2026년 7월 2일 기준 OpenAI direct Standard에서 o4-mini 가격은 입력 100만 토큰당 $1.10, 캐시 입력 100만 토큰당 $0.275, 출력 100만 토큰당 $4.40입니다. 이 행만 보고 비용을 확정하면 안 됩니다. 보이지 않는 추론 토큰은 출력으로 과금되고, Batch와 Flex는 다른 운영 조건을 가지며, Priority의 $2/$0.50/$8 행은 일반 Standard 가격이 아닙니다.
| 판단할 것 | 먼저 볼 행 | 실무 의미 |
|---|---|---|
| 일반 direct API 비용 | Standard: 입력 $1.10 / 캐시 $0.275 / 출력 $4.40 | 동기 호출의 기본 예산 산정에 사용합니다. |
| 비동기 대량 처리 | Batch: 입력 $0.55 / 출력 $2.20 | 24시간 처리 창을 받아들일 수 있는 작업에 적합합니다. |
| 낮은 우선순위 온라인 작업 | Flex: 입력 $0.55 / 캐시 $0.138 / 출력 $2.20 | 사용 가능 여부와 지연 허용 범위를 확인해야 합니다. |
| 우선 처리 | Priority: 입력 $2.00 / 캐시 $0.50 / 출력 $8.00 | 일반 가격으로 복사하면 예산이 틀어집니다. |
| 이름이 비슷한 다른 행 | Deep Research, fine-tuning, Azure, provider | 별도 계약과 별도 시트로 관리합니다. |
o4-mini가 싸다고 판단하기 전에 신규 입력, 캐시 입력, 보이는 출력, 추론 토큰을 분리해 계산합니다. 기존 평가에서 통과한 lane은 유지할 수 있습니다. 새 추론 기능은 GPT-5.4 mini나 GPT-5.5와 비교하고, 추출·분류·형식화·라우팅은 비추론 모델을 먼저 검증합니다.
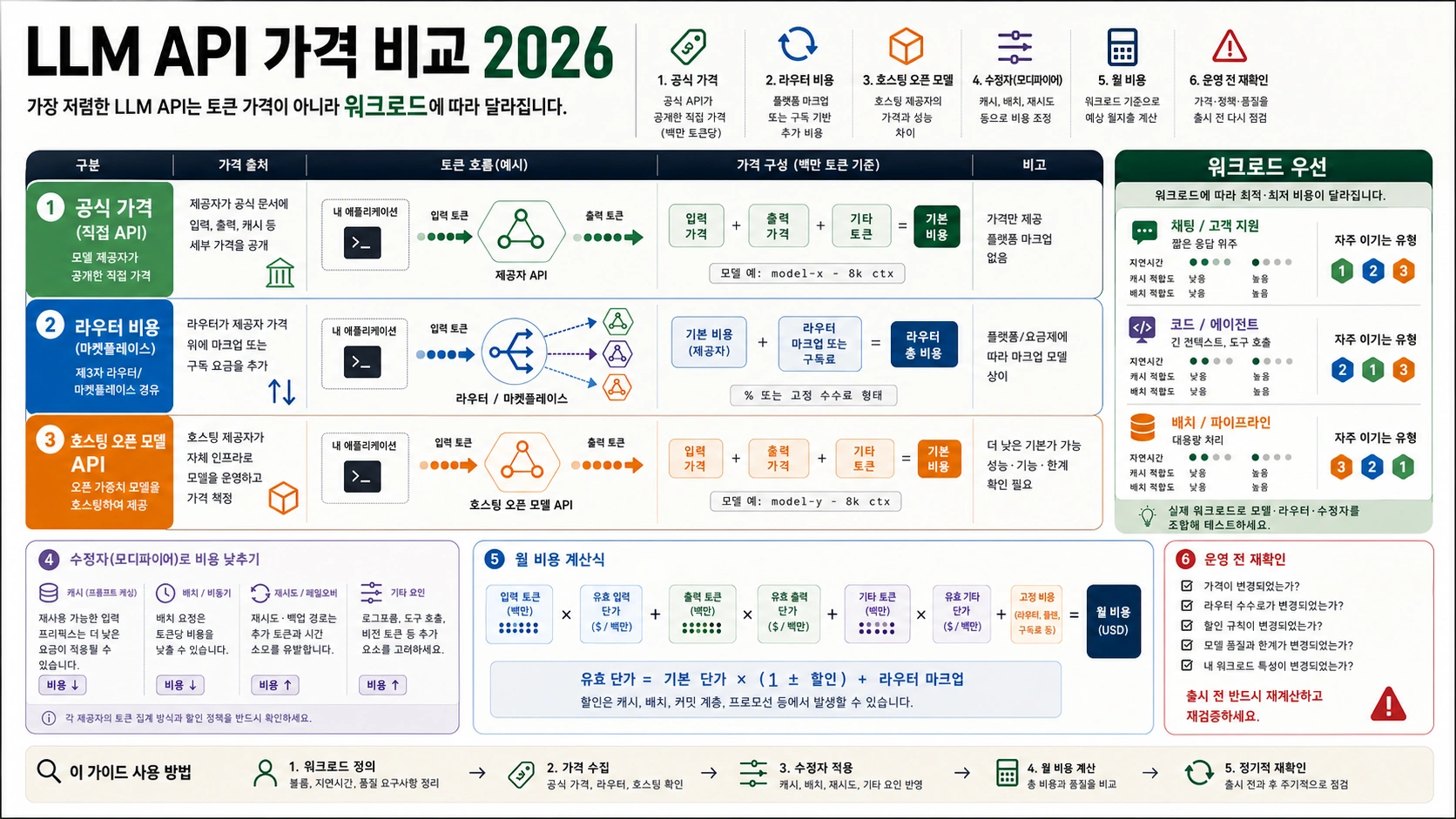
현재 o4-mini의 위치
OpenAI 모델 문서에는 o4-mini가 reasoning 모델로 남아 있으며 모델 ID는 o4-mini, 스냅샷은 o4-mini-2025-04-16입니다. 빠르고 비용 효율적인 추론 모델로 설명되지만 후속 모델도 명시되어 있습니다. 따라서 새 프로젝트의 기본값이라기보다, 검증된 경로에서 계속 쓸 수 있는 후보로 읽어야 합니다.
