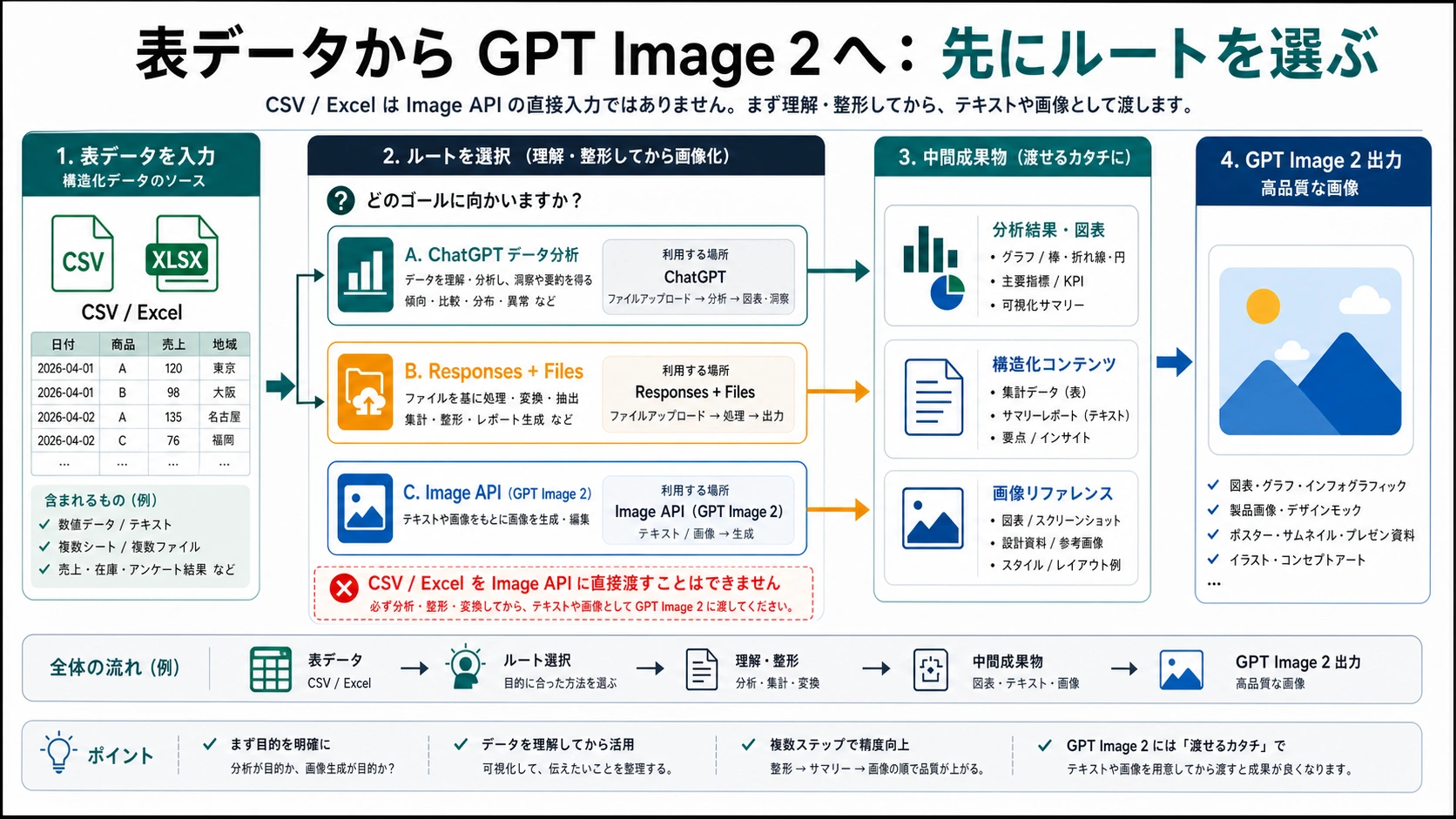
GPT Image 2のImage APIに.csvや.xlsxをそのまま渡して画像を作ることはできません。表ファイルはまずデータ処理の対象です。列名を読み、単位をそろえ、必要な行だけを選び、数値を計算し、画像で伝えるべき一文を決める必要があります。その後で、GPT Image 2にはテキスト指示、視覚ブリーフ、グラフのスクリーンショット、または画像リファレンスを渡します。
使い分けは明確です。ChatGPTのデータ分析は、人がファイルをアップロードして内容を確認する入口です。Responses + Filesは、アプリの中でファイル文脈、抽出、ツール呼び出しをつなぐ入口です。Image APIは、最後に画像を生成または編集する入口です。この三つを一つの「Excelをアップロードして生図」機能として扱うと、見た目は整っていても数値や結論が違う画像になりやすくなります。
| やりたいこと | 間違いやすい直接ルート | 選ぶべき入口 | 止める基準 |
|---|---|---|---|
| 表の行からインフォグラフィックを作る | CSVやXLSXをImage APIへ直接送る | 先に分析し、短い視覚ブリーフをGPT Image 2へ渡す | 生のワークブックを画像として扱わない |
| Excelのグラフを見やすく作り直す | ワークブックを画像リファレンスと呼ぶ | グラフをPNG/JPGに書き出して使う | 表ファイルと画像ファイルを混同しない |
| 商品、財務、レポート画像を自動生成する | 画像モデルに表の読解まで任せる | コードで解析、検証、集計してから画像生成する | 計算とプライバシー制御は画像呼び出しの前で行う |
| PPTX、PDF、XLSXを納品する | GPT Image 2がOfficeファイルを出すと期待する | 画像素材を生成し、別レイヤーで文書を組み立てる | 画像モデルは画像データを返す |
表が担う役割を先に分ける
