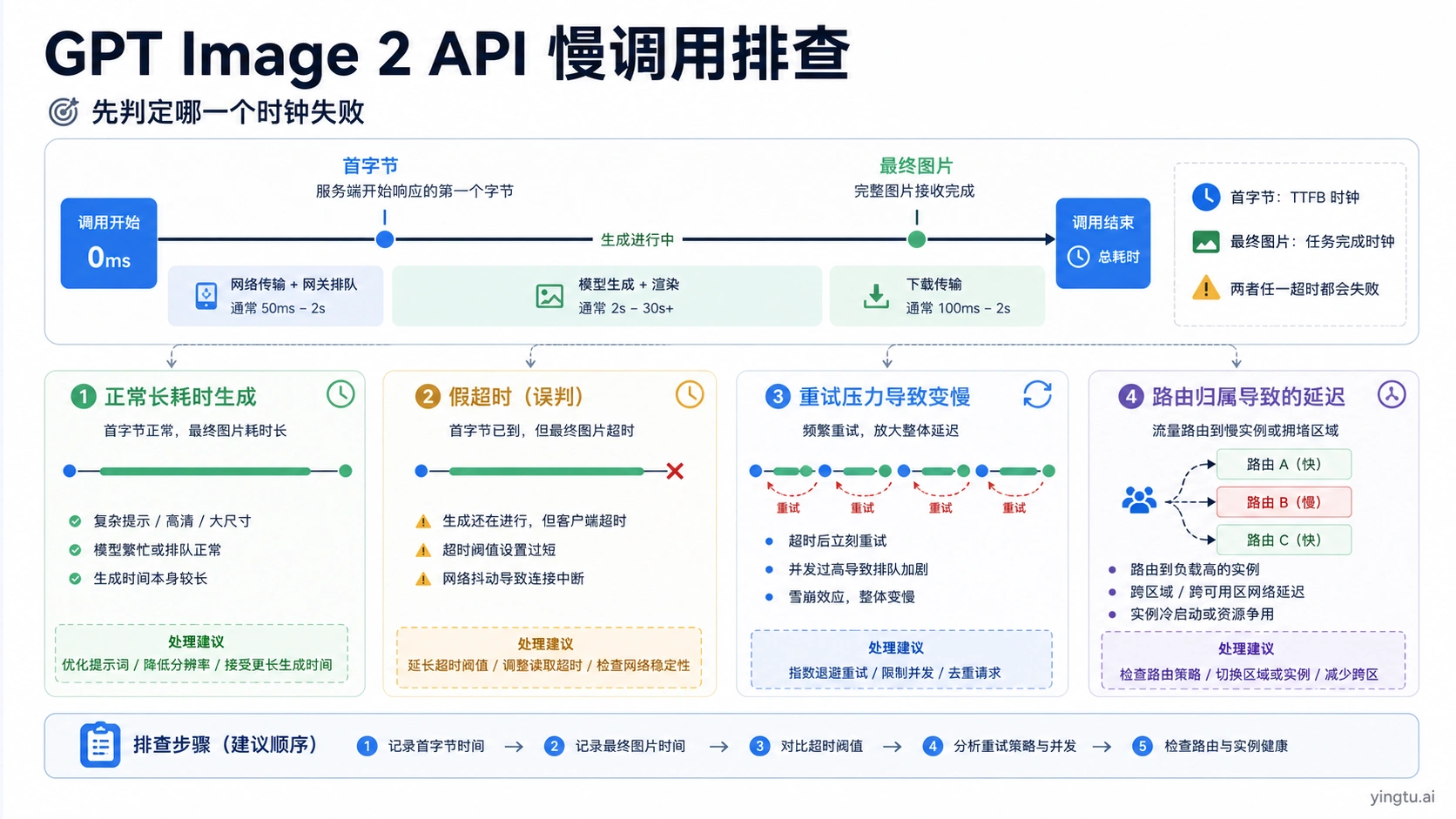
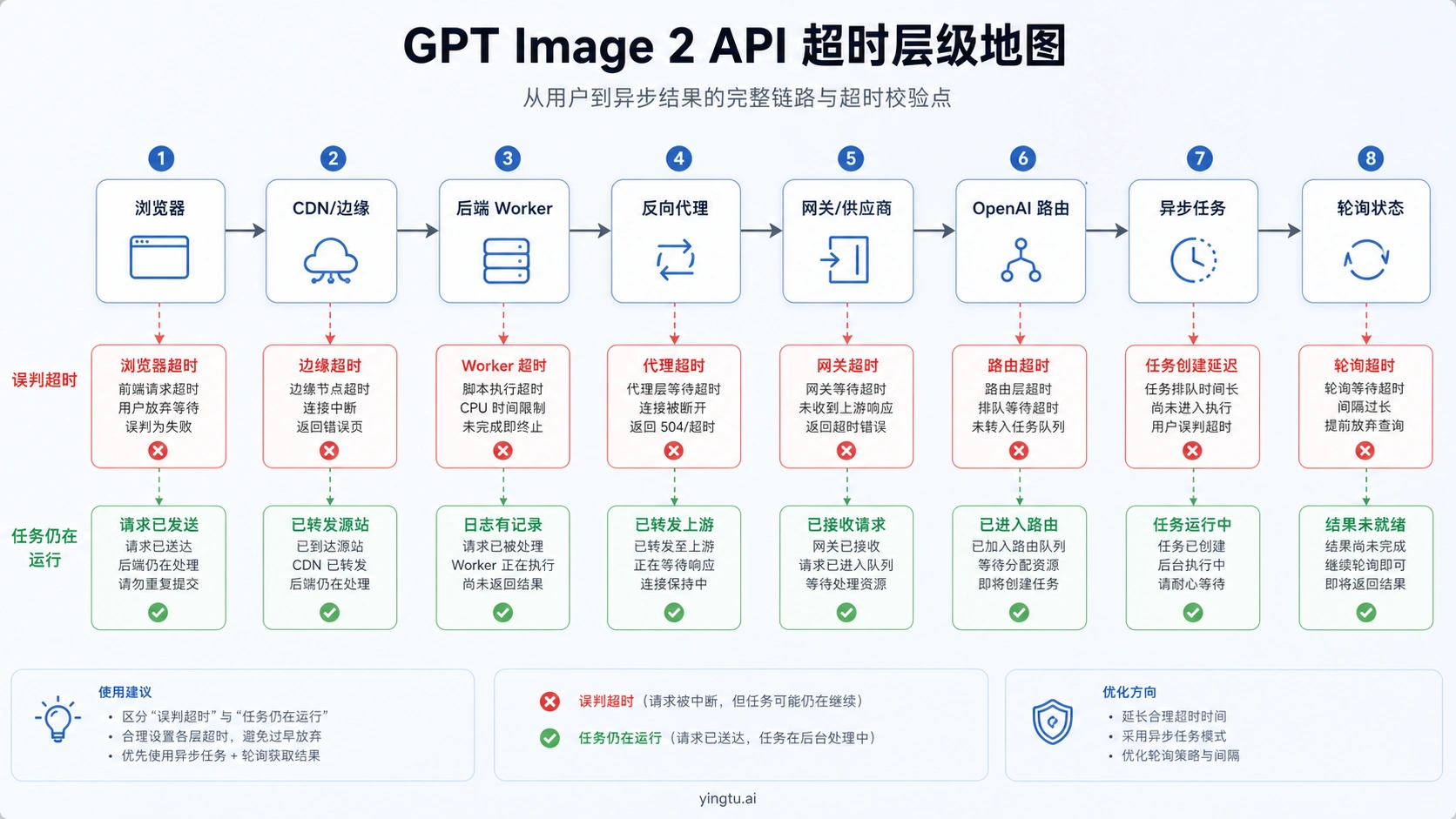
GPT Image 2 API 变慢时,先不要把问题归因给模型本身。复杂提示词确实可能需要接近两分钟,但很多“慢”其实是浏览器、Serverless、反向代理、网关、前端 fetch 或重试策略先超时。第一轮排查只做一件事:把同一次生成拆成连接、首字节、首个局部图、最终图片、下载、渲染、重试次数、HTTP 状态、request ID、模型、quality、size、format、路由归属和失败层。
| 你看到的现象 | 先归类 | 第一安全动作 |
|---|---|---|
| 首字节很晚,但最后能返回图片 | 模型计算或队列等待 | 给用户展示进行中状态,必要时使用流式或异步任务,再单独测试低质量或方图 |
| 后端成功,浏览器或代理失败 | 假超时 | 放宽真正失败的那一层,不要全链路一起放大 |
| 重试堆积或出现 429 | 重试压力或限流压力 | 停止密集重试,读取限制头,用退避和队列排空 |