한국어 자료에서는 특히 Priority 행이 일반 가격처럼 보이는 경우가 있습니다. $2.00 입력, $0.50 캐시, $8.00 출력은 Priority 처리의 행이지 Standard o4-mini의 기본 행이 아닙니다. 예산표에는 service tier를 반드시 별도 열로 둬야 합니다.
또한 GPT-4o mini, GPT-5 mini, GPT-5.4 mini, o4-mini-deep-research는 같은 모델이 아닙니다. model ID가 다르면 가격, 기능, 라우팅 의도가 달라집니다. 로그와 대시보드가 정확해야 비용 개선도 가능합니다.
한국어 자료에서 원화 환산이 보이면 편리하지만, 환율과 provider margin이 섞일 수 있습니다. 기술 비용과 결제 경로 비용을 분리하세요.
Priority 행을 Standard로 오해하면 예산이 크게 부풀거나 모델 선택이 왜곡됩니다. service tier를 로그에 남기는 것이 가장 빠른 방어책입니다.
API subscription, ChatGPT subscription, provider credit은 서로 다른 지출입니다. o4-mini 비용 논의는 API token billing 기준으로 정리해야 합니다.
운영 라우터에 o4-mini를 남길 때는 가격 행과 함께 request class, 평균 신규 입력, 캐시 비율, 보이는 출력, 추론 토큰, retry rate, 사람 수정률을 기록해야 합니다. 단가가 낮아도 추론이 길어지고 재시도가 늘어나면 총 비용은 더 비싼 모델보다 높아질 수 있습니다.
평가 세트는 세 그룹으로 나누는 것이 좋습니다. 기존 안정 작업은 o4-mini 유지 여부를 확인하고, 경계가 어려운 작업은 GPT-5.5 승격 기준을 만들고, 추론이 필요 없는 negative samples는 추출과 형식화를 비추론 모델로 뺄 수 있는지 보여줍니다.
비용 논의에서는 OpenAI direct token 가격, Batch/Flex/Priority 운영 route, Azure 또는 provider 조달 조건, ChatGPT subscription을 분리하세요. 이 네 가지가 한 표에 섞이면 모델 선택 문제인지 결제 경로 문제인지 prompt 설계 문제인지 구분할 수 없습니다.
배포 후에는 reasoning tokens 비율 상승과 cached input 비율 하락을 조기 신호로 봐야 합니다. reasoning 비율 상승은 prompt가 모호해졌거나 작업 난도가 올라갔다는 뜻일 수 있고, cache 비율 하락은 안정 prefix나 schema 배치가 깨졌다는 뜻일 수 있습니다.
