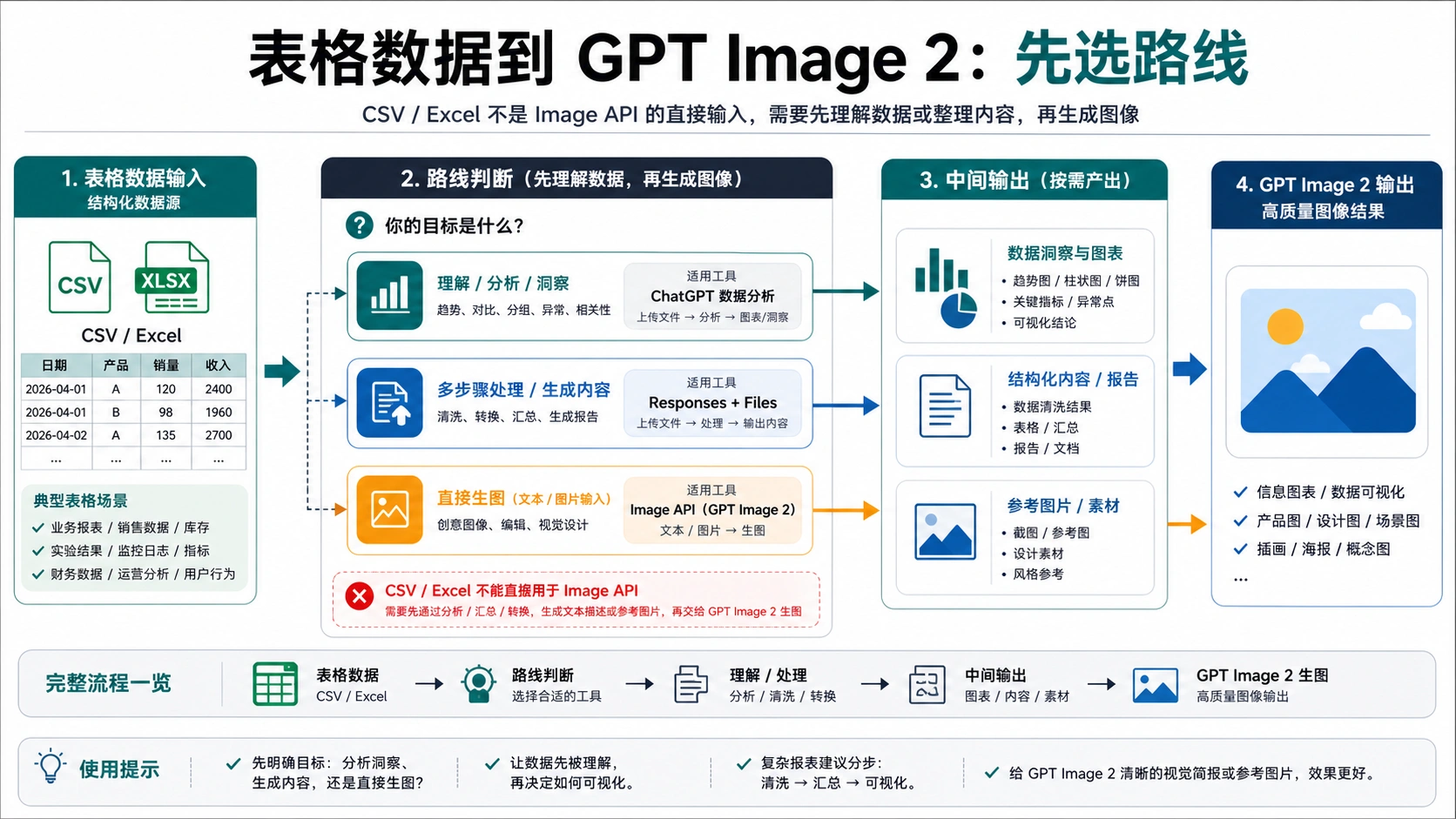
GPT Image 2 的 Image API 不能把 .csv 或 .xlsx 当作直接生图输入。表格文件先属于数据处理问题:读取字段、确认口径、筛选行列、计算指标、决定图像要表达的结论。完成这一步之后,GPT Image 2 才适合接收提示词、视觉简报、图表截图或图片参考。
最实用的分工是三段:ChatGPT 数据分析适合人工上传文件并检查含义;Responses + Files 适合把文件上下文接入应用流程;Image API 负责最后的图像生成或图像编辑。把这三段混成一个“上传文件生图”按钮,通常会得到好看的错误图。
| 任务 | 错误路径 | 正确入口 | 停止规则 |
|---|---|---|---|
| 把销售明细做成信息图 | 把 CSV 直接交给 Image API | 先分析数据,再写视觉简报给 GPT Image 2 | 不要把原始表格当图片传 |
| 把 Excel 图表美化成横版图 | 把工作簿当作参考图 | 导出图表截图,再使用图片参考路线 | 工作簿文件不是图片参考 |
| 批量生成产品或财务视觉 | 让生图模型自己读表 | 代码解析、校验、聚合,再逐张调用生图 | 计算和隐私控制放在生图前 |
| 输出 PPTX、PDF 或 XLSX | 期待 GPT Image 2 直接导出办公文件 | 先生图,再由文档或幻灯片层组装 | 图像模型输出图像,不输出原生表格或演示文件 |
先判断表格在工作流里的角色
CSV 和 Excel 文件常常同时承担三种角色:它们可以是要分析的数据源,可以是已有图表的出处,也可以是最终交付文件的一部分。GPT Image 2 只适合处理其中的“图像表达”部分。只要文件还需要计算、筛选、分组、去重、单位换算或业务解释,它就还没到生图阶段。
