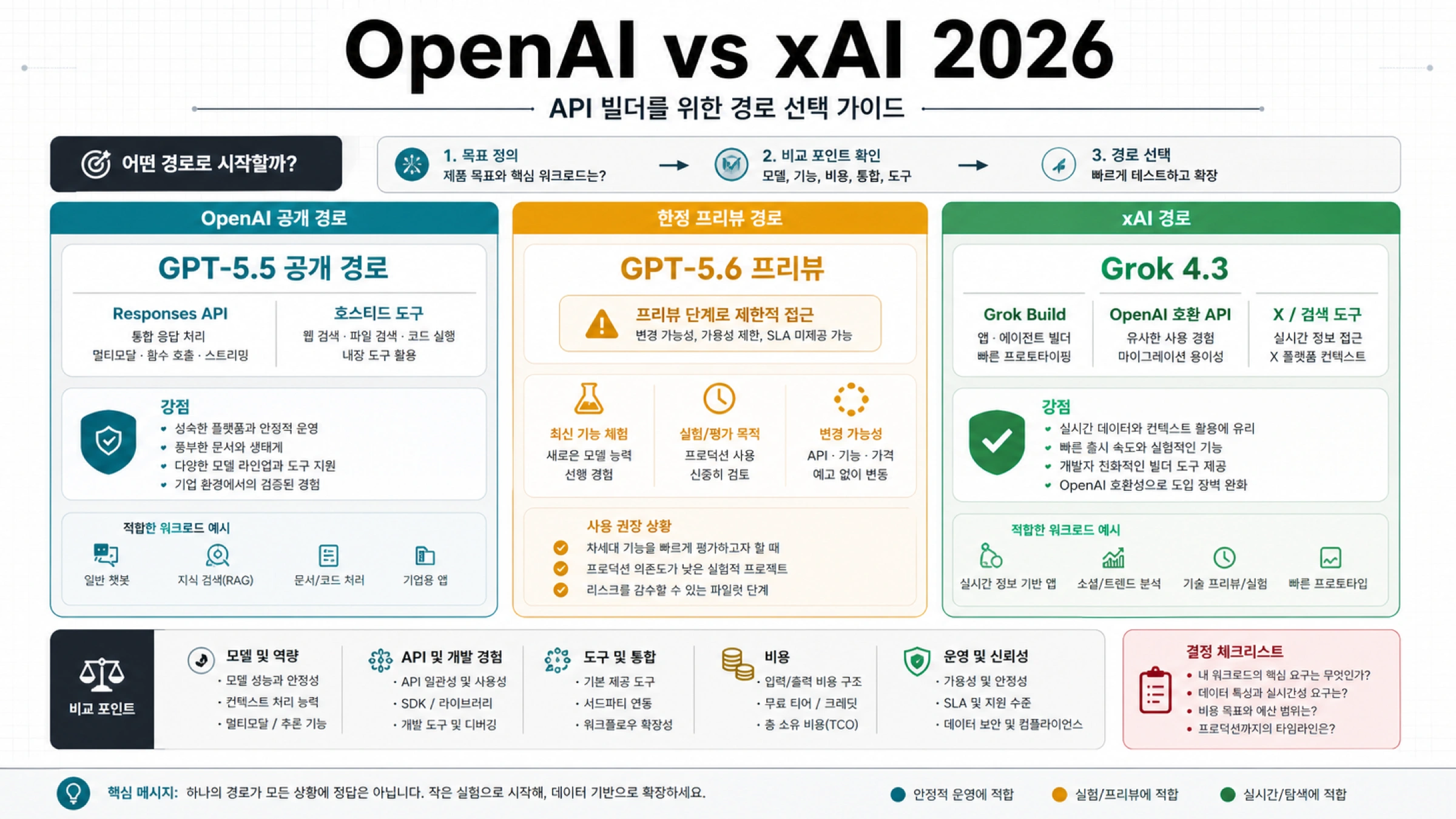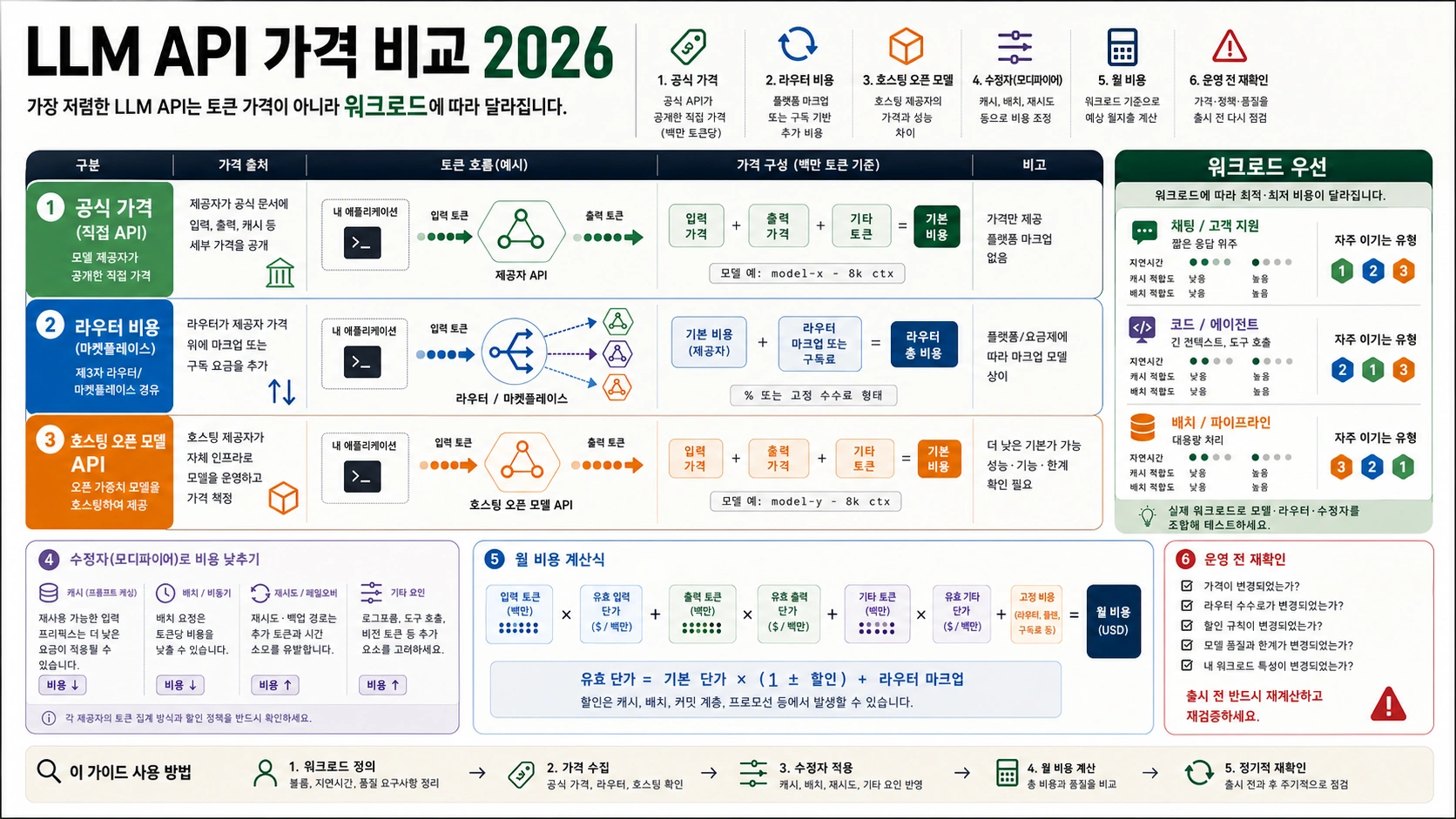
2026년 7월 2일 기준으로 LLM API의 최저가는 입력 토큰 단가만으로 정해지지 않습니다. 같은 작업을 합격 품질로 끝내는 비용, 즉 input, cached input, output, tool/search fee, router fee, retry, manual review를 함께 봐야 합니다. 개발자에게 필요한 것은 가격표 하나가 아니라 가격 owner, 호출 경로, 확인일, 단위, 그리고 청구액을 바꾸는 조건입니다. 공식 direct API, hosted open-model serving, router economics를 먼저 나눠야 같은 저가 후보라도 실제 운영 비용을 비교할 수 있습니다.
