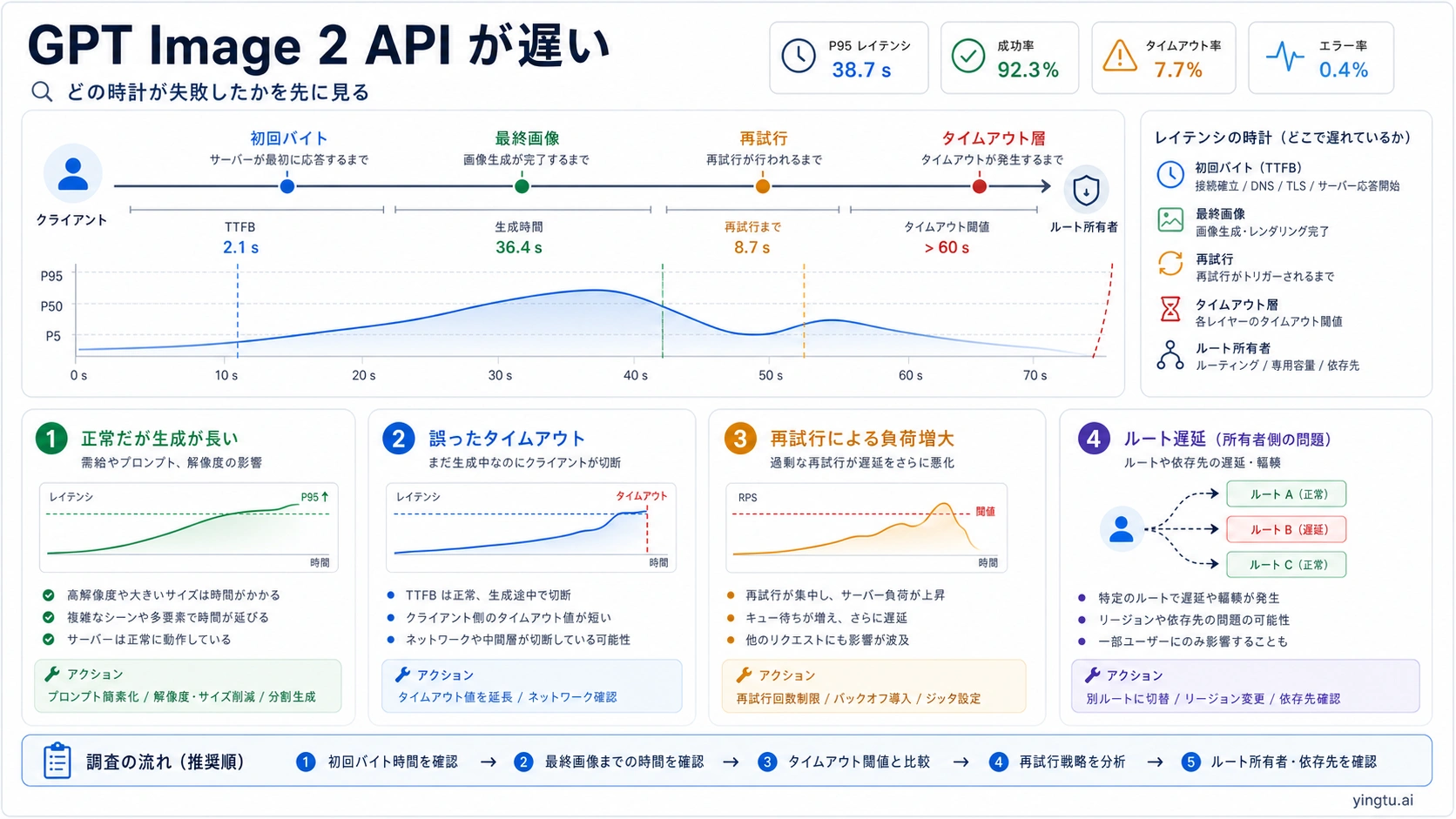
GPT Image 2 API が遅いと感じたら、最初にやるべきことはモデルを疑うことではありません。複雑なプロンプト、参照画像、高い quality、大きい size では、生成そのものが長くなることがあります。一方で、実際の障害はブラウザ、CDN、Worker、リバースプロキシ、gateway、frontend fetch、または再試行の設計にあることも多いです。まず一回の生成を、接続、初回バイト、最初の部分画像、最終画像、ダウンロード、レンダー、再試行回数、HTTP ステータス、request ID、モデル、quality、size、format、ルート所有者、失敗したタイムアウト層に分解します。
| 見えている症状 | 最初の分類 | 最初の安全な動き |
|---|---|---|
| 初回バイトが遅いが最終画像は返る | 長い生成またはキュー待ち | 進行中状態を表示し、必要なら streaming や非同期 job を使う |
| backend は終わったのに browser が失敗 | 偽のタイムアウト | 失敗した層だけを広げ、全層を緩めない |
| 再試行が積み上がる、または 429 が出る | retry と rate limit の圧力 | 短い再試行を止め、reset header と backoff を使う |
| gateway 経由だけ遅い | ルート所有者の遅延 | 同じ条件でより直接のルートと比較し、匿名化した証拠で確認する |
key を変える、provider を変える、quality を下げる、再試行を増やす、という順番にしないでください。遅い API 呼び出しは、まず「どの時計が失敗したか」を見る問題です。
遅い生成と偽のタイムアウトを分ける
「90 秒かかった」というログだけでは、どこで待ったのかが分かりません。初回バイトが来るまで無音だったのか、部分画像は出ていたのか、最終画像はできていたのか、download が重かったのか、frontend が先に abort したのか、再試行で同じ job を増やしたのかを分けます。
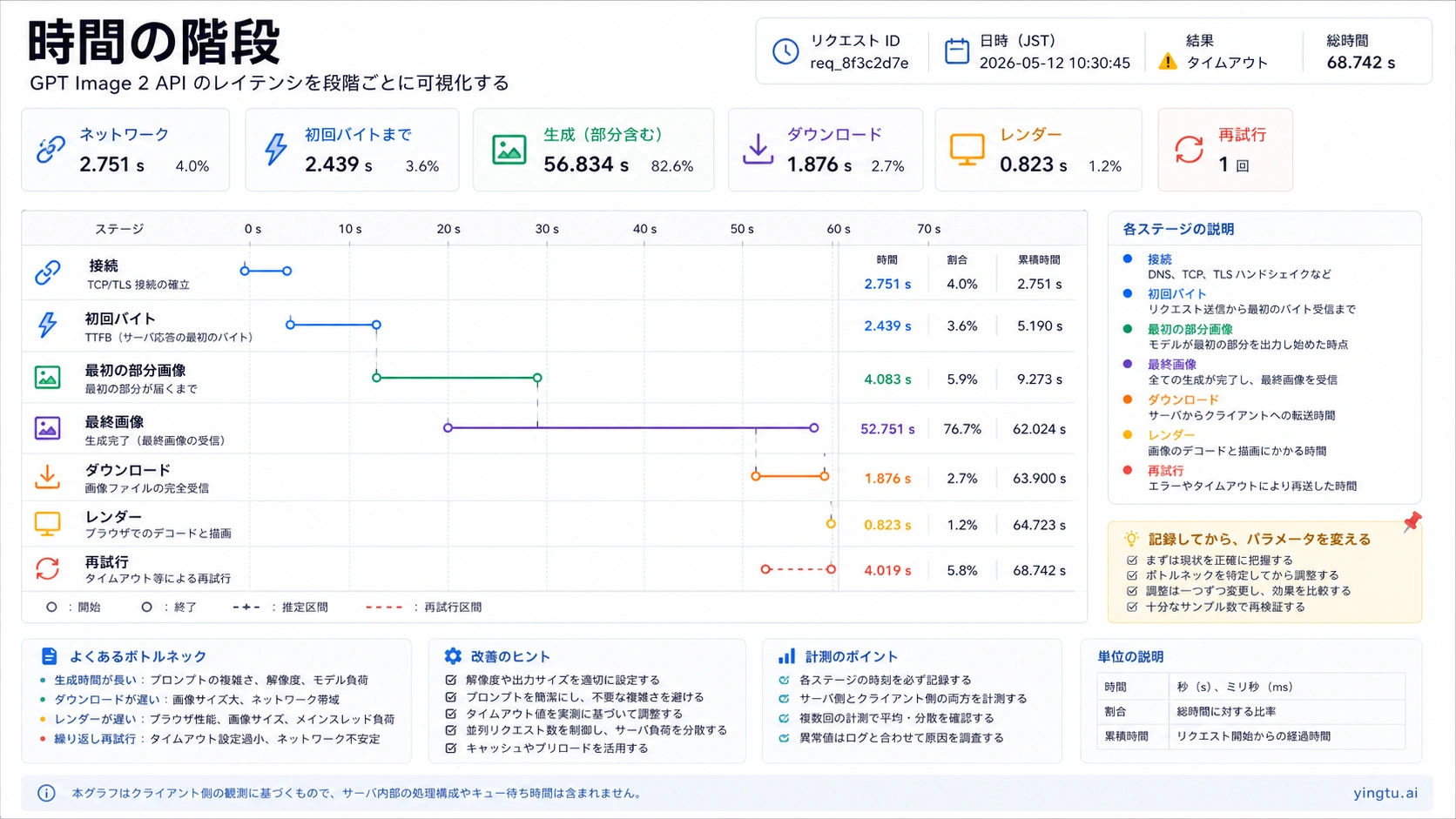
ログ項目は request_started_at、connect_ms、first_byte_ms、first_partial_image_ms、final_image_ms、download_ms、render_ms、retry_count、retry_reason、http_status、error_type、request_id、model、quality、size、format、route_owner を一つの job にまとめます。これで network、model、file、browser、retry を切り分けられます。