마이그레이션 실험은 평균 비용 하나로 끝내지 않는 것이 좋습니다. 긴 context, 짧은 output, tool call, retry가 많은 요청, cache hit가 높은 요청을 나눠서 봐야 합니다. o4-mini가 전체 평균에서는 애매해도 특정 lane에서는 여전히 가장 안정적일 수 있습니다.
월간 비용 복기에는 실패한 호출도 포함해야 합니다. 성공한 최종 답변만 보면 retry에 가려진 입력, 출력, 추론 토큰이 사라집니다. 추론 모델에서는 실패 호출도 비용을 만들기 때문에 성공 응답 기준의 추정은 실제 현금 흐름을 낮게 봅니다.
새 모델로 바꾸는 조건은 측정 가능한 문장이어야 합니다. 같은 eval set에서 품질이 떨어지지 않고, retry rate가 늘지 않고, 평균 및 p95 reasoning tokens가 설명 가능하고, 지연 시간이 허용 범위이며, 월 비용이나 실패율이 실제로 개선될 때 교체합니다.
기존 lane을 삭제할 때도 rollback 근거를 남겨야 합니다. 이전 모델 점수, 대표 실패 샘플, 비용 분포, 대체 모델이 이긴 이유, 적용 날짜를 기록하면 이후 비용이나 품질 변동이 모델 교체 때문인지 traffic mix나 prompt 변경 때문인지 구분할 수 있습니다.
캐시 복기도 배포 기록에 남기세요. 어떤 prefix가 안정적인지, 어떤 schema를 움직이면 안 되는지, 어떤 동적 필드를 뒤로 보내야 하는지 정리하면 작은 prompt 정리 때문에 cached input 장점이 사라지는 일을 줄일 수 있습니다.
비용 귀속은 request class별로 나눠야 합니다. coding repair, 짧은 분류, 긴 policy가 붙은 판단, visual reasoning, tool routing은 같은 o4-mini라도 입력 구조와 실패율이 다릅니다. 합산 평균만 보면 어느 용도를 다른 모델로 옮겨야 하는지 알기 어렵습니다.
평가 결과와 가격표는 같은 의미가 아닙니다. 가격표는 공식 사실이고, eval은 팀 환경의 관측이며, router는 운영 정책입니다. 세 층을 분리하면 공식 가격이 바뀌거나 모델 품질이 흔들릴 때 어느 층을 수정해야 하는지 빠르게 알 수 있습니다.
교체 후에도 rollback 조건을 미리 정해야 합니다. 특정 요청군에서 실패율이 다시 올라가거나, p95 reasoning tokens가 기준선을 넘거나, cached input 비율이 떨어져 월 비용이 증가하면 이전 lane을 임시로 되살릴 수 있어야 합니다. 그래야 모델 선택이 일회성 선언이 아니라 운영 가능한 실험이 됩니다.
팀 문서에는 숫자뿐 아니라 왜 그 숫자를 쓰는지도 남겨야 합니다. Standard 행은 일반 동기 호출, Batch는 비동기 대량 처리, Flex는 낮은 우선순위, Priority는 의도적 프리미엄 처리라는 설명이 있어야 새 구성원이 같은 예산표를 같은 방식으로 읽습니다.