| 가격 경로 | 쓰는 경우 | 현재 증거를 읽는 법 |
|---|---|---|
| 공식 direct API | 공식 지원, 청구, 데이터 경로, 모델 약관이 필요할 때 | OpenAI, Anthropic, Gemini, DeepSeek, Mistral, xAI의 direct rows는 각 공식 문서가 owner입니다. |
| Hosted open-model API | 자체 GPU 없이 open-weight model을 저렴하게 serving할 때 | Groq-hosted GPT OSS, Llama, Qwen 가격은 Groq route price이지 모델 제작자의 공식 가격이 아닙니다. |
| Router 또는 marketplace | 하나의 계정으로 model switching, fallback, 비교가 필요할 때 | OpenRouter-style rows는 platform fee, request limits, routing behavior를 포함한 router economics입니다. |
먼저 이 공식으로 가짜 최저가를 걸러냅니다.
monthly API cost = uncached input + cached input + output + route/tool/search/request fees + retry overhead - batch/cache savings
bulk extraction, support bot, coding agent, long-context analysis, regulated workflow, offline batch는 서로 다른 후보가 이길 수 있습니다. 운영 전 availability, preview, cache/batch, Free Tier, data residency, router fee, deprecation을 다시 봅니다.
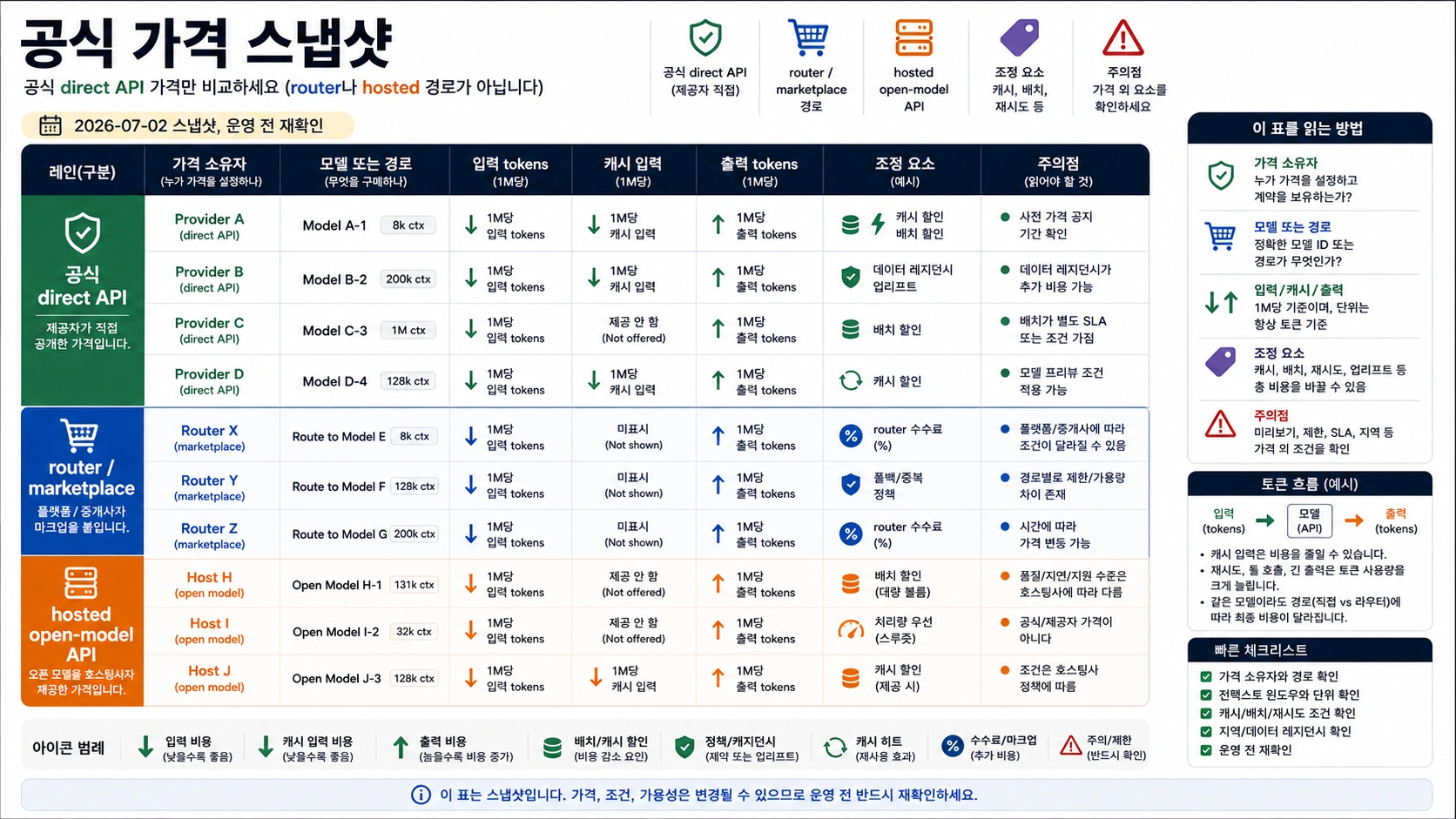
공식 direct API 가격 스냅샷
아래 표는 2026-07-02의 owner-labeled starting point입니다. 영구 순위가 아닙니다. 별도 표시가 없으면 USD / 1M tokens입니다.
| Owner / route | 2026-07-02 checked row | Input | Cached input | Output | Caveat |
|---|---|---|---|---|---|
| OpenAI direct API, Standard | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Standard, Batch, Flex, Priority는 서로 다른 가격 계약이며 일부 지역 처리에는 추가 비용이 붙을 수 있습니다. |
| OpenAI direct API, Standard | gpt-5.4-mini | $0.75 | $0.075 | $4.50 | 낮은 비용의 OpenAI 후보일 뿐 모든 워크로드의 최저가 모델은 아닙니다. |
| OpenAI direct API, Standard | gpt-5.5 | $5.00 | $0.50 | $30.00 | 품질 이득이 높은 출력 비용을 상쇄할 때만 후보로 둡니다. |