gpt-image-2 というモデル名だけでは十分ではありません。OpenAI direct、Azure deployment、compatible gateway、reverse route は、同じモデル名でも timeout、headers、retry、ログの所有者が違います。ルートが違うなら、同じ latency として混ぜないでください。
画像生成向けのタイムアウト予算を作る
タイムアウト予算は、全てを長くすることではありません。ブラウザはユーザー状態を持ち、backend は job を持ち、proxy は upstream を待ち、queue は作業完了を待つ、という役割分担が必要です。同期 HTTP のまま frontend に最終画像まで待たせるほど、偽のタイムアウトが増えます。
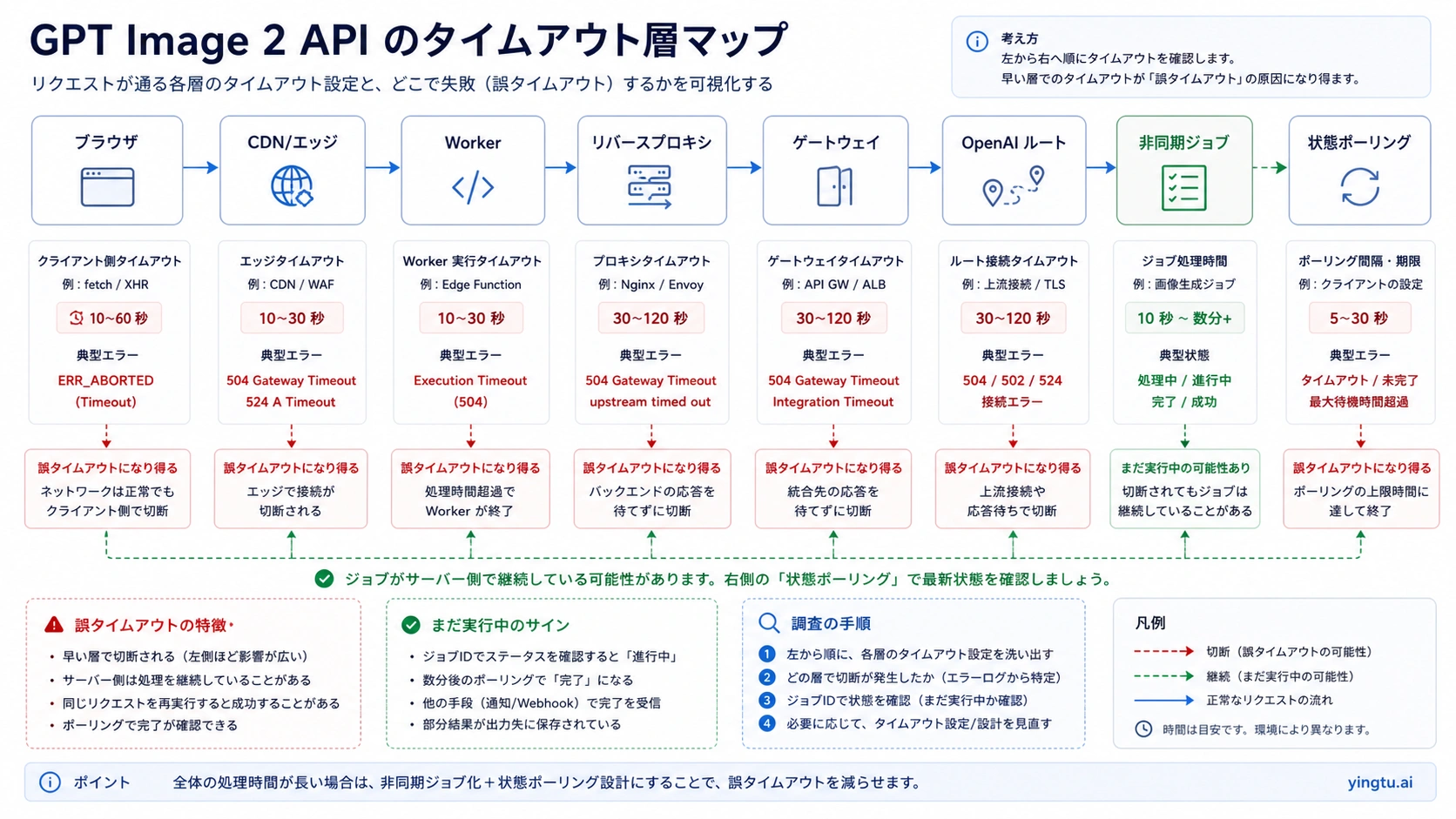
| 層 | よくある失敗 | より安全な設計 |
|---|---|---|
| ブラウザ | fetch が backend より先に abort | job ID、進行状況、polling を返す |
| CDN/edge | platform limit で切れる | 長い生成を短い edge path から外す |
| Worker | function timeout が先に来る | long-running worker、queue、background job を使う |
| リバースプロキシ | idle/upstream timeout | 画像 route だけ調整する |
| gateway | 内部待ちや再試行が見えない | provider logs と upstream status を別に見る |
| SDK/HTTP client | local timeout が先に発火 | product path に合う明示 timeout を置く |
UX は「読み込み中」だけにしないでください。queued、generating、partial preview、finalizing、saved、failed at local timeout のように状態を分けると、ユーザーの二重クリックも減り、support に出す証拠も整理できます。
基準を測ってからパラメータを変える
OpenAI の画像生成ガイドには実用的なレバーがあります。draft では low quality が速く、square output は扱いやすく、latency を重視する preview では JPEG が PNG より向くことがあり、複雑な prompt は長くなることがあります。ただし、これは「最初に全部下げる」という意味ではありません。
| 変更 | 改善しうること | 損なうこと | 試す場面 |
|---|---|---|---|
| quality low | draft の戻り | 細部、文字、仕上がり | 下書き、サムネ、内部確認 |