CSVやExcelは、分析対象のデータ、既存グラフの元データ、最終納品ファイルの一部という三つの役割を持ちます。GPT Image 2が得意なのは、意味と数値が決まったあとに視覚として表現する部分です。フィルタ、集計、単位変換、外れ値の処理、列の意味づけが残っているなら、まだ画像生成に進む段階ではありません。
手作業では、まずChatGPTのファイル対応セッションに表を置き、傾向、異常値、比較軸、可視化候補を出させます。ここで大事なのは画像を急がないことです。どの列を使ったか、計算式は何か、どの数値を画面に出すか、どの注意書きを残すかを先に固定します。
アプリや業務システムでは、通常の表計算ライブラリでファイルを読みます。必須列、日付形式、通貨、行数、空欄、個人情報、重複行を確認し、画像に必要な情報だけへ縮約します。画像モデルに「表を読んで良い感じにして」と頼むのではなく、画像モデルが描ける形まで人間またはコードが責任を持つ、という発想が必要です。
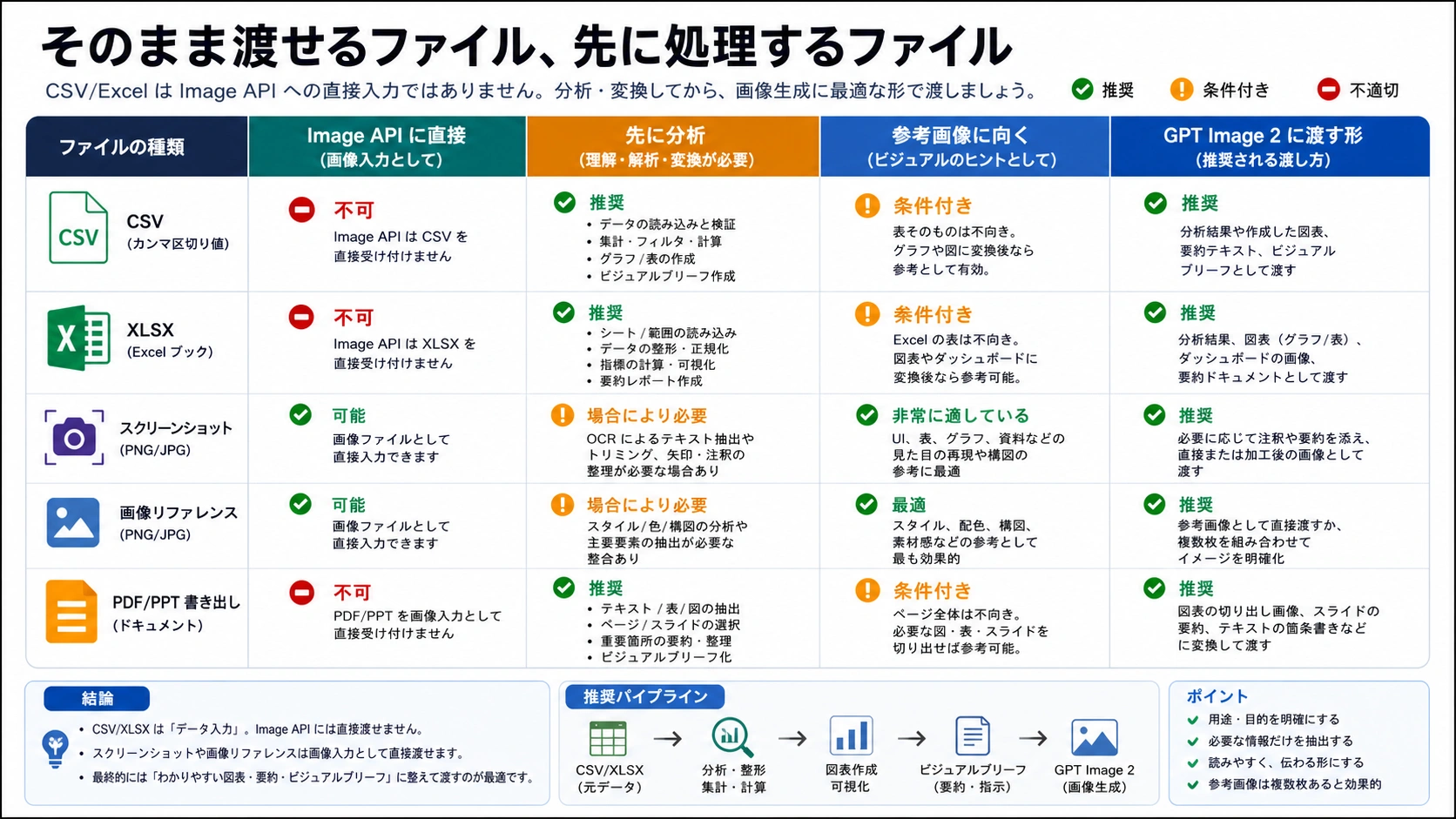
| 入力または出力 | Image APIへ直接渡せるか | より安全なルート | 理由 |
|---|---|---|---|
| CSVの行データ | いいえ | 解析または手動確認後に視覚ブリーフ化 | 行には計算、抽出、比較、説明が必要 |
| Excelワークブック | いいえ | 手作業ならChatGPTデータ分析、運用ならコード解析 | 複数シート、数式、非表示列、結合セル、書式の意味がある |
| グラフのスクリーンショット | 画像として使える | PNG/JPGで書き出し、変換したい方向を説明 | すでに画像なので視覚文脈になる |
| 表のスクリーンショット | 使えるが注意 | 必要範囲だけを切り出す | 小さいセル文字や大量数値は生成後の照合が必要 |
| 既存の商品画像やブランド画像 | 画像入力として使える | 権利と機密を確認して編集または参考ルートへ | これは画像編集であり表の読み取りではない |