공식 o4-mini 가격 행
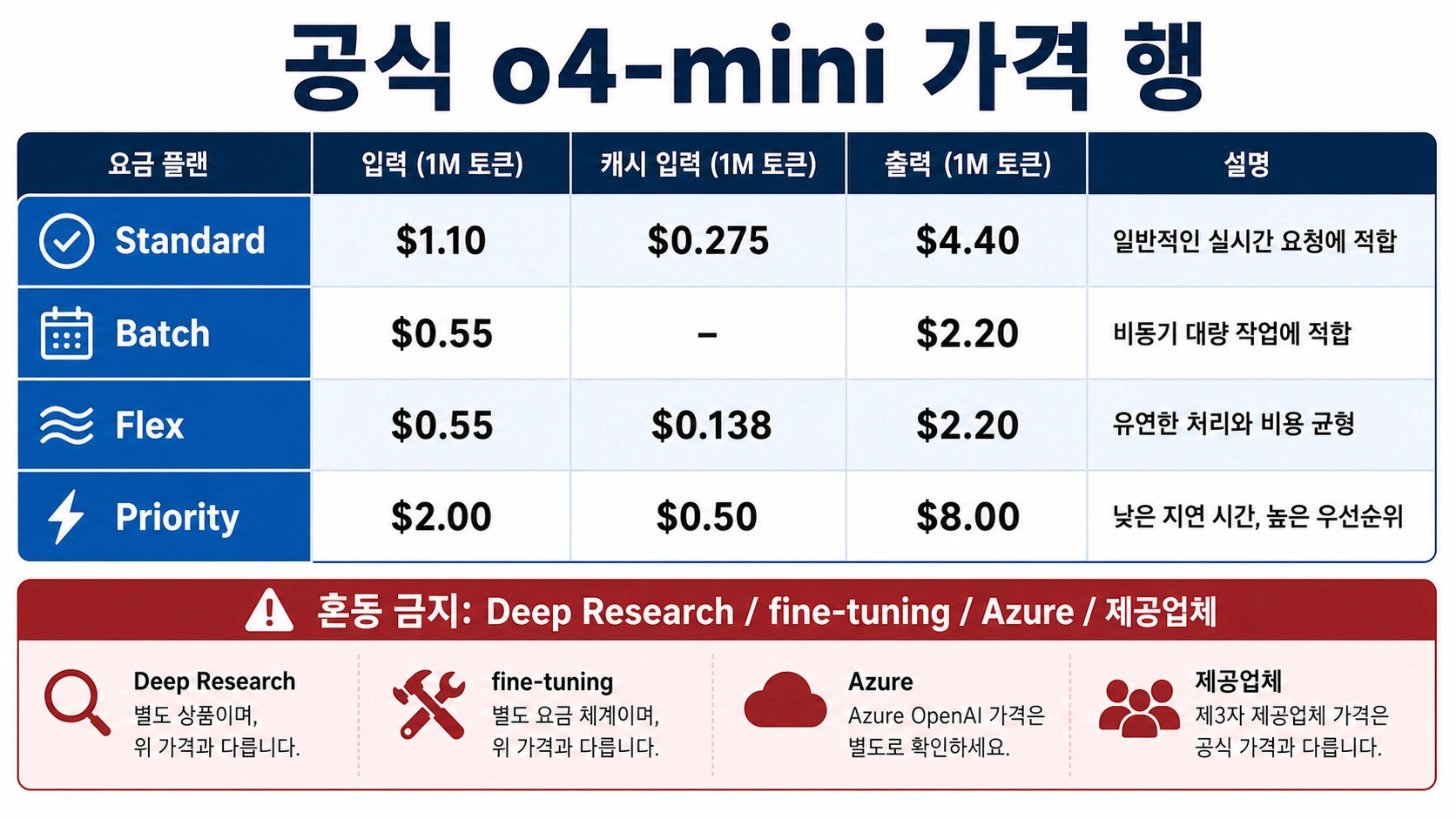
가격을 읽을 때는 Standard와 Batch, Flex, Priority를 분리합니다. Provider, Azure, Deep Research, fine-tuning 행은 별도의 계약입니다. 한국어 환경에서 자주 보이는 원화 환산이나 provider 요금은 구매 판단에는 유용하지만 OpenAI direct 행을 대체하지 않습니다.
| 라우트 | 입력 / 1M | 캐시 입력 / 1M | 출력 / 1M |
|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 |
Batch o4-mini | $0.55 | 별도 행 없음 | $2.20 |
Flex o4-mini | $0.55 | $0.138 | $2.20 |
Priority o4-mini | $2.00 | $0.50 | $8.00 |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 |
실제 요청 비용 계산법

hljs textcost = fresh_input / 1,000,000 * 1.10 + cached_input / 1,000,000 * 0.275 + (visible_output + reasoning_tokens) / 1,000,000 * 4.40
Standard 계산식은 신규 입력 / 1,000,000 * 1.10, 캐시 입력 / 1,000,000 * 0.275, 그리고 보이는 출력과 추론 토큰 합계 / 1,000,000 * 4.40을 더하는 방식입니다. 추론 토큰은 최종 답변에 보이지 않지만 output tokens로 과금됩니다.
예를 들어 신규 입력 10,000, 캐시 0, 보이는 출력 2,000, 추론 토큰 3,000이면 입력 비용은 $0.011, 출력 측 비용은 $0.022, 총 약 $0.033입니다. 단건으로는 작아 보여도 대량 트래픽에서는 추론 토큰 변동이 월 비용을 바꿉니다.
긴 prompt의 경우 80,000 입력 중 60,000이 캐시라면 신규 입력은 20,000뿐입니다. 하지만 5,000 보이는 출력과 10,000 추론 토큰은 output 단가로 계산됩니다. 캐시는 큰 도움을 주지만 무제한 추론을 대신 막아주지는 않습니다.