| square output | 生成と layout の単純化 | 必要な縦横比 | 後で crop できる時 |
| JPEG | 転送と decode | 透明度、後工程 | preview や写真系出力 |
| PNG/WebP | 品質と圧縮制御 | 転送量と処理 | production asset |
| 参照画像を減らす | upload/input 処理 | style と identity の制御 | 参照が多すぎる時 |
| prompt を絞る | model work | 指示の精度 | 遅い時計が生成側にある時 |
品質が価値そのものなら、数値だけのために下げないでください。品質の分岐は /ja/blog/gpt-image-2-low-quality/、大きい画像は /ja/blog/gpt-image-2-4k-image-generation/ に渡し、遅延対応では slow clock と owner に集中します。
Streaming と非同期で体感を改善する
Streaming partial images は、最終画像ができる前に進行中であることを見せられます。ただし final compute が必ず短くなるわけではありません。ログでは first byte、first partial image、final image を別々に持ちます。
Streaming が合わない UI では async job が安定します。backend が job を作り、frontend は status を polling するか subscribe します。この形なら browser request が全時間を持つ必要がなく、失敗時も「まだ実行中」と「失敗したので新規 job が必要」を分けられます。
再試行で rate limit を悪化させない
local timeout のあと即座に retry すると、上流でまだ動いている job と新しい job が並びます。これが複数ユーザーで起きると、RPM、TPM、IPM、daily limit、429 に近づきます。再試行は必要ですが、original job の状態を知らない再試行は危険です。
| 条件 | retry の扱い |
|---|---|
| local timeout | 既存 job がまだ動いていないか先に確認 |
| 429 または limit headers | reset header と jitter backoff に従う |
| 5xx | 最大回数付きの限定 retry |
| ユーザーの二重クリック | pending job を返すか、新規生成の確認を出す |
| gateway 内部 retry | 自社 retry と別に数える |
429 や quota が主題になったら /ja/blog/openai-api-rate-limit/ や /ja/blog/gpt-image-2-usage-limits/ に分けます。latency 対応を hidden quota workaround にしないことが大事です。