人工工作流里,表格通常先进入 ChatGPT 数据分析。用户上传文件,要求模型找出趋势、异常、可视化角度或摘要。这里的重点不是马上生成图片,而是把数据变成一组可以检查的判断:哪些列被使用,计算口径是什么,数字是否能在图片上出现,哪些行应该被排除。
开发工作流里,表格应该由程序解析。应用需要确认字段是否存在、日期格式是否一致、货币单位是否统一、空值如何处理、隐私字段是否需要删除。只有在这些检查完成后,才把缩小后的数据载荷交给生成模型。否则图片看起来越专业,越容易掩盖前面没有校验的错误。
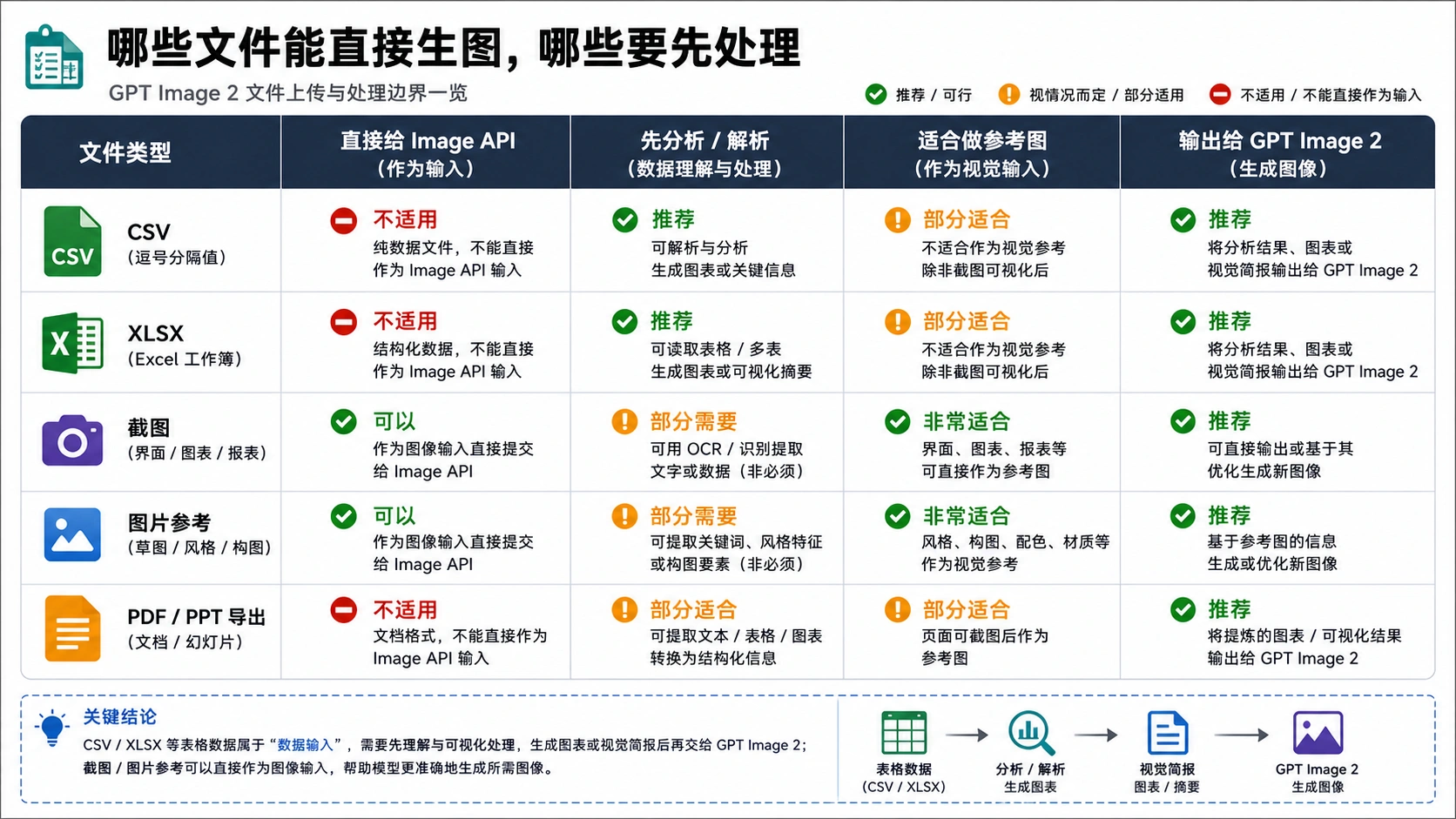
| 输入或输出 | 能否直接作为 Image API 输入 | 更稳妥的路线 | 原因 |
|---|---|---|---|
| CSV 行数据 | 否 | 先解析或人工检查,再写视觉简报 | 行数据需要计算、筛选、分组和叙事选择 |
| Excel 工作簿 | 否 | 人工用 ChatGPT 数据分析,生产用代码解析 | 工作簿可能有多 sheet、公式、隐藏列、合并单元格和格式含义 |
| 图表截图 | 可以作为图片参考 | 导出干净 PNG/JPG,再描述要改成什么样 | 截图已经是图像,适合做视觉上下文 |
| 表格截图 | 可以但要谨慎 | 只截取可见且要保留的区域 | 密集小字和大量数字仍需要人工复核 |
| 产品图或品牌图 | 可以作为图像输入或参考 | 使用编辑或参考路线,并先确认权利和隐私 | 这是图像编辑,不是表格读取 |
| PPTX、PDF、XLSX 输出 | 否 | 先生成图片资产,再由其他工具组装文件 | 生图接口返回图像数据,不负责办公文件结构 |
