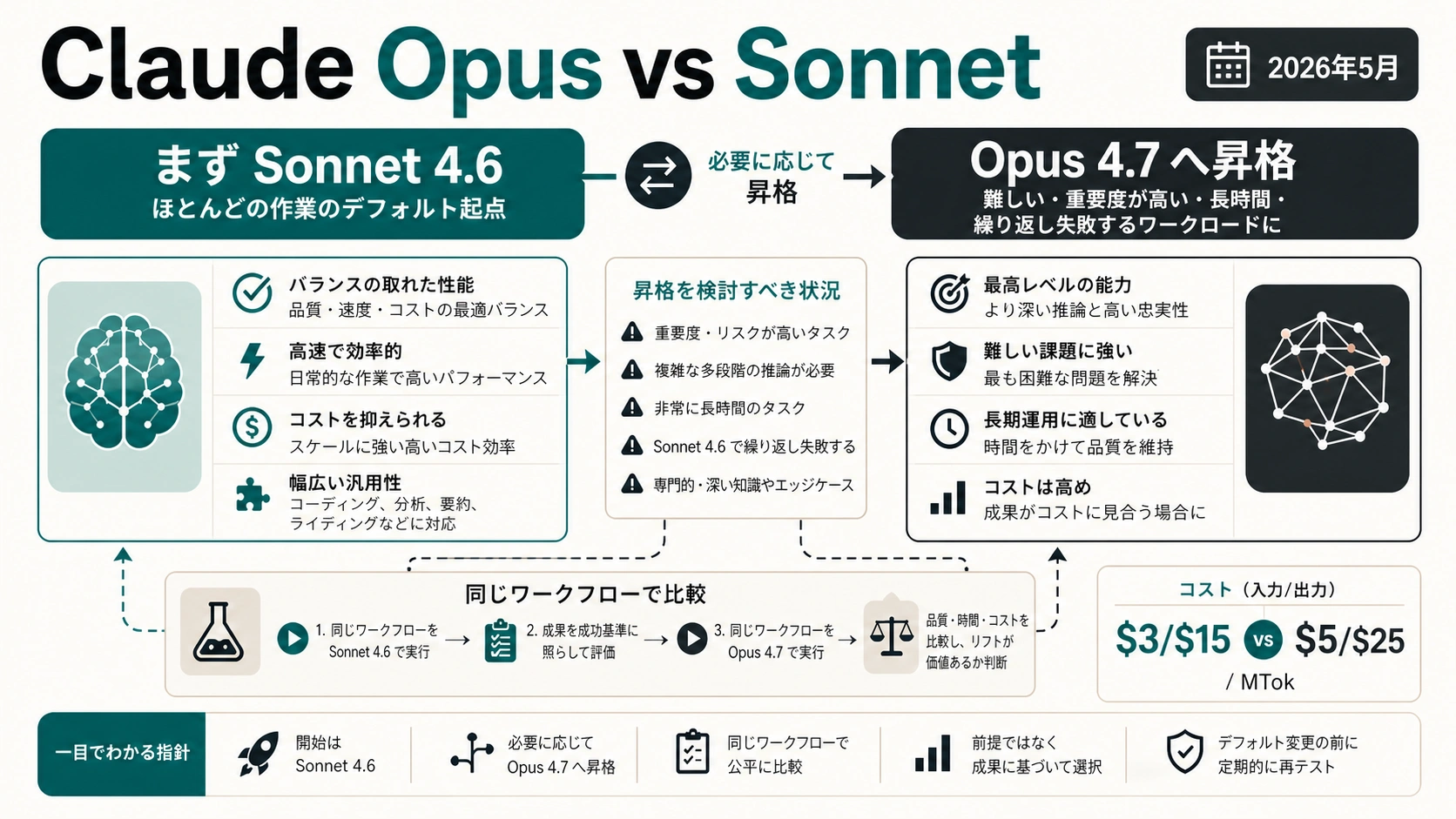
2026年5月7日時点では、Claude の多くの作業は Sonnet 4.6 から始めるのが現実的です。Opus 4.7 は、タスクが十分に難しく、失敗したときの損失が大きい場合に試す上位ルートです。Sonnet は速度、コスト、反復のしやすさを含めた標準モデルで、Opus は高リスクの推論、設計判断、長時間エージェント、重い文書読解、または Sonnet が同じ受け入れ基準で何度も止まる場面のためのエスカレーションです。
| 作業の状態 | まず試すモデル | Opus を試す境界 |
|---|---|---|
| 日常のコーディング、調査、文章作成、社内資料、ブラウザ操作 | Sonnet 4.6 | 同じ誤りを繰り返し、人間の修正が重くなる。 |
| API の大量処理や本番ワークフロー | Sonnet 4.6 | 失敗、再実行、レビュー時間の合計が Opus の差額を超える。 |
| 複数ファイルの設計、根本原因調査、制約の多い推論 | Opus 4.7 のテスト枠 | 実成果が改善しなければ Sonnet を基準に戻す。 |
| 長時間のエージェントや多段 workflow | Sonnet 基準と Opus 比較 | Opus のほうが計画を保ち、遠回りが少ない。 |
| 単純な抽出、分類、整形、ルーティング | Haiku 4.5 の別枠 | Haiku で足りなければ Sonnet、いきなり Opus ではない。 |
API の価格だけで決めると判断を誤ります。現在の Anthropic 文書では、Sonnet 4.6 は 100万 token あたり入力 $3、出力 $15、Opus 4.7 は入力 $5、出力 $25 とされています。ただし実際の費用は、出力の長さ、prompt caching、batch、thinking の設定、再試行、レビュー時間、さらに Opus 4.7 の tokenizer が同じ固定テキストをより多い token として数える場合があるという注意で変わります。

現在の比較は Opus 4.7 と Sonnet 4.6