| Anthropic direct API | Claude Sonnet 5 intro row | $2.00 | 캐시 경로별 상이 | $10.00 | intro 가격은 2026-08-31까지이며 이후에는 입력 $3.00, 출력 $15.00 행으로 바뀝니다. |
| Anthropic direct API | Claude Haiku 4.5 | $1.00 | 캐시 경로별 상이 | $5.00 | cache write, cache hit, Batch, Fast mode, data residency가 청구액을 바꿉니다. |
| Google Gemini Developer API | gemini-3.1-flash-lite, Paid Tier Standard | $0.25 text/image/video, $0.50 audio | $0.025 text/image/video, $0.05 audio | $1.50 | Free Tier는 탐색용이고 운영 예산은 paid project와 데이터 조건으로 별도 계산해야 합니다. |
| Google Gemini Developer API | gemini-3.5-flash, Paid Tier Standard | $1.50 | $0.15 | $9.00 | Google Search와 Maps grounding은 포함량 이후 query fee를 더할 수 있습니다. |
| Google Gemini Developer API | gemini-3.1-pro-preview, Paid Tier Standard | $2.00 <= 200k, $4.00 > 200k | $0.20 <= 200k, $0.40 > 200k | $12.00 <= 200k, $18.00 > 200k | prompt length가 단가 구간을 바꾸며 preview status도 재확인해야 합니다. |
| DeepSeek direct API | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | deepseek-chat와 deepseek-reasoner는 V4 Flash mode로 매핑되며 2026-07-24 deprecation 예정입니다. |
| DeepSeek direct API | deepseek-v4-pro | $0.435 cache miss | $0.003625 cache hit | $0.87 | 공식 페이지는 1M context도 제시하지만 운영 전 latency와 품질 검증이 필요합니다. |
| Mistral 가격 | Mistral Large example | $2.00 | public FAQ 미기재 | $6.00 | Mistral은 input과 output token을 모두 청구하며 Batch는 50% discount입니다. |
| xAI model docs | Grok 4.3 | $1.25 | 미기재 | $2.50 | coding은 Grok Build 0.1을 별도로 보고 voice, image, video는 단위가 다릅니다. |
Hosted open-model API와 router는 더 싸 보일 수 있지만 다른 계약입니다.