| 只有某个网关或中转慢 | 路由归属延迟 | 用相同请求形态对比直连或另一条可观测路由,再带脱敏证据升级 |
不要先换 key、换供应商、降低画质或无限重试。慢调用的第一答案,是确认哪一个时钟失败、哪一个系统拥有日志。
判断是正常等待还是假超时
GPT Image 2 的慢调用至少有三类。第一类是正常的长生成:提示词复杂、参考图多、输出尺寸大、quality 高,最终会返回图。第二类是假超时:上游还在生成,浏览器、边缘函数、代理或网关先断。第三类是失败后被重试放大:本来一次慢请求变成多次并发请求,最后又碰到速率限制。
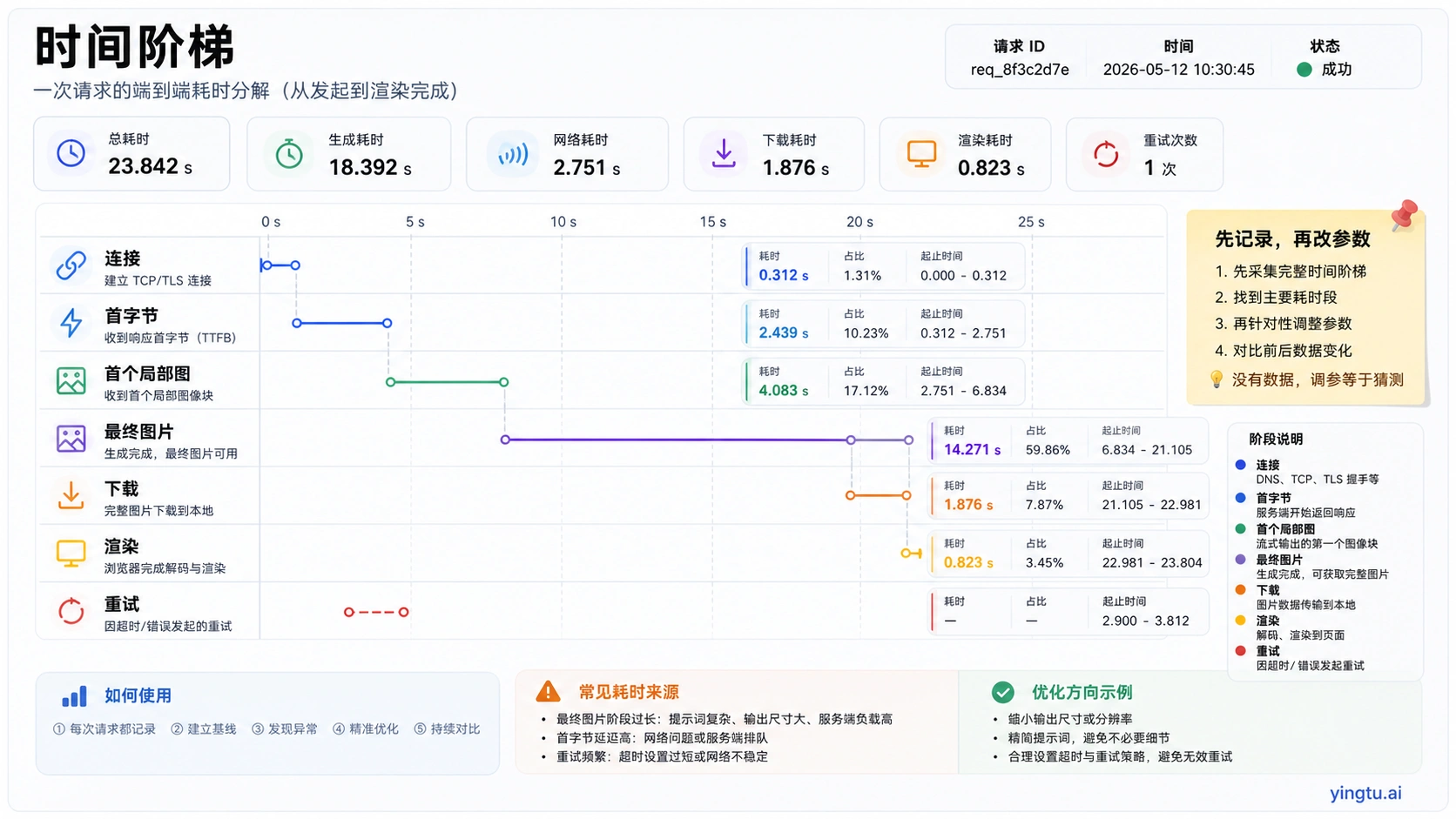
Use one structured log event, but write it in your own Chinese code comments so every operator can read it. request_started_at and connect_ms separate network setup from model work. first_byte_ms shows whether the route stayed silent. first_partial_image_ms matters only when streaming partial images are enabled. final_image_ms measures generation completion rather than frontend rendering. download_ms and render_ms catch large output or browser decoding. retry_count and retry_reason show whether the product multiplied the work. http_status, error_type, request_id, model, quality, size, format, and route_owner make comparisons possible.
