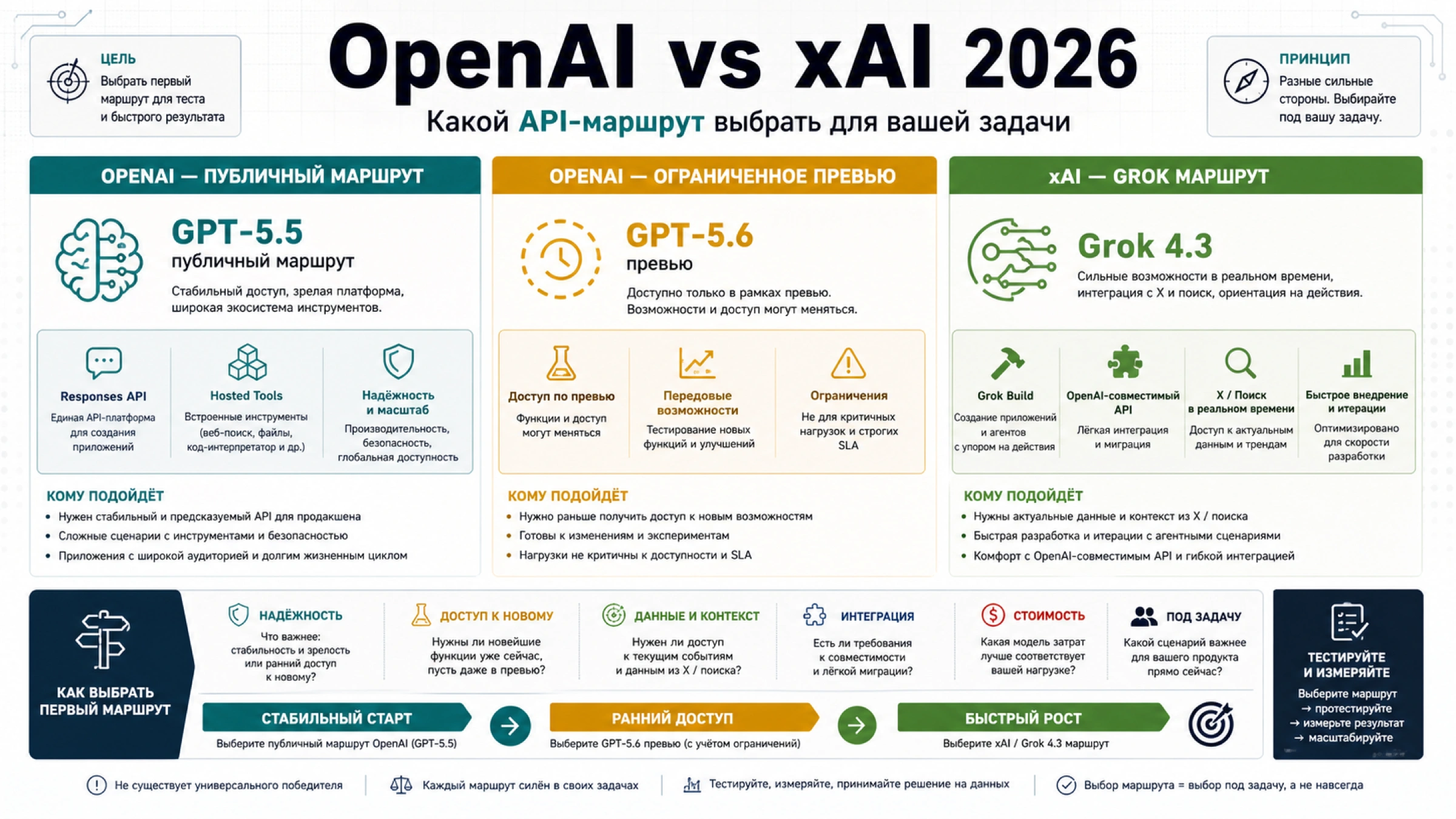
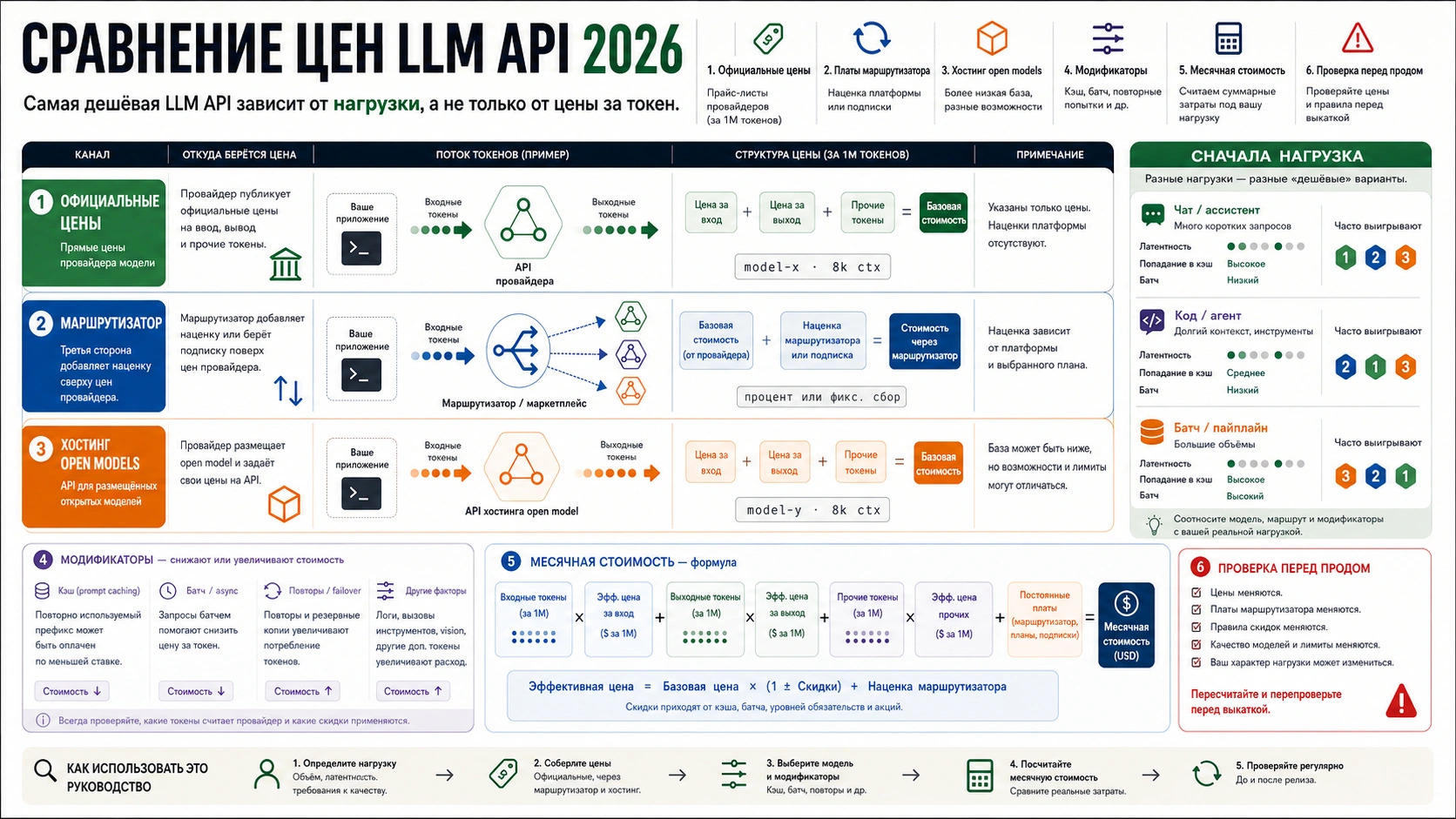
На 2 июля 2026 года прямой Standard-тариф OpenAI для o4-mini составляет $1.10 за 1M входных токенов, $0.275 за 1M кешированных входных токенов и $4.40 за 1M выходных токенов. Эта строка не равна полной стоимости запроса: скрытые reasoning tokens оплачиваются как выход, Batch и Flex меняют маршрут цены, а для новых reasoning-нагрузок текущие документы OpenAI заставляют сравнивать более новые GPT-5.x модели.