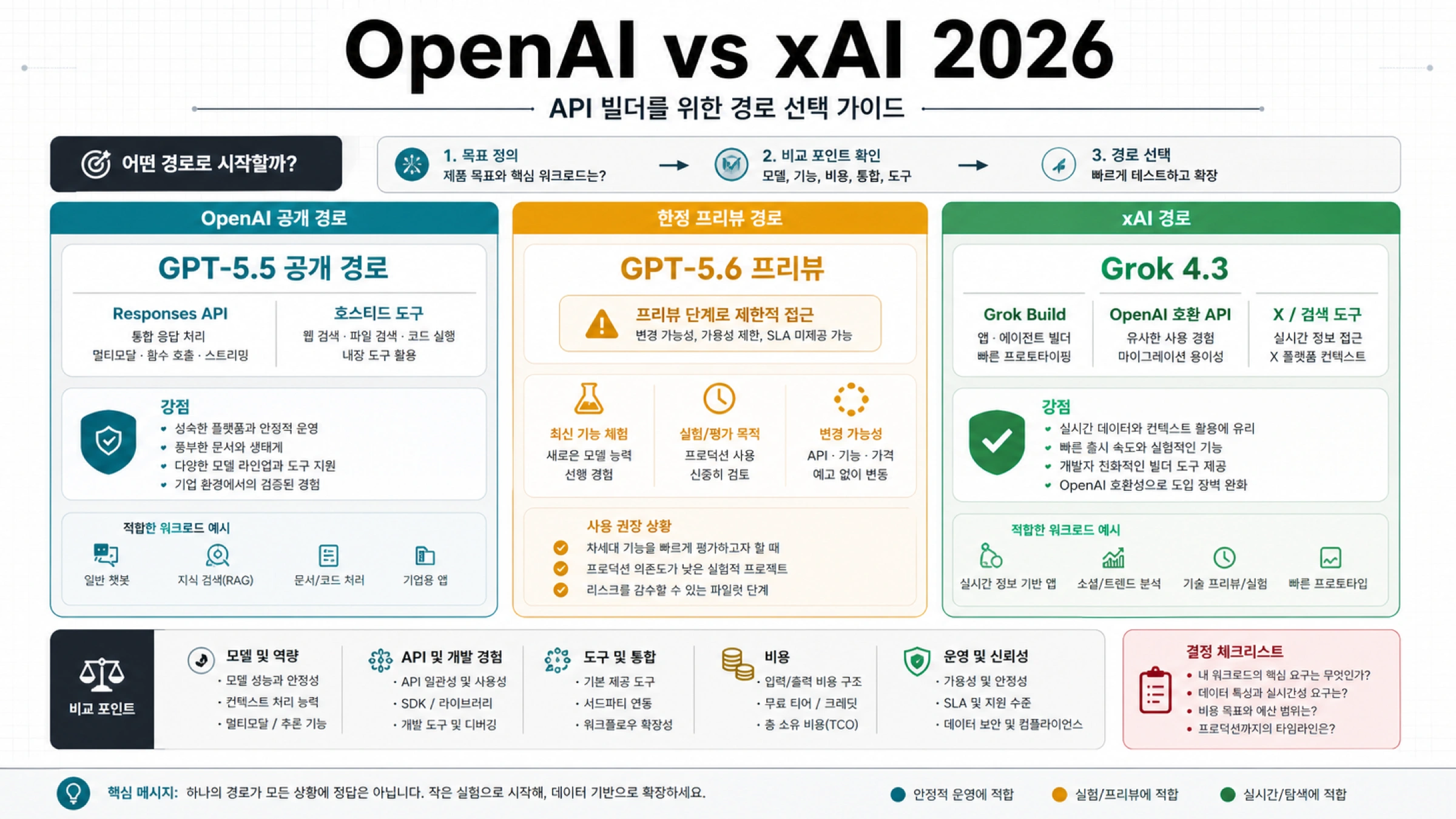
o4-mini를 계속 쓸 때
o4-mini는 자체 평가에서 이미 통과한 작업에 적합합니다. 제한된 코드 검토, 짧은 논리 검증, 수학 체크, 시각 자료 판단, router의 두 번째 판단처럼 결과가 검증 가능하고 출력 길이가 관리되는 곳이 후보입니다.