日本語の比較情報には、Claude 4、Opus 4.1、Opus 4.5、Opus 4.6、Sonnet 4.5 を前提にした古い整理がまだ多く残っています。過去の使用感としては参考になりますが、いま決めたいのは、現在の Sonnet 4.6 を標準に置くか、Opus 4.7 へ上げる価値があるかです。
Anthropic の現在のモデル概要では、Opus 4.7、Sonnet 4.6、Haiku 4.5 が主要な選択肢として扱われています。Opus 4.7 は専門的なソフトウェアエンジニアリング、複雑な推論、エージェント型ワークフロー、上級コーディング、高リスクの企業タスクに向いたモデルです。Sonnet 4.6 は、日常作業、スケールする本番処理、コーディング、エージェント、ブラウザや computer use、長いコンテキスト、コスト効率の良い処理に向くバランス型です。
| 現在の公式行 | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| 実務での役割 | 多くの作業の標準モデル | 最難関作業の上位モデル |
| API 価格、2026-05-07 確認 | $3 入力 / $15 出力 per MTok | $5 入力 / $25 出力 per MTok |
| レイテンシ | Fast | Moderate |
| コンテキスト | 1M | 1M |
| 最大出力 | 64k | 128k |
| thinking | Extended thinking と adaptive thinking | Adaptive thinking |
| 最初の用途 | 日常作業、コード反復、本番処理 | 深い推論、agent coding、高リスク判断 |
Haiku 4.5 は補助線として扱えば十分です。単純な抽出、分類、整形、低リスクのバッチ処理では有効ですが、Opus と Sonnet のページの中心に置くべきではありません。
Sonnet 4.6 を標準にすべき場面
Sonnet の強みは、単に安いことではありません。十分な知能を持ちながら、反応が速く、コストが読め、検証しやすいことです。日常のコーディング、PR レビュー、ドキュメント作成、データ整形、構造化要約、サポート仕分け、ブラウザ操作、オフィス分析、多くの API 本番処理では Sonnet を先に試すのが自然です。