| Что нужно решить | Первая строка для проверки | Практический смысл |
|---|---|---|
| Обычная прямая API-стоимость | Standard: $1.10 input / $0.275 cached / $4.40 output | Базовая оценка для синхронных вызовов OpenAI direct. |
| Асинхронная пакетная работа | Batch: $0.55 input / $2.20 output | Подходит для офлайн-оценок, backfill и массовой классификации. |
| Низкоприоритетная онлайн-нагрузка | Flex: $0.55 input / $0.138 cached / $2.20 output | Это сервисный уровень, а не универсальная цена по умолчанию. |
| Премиальная обработка | Priority: $2.00 input / $0.50 cached / $8.00 output | Не использовать как обычную Standard-оценку. |
| Похожие, но другие строки | Deep Research, fine-tuning, Azure, providers | Это отдельные контракты и отдельные таблицы бюджета. |
Рабочее правило: оценивать o4-mini через fresh input, cached input, visible output и reasoning tokens до вывода о дешевизне. Оставляйте модель там, где evals уже подтверждают качество; для новых задач тестируйте GPT-5.4 mini или GPT-5.5; для extraction, classification, formatting и routing сначала проверяйте более дешевую non-reasoning модель.
Что означает o4-mini сейчас
Страница модели OpenAI по-прежнему указывает o4-mini как reasoning-модель с идентификатором o4-mini и снимком o4-mini-2025-04-16. Модель описана как быстрый и экономичный вариант для reasoning, coding и visual задач. При этом она уже имеет преемника в новой линейке, поэтому корректная позиция звучит так: o4-mini можно использовать в проверенных маршрутах, но не стоит автоматически выбирать ее для новой системы.
Русскоязычные материалы часто смешивают OpenAI direct, локальных провайдеров, proxy-API, Azure и калькуляторы. Это разные поверхности биллинга. Если в логах записан o4-mini, бюджет для direct-вызова должен начинаться с direct-строки OpenAI, а provider-курс, лимиты и поддержка должны жить в отдельной колонке закупки.
Главный вопрос для production не в названии модели, а в измеренной стоимости выполнения задачи. Если o4-mini решает конкретный класс запросов с приемлемой точностью, коротким выходом и низким retry rate, ее можно оставить. Если задача новая, цена одной строки не заменяет тест качества и отказов.
Для российских команд особенно важно не смешивать direct API и provider-route. Provider может быть нужен из-за оплаты, доступа или локального support, но его цена не переписывает официальную строку OpenAI.
Если закупка идет через посредника, держите два бюджета: техническая оценка direct tokens и операционная оценка provider fees. Иначе невозможно понять, что оптимизировать: prompt, route, retry или контракт.
Минимальный usage log должен хранить model, service tier, input tokens, cached tokens, output tokens, reasoning tokens и request class. Без этих колонок тарифная таблица превращается в догадку.
Для production-решения одной price row недостаточно. В таблице бюджета должны быть request class, средний fresh input, cached input ratio, visible output, reasoning tokens, retry rate и human repair. Только тогда видно, почему маршрут дорогой: длинный prompt, слабый cache hit, слишком свободный reasoning budget или модель, которая часто не проходит с первого раза.
Eval set лучше делить на три группы: стабильные старые задачи, сложные пограничные задачи и negative samples без настоящего reasoning. Первая группа показывает, можно ли оставить o4-mini; вторая показывает, когда нужен GPT-5.5; третья защищает от привычки отправлять extraction и formatting в reasoning-модель без пользы.
