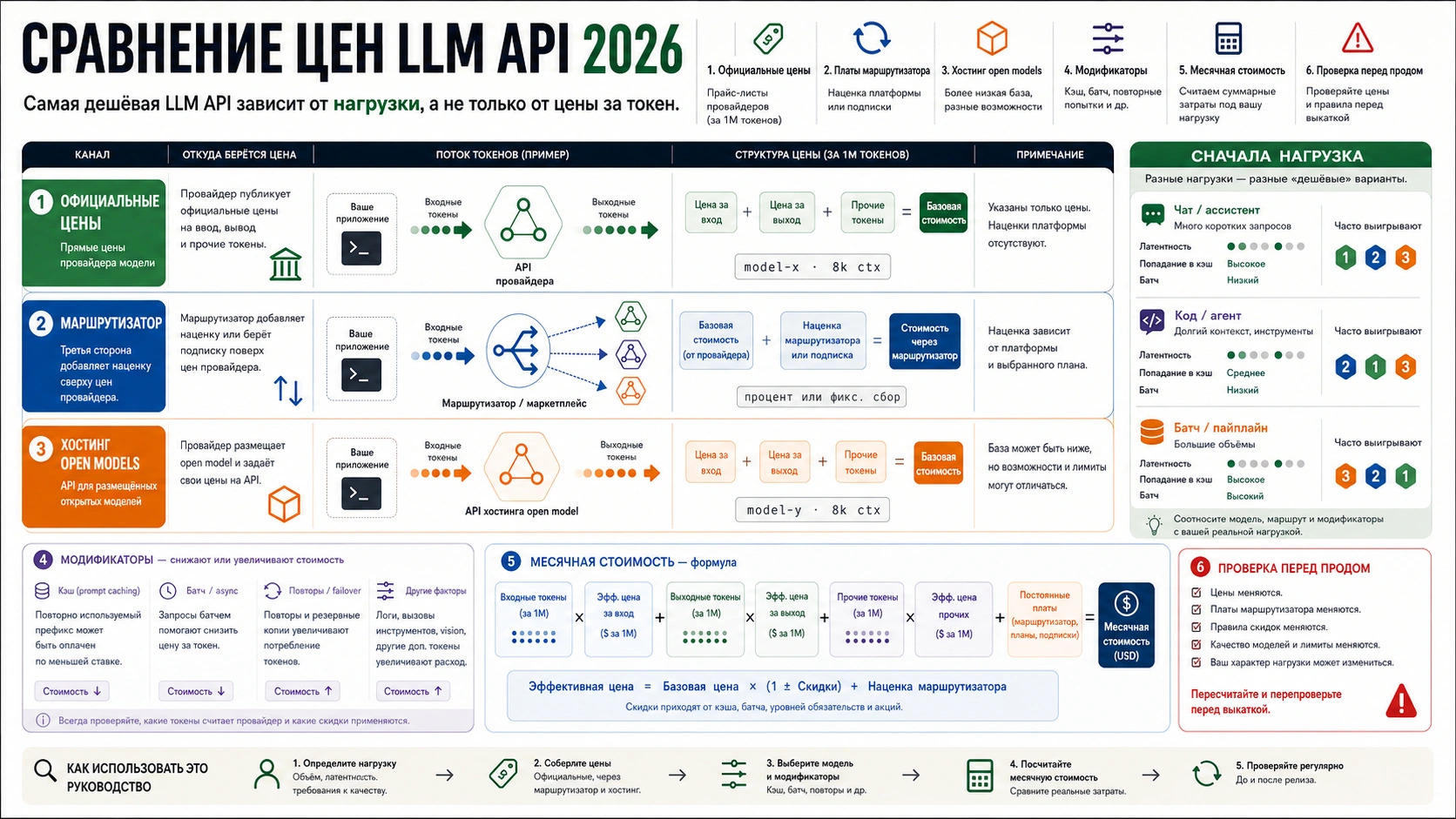
На 2 июля 2026 года дешевый LLM API нельзя выбирать по одной input-token строке. Сравнивайте стоимость принятого результата: input, cached input, output, tool/search fees, router fee, retry overhead и человеческая проверка часто меняют победителя. Для разработчика одной глобальной таблицы мало. Нужны владелец цены, тип маршрута, дата проверки, единица измерения и условия, которые меняют счет. Поэтому direct API, hosted open-model serving и router economics надо разделить до выбора модели, иначе разные контракты выглядят как одна строка.