| PPTX/PDF/XLSX出力 | いいえ | 画像素材を作り、別ツールで文書化 | 生成結果は画像データでありファイル構造ではない |
判断が早いほど失敗が減ります。データを理解したいならファイル分析か自前解析、既存の見た目を整えたいなら画像リファレンス、意味が固まっているならGPT Image 2へ短い視覚指示を渡します。
三つのOpenAI入口を混ぜない
ファイルアップロードという言葉は同じでも、入口ごとに契約が違います。ChatGPTでは、人がファイルをアップロードして会話しながら理解できます。Responses + Filesでは、アプリがファイルを文脈として扱い、抽出やツール呼び出しとつなげられます。Image APIでは、画像生成に必要なテキストや画像を渡します。一方の入口でファイルを扱えるからといって、もう一方の入口がワークブックを直接読むとは限りません。
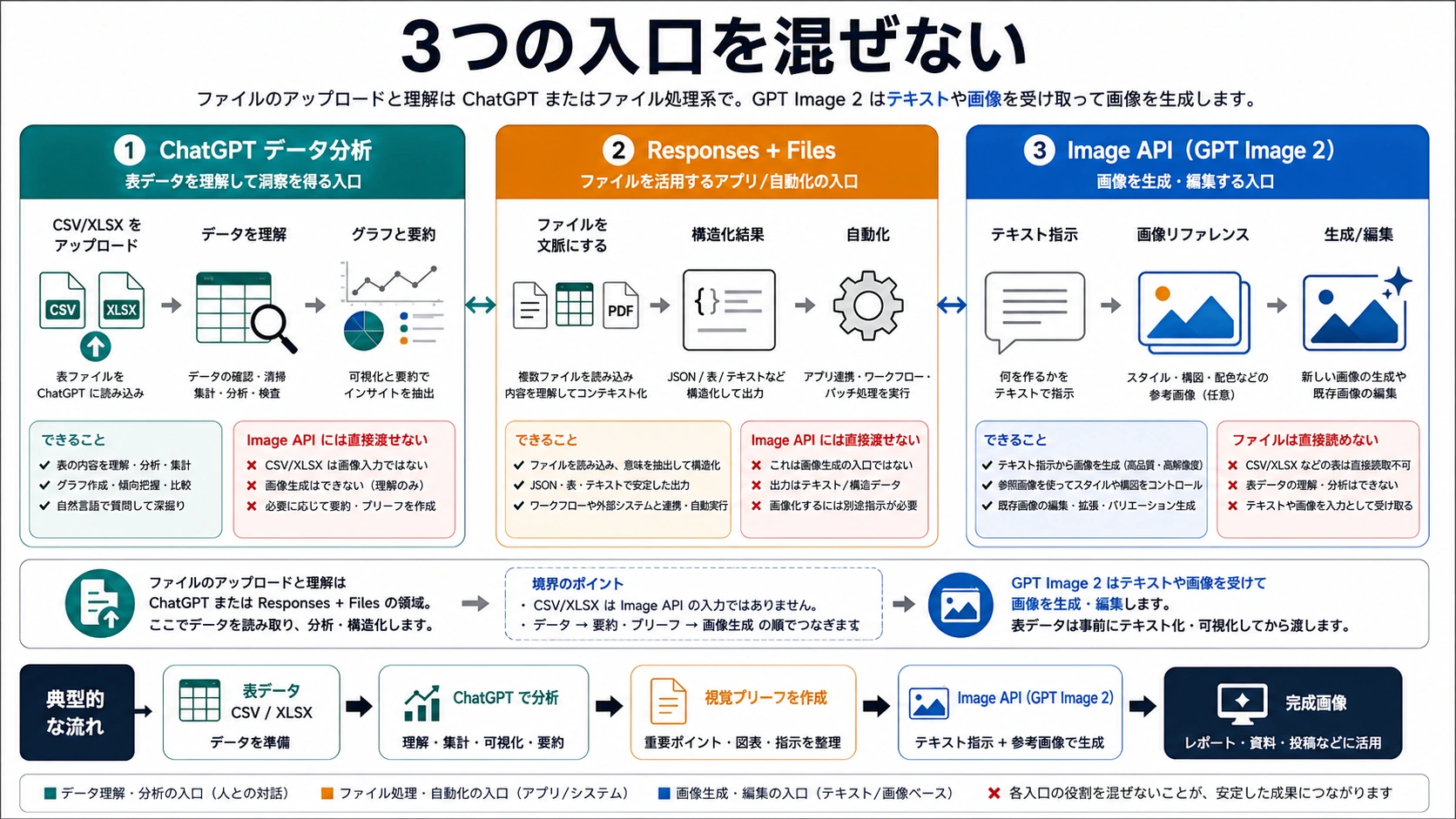
| 入口 | 向いている仕事 | 表の役割 | GPT Image 2の役割 | よくある誤解 |
|---|---|---|---|---|
| ChatGPTデータ分析 | 人がファイルを確認し、要約や図表案を得る | CSV/XLSXをアップロードして内容を読む | 分析結果を画像タスクへ変える支援 | UIでできることをImage APIの契約と同一視する |
| Responses + Files | アプリ内のファイル文脈と自動化 | 抽出、検索、前処理、構造化出力の材料 | 後続ステップとして画像生成できる | file contextを画像モデルの直接読解だと思う |
| Image API生成 | すでに描く内容が決まっている画像生成 | 表の内容は短い指示へ変換済み | gpt-image-2が画像をレンダリングする | JSONのpromptが必要な場所へworkbookを送る |
| Image API編集/参考 | 既存画像の変換や参考 | グラフや表を画像として書き出す | 画像リファレンスと指示に従う | 生のXLSXを画像参考と呼ぶ |
