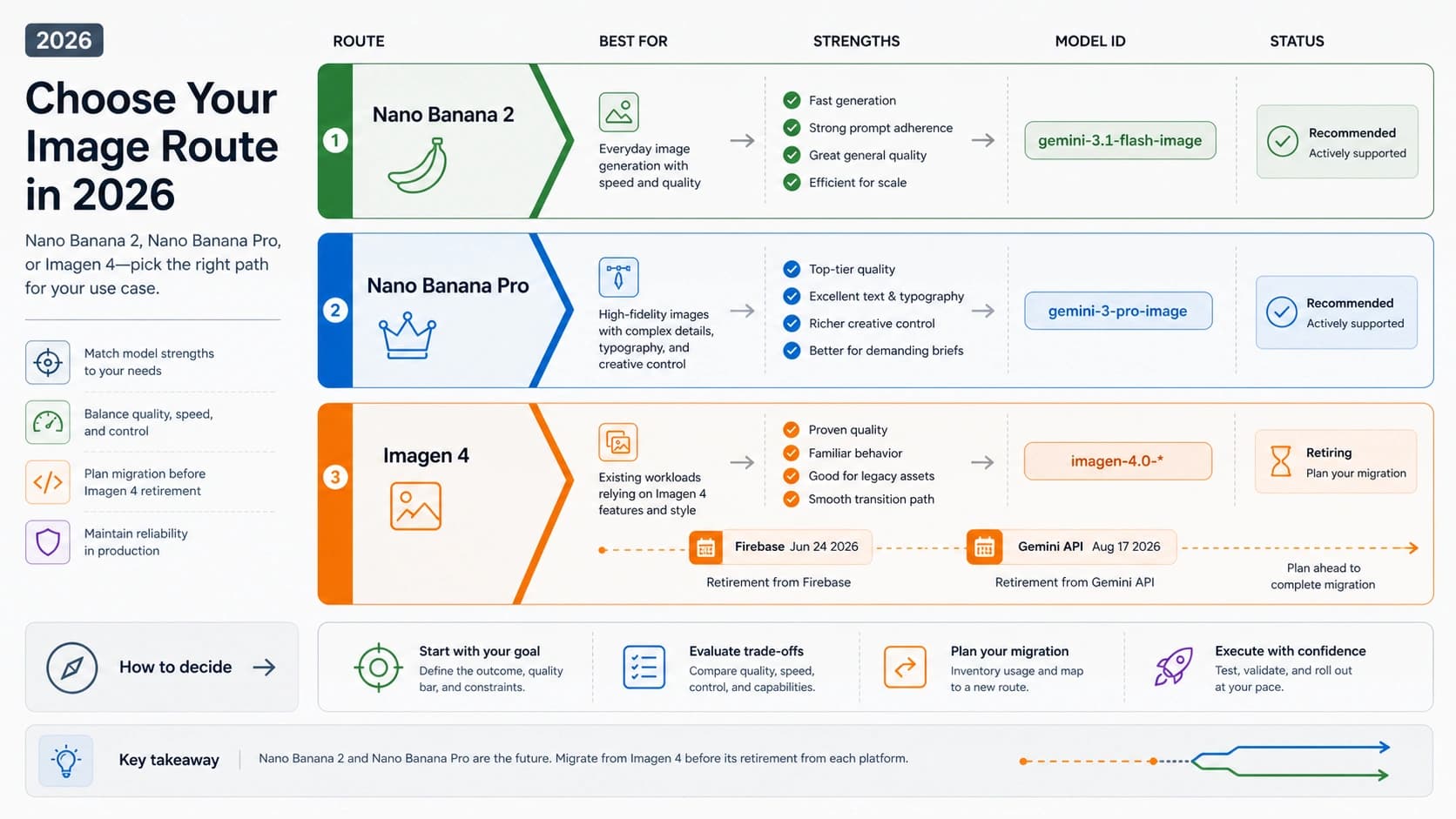
2026年5月8日時点で、DeepSeek V4 Preview は公式に利用可能です。DeepSeek の4月24日リリースは V4 Preview を公式公開かつオープンウェイトとし、API側では deepseek-v4-pro と deepseek-v4-flash を示しています。したがって最初の問いは「本当に出たのか」ではなく、公式API、App、Hugging Face、Provider、ローカル実行のどれで、どちらのモデルを先に検証するかです。
| ルート | 最初に使う場面 | 本番前に見ること |
|---|---|---|
| App / Chat | まず挙動を触りたい | 機能制限、プライバシー境界、APIで再現できるか |
| 公式API | DeepSeek本人のhosted contractが必要 | model ID、1Mコンテキスト、384K max output、価格日付、streaming、thinking mode |
| Hugging Face | オープンウェイトや研究制御が必要 | ハードウェア、推論スタック、ライセンス、recall、latency、公式APIとの差 |
| Provider | gatewayや既存請求ルートが必要 | Providerごとの価格、quota、routing、log、fallback、support |
| ローカル実行 | 最大制御やoffline-sensitive検証が必要 | GPU、メモリ、KV cache、運用、監視、評価セット |
最初の切り分けは単純です。測定しやすく、失敗しても自動検出や再実行ができる大量処理は deepseek-v4-flash から始めます。コード、Agent、長文統合、複数証拠の照合、人間の修正コストが高い処理は deepseek-v4-pro から始めます。deepseek-v4-preview を API の model ID として使わず、1Mコンテキストを品質保証として扱わないことが重要です。
公式発表で確定できること
DeepSeek のリリースは 2026年4月24日付で、V4 Preview が officially live で open-sourced だと説明しています。DeepSeek-V4-Pro は 1.6T total / 49B active の MoE、DeepSeek-V4-Flash は 284B total / 13B active の MoE として示されています。両方に 1Mコンテキストと thinking / non-thinking mode が関係します。
この情報は強い事実境界ですが、導入判断そのものではありません。速報や技術メモは、100万トークン、低コスト、オープンモデル、ベンチマークを同じ流れで扱いがちです。しかし実装では、公式API、Hugging Face、Provider、ローカル実行を別々の契約として扱う必要があります。
既存のDeepSeek連携があるなら、最初の作業はpromptの全面変更ではなく、route ownerの棚卸しです。どのサービスが公式APIを呼び、どこがProviderを経由し、どこに古いdeepseek-chatやdeepseek-reasonerが残り、どこがローカル実験なのかを分けます。この棚卸しなしにmodel IDだけを置き換えると、価格、ログ、fallback、support境界の変更を見落とします。
ProとFlashの差は、単なる上位版と軽量版ではありません。Flashは低コスト・低遅延・高スループットの検証レーンです。Proは失敗時の人間コストが高い難しいレーンです。この前提を最初に置かないと、価格表やパラメータ数だけで誤った採用判断になります。
FlashとProの初回テスト
Flashは、分類、抽出、文書スクリーニング、構造化出力、低リスクな一括要約、ルーティングなど、受け入れ条件を機械的に見られる処理に向いています。schema、テストセット、レビューキュー、二段階検証で悪い出力を止められるなら、Flashの安さと速さを利用してサンプル数を増やせます。

Proは、弱い回答が高くつく処理から検証します。複数ファイルのデバッグ、coding agent、設計判断、長い契約書の矛盾チェック、tool-heavy workflow、長文資料の統合では、token価格よりも再試行・人手修正・レビュー時間の方が支配的になることがあります。
| 処理 | 最初のモデル | 理由 |
|---|---|---|
| 大量分類・タグ付け | deepseek-v4-flash | 悪い出力を検出しやすい |