同一个 gpt-image-2 标签可能经过 OpenAI 直连、Azure、兼容网关、反向路由或自建代理。模型名相同不等于链路相同。只要 base URL、超时策略、重试策略、日志归属不同,就必须作为不同路线记录。如果同一个提示词在直连快、在某网关慢,模型不再是唯一嫌疑。
建立适合图片生成的超时预算
超时预算不是把所有层都改成 300 秒。更好的做法是让每一层知道自己在等待什么:浏览器等状态,后端等任务,代理等上游,队列等工作完成。同步等待越靠近用户,越容易制造“前端失败但后端仍在跑”的假故障。
| 层 | 常见故障 | 更稳的规则 |
|---|---|---|
| 浏览器或移动端 | fetch 在后端完成前 abort | 不让浏览器持有完整生成窗口,返回 job ID 或流式进度 |
| CDN/边缘函数 | 平台请求上限截断 | 把图片生成移出短生命周期边缘路径 |
| 后端 Worker | 函数运行超时 | 使用长运行 worker、队列或后台任务 |
| 反向代理 | upstream 或 idle timeout | 只针对图片路由提高失败层,不要全局放宽 |
| 网关或供应商 | 内部等待或重试不可见 | 单独看路由日志、上游状态和超时设置 |
| HTTP/SDK 客户端 | 本地 timeout 先触发 | 设置与产品路径匹配的显式超时和重试上限 |
一个交互式产品不应该让用户盯着空白 loading。更可靠的路径是:创建任务、返回任务 ID、展示 queued、generating、finalizing、saved、failed 等状态。如果需要同步返回,也要把首字节、局部图和最终图分开记录。
调参数前先固定基线
OpenAI 的图片生成指南给了几个官方方向:低 quality 更适合草稿,方图通常更快,JPEG 在关注延迟时通常比 PNG 更合适,复杂提示词可能需要接近两分钟。这些都是调优开关,但不能代替诊断。没有基线时同时改 quality、size、format、路由和重试,只会让日志失去解释力。
| 改动 | 可能改善 | 可能损伤 | 何时尝试 |
|---|---|---|---|
| quality 设为 low | 草稿反馈速度 | 细节、文字和成片质量 | 概念图、缩略图、内部预览 |
| 方图输出 | 生成和布局更简单 | 不适合固定横竖版式 | 可以后期裁切或拼版时 |
| JPEG | 传输和浏览器解码 | 透明度和部分后期流程 | 预览或照片类图片 |
| PNG/WebP | 质量、透明或压缩控制 | 可能增加传输和处理 | 需要后期或高质量交付时 |
| 减少参考图 | 上传和输入处理 | 风格、身份和构图控制下降 | 多参考图没有带来稳定收益时 |
| 简化提示词 | 模型工作量和审核复杂度 | 细节指令变弱 | 慢钟明确发生在生成阶段时 |
如果质量本身是产品价值,不要为了一个数字把成片质量牺牲掉。草稿可以低质量,客户交付、商品主图、设计资产可能需要高质量加异步任务。质量分支可以继续看 /zh/blog/gpt-image-2-low-quality/,大尺寸分支可以看 /zh/blog/gpt-image-2-4k-image-generation/。
用流式和异步改善体感延迟
流式局部图能让用户更早看到“任务活着”,但它不等于最终生成计算更快。把流式当作产品状态工具,而不是性能魔法。日志里至少要分开记录首字节、首个局部图和最终图片。
当流式不适合时,异步任务更稳。后端创建图片任务,前端轮询或订阅状态,用户看到明确阶段。这样比浏览器一直持有请求安全,也能阻止重复点击。重复点击在图片生成里不是普通刷新,它可能创建新的计费任务、占用并发并引发 429。
防止重试把慢调用放大成限流
慢调用和限流会互相喂养。如果本地 60 秒超时后立刻重试,而原任务仍在上游运行,就可能从一次生成变成多次生成。OpenAI 速率限制文档也提醒,失败请求可能仍计入每分钟限制,所以密集重试不是恢复策略。
| 条件 | 重试规则 |
|---|---|
| 本地 timeout,没有上游结果 | 先查原任务是否仍在运行,不要马上创建新图 |
| 返回 429 或限制头 | 按 reset 头和指数退避排队 |
| 返回 5xx | 有上限、有抖动、有最大次数 |
| 用户再次点击生成 | 复用同一 pending job,或明确提示会创建新任务 |
| 网关内部已重试 | 把网关重试和自家重试分开计数 |