| Files API | 対応目的のためにファイルを保存 | 下流の目的が対応している時だけ意味がある | Image APIへの万能橋ではない | CSVを保存すればGPT Image 2が読めると思う |
直接生成が適しているのは、アプリがすでに描く内容を知っている場合です。たとえば「16:9の財務インフォグラフィック。Q4売上は4.8M、北米が44%、APACが+18%で最速、12月の返金が10月の2.3倍。棒グラフ、強調吹き出し、警告帯を使う」という指示は画像向けです。生のワークブックはまだ画像向けではありません。
Responsesの流れが有効な場合でも、境界は残ります。周辺ワークフローがファイルを読み、必要な値を取り出し、構造化してから、画像生成ステップへ渡します。画像ステップに渡すのは、ファイルそのものではなく、画像化できる情報です。
直接アップロードが失敗する理由
Image APIの生成は、promptから画像を作る動作です。promptには表から得た事実を含められますが、endpoint自体がワークブック解析器になるわけではありません。数式、非表示列、フィルタ、単位、空欄、異常値、業務上の注意は、画像リクエストの前に決める必要があります。
編集や参考のルートでは、画像入力を文脈として使います。グラフのスクリーンショット、表のスクリーンショット、手書きラフ、以前の生成画像、商品写真などが対象です。.xlsxはファイルであって、画像ではありません。表の見た目を保ちたい場合は、該当範囲をきれいな画像として書き出し、不要なメニューや行番号を取り除き、どのように作り替えるかを指定します。
Files APIも混乱の原因になります。ファイルを保存できても、そのfile_idがあらゆるendpointで使えるわけではありません。画像リファレンスとして使うなら画像ファイルである必要があります。検索や文書処理ならテキスト/ドキュメントの流れです。batchやfine-tuningなら目的も形式も別です。