明確な指示、測定できる出力契約、失敗を検知する仕組みがあるなら、Opus から始めても結果が変わらないことがあります。本番ではモデル名の強さより、受け入れ可能な出力に到達する総コストが重要です。Sonnet で十分な品質が出るなら、浮いた予算をテスト、検証、二段階レビュー、より多いコンテキスト投入に回せます。
Sonnet から始めるべき条件は次の通りです。
- 出力をテスト、schema、ルール、人間レビューで確認できる。
- 頻度が高く、token 価格が累積しやすい。
- 深い一発回答よりも速い反復が必要。
- prompt と成功条件が明確。
- モデルに戦略創造よりも手順実行を求めている。
- 失敗を retry、lint、unit test、二重チェックで捕まえられる。
Claude app のユーザーにとっても、Sonnet は通常の出発点です。API チームにとっても、現在の価格行が低く、スケール用途に向くため、最初の本番候補にしやすいモデルです。
Opus 4.7 を試す価値がある場面
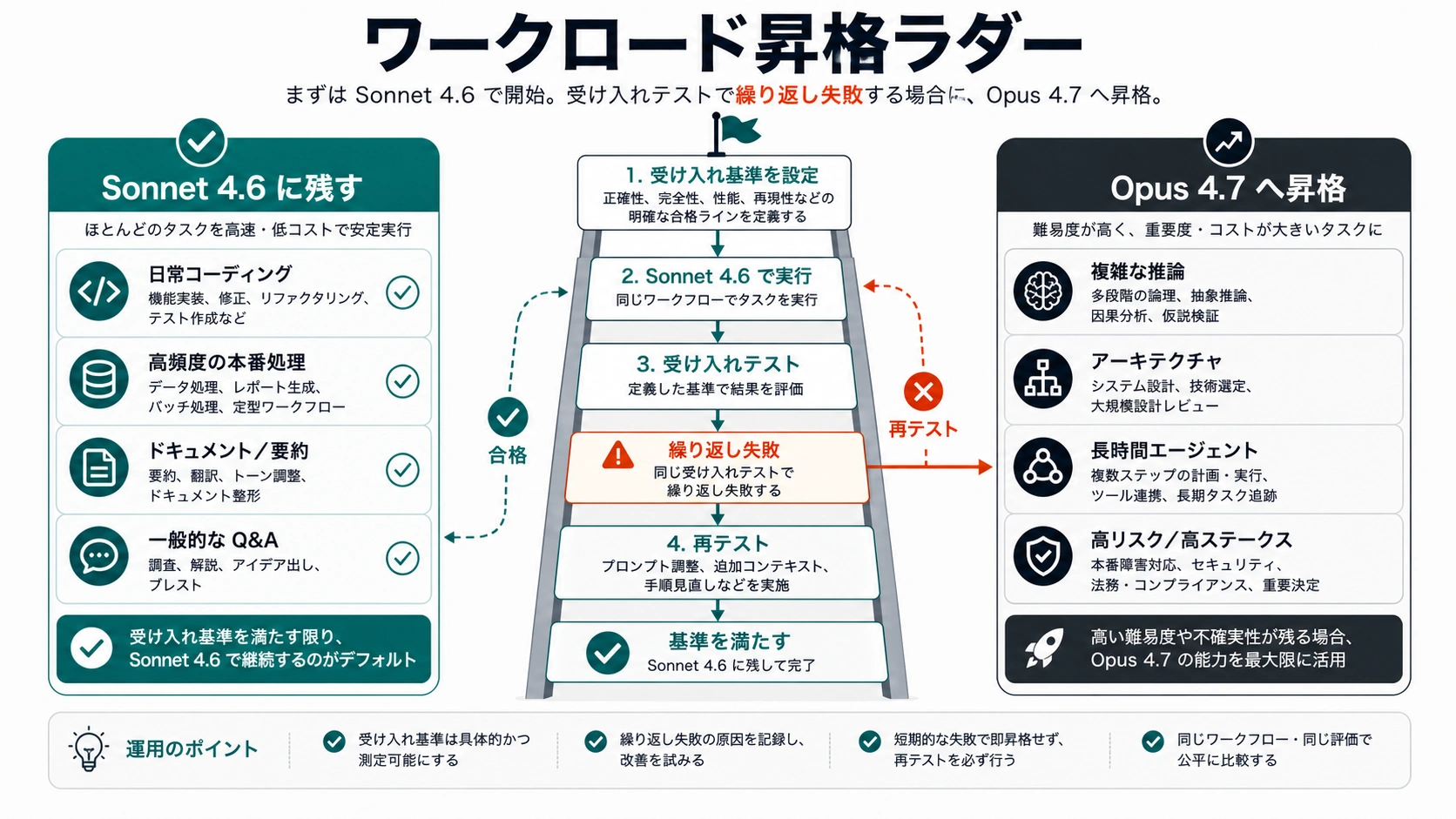
Opus は、失敗の損失が大きい、文脈が複雑、判断が曖昧、安い再試行では改善しない、という場面で価値が出ます。重要なタスクなら何でも Opus という意味ではありません。より深い推論、長い計画維持、文脈の扱いの安定性が成果を変えるときに使います。
Opus 4.7 のテスト枠を作る条件は次の通りです。
- Sonnet が prompt 改善後も同じ基準を外す。
- 複数ファイル、複数システム、複数制約の設計判断が必要。
- 長い文書群を読み、例外やニュアンスを保つ必要がある。
- 長時間 agent が計画を失う、ループする、脆い近道を取る。
- エンジニアリング、法務、財務、企業判断に直結する。
- 根本原因調査で、もっともらしい短絡が高くつく。
- 人間のレビュー時間が最大コストになっている。
Opus はすべての prompt の上位互換ではありません。Sonnet と同じ答え、または文体だけの改善なら Sonnet に残します。Opus が悪い設計判断を防ぎ、隠れた依存を見つけ、Sonnet では安定しない長い実行を完了させるなら、その差額に意味があります。