Финансовая коммуникация тоже должна быть разделена. OpenAI direct row отвечает за техническую оценку токенов. Batch, Flex и Priority отвечают за операционную route. Azure или provider отвечают за закупку, валюту и доступ. ChatGPT subscription вообще не является API token billing. Если смешать эти уровни, оптимизировать будет нечего.
После запуска полезны два ранних сигнала: доля reasoning tokens в output-side tokens и доля cached input во входе. Рост reasoning может означать, что prompt стал расплывчатым или задача ушла в сложность. Падение cache ratio часто означает, что стабильный префикс сломан или переменные данные попали слишком рано.
Официальные строки цены o4-mini
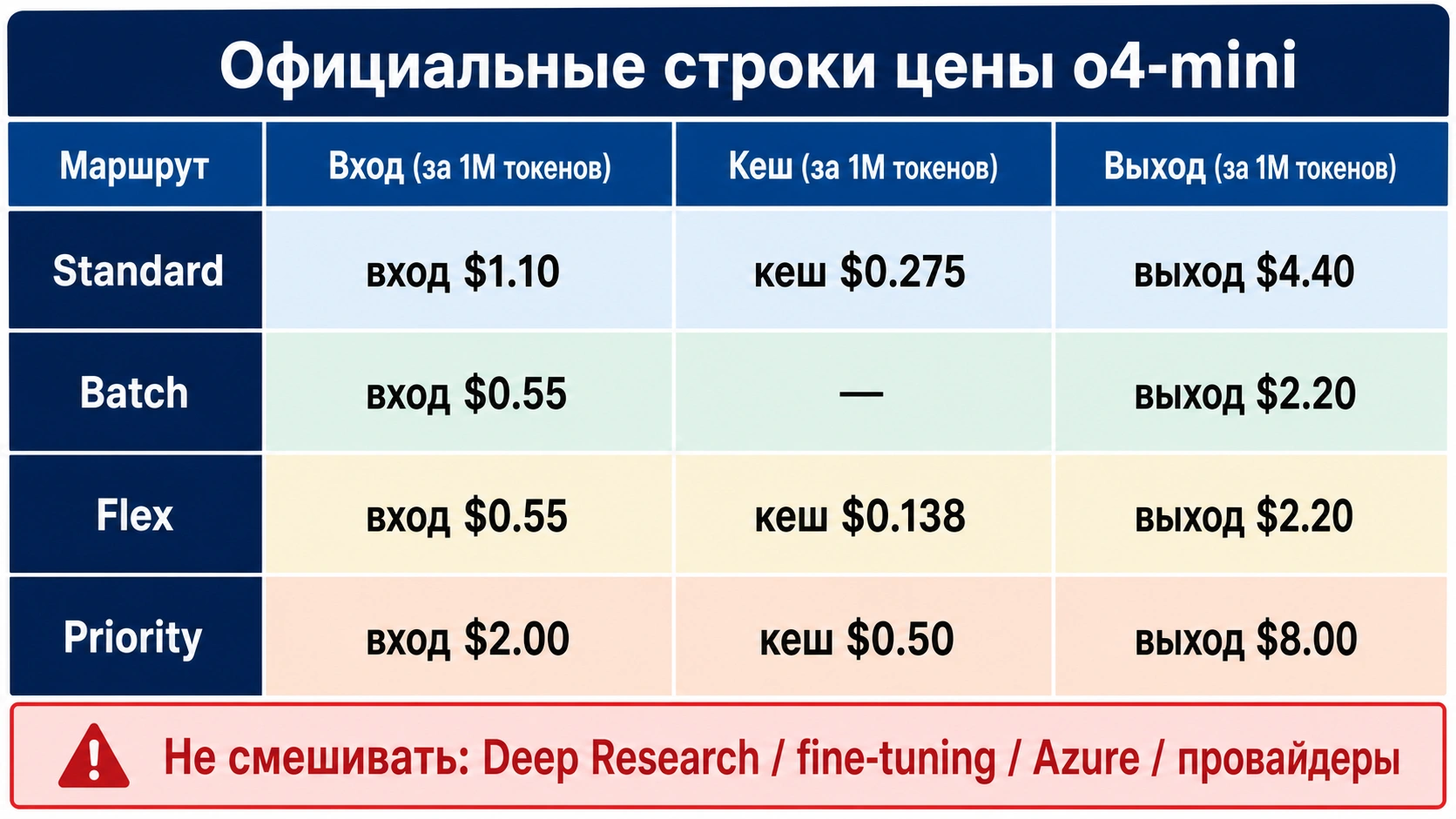
Сначала отделите base inference от сервисных уровней. Standard, Batch, Flex и Priority выглядят как одна семья, но отвечают на разные операционные вопросы. Deep Research, fine-tuning/RFT, Azure и сторонние API имеют собственные условия.