这里的目标不是避免所有重试,而是避免重复制造同一张图。产品层要有去重概念:同一用户、同一提示词、同一参数、同一 pending 状态,默认返回原任务状态,而不是再发一次。
分清 OpenAI、Azure、网关和反向路由
慢在哪里,决定该找谁。OpenAI 直连要看模型 ID、端点、request ID、状态码和限制头;Azure 要看 deployment、区域、Azure quota 和 APIM;兼容网关要看 base URL、上游状态、超时和内部重试;反向路由则要把账号池、会话、不可见重试和支持风险单独隔离。
如果相同参数在直连快、在某网关慢,模型不是唯一嫌疑。如果某网关不能提供透明日志,不能说明上游是否仍在跑,也不能区分本地超时和模型等待,它就不适合承担生产延迟诊断。成本或接入选择可以走 /zh/blog/gpt-image-2-api-cheap/,配额问题走 /zh/blog/gpt-image-2-usage-limits/,当前页面只解决慢钟和归属。
用正确证据升级

升级材料越干净,支持和工程排查越快。一个合格证据包包括时间戳、时区、是否重复发生、路由归属、模型和端点、quality、size、format、是否流式、首字节、首个局部图、最终图片、下载、渲染、失败层、重试次数、HTTP 状态、request ID、worker、代理、CDN、浏览器 timeout,以及最小脱敏复现。
不要发送 API key、token、完整用户提示词、私有图片、原始客户 ID、IP、渠道 ID、账号池细节或未脱敏日志。需要 request ID 时,发送 request ID 和时间,不要把带密钥的完整请求贴出去。升级后的决策也要具体:只放宽某个 timeout,改异步任务,降低草稿参数,换输出格式,拆分 4K 任务,调整退避,或把问题交给真正拥有日志的路由方。
做一个最小复现实验
当日志已经能分出首字节、最终图片和失败层之后,再做最小复现实验。不要在一次实验里同时换模型、换网关、改 quality、改 size、改 format、改 retry、改 timeout。每一轮只改变一个变量,其他条件保持一致。这样结果才有解释力,也能给支持方或供应商留下清晰证据。
推荐实验顺序是:先用同一个 prompt、同一个 size、同一个 quality、同一个 format、同一个 route owner 连续跑三次,确认慢是稳定现象还是单次波动。再保持 prompt 不变,只切换同步和异步路径,观察 browser timeout 是否消失。然后只切换 output format,例如 PNG 与 JPEG,对比 download_ms 和 render_ms。之后再把 quality 从 high 调到 low,看 first_byte_ms 和 final_image_ms 是否明显变化。最后才比较 OpenAI direct、Azure 或 gateway 路由。
| 实验轮次 | 保持不变 | 唯一变量 | 判断标准 |
|---|---|---|---|
| 基线 | prompt、quality、size、format、route | 连续三次同路由 | 判断是否稳定慢 |
| 同步对异步 | prompt、参数、route | 浏览器等待方式 | browser timeout 是否消失 |
| 输出格式 | prompt、quality、size、route | JPEG / PNG / WebP | download 与 render 是否变化 |
| quality | prompt、size、format、route | low / medium / high | final_image_ms 是否变化 |
| 路由 | prompt、参数、retry policy | direct / Azure / gateway | route owner 是否决定延迟 |
如果只有高 quality 或大尺寸慢,就不要把结论写成“GPT Image 2 慢”。如果只有浏览器同步路径失败,就不要把结论写成“OpenAI 慢”。如果只有某 gateway 慢,就不要把该结果当作官方模型行为。最小复现实验的价值,就是把结论缩小到真正可修的层。
对团队协作来说,还要把实验结果放进同一张事件表。表里至少包含时间、时区、route owner、base URL 所属方、是否 streaming、是否异步、参数、首字节、最终图片、失败层、重试次数和备注。只要这些字段齐全,即使最后需要升级,也不会变成“用户说很慢、工程说看不出来”的来回。
上线前的护栏