계속 쓰더라도 재평가가 필요합니다. 정확도, 지연 시간, 보이는 출력 길이, 추론 토큰, retry rate, 사람 수정률, downstream failure를 함께 봐야 합니다. 토큰 단가가 낮아도 재시도와 숨은 출력이 많으면 총 비용은 올라갑니다.
운영 라우터에서는 o4-mini를 제한된 lane으로 두는 것이 안전합니다. 어려운 계획이나 복잡한 코드 수리는 GPT-5.5, 새 저비용 추론은 GPT-5.4 mini와 비교, 단순 추출과 형식화는 비추론 모델로 분리합니다.
모델을 바꿀 때
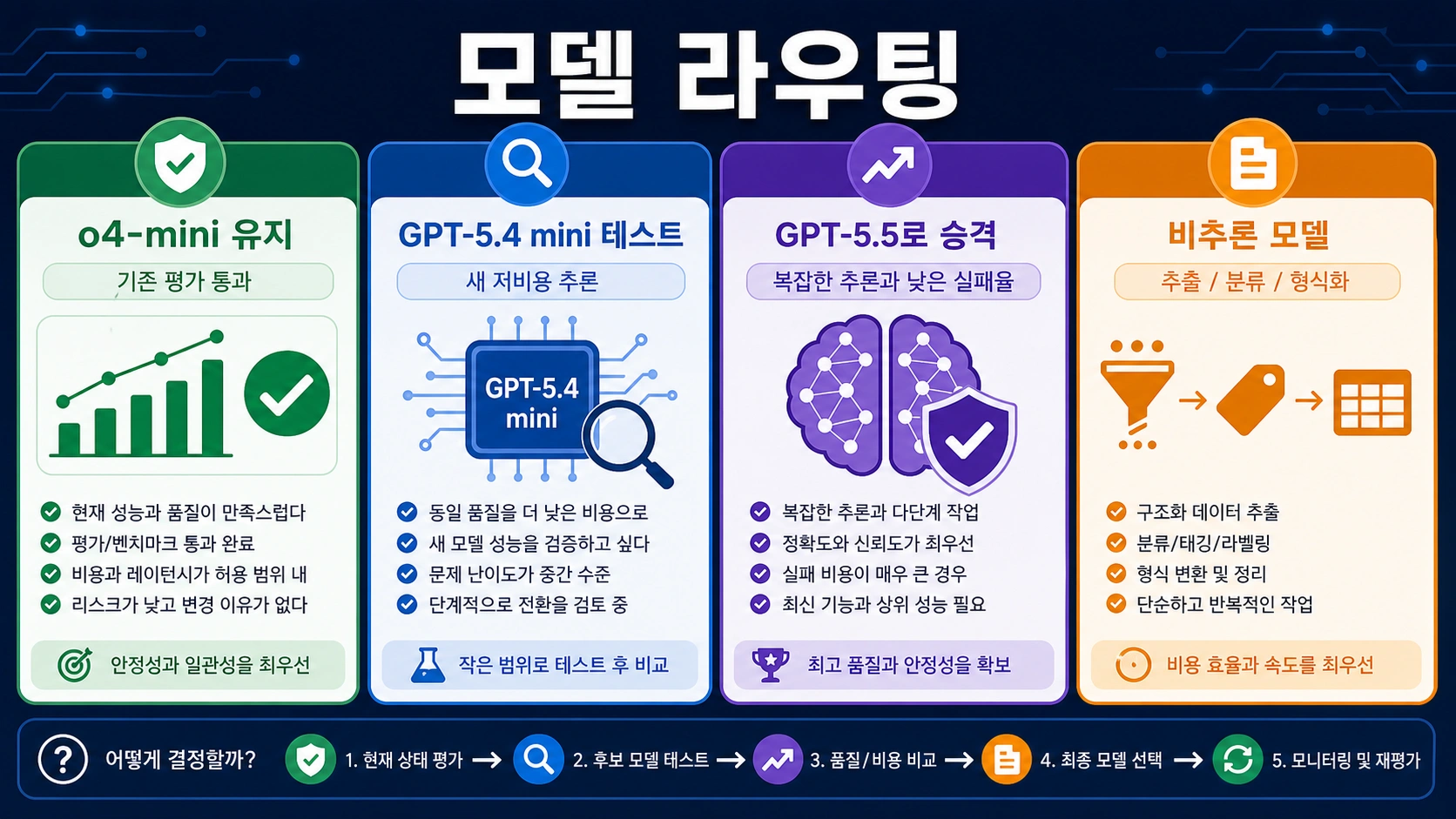
새 추론 기능은 최신 GPT-5.x 후보부터 비교하는 것이 좋습니다. GPT-5.4 mini는 저비용 추론 후보이고, GPT-5.5는 복잡한 추론과 낮은 실패율이 중요한 경우의 후보입니다. o4-mini는 기준 모델로 남기되 평가 없이 기본값으로 고정하지 마세요.