コスト差は料金表だけでは決まらない
Anthropic の pricing は token 価格の正しい参照先ですが、料金表は workload の全コストではありません。Sonnet 4.6 の $3/$15 と Opus 4.7 の $5/$25 は基礎差にすぎません。実支出は、出力長、cache の書き込みと命中、batch の可否、thinking の強さ、tool schema、繰り返しコンテキスト、再試行、レビュー時間で変わります。
さらに現在の pricing では、Opus 4.7 は新しい tokenizer を使い、内容によって同じ固定テキストが最大 35% 多い token として数えられる可能性があるとされています。これは毎回 35% 高いという意味ではなく、Sonnet の過去 token 数に Opus の価格を掛けるだけでは移行見積もりにならないという意味です。
| コスト層 | 判断への影響 |
|---|---|
| 入力と出力の単価 | Opus は token あたり高い。 |
| 出力長 | 深い回答は長くなりやすく、予算制限が必要。 |
| prompt caching | 繰り返し入力を下げられるが、cache write も考える。 |
| batch | 非同期処理なら安くできる場合がある。 |
| thinking | 難問の質を上げるが、遅延や費用も増える。 |
| tokenizer | 同じテキストでも Opus 4.7 では token 数が変わる可能性。 |
| レビュー時間 | 高いモデルでも手戻りを減らせば総コストは下がる。 |
問いは「どちらの単価が安いか」ではなく、「この workflow で受け入れ可能な出力に一番安く到達するのはどちらか」です。
デフォルトを変える前に同じワークフローで比べる
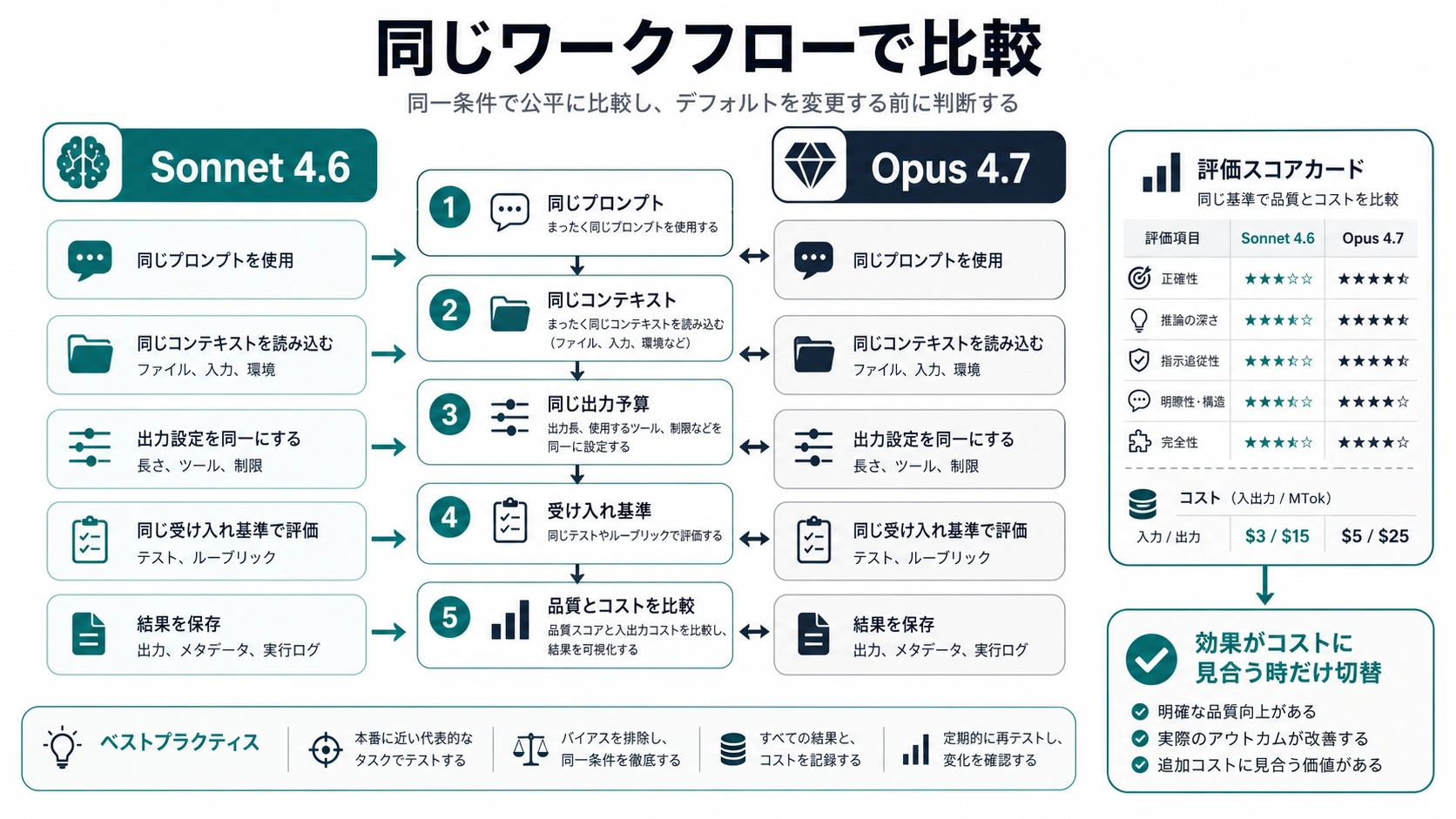
モデル名だけで production default を変えないでください。公平な比較では prompt、context、output budget、tools、受け入れ基準をそろえます。ここがずれると、モデル差ではなくタスク差を測ってしまいます。
小さな検証手順は次の通りです。