慢调用修好后,还要给生产路径加护栏。第一,生成按钮要有 pending 状态,不能让用户在同一个 job 未结束时连续点击。第二,后端要把同一用户、同一 prompt、同一参数、同一路由的 pending job 合并返回,而不是创建新任务。第三,超时错误要写清楚是 local timeout、gateway timeout、upstream error 还是 returned API error。第四,监控面板要按 route owner 分组,避免把 OpenAI direct、Azure、gateway 和自建代理的耗时揉成一个平均数。
还要把“看起来成功”的慢路径也纳入监控。比如最终图片返回了,但 first_byte_ms 长期超过产品可接受范围;或者最终图片很快,但 download_ms 和 render_ms 在移动端很高;或者重试不多,但用户重复点击多。这些不是发布阻塞,但会变成真实用户体验问题。真正成熟的图片生成链路,不只关心成功率,也关心用户是否知道任务还在运行、是否会误点第二次、是否能在失败后拿到可理解的下一步。
最后,任何跨路线对比都要加说明。直连路线能回答官方模型和参数问题,Azure 能回答部署和区域问题,gateway 能回答中转配置和上游映射问题,前端能回答 browser timeout 和渲染问题。只要证据跨了路线,就不要写成单一结论。这样既能保护读者不误修,也能保护团队不把私有日志、账号池、渠道号或客户数据带进公开排障过程。
团队分工怎么落地
这类慢调用最好不要只交给一个人排查。前端负责确认 browser timeout、重复点击、状态展示、渲染和下载耗时;后端负责确认 job ID、队列、worker timeout、重试上限和幂等;平台负责确认 CDN、反向代理、网关和日志透传;业务负责人负责决定草稿、预览、生产资产分别能接受什么 quality、size 和等待体验。分工清楚后,才不会出现前端只看到失败、后端只看到任务成功、平台只看到上游还在等的断层。
上线前可以把慢调用处理写成一条 runbook:先看是否有 request ID 和 HTTP 状态;没有状态就看首字节;首字节已到就看 partial image 或最终图;最终图已到就看下载和渲染;本地 timeout 已触发就查 job 是否还在跑;出现 429 就暂停密集重试;只有网关慢就找路由所有者。这个顺序能让新人也按同一逻辑处理,而不是每次从“是不是模型慢”重新争论。
如果必须临时降级,也要给降级加边界。草稿可以用 low quality,后台批量任务可以进队列,移动端可以先显示部分图或状态卡,大尺寸任务可以拆成单独流程。但生产封面、客户交付图、商品图和设计源文件不应只为了省几十秒就降到无法使用的质量。慢调用修复的目标是让等待可解释、可观测、可恢复,而不是把所有图片都变成低质量输出。
另外,排障结论要写成可验证句子。不要写“速度不稳定”这种无法行动的话,而要写“gateway 路由的 first_byte_ms 在三次相同参数实验中都明显晚于 direct,browser timeout 不是主因”。也不要写“提高 timeout 已解决”这种半句,而要写“只放宽图片生成 upstream timeout,健康检查、连接超时和普通 API 路由保持原值”。这样的句子能直接变成代码变更、配置变更或支持工单。
每次改动后都保留旧基线,下一轮只比较同一口径的数据。
这样才能把慢调用从感觉问题变成工程证据。
结论必须可复查。
常见问题
GPT Image 2 API 慢是正常的吗?
复杂提示词可能确实慢,但“慢”不能直接等于正常。只要浏览器、worker、代理或网关在最终图片前失败,就要按假超时处理。先看首字节和最终图,不要只看总耗时。
60 秒 timeout 够不够?
对复杂图片任务可能不够,尤其是同步等待最终图片的路径。但不要把所有层都改长。找出失败层,只给图片路由或后台任务足够等待,其余连接和健康检查仍要严格。
流式会让最终图片更快吗?
不会保证最终计算更快。流式的价值是更早给用户进度,减少重复点击,并让日志看到首个局部图。最终图片时间仍要独立记录。
应该先降低 quality 吗?
只有草稿、预览或内部探索适合先试低 quality。生产图、商品图、设计图应该先量出慢钟,再做有对照的 quality、size、format 实验。
网关是不是慢的原因?
只有同形态对比后才能判断。记录 base URL、路由归属、上游状态、网关重试、首字节、最终图和状态码。如果网关没有透明日志,把它和 OpenAI 直连分开,不要混成一个结论。