추출, 분류, JSON 형식화, 메타데이터 정리, 라우팅 prefilter는 추론이 필요 없을 수 있습니다. 이런 작업은 비추론 모델이 비용도 낮고 실패 형태도 예측하기 쉽습니다.
| 작업 | 먼저 테스트할 모델 | 이유 |
|---|---|---|
기존 o4-mini lane 평가 통과 | o4-mini 유지 후 재평가 | 이미 생산 기준선이 있습니다. |
| 새 저비용 추론 | GPT-5.4 mini와 o4-mini 비교 | 새 모델이 비용 대비 품질에서 이길 수 있습니다. |
| 복잡한 계획과 코드 수리 | GPT-5.5 | 재시도 감소가 높은 단가를 상쇄할 수 있습니다. |
| 추출, 분류, 형식화, 라우팅 | 비추론 모델 | 추론 토큰이 가치로 이어지지 않을 수 있습니다. |
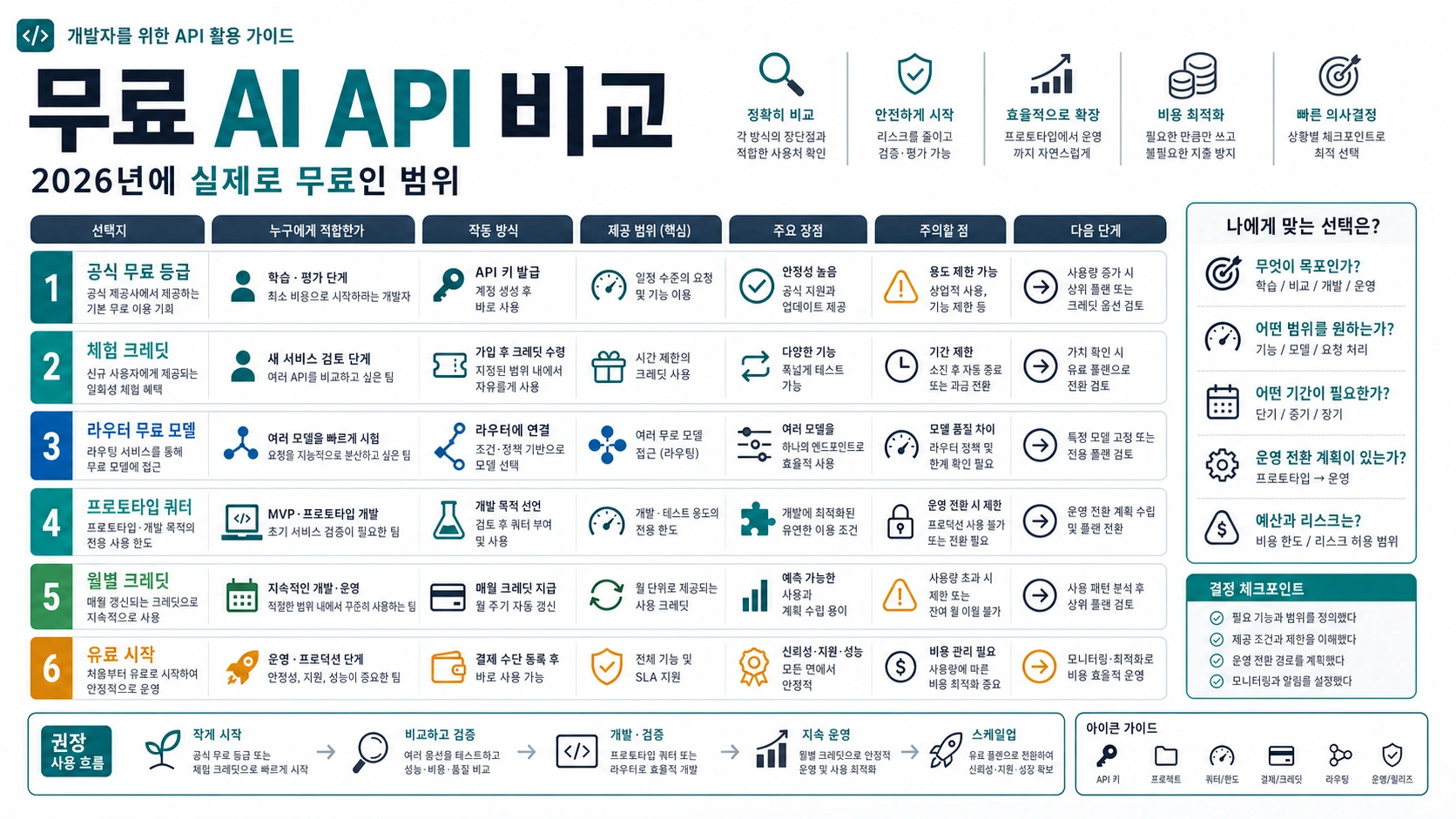
실제로 효과 있는 비용 제어
Prompt caching은 첫 번째 비용 제어 수단입니다. 안정적인 시스템 지시문, schema, 긴 정책, 반복되는 reference block을 앞에 두고 매번 바뀌는 사용자 입력은 뒤로 보내야 합니다.