| Маршрут | Input / 1M | Cached input / 1M | Output / 1M |
|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 |
Batch o4-mini | $0.55 | не указано отдельно | $2.20 |
Flex o4-mini | $0.55 | $0.138 | $2.20 |
Priority o4-mini | $2.00 | $0.50 | $8.00 |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 |
Как оценить реальную стоимость запроса
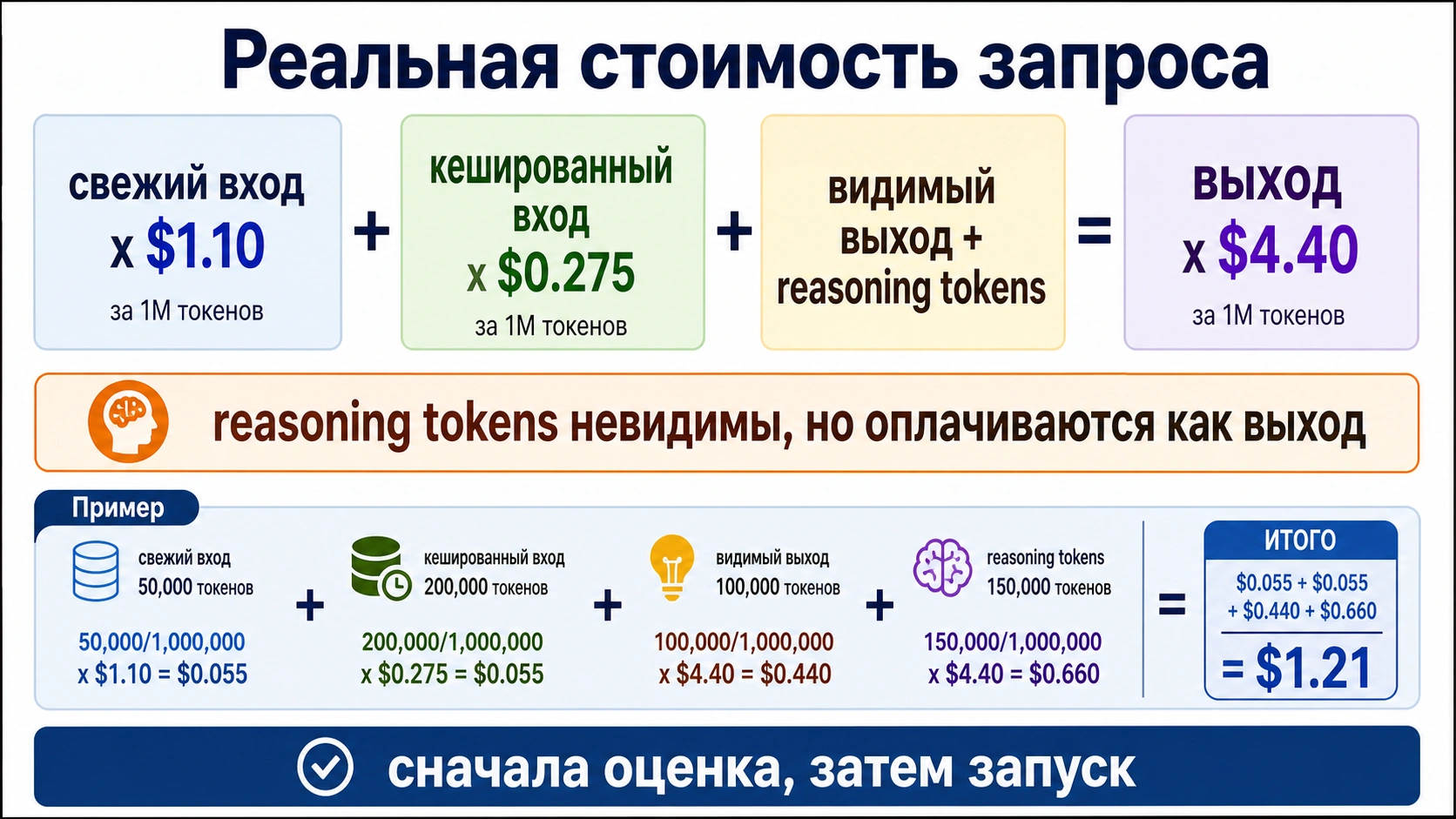
hljs textcost = fresh_input / 1,000,000 * 1.10 + cached_input / 1,000,000 * 0.275 + (visible_output + reasoning_tokens) / 1,000,000 * 4.40
Для Standard-маршрута используйте формулу: fresh input / 1,000,000 * 1.10 плюс cached input / 1,000,000 * 0.275 плюс visible output и reasoning tokens вместе / 1,000,000 * 4.40. Reasoning tokens не видны пользователю, но они занимают контекст и оплачиваются как output.
Пример: 10,000 fresh input, 0 cached input, 2,000 visible output и 3,000 reasoning tokens. Вход стоит $0.011, output-side часть стоит $0.022, итог около $0.033. При единичном вызове это мало, но при 100,000 вызовах в день скрытые reasoning tokens становятся заметной статьей.
В длинном prompt сценарии 80,000 входных токенов могут содержать 60,000 cached tokens. Тогда fresh часть равна 20,000, cached часть стоит дешевле, но выход и reasoning все равно считаются по output-ставке. Это особенно важно для агентов, которые дают короткий ответ после длинного скрытого рассуждения.
Когда o4-mini все еще имеет смысл
o4-mini хорошо защищена там, где есть eval suite: coding review с ограниченным ответом, логические проверки, небольшие математические задачи, visual reasoning и второй слой router decision. В этих зонах модель может давать приемлемое качество с меньшей полной стоимостью.
Оставление модели должно быть осознанным. Отслеживайте latency, visible output length, reasoning tokens, retry rate, human repair и downstream failure. Дешевая ставка за токен не спасает маршрут, если он генерирует больше рассуждения или чаще требует повтора.
Хороший router не выбирает одну модель навсегда. Он оставляет o4-mini для проверенных классов запросов, поднимает сложные задачи к GPT-5.5, тестирует GPT-5.4 mini для новых бюджетных reasoning job и отправляет простое извлечение к non-reasoning модели.