- 実ワークフローから三つから五つの代表タスクを選ぶ。
- 機密情報を除くか、承認済み環境でだけ実行する。
- 現在の prompt と予算で Sonnet 4.6 を走らせる。
- 同じ prompt、context、予算で Opus 4.7 を走らせる。
- 同じ受け入れ基準で採点する。
- token cost、latency、retry、レビュー時間、採用結果を記録する。
- Opus の改善が費用差を上回る slice だけ移す。
これは逆の失敗も防ぎます。Sonnet の単価だけを見て残し、再試行やレビューでより高くつくことがあるからです。多くのチームには、通常トラフィックを Sonnet、難しい例外を Opus に送る混合戦略が合います。
Claude app、API、Claude Code は同じ判断ではない
Claude app で選べるモデル、Claude Platform API で呼べる model ID、Claude Code のセッションで使われるモデルは関連していますが同じではありません。app ユーザーはプランとメッセージ制限を見ます。API 開発者は token 価格、rate limit、cache、batch、統合挙動を見ます。Claude Code ユーザーは、サブスクリプションログイン、API key、ローカル設定も確認する必要があります。
境界を分けると判断が楽になります。
- Pro、Max、API billing を選ぶ話なら、これはアクセスと請求の問題です。
- Claude Code を無料や Pro で使えるかなら、これは利用ルートの問題です。
- あるタスクをどのモデルに投げるかなら、ここで Sonnet、Opus、Haiku、またはテスト枠を選びます。
アクセスを買っても model routing は解決しません。Pro ユーザーでも Sonnet を標準にできます。Opus API にアクセスできるチームでも、難しい slice だけ Opus に送れます。Claude Code でも、まず現在のセッションがどのルートで課金されるかを確認すべきです。
よくある質問
Opus は Sonnet より常に上ですか?