| Ценовой маршрут | Когда использовать | Как читать текущие доказательства |
|---|---|---|
| Official direct API | Нужны provider support, billing, data route и model terms | OpenAI, Anthropic, Gemini, DeepSeek, Mistral и xAI владеют только своими прямыми API rows. |
| Hosted open-model API | Нужен дешевый serving open-weight models без своего GPU | Groq-hosted GPT OSS, Llama и Qwen — цены Groq route, не официальный прайс авторов модели. |
| Router или marketplace | Нужен один account для switching, fallback или сравнения | OpenRouter-like rows принадлежат router economics; platform fee и request limits важны рядом с token price. |
Начните с формулы:
monthly API cost = uncached input + cached input + output + route/tool/search/request fees + retry overhead - batch/cache savings
Bulk extraction, support bot, coding agent, long-context analysis, regulated workflow и offline batch могут выбрать разные модели. Перед traffic move перепроверьте availability, preview labels, cache/batch discounts, free tier, data residency uplift, router fees и deprecation dates.
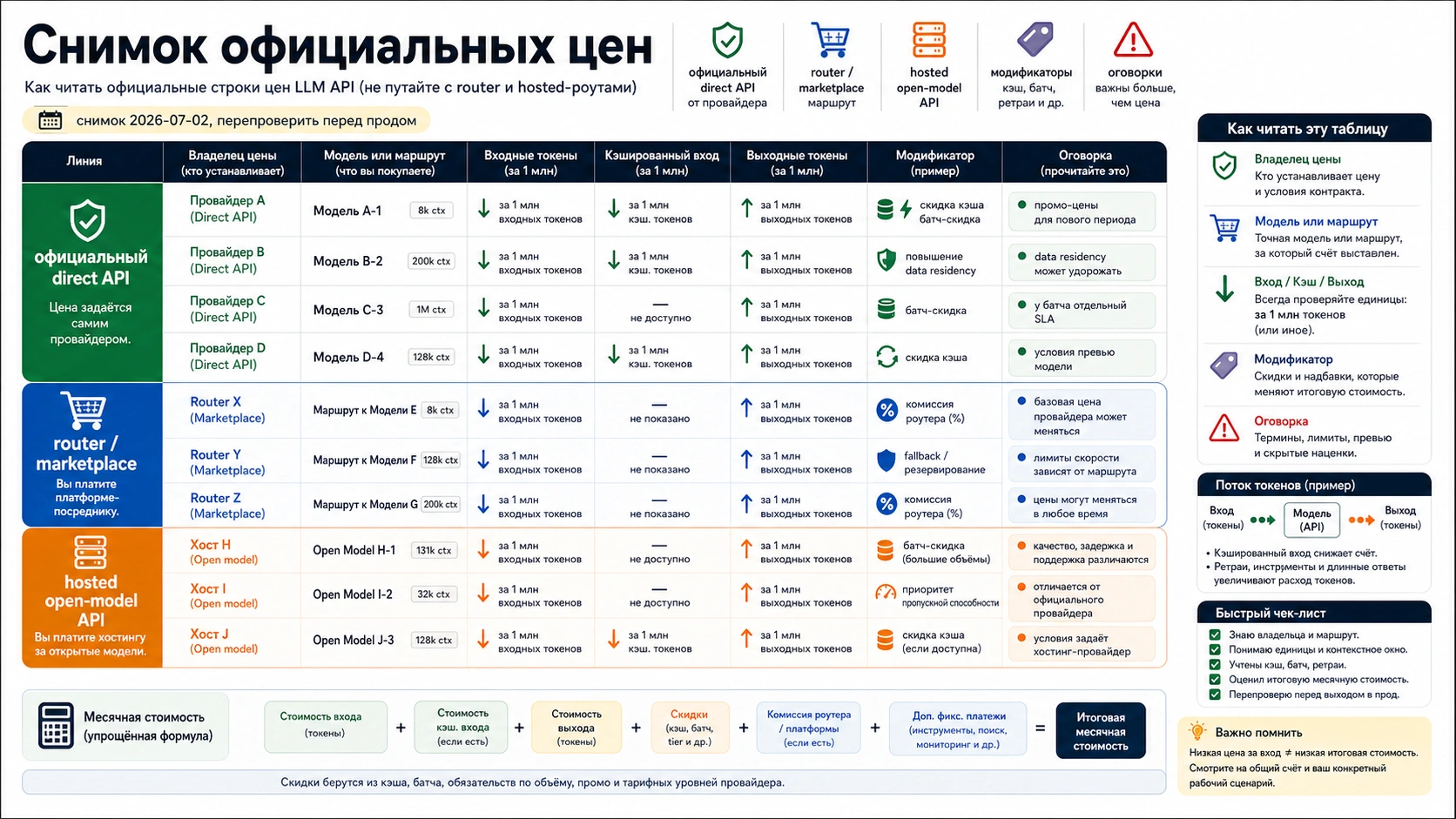
Снимок официальных direct API цен
Эта таблица — dated owner-labeled baseline, а не вечный leaderboard. Все цены указаны в USD за 1M tokens, если не сказано иначе. Input, cached input и output разделены, потому что output-heavy apps часто меняют ранжирование.