Когда стоит сменить модель
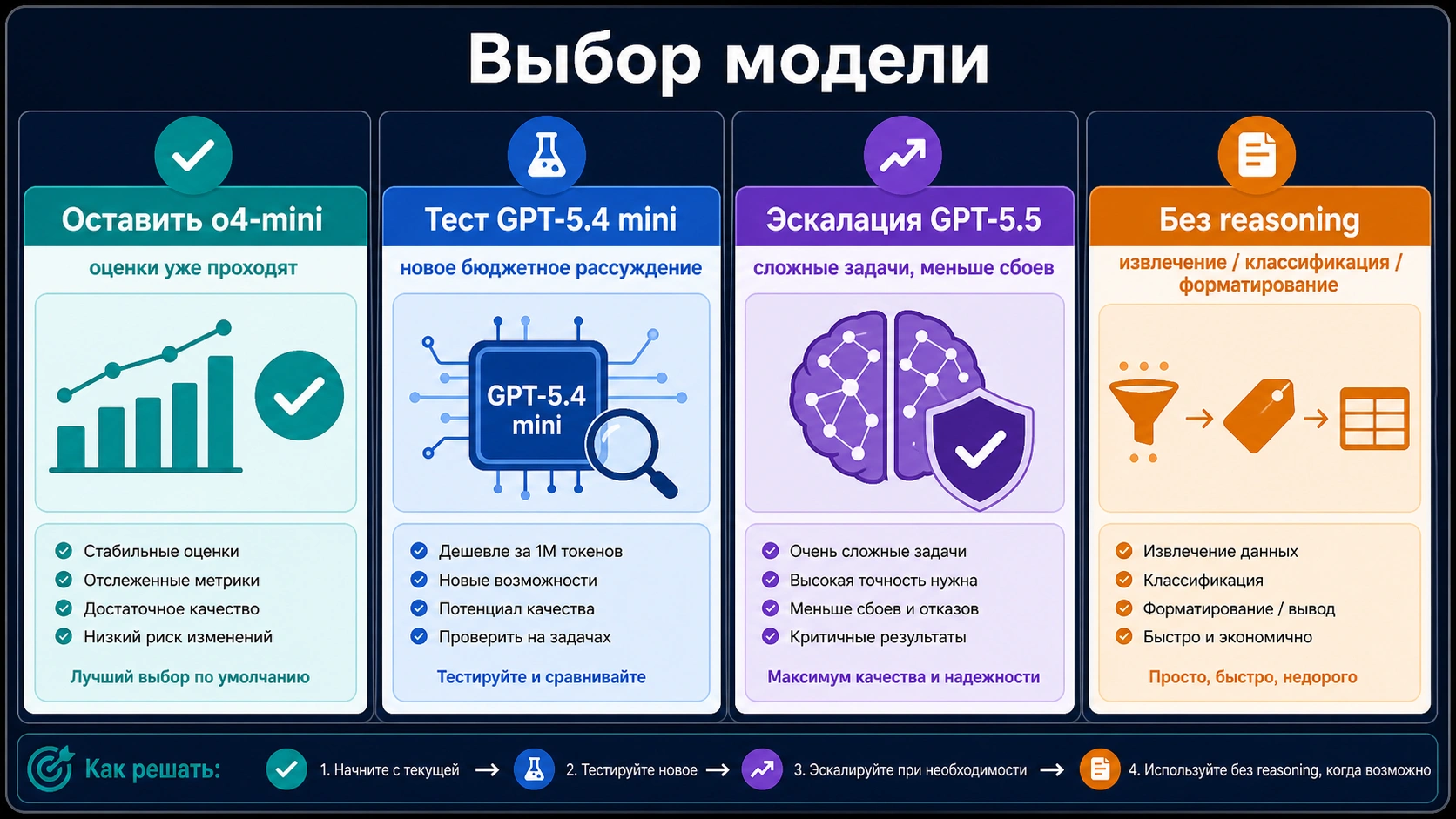
Для новой reasoning-функции начните с сравнения новых GPT-5.x рекомендаций. GPT-5.4 mini полезен как бюджетная reasoning-линия, GPT-5.5 как качество и надежность для сложных задач. o4-mini стоит оставить в сравнении, но не назначать победителем без измерений.