OpenAI direct、Azure、gateway、reverse route を分ける
OpenAI direct なら model ID、endpoint、request ID、status、headers を見ます。Azure なら deployment、region、quota、APIM、regional status を見ます。compatible gateway なら base URL owner、upstream mapping、provider timeout、retry policy、log visibility を見ます。reverse route なら account/session owner、hidden retries、policy boundary、support risk まで分けます。
同じ prompt が direct では速く gateway では遅いなら、モデルだけの問題ではありません。gateway が透明なログを出せず、local timeout と upstream wait を分けられないなら、production latency diagnosis には不十分です。費用や接入選択は /ja/blog/gpt-image-2-api-cheap/ に渡し、ここでは時計と所有者を守ります。
エスカレーションには脱敏した証拠を送る

送るべきものは、timestamp、timezone、再現頻度、route owner、model、endpoint、streaming の有無、quality、size、format、reference images、first byte、partial image、final image、download、render、timeout layer、retry count、returned status、request ID、worker/runtime、proxy、CDN、browser timeout、最小再現条件です。
送ってはいけないものは、API key、token、private prompt、private image、customer identifier、IP、channel ID、account-pool details、raw logs です。最後の判断は具体的にします。一つの timeout を広げる、async job に移す、draft quality を下げる、format を変える、高解像度を分ける、backoff を直す、またはログを持つ route owner に渡す、のどれかです。
最小再現テストを作る
主要な時計を記録できたら、次は最小再現テストです。一回のテストで route、quality、size、format、retry、timeout を同時に変えないでください。複数の値を同時に動かすと、速くなった理由も、まだ遅い理由も説明できません。