したがって、表から画像へ進む流れは二段階です。データ段階では、読み取り、検証、抽出、計算、要約、メッセージ決定を行います。画像段階では、そのメッセージを視覚としてレンダリングします。この二つを一つのpromptに押し込むと、列の取り違え、制約の欠落、数字の不一致、読めない小文字、存在しないラベル、見栄えは良いが業務判断に使えない画像が起きます。
手作業では視覚ブリーフを先に作る
手作業の流れは、社内レポート、営業サマリー、キャンペーン振り返り、会議用の初期案に向いています。人が途中で内容を確認できるからです。逆に、顧客向けの無人処理、機密表、厳密なログが必要なフローには向きません。
まずファイル対応のChatGPTセッションにCSVやExcelをアップロードし、画像ではなく分析を依頼します。
hljs textRead this workbook and focus only on the Revenue and Refunds sheets. Find the three strongest visual messages for a one-slide executive summary. For each message, list the required rows/columns, calculation used, and caveat that must appear in the visual.
次に、一つの候補だけを画像用ブリーフへ変換します。
hljs textTurn option 2 into a GPT Image 2 visual brief. Use no more than 6 labels, include the exact numbers that must appear, name the chart type, layout, color emphasis, and the sentence the reader should remember after 3 seconds. Do not generate the image yet.