| 一括要約 | deepseek-v4-flash | throughputとコストが重要 |
| コードAgent | deepseek-v4-pro | 脆い回答が開発時間を浪費する |
| 長文統合 | Flashから始め、難例をProへ | 簡単な文書にPro料金を払わない |
| tool calling | 同じschemaで両方を比較 | 引数の安定性は実タスク依存 |
API IDと旧エイリアス
新しい実装では deepseek-v4-pro または deepseek-v4-flash を明示します。リリースでは deepseek-chat と deepseek-reasoner が互換エイリアスとして扱われ、2026-07-24 15:59 UTC 後にアクセス不可になる予定だとされています。古いクライアントの移行期間には便利ですが、新規production設定の主語にはしない方が安全です。

OpenAI-compatible client を使う場合、DeepSeek公式の base URL は https://api.deepseek.com です。これは公式APIの入口であり、Providerの価格やroutingを証明するものではありません。設定には model ID、route owner、価格確認日、streaming、tool/JSON期待値、thinking mode、rollback方針を分けて記録します。
hljs tsimport OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: "https://api.deepseek.com",
});
const response = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [{ role: "user", content: "Summarize the document and cite evidence lines." }],
stream: true,
max_tokens: 4096,
});
価格は日付付きで扱う
2026年5月8日時点の DeepSeek pricing では、deepseek-v4-flash が cache hit input $0.0028、cache miss input $0.14、output $0.28 per 1M tokens とされています。deepseek-v4-pro は割引中の行で $0.003625、$0.435、$0.87 per 1M tokens、元の行で $0.0145、$1.74、$3.48 です。V4-Pro 75%割引は 2026-05-31 15:59 UTC まで延長と書かれています。
これらは更新される可能性がある数字です。Providerが別価格、割引、クレジット、地域ルート、fallback、ログ、quota、サポートを出す場合、それはProvider自身の契約です。価格を引用するなら、公式API価格とProvider価格を同じ表に混ぜず、必ず確認日と所有者を近くに置きます。
1Mコンテキストの検証
1Mコンテキストは長い入力を受けられるという能力であり、長文タスクの品質保証ではありません。検証すべきなのは、遠い位置の事実を拾えるか、複数箇所を結合できるか、矛盾を見落とさないか、latencyとtimeoutが許容範囲か、384K max outputが実用上どう効くか、accepted-output costが合うかです。

| 検証 | 見るもの | 失敗サイン |
|---|---|---|
| 入力受け入れ | 目的サイズを通せるか | reject、truncation、timeout |
| 遠距離recall | 中盤・終盤の事実を拾えるか | 冒頭だけで答える |
| 横断推論 | 複数証拠を結合できるか | 片方の章だけで判断する |
| latency | SLAに入るか | p95やtimeoutが高い |
| output境界 | 384K max outputを扱えるか | 出力が切れる、肥大化する |
| route安定性 | PreviewやProvider差が管理可能か | ルート変更で結果が崩れる |
オープンウェイト、Provider、ローカル
DeepSeekの verified Hugging Face collection には Pro、Pro-Base、Flash、Flash-Base が含まれます。model card は Preview series、MoE構成、1Mコンテキスト、thinking modes、MIT license を示します。これはオープンウェイトの証拠ですが、ローカルで公式APIと同じlatencyやcontext挙動になる証拠ではありません。