Если задача сводится к extraction, classification, formatting, metadata normalization или routing prefilter, reasoning-модель часто не нужна. В таких местах дешевле снизить сложность маршрута, чем искать еще одну скидку в тарифной таблице.
| Нагрузка | Сначала тестировать | Причина |
|---|---|---|
Существующий o4-mini lane прошел evals | Оставить o4-mini и ретестировать | Есть production baseline. |
| Новое бюджетное reasoning | GPT-5.4 mini и o4-mini рядом | Новая модель может выиграть по quality per dollar. |
| Сложное планирование или coding repair | GPT-5.5 | Меньше повторов может окупить цену. |
| Extraction, classification, formatting, routing | Non-reasoning model | Reasoning tokens часто не добавляют пользы. |
Контроль затрат, который действительно работает
Prompt caching работает, когда длинный префикс стабилен. Держите системные инструкции, JSON schema, политики и повторяемые reference blocks в начале, а переменные данные пользователя переносите ниже. Тогда cached input действительно снижает стоимость.
max_output_tokens для reasoning-модели ограничивает не только видимый текст. Если бюджет слишком маленький, модель может потратить его на reasoning и не дать полезный ответ. Если слишком большой, скрытая output-часть будет расти без видимого сигнала.
Batch снижает цену, но требует асинхронного окна. Flex может быть дешевле, если подходит низкий приоритет. Priority дороже и должен использоваться только при доказанной операционной причине. Самый сильный контроль все равно приходит от меньшего количества запросов, более коротких prompts, меньшего retry rate и правильного routing.
Если блокирует 429 или quota, сначала откройте руководство по OpenAI API rate limit; если проблема в key, billing или trial state, начните с руководство по OpenAI API key free trial.
Типичные ошибки
Не переносите fine-tuning/RFT строки в base inference budget. Training hours, tuned-model inference и data-sharing настройки не равны обычному Standard-вызову.
Не считайте o4-mini-deep-research обычным o4-mini. Это отдельная специализированная модель с другой задачей.
Не копируйте Azure или provider-цену в OpenAI direct spreadsheet. У локального провайдера могут быть валютная конвертация, proxy-limits, support и собственные правила.
Не игнорируйте reasoning tokens. Короткий ответ может оказаться дорогим, если модель долго рассуждала внутри.
Чеклист перед запуском
- Проверьте model ID в коде, логах и usage dashboard.
- Используйте Standard для обычной direct-оценки, а Batch, Flex и Priority держите в отдельных строках.
- Разделяйте fresh input и cached input.
- Складывайте visible output и reasoning tokens для output-side стоимости.
- Сравните GPT-5.4 mini и GPT-5.5 на собственном eval set.
- Для rate limit проблем используйте локализованную инструкцию по OpenAI API rate limits; для ключей и биллинга проверьте страницу про API key free trial.
Часто задаваемые вопросы
Сколько стоит o4-mini API сейчас?
На 2 июля 2026 года Standard OpenAI direct: $1.10 input, $0.275 cached input, $4.40 output за 1M tokens. Остальные маршруты нужно считать отдельно.
Оплачиваются ли reasoning tokens?
Да. Hidden reasoning tokens считаются output tokens, даже если пользователь видит короткий ответ.
Cached input считается второй раз?
Нет. Это часть текущего входа, которая получила cached rate из-за повторяемого префикса.
Batch дешевле Standard?
Да по строке цены, но это async-маршрут с 24-hour window. Для интерактивных сценариев он обычно не подходит.
Flex и Batch одинаковые?
Нет. Flex - lower-priority service tier, Batch - asynchronous batch route.
o4-mini deprecated?
Документы OpenAI продолжают показывать модель и одновременно указывают преемника. Это сигнал тестировать новые модели, но не приказ удалять проверенный production lane.
Выбирать o4-mini или GPT-5.4 mini?
Сравнивайте на evals. Для новой бюджетной reasoning-задачи GPT-5.4 mini часто должен быть первым кандидатом, но o4-mini может остаться победителем в старом стабильном lane.
Как считать monthly spend?
Оцените один запрос, умножьте на volume, добавьте retry rate, failed calls, route share Batch/Flex/Priority и сверяйте с usage logs.