この中間ブリーフが品質を守ります。分析、コピー、グラフ設計、画像生成を分けることで、誤った指標や曖昧な見せ方を早く見つけられます。ブリーフの数値が間違っていれば、どれほど美しい画像でも失敗です。ブリーフが曖昧なら、モデルはレイアウトやラベルを想像で補います。
複数の図を作る場合は、図ごとにブリーフを作ります。一つのワークブックから、ルートマップ、トレンド、前後比較、リスクチェック、商品カードが生まれることがあります。それぞれ読者の判断が違うため、同じ表を使っていても同じpromptにまとめない方が安定します。
開発では表解析を画像生成の前に置く
繰り返し使う処理では、決定論的なデータ層が必要です。商品カタログ、週次レポート、顧客向けダッシュボード、広告バリエーション、多言語インフォグラフィックは、画像モデルの推測に任せるべきではありません。

安全な実装は五段階です。まず一般的な表計算ライブラリでCSV/XLSXを読みます。次に必須列、型、単位、日付、行数を検証します。三つ目に、画像に必要な小さなpayloadへ縮約します。四つ目に、payloadから視覚ブリーフを作ります。最後にGPT Image 2を呼び出し、元payload、生成prompt、response ID、画像ファイル、レビュー結果を一緒に保存します。
画像呼び出しへ渡す情報は、巨大な表ではなく短い視覚タスクにします。
hljs json{
"visual_type": "executive infographic",
"title": "Q4 revenue grew, but refund pressure moved to December",
"must_show": [
"Q4 revenue: $4.8M",
"North America: 44% of revenue",
"APAC: fastest growth at +18%",
"December refunds: 2.3x October"
],
"layout": "16:9 board with one bar chart, one callout, and one caution strip",
"tone": "clean finance report, high contrast, readable labels",
"do_not_invent": [
"Do not add regions not present in the payload",
"Do not change the numbers",
"Do not create a forecast"
]
}
短いpayloadは監査しやすく、モデルの自由度を必要な範囲に制限できます。画像に表示すべき数字、追加してはいけない地域、作ってはいけない予測を明示できます。あとで数字の出所を聞かれた時、どの行から来たか、どの変換を通ったか、どのpromptで描かれたかを追えます。
batch生成では、全ワークブックを毎回送るのではなく、出力一つにつきpayload一つにします。商品比較、地域別サマリー、更新リスク、在庫警告、顧客向けグラフを分けると、レビューが速くなり、誤読も減ります。
スクリーンショットと参考画像は視覚改造向け
ワークブック全体を理解する必要がなく、既存の図表を見やすくしたいだけなら、画像リファレンスを作ります。グラフまたは表をPNG/JPGとして書き出し、不要なタブ、メニュー、行番号、列記号、空白、注釈を取り除きます。
hljs textUse the attached chart as the data and layout reference. Redesign it as a clean 16:9 executive slide graphic. Preserve the region names, relative ordering, and visible numbers. Make labels large enough for a presentation screen. Do not add new numbers or forecast values.