ローカル実行は無料hosted APIではなく、runtime責任の引き受けです。GPU、メモリ、KV cache、serving stack、batching、監視、セキュリティ、アップデート、評価を自分で持ちます。Provider route も別契約なので、公式APIの結果をそのまま移植できると考えず、同じ評価セットで再確認します。
ローカル評価は、最初から1Mを狙うより、32K、128K、256K、さらに長い文書へ段階的に伸ばす方が安全です。各段階でメモリ、p95 latency、遠距離recall、出力の採用率、retry率を残します。これにより、モデルの限界と自社serving stackの限界を分けて判断できます。
GPT比較を見るべき場面
DeepSeek V4 Previewの内部選択、つまり公式状態、API ID、Pro/Flash、1M検証、weights、Provider、ローカル実行を決める段階なら、このDeepSeek-only判断で足ります。OpenAIとDeepSeekの採用判断になったら、別の比較ページ GPT-5.5 vs DeepSeek-V4 を使います。そこではベンダー間のルート選択が主題になります。
本番前チェックリスト
- configに
deepseek-v4-flashまたはdeepseek-v4-proを固定する。 - route ownerを official API、Provider、Hugging Face、local serving に分ける。
- 同じprompt/eval setでFlashとProを比較する。
- 1Mが理由なら遠距離recallと横断推論を入れる。
- token単価ではなくaccepted-output costを見る。
- streaming、JSON、tools、thinking modeは実際に使う箇所だけ検証する。
deepseek-chatとdeepseek-reasonerの残存を退役日前に探す。- 価格、割引、Provider条件、利用可否は公開前に再確認する。
評価セットは三つに分けると運用しやすくなります。通常回帰セットはモデル更新やProvider差分を検出します。長文セットはlost-middle、遠距離recall、出力切れを見ます。高失敗コストセットはFlashで十分か、Proへ上げるべきかを判断します。この三層があると、Preview期間の変化にも追従しやすくなります。
FAQ
DeepSeek V4 Preview は公式ですか?
はい。DeepSeekの2026年4月24日リリースは V4 Preview を公式公開かつオープンウェイトとし、API docs もV4 model IDを示しています。Previewという限定は残すべきです。
API model ID は何ですか?
deepseek-v4-pro または deepseek-v4-flash を使います。deepseek-v4-preview はmodel IDではありません。deepseek-chat と deepseek-reasoner は互換エイリアスで、2026-07-24 15:59 UTC 後に利用不可予定です。
FlashとProはどちらを先に試すべきですか?
大量で測定しやすく、低コスト・低latencyが重要な処理はFlashです。複雑推論、コード、Agent、長文統合、修正コストの高い処理はProです。
1Mコンテキストはそのまま本番で使えますか?
いいえ。公式情報は能力を示しますが、本番ではrecall、latency、timeout、384K max output、Provider制限、Preview期間の変化を検証します。
weights はオープンですか?
DeepSeekの verified Hugging Face collection には Pro、Pro-Base、Flash、Flash-Base があり、model card は MIT license を示しています。ただしローカル運用の品質は別途検証が必要です。
Provider route は公式APIですか?
違います。Providerの価格、routing、fallback、log、quota、supportは別契約です。DeepSeekのfirst-party claimsには公式DeepSeek docsを使います。
ローカルで1Mコンテキストを使えますか?
評価はできますが、GPU、メモリ、serving stack、latency、recall、accepted-output cost の問題です。短いcontext ladderから段階的に広げるべきです。