Opus 4.7 は最難関タスクのための強い上位モデルですが、すべての作業の標準ではありません。速度、費用、規模が重要なら Sonnet 4.6 が先です。Opus は難度や失敗コストが差額を上回るときに試します。
先に使うべきなのは Opus ですか、Sonnet ですか?
ほとんどの作業では Sonnet 4.6 です。高リスク、曖昧、長時間、設計判断が重い、文書量が多い、または Sonnet が同じ受け入れ基準で失敗する場合に Opus 4.7 を比較します。
Opus は Sonnet よりどれくらい高いですか?
2026年5月7日時点の公式行では、Sonnet 4.6 は 100万 token あたり入力 $3、出力 $15、Opus 4.7 は入力 $5、出力 $25 です。実費は出力長、cache、batch、thinking、retry、tokenizer で変わります。
Sonnet はコーディングに十分ですか?
多くの coding loop、PR review、refactor、test、通常の agent には Sonnet 4.6 で十分です。複雑な設計、複数制約、根本原因調査、同じ基準の失敗が続く場合に Opus を試します。
Claude Code は Opus と Sonnet のどちらを使いますか?
Claude Code の挙動は製品、プラン、設定、ルートで変わります。Claude Code は作業面であり、Opus と Sonnet の選択そのものではありません。通常の作業は Sonnet、難しい repo task は Opus と同じ条件で比較します。
Haiku はどこで使いますか?
Haiku 4.5 は速度とコストの逃げ道です。抽出、分類、整形、低リスクの batch で使います。足りないときは Sonnet に上げ、すぐ Opus にはしません。
古い Opus 4.5 や Sonnet 4.5 の記事は使えますか?
歴史的な感覚としては読めますが、現在の判断は Opus 4.7 と Sonnet 4.6 の事実で更新すべきです。
チームはいつ両方を使うべきですか?
安い通常経路と難しい例外経路があるときです。Sonnet が通常処理を担当し、Opus は Sonnet が失敗する slice、深い推論、高いレビューコストのタスクを担当します。