この流れは、見た目の構造がすでにあり、階層、余白、ラベルサイズ、コントラスト、配色を改善したい時に向いています。逆に、スクリーンショットが密すぎる、数字が小さい、計算に隠れた行が必要、フィルタの条件が重要という場合は、データ段階に戻るべきです。
参考画像を使った後のレビューは、デザイン確認だけでは足りません。ラベル、数値、順序、単位、色、欠落行を元画像と照合します。数字や日付が入る画像は、装飾ではなく図表として確認する必要があります。
プライバシーと納品形態を分ける
表には顧客名、売上、社員情報、医療情報、法務文書、未公開の財務情報が含まれることがあります。便利だからという理由だけでアップロード先を決めるべきではありません。手作業なら、そのチャット環境にファイルを置いてよいかを確認します。アプリなら、保存場所、アクセス権、ログ、保持期間、削除手順、生成promptの扱いを確認します。
安全な流れは、生成前に最小化することです。不要な列を消し、行を集計し、個人名をカテゴリへ置き換え、画像に必要な合計値、ランキング、ラベルだけを残します。画像に「APACが+18%で最速」と出すだけなら、全取引明細は不要です。
納品ファイルも別レイヤーです。「ExcelからPowerPointを作る」という依頼は、一回の画像生成ではありません。データ分析、画像素材生成、スライド組み立て、書き出し、確認という流れです。GPT Image 2は視覚素材を作れますが、PPTXやPDFの構造は文書またはスライドの処理で組み立てます。
典型的な失敗を先につぶす
一つ目はfile_idの近道です。ワークブックをアップロードしてIDを得たあと、そのIDを画像リファレンスとして渡してしまう失敗です。画像リファレンスには画像ファイルが必要です。表ファイルのIDは、分析、検索、前処理の流れで使います。
二つ目は長い表をpromptへ貼ることです。大量の行を貼ると、モデルが間違った行を選び、注意書きを落とし、ラベルを作り、読めない小文字を描く可能性が上がります。短い視覚payloadの方が、巨大な表貼り付けより安定します。
三つ目はネイティブ文書出力の期待です。GPT Image 2は画像データを返します。PPTX、PDF、XLSXが必要なら、画像生成の後に別の組み立て工程を置きます。
四つ目は数字レビューの省略です。画像モデルは本物らしいグラフを描けますが、数字、日付、地域名、合計、商品名を誤ることがあります。公開前または顧客提出前に、ソースpayloadと画像を照合します。
五つ目は問題の分類を早く決めすぎることです。実際の障害がquotaや429なら GPT Image 2 usage limits guide が近いです。ChatGPTとAPIの選択なら ChatGPT Images 2.0 が近いです。コストやプロバイダ比較なら cheap GPT Image 2 API guide を使います。CSV/Excelの仕事はより狭く、表データを画像化できるpayloadへ変えることが中心です。
運用チームでは、データ担当、エンジニア、デザイン担当、レビュー担当の責任を分けると安定します。データ担当は口径を確認し、エンジニアは解析と脱機密を確認し、デザイン担当は視覚目的を確認し、最後に生成画像を照合します。この分解により、すべてのリスクを一つのpromptへ押し込まずに済みます。
よくある質問
GPT Image 2はCSVを直接アップロードできますか?
Image APIの直接生成入力としてはできません。CSVを先に解析または確認し、画像に必要な結論、数値、注意書きを短いpromptまたは視覚ブリーフにします。
Excelワークブックをそのまま渡せますか?
.xlsxを画像モデルのネイティブ入力として扱わない方が安全です。手作業ではChatGPTデータ分析、運用ではコード解析を使い、縮約済みpayloadを渡します。
ChatGPTで表を読んでから画像を作れますか?
ファイル対応のChatGPTセッションなら、表の分析から視覚ブリーフ作成までを支援できます。ただし、それは製品側の作業流れであり、ワークブックをImage APIへ直接渡すこととは別です。
Responses APIでfilesと画像生成を同じ流れに入れられますか?
可能です。ファイル文脈、ツール呼び出し、構造化出力、画像生成をつなげられます。ただし、最終画像ステップに必要なのはprompt、画像入力、または画像化できる指示です。
Files APIにCSVを置けばGPT Image 2が読めますか?
自動では読めません。Files APIは対応目的のためにファイルを保存します。保存済みの表ファイルが、そのまま画像リファレンスや生成入力になるわけではありません。
file_idは画像生成でどう使うべきですか?
画像ルートが対応するファイル種別と場所でのみ使います。画像ファイルのIDは参考画像になり得ます。表ファイルのIDは分析、検索、前処理の文脈で扱います。
スクリーンショットは原始データより良いですか?
見えているグラフをデザインし直すだけなら良い選択です。隠れた行、計算式、フィルタ、正確な集計が必要なら、原始データを解析してpayloadを作ります。
大きい表はどう処理しますか?
全体を画像ステップに渡しません。不要列を削り、行を集計し、目的の数値とラベルだけを残します。機密データでは、自社側で解析、脱機密、ログ管理を済ませます。
GPT Image 2はPPTX、PDF、XLSXを出力できますか?
GPT Image 2の出力は画像データです。PPTX、PDF、XLSXが必要な場合は、画像素材を作ったあとで文書またはスライド処理を行います。