边界判断越早做越好。只要目标是“理解数据”,先使用文件分析或程序解析;只要目标是“改变一张已有图的视觉效果”,导出截图或参考图;只要目标是“把已确定的信息画成图”,再进入 GPT Image 2。
三个 OpenAI 入口不要混用
文件上传不是一个统一能力。ChatGPT 的文件上传让人和模型围绕一个文件对话;Responses + Files 让应用把文件上下文、工具调用和结构化输出放进一个流程;Image API 的生成路线接收的是提示词和图像相关输入。看到某个入口能处理文件,不能推导出另一个入口能直接读取工作簿。
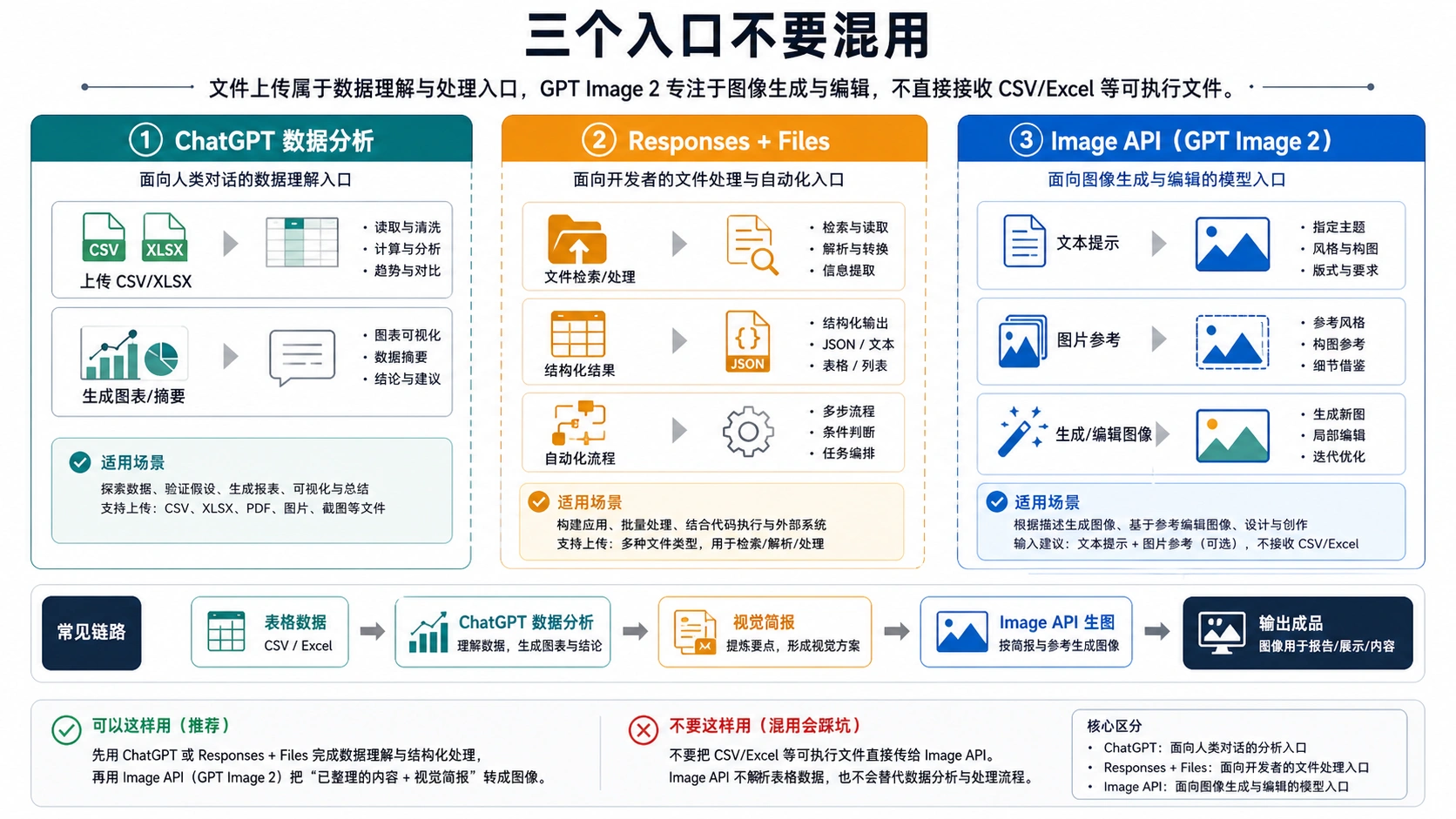
| 入口 | 最适合的任务 | 表格扮演的角色 | GPT Image 2 扮演的角色 | 常见误判 |
|---|---|---|---|---|
| ChatGPT 数据分析 | 人工检查文件、找结论、试做图表 | 用户上传 CSV/XLSX 并要求摘要、图表或视觉方向 | 帮助把分析结果改写成生图提示或图像任务 | 把 UI 里的文件行为当成 Image API 合约 |
| Responses + Files | 应用流程里的文件上下文和工具编排 | 文件可参与检索、提取、转换或结构化输出 | 图像生成可以成为后续工具步骤 | 误以为文件输入等于图像模型直接读 XLSX |
| Image API 生成 | 已有图像需求,直接提示词生图 | 表格内容必须已经变成文字说明或视觉简报 | gpt-image-2 根据提示和参数渲染图像 | 在需要 JSON 提示词的位置发送工作簿 |
| Image API 编辑或参考 | 改造已有图片、跟随参考图 | 表格或图表要先导出成图片 | 模型根据图片参考和提示进行编辑或生成 | 把原始工作簿叫作图片参考 |