| Owner и route | Representative row checked July 2, 2026 | Input | Cached input | Output | Caveat |
|---|---|---|---|---|---|
| OpenAI direct API, Standard | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Standard, Batch, Flex и Priority считаются отдельно; региональная обработка может добавить uplift. |
| OpenAI direct API, Standard | gpt-5.4-mini | $0.75 | $0.075 | $4.50 | Хорошая строка для теста недорогих OpenAI-задач, но не универсальный победитель. |
| OpenAI direct API, Standard | gpt-5.5 | $5.00 | $0.50 | $30.00 | Используйте только если качество окупает высокий output-cost. |
| Anthropic direct API | Claude Sonnet 5 intro row | $2.00 | зависит от cache route | $10.00 | Intro-цена указана до 2026-08-31; затем строка становится $3.00 input и $15.00 output. |
| Anthropic direct API | Claude Haiku 4.5 | $1.00 | зависит от cache route | $5.00 | Cache write, cache hit, Batch, Fast mode и data residency меняют итог. |
| Google Gemini Developer API | gemini-3.1-flash-lite, Paid Tier Standard | $0.25 text/image/video, $0.50 audio | $0.025 text/image/video, $0.05 audio | $1.50 | Free Tier полезен для проверки, но продакшн надо считать по paid project и data terms. |
| Google Gemini Developer API | gemini-3.5-flash, Paid Tier Standard | $1.50 | $0.15 | $9.00 | Grounding with Google Search и Maps может добавить query fees после включенного лимита. |
| Google Gemini Developer API | gemini-3.1-pro-preview, Paid Tier Standard | $2.00 <= 200k, $4.00 > 200k | $0.20 <= 200k, $0.40 > 200k | $12.00 <= 200k, $18.00 > 200k | Цена меняется после порога prompt length; preview status надо перепроверять. |
| DeepSeek direct API | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | deepseek-chat и deepseek-reasoner сейчас мапятся на режимы V4 Flash и запланированы к deprecation 2026-07-24. |
| DeepSeek direct API | deepseek-v4-pro | $0.435 cache miss | $0.003625 cache hit | $0.87 | Официальная страница также указывает 1M context; перед переносом трафика проверьте latency и качество. |
| страница цен Mistral | Mistral Large example | $2.00 | не указано в public FAQ | $6.00 | Mistral считает input и output tokens, а Batch получает 50% discount. |
| xAI model docs | Grok 4.3 | $1.25 | не указано | $2.50 | Для coding docs указывают Grok Build 0.1; voice, image и video имеют другие units. |
Hosted open-model APIs и routers могут быть дешевле, но это другие контракты:
| Владелец route | Строка или контракт | Ценовой сигнал | Как использовать |
|---|---|---|---|
| цены Groq | openai/gpt-oss-20b hosted by Groq | $0.075 uncached input, $0.0375 cached input, $0.30 output | Это цена GroqCloud serving, не официальный прайс автора модели. |
| цены Groq | openai/gpt-oss-120b hosted by Groq | $0.15 uncached input, $0.075 cached input, $0.60 output | Хороший cheap-first test для open-model workload, если качество и latency подходят. |
| цены OpenRouter | Pay-as-you-go plan | 5.5% platform fee, 400+ models, 70+ providers | Это router contract, а не официальный прайс underlying providers. |
| цены OpenRouter | Free plan | 50 requests/day, free-model access | Подходит для exploration, но не для production entitlement. |
Если нужной модели нет, идите к owner page и добавьте model ID, route, unit, checked date и caveat в тот же формат.