順番は単純にします。まず同じ prompt、同じ quality、同じ size、同じ format、同じ route owner で三回走らせ、遅さが安定しているか一時的な揺れかを見ます。次に待ち方だけを変えます。browser が同期で待つ形と、backend job id を返して polling する形を比べ、browser timeout が消えるか確認します。その後、format だけを JPEG、PNG、WebP で比べ、download_ms と render_ms を見ます。quality はその次です。最後にだけ OpenAI direct、Azure、gateway の route owner を比較します。
| テスト | 固定するもの | 一つだけ変えるもの | 判断すること |
|---|---|---|---|
| 基準 | prompt、quality、size、format、route | 同条件で三回 | 遅さが安定しているか |
| 同期と非同期 | prompt、参数、route | 待ち方 | browser timeout が消えるか |
| 出力形式 | prompt、quality、size、route | JPEG / PNG / WebP | download と render の影響 |
| quality | prompt、size、format、route | low / medium / high | final_image_ms の変化 |
| route owner | prompt、参数、retry policy | direct / Azure / gateway | 遅さが route に属するか |
このテストで、high quality だけが遅いなら「API 全体が遅い」とは言いません。browser の同期 path だけが失敗するなら upstream のせいにしません。gateway だけが遅いなら、OpenAI direct の挙動と混ぜません。最小再現の目的は、責任を広げることではなく、直せる層まで狭めることです。
チーム内では結果を一つの表に残します。時刻、timezone、route owner、base URL の所有者、streaming の有無、async の有無、参数、first byte、final image、失敗層、retry count、補足を書いておくと、後から support に渡す時も話が早くなります。
本番前のガードレール