| Route owner | 행 또는 계약 | 가격 신호 | 사용법 |
|---|---|---|---|
| Groq 가격 | openai/gpt-oss-20b hosted by Groq | $0.075 uncached input, $0.0375 cached input, $0.30 output | GroqCloud serving 가격이며 모델 제작자의 공식 API 가격이 아닙니다. |
| Groq 가격 | openai/gpt-oss-120b hosted by Groq | $0.15 uncached input, $0.075 cached input, $0.60 output | open-model workload의 cheap-first test 후보이나 품질과 latency 검증이 필요합니다. |
| OpenRouter 가격 | Pay-as-you-go plan | 5.5% platform fee, 400+ models, 70+ providers | router contract이지 underlying provider의 공식 가격이 아닙니다. |
| OpenRouter 가격 | Free plan | 50 requests/day, free-model access | 탐색용이지 운영 권리가 아닙니다. |
후보 모델이 표에 없다면 owner page로 가서 model ID, route, unit, checked date, caveat를 같은 형식으로 추가하세요.
워크로드별 저비용 후보
싼 모델은 같은 job을 acceptable quality와 retry rate로 통과할 때만 이깁니다. 첫 shortlist는 provider가 아니라 workload에서 시작합니다.
| 워크로드 | 먼저 테스트할 후보 | 싸질 수 있는 이유 | 중지 기준 |
|---|---|---|---|
| 대량 추출, 분류, 정규화 | DeepSeek V4 Flash, Gemini 3.1 Flash-Lite, Groq GPT OSS 20B, OpenAI GPT-5.4-nano | labels나 validators로 품질을 측정하기 쉬워 input/output 단가가 중요합니다. | false positive, retry, human-review rate를 세기 전에는 배포하지 않습니다. |
| 지원 챗봇과 FAQ | Gemini 3.1 Flash-Lite, OpenAI GPT-5.4-mini/nano, Claude Haiku 4.5, DeepSeek V4 Pro | output ratio가 중간이고 cached policy context가 도움 됩니다. | escalation quality가 떨어지면 낮은 token price가 낮은 비용이 아닙니다. |
| Coding assistant 또는 agentic tool use | Claude Sonnet 5, OpenAI GPT-5.4/GPT-5.5, xAI Grok Build, Gemini 3.5 Flash | 실패가 retry와 developer time을 만듭니다. | same-repo eval, tool-call success, rollback cost를 봅니다. |
| Long-context analysis | Gemini Pro/Flash long-context, DeepSeek V4 1M context, Grok 4.3 | 큰 call 하나가 chunking + retrieval보다 쌀 수 있습니다. | context tier나 cache storage가 바뀌면 재계산합니다. |
| 규제, 민감, enterprise workflow | Direct provider API 또는 contracted cloud route | billing, data handling, audit logs, support가 낮은 단가보다 중요할 수 있습니다. | router token row만 보고 옮기지 않습니다. |
| Offline batch | OpenAI Batch, Google Batch, Mistral Batch, Groq Batch | 비동기 작업은 discount를 받을 수 있습니다. | latency route가 아니므로 completion window와 output retrieval을 확인합니다. |

월간 비용 워크시트
실제 청구액은 token mix에서 시작합니다. 모든 후보에 같은 workload shape를 적용합니다.