Самый дешевый маршрут по типу workload
Дешевая модель побеждает только если выполняет ту же задачу с приемлемым quality и retry rate. Первый shortlist должен быть workload-based.
| Workload | Начать тест с | Почему может быть дешево | Stop rule |
|---|---|---|---|
| Bulk extraction, classification, normalization | DeepSeek V4 Flash, Gemini 3.1 Flash-Lite, Groq GPT OSS 20B, OpenAI GPT-5.4-nano | Low input/output rows важны, потому что quality обычно измеряется labels или validators. | Не shipping до подсчета false positives, retries и human-review rate. |
| Support chatbot и FAQ | Gemini 3.1 Flash-Lite, OpenAI GPT-5.4-mini/nano, Claude Haiku 4.5, DeepSeek V4 Pro | Output ratio средний, cached policy context может помочь. | Если escalation quality падает, низкая token price не равна низкой cost. |
| Coding assistant или agentic tool use | Claude Sonnet 5, OpenAI GPT-5.4/GPT-5.5, xAI Grok Build, Gemini 3.5 Flash | Ошибки создают expensive retries и developer time. | Нужны same-repo evals, tool-call success rate и rollback cost. |
| Long-context analysis | Gemini Pro/Flash long-context, DeepSeek V4 1M context, Grok 4.3 | Один большой вызов может быть дешевле chunking + retrieval. | Пересчитать при переходе через context-tier threshold или cache storage. |
| Regulated или enterprise workflows | Direct provider API или contracted cloud route | Billing, data handling, audit logs и support могут быть важнее низкой строки. | Не выбирать router только из-за token row. |
| Offline batch | OpenAI Batch, Google Batch, Mistral Batch, Groq Batch | Async workloads часто получают discount. | Batch не latency route; проверьте completion window и output retrieval. |

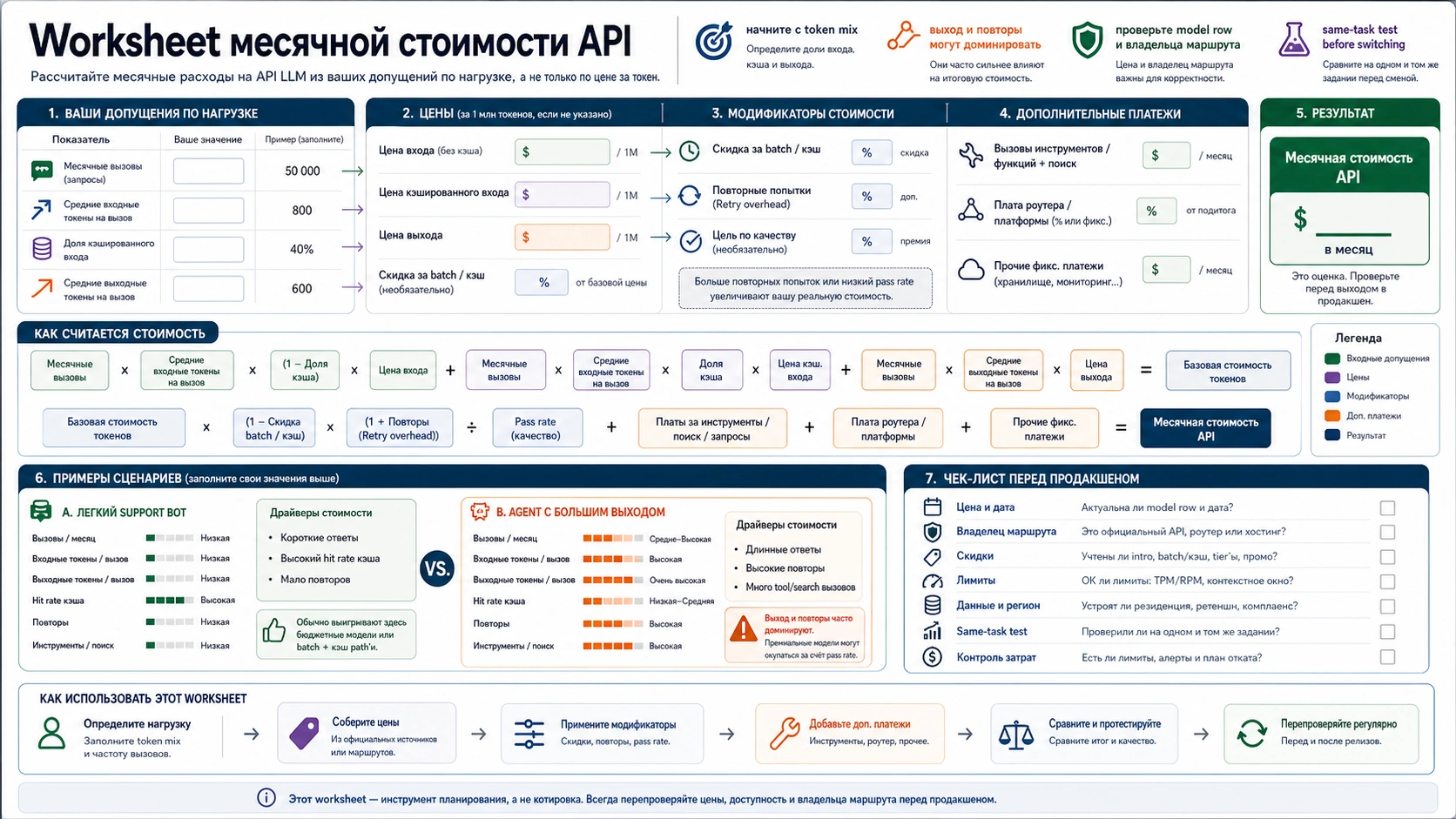
Monthly cost worksheet
Реальный счет начинается с token mix. Для каждого кандидата используйте одинаковую форму нагрузки.
- Monthly uncached input tokens.
- Monthly cached input tokens или cache-hit rate.
- Monthly output tokens, включая reasoning/thinking tokens когда они billed as output.
- Tool, search, request, route или platform fees.
- Retry and fallback overhead.
- Batch/cache savings.
- Human-review или failure cost если output не проходит.
| Scenario | Candidate route | Token mix | Simple monthly token cost | Interpretation |
|---|---|---|---|---|