max_output_tokens는 보이는 텍스트만 제한하지 않습니다. 추론 모델에서는 reasoning tokens와 visible output의 합계에 영향을 줍니다. 너무 낮으면 답변 전에 멈추고, 너무 높으면 숨은 비용이 커집니다.
Batch는 비동기 작업 비용을 낮춥니다. Flex는 낮은 우선순위를 받아들일 수 있을 때만 사용합니다. Priority는 비용이 올라가는 행이므로 정상 예산과 분리해야 합니다.
429나 quota가 문제라면 OpenAI API rate limit 가이드를 먼저 보세요. key, billing, trial state가 문제라면 OpenAI API key free trial 가이드부터 확인하세요.
피해야 할 오해
fine-tuning이나 RFT 가격을 base inference 가격으로 쓰지 마세요. 훈련 시간, tuned-model inference, data sharing 조건은 다른 계약입니다.
o4-mini-deep-research를 일반 o4-mini로 보지 마세요. 이름은 비슷하지만 다른 모델 행입니다.
Azure 또는 provider 가격을 OpenAI direct 가격으로 복사하지 마세요. 지역, 배포, 결제, 지원 조건이 다릅니다.
보이는 출력만으로 계산하지 마세요. 추론 토큰은 보이지 않아도 output으로 과금됩니다.
배포 전 체크리스트
- 코드와 로그의 model ID가
o4-mini인지 확인합니다. - 일반 direct 계산은 Standard 행을 쓰고 Batch/Flex/Priority는 별도 열로 둡니다.
- 신규 입력과 캐시 입력을 분리합니다.
- 보이는 출력과 추론 토큰을 합쳐 output 단가를 적용합니다.
- GPT-5.4 mini, GPT-5.5, 비추론 모델을 같은 eval set에서 비교합니다.
- 문제가 rate limit이면 OpenAI API rate limit 문서, API key와 billing이면 API key free trial 문서를 먼저 확인합니다.
자주 묻는 질문
현재 o4-mini API 가격은 얼마인가요?
2026년 7월 2일 기준 OpenAI direct Standard는 입력 $1.10, 캐시 입력 $0.275, 출력 $4.40 / 100만 토큰입니다.
추론 토큰도 과금되나요?
예. 보이지 않는 추론 토큰은 output tokens로 과금됩니다.
캐시 입력은 prompt를 두 번 계산한다는 뜻인가요?
아닙니다. 현재 입력 중 재사용 가능한 앞부분이 더 낮은 cached rate로 계산된다는 뜻입니다.
Batch가 더 싼가요?
단가가 낮지만 비동기 route입니다. 실시간 사용자 흐름에는 적합하지 않습니다.
Flex와 Batch는 같은가요?
다릅니다. Flex는 lower-priority service tier, Batch는 async batch route입니다.
o4-mini는 deprecated인가요?
문서에는 아직 남아 있고 후속 모델도 표시됩니다. 새 작업은 비교해야 하지만 검증된 lane을 즉시 제거하라는 뜻은 아닙니다.
GPT-5.4 mini와 어느 쪽을 써야 하나요?
저비용 추론이면 둘 다 평가하세요. 기존 o4-mini lane이 통과했다면 유지할 수 있고, 새 작업은 GPT-5.4 mini를 먼저 볼 수 있습니다.
월 비용은 어떻게 계산하나요?
한 요청의 신규 입력, 캐시 입력, 보이는 출력, 추론 토큰을 계산한 뒤 요청량, retry, 실패율, Batch/Flex/Priority 비중을 곱합니다.