- Monthly uncached input tokens.
- Monthly cached input tokens 또는 cache-hit rate.
- Monthly output tokens, output으로 billed되는 reasoning/thinking tokens 포함.
- Tool, search, request, route 또는 platform fees.
- Retry와 fallback overhead.
- Batch/cache savings.
- 출력이 통과하지 못할 때의 human-review 또는 failure cost.
| Scenario | Candidate route | Token mix | Simple monthly token cost | Interpretation |
|---|---|---|---|---|
| Bulk data cleanup | Groq GPT OSS 20B | 100M input, 10M output | $10.50 | hosted open model이 검증을 통과하면 매우 저렴합니다. |
| Bulk data cleanup | DeepSeek V4 Flash | 100M cache-miss input, 10M output | $16.80 | direct DeepSeek row는 낮지만 품질과 latency를 봅니다. |
| Bulk data cleanup | OpenAI GPT-5.4-nano | 100M input, 10M output | $32.50 | OpenAI compatibility나 output quality가 중요하면 후보입니다. |
| Bulk data cleanup | Gemini 3.1 Flash-Lite | 100M text input, 10M output | $40.00 | cache/Batch로 낮아질 수 있지만 Free Tier를 운영 가정으로 두지 않습니다. |
| Output-heavy chatbot | Groq GPT OSS 20B | 20M input, 20M output | $7.50 | output도 싸지만 open-model quality가 통과해야 합니다. |
| Output-heavy chatbot | DeepSeek V4 Flash | 20M cache-miss input, 20M output | $8.40 | output price가 낮습니다. hallucination과 escalation cost를 봅니다. |
| Output-heavy chatbot | OpenAI GPT-5.4-nano | 20M input, 20M output | $29.00 | output cost가 지배합니다. 품질이 이길 때만 씁니다. |
| Output-heavy chatbot | Gemini 3.1 Flash-Lite | 20M text input, 20M output | $35.00 | Gemini ecosystem fit이 retry를 줄이면 후보입니다. |
modifier를 더합니다. OpenAI GPT-5.4-nano에서 반복 system prompt의 40%가 cached input이면 그 부분은 $0.20/M에서 $0.02/M로 내려갑니다. Gemini 3.1 Flash-Lite를 Batch로 돌리면 input은 $0.25/M에서 $0.125/M, output은 $1.50/M에서 $0.75/M로 내려갑니다. OpenRouter route의 5.5% fee는 direct billing과 비교하기 전에 1.055를 곱합니다.
마지막 지표는 completed task cost입니다.
price per completed task = total monthly route cost / accepted task count
cheap route가 94%만 통과하고 비싼 route가 99.5% 통과하면 차이는 retries, fallbacks, manual review, support tickets가 됩니다.

Direct API, router, hosted open model, self-host의 차이
Direct API와 router는 ownership 문제가 다릅니다. 공식 support, billing clarity, data route, enterprise controls, incident diagnosis가 중요하면 direct provider API가 더 명확합니다.
Router는 model switching, fallback, traffic comparison, single integration에 유용합니다. OpenRouter의 5.5% platform fee, free limits, routing behavior를 cost model에 넣습니다.
Hosted open-model APIs는 중간입니다. Groq는 serving price, limits, latency, roster의 owner입니다. openai/gpt-oss라는 label이 OpenAI API price를 뜻하지 않습니다.
Self-hosting은 volume, data locality, hardware access, ops capacity가 있을 때만 비교합니다. free weights는 GPU utilization, serving, monitoring, security patching을 숨깁니다.
단순 가격표를 망가뜨리는 비용 요소
첫 함정은 output ratio입니다. chatbot이나 report generator는 input보다 output에 더 많이 쓸 수 있습니다.
두 번째는 caching입니다. OpenAI, Google, Anthropic, DeepSeek, Groq는 cache semantics와 rows가 다릅니다.
세 번째는 Batch입니다. offline extraction, eval generation, enrichment용이지 realtime chat과 같은 product가 아닙니다.