| Bulk data cleanup | Groq GPT OSS 20B | 100M input, 10M output | $10.50 | Очень дешево, если hosted open model проходит validation. |
| Bulk data cleanup | DeepSeek V4 Flash | 100M cache-miss input, 10M output | $16.80 | Низкая direct DeepSeek строка, но качество и latency надо проверять. |
| Bulk data cleanup | OpenAI GPT-5.4-nano | 100M input, 10M output | $32.50 | Может быть выгодно при OpenAI compatibility или better output. |
| Bulk data cleanup | Gemini 3.1 Flash-Lite | 100M text input, 10M output | $40.00 | Cache или Batch могут улучшить итог, но Free Tier не production assumption. |
| Output-heavy chatbot | Groq GPT OSS 20B | 20M input, 20M output | $7.50 | Output дешевый, но open-model quality must pass. |
| Output-heavy chatbot | DeepSeek V4 Flash | 20M cache-miss input, 20M output | $8.40 | Низкий output price; измерьте hallucination и escalation cost. |
| Output-heavy chatbot | OpenAI GPT-5.4-nano | 20M input, 20M output | $29.00 | Output dominates; используйте если quality beats cheaper routes. |
| Output-heavy chatbot | Gemini 3.1 Flash-Lite | 20M text input, 20M output | $35.00 | Хорошо если Gemini ecosystem fit снижает retries. |
Добавьте modifiers: 40% repeated system prompt на OpenAI GPT-5.4-nano падает с $0.20/M до $0.02/M как cached input. Gemini 3.1 Flash-Lite через Batch падает с $0.25/M до $0.125/M input и с $1.50/M до $0.75/M output. OpenRouter route с 5.5% fee надо умножать на 1.055.
Финальная метрика:
price per completed task = total monthly route cost / accepted task count
Если cheap route принимает 94% задач, а дорогой 99.5%, недостающие 5.5% становятся retries, fallbacks, manual review, support tickets или lost output.
Для русскоязычной команды полезно добавить еще один слой учета: валюту закупки, налоговые документы, способ оплаты и допустимость зарубежного vendor route. Даже когда токены оплачиваются в USD, внутренний бюджет часто утверждается в другой валюте и с лимитом по проекту. Поэтому в рабочей таблице держите отдельные колонки для FX rate, payment owner, invoice owner, monthly cap, alert threshold и rollback route. Это не меняет token math, но меняет production decision.
Direct API, router, hosted open model или self-host?
Direct API и router решают разные ownership problems. Direct provider API чище, когда нужны support, billing clarity, data route, enterprise controls и incident diagnosis.