遅い path を直した後も、本番には guardrail が必要です。生成ボタンには pending 状態を持たせ、同じ job が終わる前に二回目の生成を作らないようにします。backend は同じ user、同じ prompt、同じ参数、同じ route owner の pending job を返し、新しい job を作らない設計にします。エラー表示は local timeout、gateway timeout、upstream error、returned API error を分けます。監視は route owner ごとに分け、OpenAI direct、Azure、gateway、自社 proxy の平均を一つに混ぜないでください。
成功した job も監視対象です。最終画像は返ったが first_byte_ms が長い、final_image_ms は短いが download_ms と render_ms が重い、retry は少ないがユーザーの二重クリックが多い、といったケースは障害ではなくても体験を壊します。画像生成の本番運用では、成功率だけでなく、どの段階で待ったか、ユーザーに何を見せたか、同じ仕事を重複して作っていないか、support に渡せる証拠があるかを一緒に見ます。
さらに、route をまたぐ比較には必ず注記を入れます。direct は公式モデルとパラメータの話、Azure は deployment と region の話、gateway は中継設定と upstream mapping の話、frontend は browser timeout と render の話です。この境界を守ると、読者は間違った層を修正せずに済み、チームも private logs、account details、channel data を公開の説明に混ぜずに済みます。
よくある質問
GPT Image 2 API は普通に遅いことがありますか?
あります。複雑な生成は長くなります。ただし browser や proxy が先に落ちるなら正常待ちではなく偽のタイムアウトです。first_byte_ms と final_image_ms を分けて見ます。
60 秒 timeout は短すぎますか?
複雑な image job には短いことがあります。とはいえ全ての timeout を広げず、失敗した層だけを画像 route または background job に合わせます。
Streaming は最終画像を速くしますか?
保証しません。ユーザーに進行を見せ、二重クリックを減らすための仕組みです。final image time は別に測ります。
まず quality を下げるべきですか?
draft や preview なら有効です。production asset では、まず slow clock を測り、品質変更は controlled test として行います。
gateway が遅いかはどう見ますか?
同じ prompt、quality、size、format でより直接のルートと比べます。base URL owner、upstream status、retry count、first byte、final image time、status code を記録してください。