네 번째는 tool/search fees입니다. web search, Google Grounding, compound tools, router features가 token row 밖 비용을 만듭니다.
다섯 번째는 preview, intro, tier thresholds입니다. Sonnet intro row에는 종료일이 있고 Gemini Pro Preview는 prompt length로 바뀌며 DeepSeek alias는 deprecation이 있습니다.
마지막은 retry overhead입니다. accepted answer 하나에 평균 1.3 attempts라면 1.3배 비용으로 봅니다.
Provider별 메모
OpenAI pricing page는 OpenAI direct API token rows의 owner이며 Standard, Batch, Flex, Priority를 분리합니다.
Anthropic pricing page는 Claude direct rows와 cache, Batch, Fast mode, data residency modifiers의 owner입니다. subscription 비교는 Claude API pricing versus subscription을 봅니다.
Google Gemini pricing page는 Developer API rows, Free Tier, Batch, grounding fees를 분리합니다. free quota는 Gemini API free tier를 봅니다.
DeepSeek pricing은 deepseek-v4-flash와 deepseek-v4-pro를 표시하며 legacy chat/reasoner names는 V4 Flash mode로 mapping됩니다.
Mistral은 Mistral Large example과 50% Batch discount를 인용할 수 있지만 다른 row는 official evidence가 필요합니다.
xAI docs는 chat에는 Grok 4.3, coding에는 Grok Build 0.1을 가리킵니다. voice/image/video units는 text-token table에 넣지 않습니다.
Groq는 GroqCloud serving의 owner입니다.
OpenRouter는 router/marketplace economics의 owner입니다.
운영 전 재확인 체크리스트
| Check | 기록할 것 |
|---|---|
| Price owner | Official provider, hosted provider, router, cloud marketplace, self-hosted route. |
| Model ID | Exact model string, alias/preview/dated/deprecation status. |
| Token mix | Input, cached input, output, reasoning tokens, average output ratio. |
| Route fees | Platform fee, request fee, search/tool fee, cache storage, data residency, marketplace uplift. |
| Quality threshold | Pass rate, retry rate, fallback rate, human-review rate, failed-output cost. |
| Latency and limits | RPM, TPM, context limit, batch window, timeout, provider status behavior. |
| Data route | Retention, training use, region, enterprise terms, audit needs. |
| Spend controls | Hard caps, alerts, project budgets, tenant attribution, rollback route. |
자주 묻는 질문
지금 가장 싼 LLM API는 무엇인가요?
단순 high-volume text tasks에서는 Groq GPT OSS 20B나 DeepSeek V4 Flash가 싸 보입니다. 하지만 output ratio, cache, batch, retries, route fees, quality threshold를 넣어야 진짜 승자가 나옵니다.
OpenAI가 Claude나 Gemini보다 싼가요?
model과 workload에 따라 다릅니다. GPT-5.4-nano/mini, Claude Sonnet 5, Gemini 3.1 Flash-Lite는 각기 다른 장점이 있습니다.
OpenRouter 같은 router를 써야 하나요?
switching, fallback, one account, provider comparison이 engineering time을 줄이면 유용합니다. platform fee와 routing behavior를 넣어 계산합니다.
Free Tier를 운영에 써도 되나요?
보통 아닙니다. exploration과 prototype용이며 운영에는 predictable quota, billing owner, data terms, support path가 필요합니다.
왜 output price가 중요한가요?
많은 provider에서 output tokens가 input보다 훨씬 비쌉니다. chatbot, agent, report generator는 output-heavy가 되기 쉽습니다.
cache와 batch가 순위를 바꾸나요?
repeated prompts나 stable prefixes에서는 cache, 기다릴 수 있는 offline workloads에서는 batch가 이깁니다.
third-party pricing table을 믿어도 되나요?
discovery에는 좋습니다. final pricing은 official owner page를 확인해야 합니다.
LLM API 가격 비교는 얼마나 자주 업데이트해야 하나요?
production decision 전과 published refresh 전마다 확인합니다. model names, preview status, cache rules, router fees는 빠르게 바뀝니다.