Routers полезны для model switching, fallback, traffic comparison и single integration. OpenRouter's 5.5% platform fee, free limits и routing behavior входят в модель cost.
Hosted open-model APIs находятся между ними. Groq owns serving price, limits, latency и roster. Метка openai/gpt-oss не делает строку официальной OpenAI API ценой.
Self-hosting имеет смысл только при volume, data locality, hardware access и ops capacity. Иначе free weights прячут GPU utilization, serving engineering, monitoring и on-call.
Что ломает простые таблицы цен
Output ratio — первая ловушка. Chatbot или report generator может платить больше за output, чем input.
Caching — вторая. У OpenAI, Google, Anthropic, DeepSeek и Groq разные semantics, cache hit/miss rows и иногда storage cost.
Batch — третья. Это offline route для extraction, eval generation и enrichment, а не realtime chat.
Tool/search fees — четвертая. Web search, Google Grounding, compound tools и router features могут стать значимой частью bill.
Preview, intro и thresholds — пятая. Sonnet intro has end date, Gemini Pro Preview changes by prompt length, DeepSeek aliases deprecate.
Retry overhead обязателен. Модель с 1.3 attempts per accepted answer должна считаться как 1.3 attempts.
Заметки по providers
OpenAI pricing page owns OpenAI direct token rows and separates Standard, Batch, Flex, Priority, plus regional/data-residency caveats.
Anthropic pricing page owns Claude direct rows plus cache, Batch, Fast mode и data-residency modifiers. Для API vs subscription смотрите Claude API pricing versus subscription.
Google Gemini pricing owns Gemini Developer API rows, Free Tier, Batch и grounding fees. Для free quota смотрите Gemini API free tier.
DeepSeek pricing now presents deepseek-v4-flash and deepseek-v4-pro; legacy chat/reasoner names map to V4 Flash and have a scheduled deprecation.
Mistral public pricing supports Mistral Large row and 50% Batch discount; do not invent other rows.
xAI docs point chat to Grok 4.3 and coding to Grok Build 0.1; keep voice/image/video units out.
Groq is a hosted open-model serving lane, official for GroqCloud serving only.
OpenRouter is router/marketplace economics, not official provider pricing.
Production recheck checklist
| Check | What to record |
|---|---|
| Price owner | Official provider, hosted provider, router, cloud marketplace или self-hosted route. |
| Model ID | Exact model string, alias/preview/dated/deprecation status. |
| Token mix | Input, cached input, output, reasoning tokens и output ratio. |
| Route fees | Platform fee, request fee, search/tool fee, cache storage, data residency, marketplace uplift. |
| Quality threshold | Pass rate, retry rate, fallback rate, human-review rate, failed-output cost. |
| Latency and limits | RPM, TPM, context limit, batch window, timeout, provider status behavior. |
| Data route | Retention, training use, region, enterprise terms, audit needs. |
| Spend controls | Hard caps, alerts, per-project budgets, tenant attribution, rollback route. |
Часто задаваемые вопросы
Какой LLM API самый дешевый сейчас?
Для простых high-volume text tasks hosted open-model routes вроде Groq GPT OSS 20B или direct low-cost rows вроде DeepSeek V4 Flash выглядят дешево. Реальный победитель определяется после output ratio, cache, batch, retries, route fees и quality threshold.
OpenAI дешевле Claude или Gemini?
Зависит от model и workload. GPT-5.4-nano/mini могут быть cost-effective, Claude Sonnet 5 может окупаться качеством coding/agentic, Gemini 3.1 Flash-Lite — высоким volume в Google ecosystem.
Стоит ли использовать router вроде OpenRouter?
Да, если switching, fallback, one account или comparison экономят engineering time. Но platform fee, request limits и routing behavior входят в cost model.
Free tiers подходят для production?
Обычно нет. Это exploration и prototypes. Production требует predictable quota, billing owner, data terms, support path и spend controls.
Почему output price так важен?
У многих providers output tokens стоят в разы дороже input. Chatbot, agent или report generator often spend more on output.
Как cache и batch меняют победителя?
Cache помогает repeated prompts и stable prefixes; batch — offline workloads. Они меняют ranking только если workload реально matches conditions.
Можно ли доверять third-party pricing tables?
Используйте для discovery. Final pricing должен идти к official owner page; router/hosted-provider pages own only their route economics.
Как часто обновлять сравнение цен LLM API?
Перед каждой production decision и каждым published refresh. Model names, preview status, cache rules, batch discounts и router fees меняются быстро.