| Files API | 为支持的 API 目的存储文件 | 只有下游端点支持时才有意义 | 不是自动通向 Image API 的桥 | 上传 CSV 后期待 gpt-image-2 自动读取 |
直接生图路线适合应用已经知道要画什么的场景。例如:“做一张 16:9 财务信息图,展示第四季度收入按地区分布,北美占比最高,亚太增长最快,十二月退款压力增加”。这些已经是图像可执行的信息。原始工作簿还不是。
Responses 路线适合更完整的产品体验:用户上传文件,系统分析并抽取数据,结构化出图像需求,再调用图像生成。即便这样,也要把合约写清楚:主模型或工具链可以理解文件,最终图像步骤仍然需要提示词、图片输入或图像可执行的说明。
为什么直接上传表格会失败
Image API 生成端点的核心动作是从提示词生成图片。提示词可以包含从表格得到的事实,但端点本身不是工作簿解析器。表格里的行列、公式、筛选条件、隐藏字段、单位和异常值,需要在图像请求之前处理清楚。
编辑或参考路线的输入形态不同。它适合用图像作为上下文,例如图表截图、表格截图、手绘草图、上一版生成图或产品图。.xlsx 文件不是图片参考;它只是一个文件。想保留某个表格布局时,先把目标区域导出为清晰图片,裁掉无关菜单和行号,再要求模型改造视觉层级。
Files API 也容易造成误解。上传文件拿到 file_id 并不意味着每个端点都能读这个文件。file_id 的含义取决于后续路线:在图片参考里,它应该指向图像资产;在文件检索场景中,它属于文本和文档流程;在批处理或微调里,格式和目的又不同。
因此,表格到图像至少有两个阶段。第一阶段是数据阶段:读取、校验、筛选、计算、摘要、决定结论。第二阶段是图像阶段:把结论渲染成图片。合并两个阶段会产生可预测的故障:错列、漏行、把噪声当重点、数字不一致、小字不可读、总额对不上,或者图片很精致但没有回答业务问题。
人工路线:先从文件分析得到视觉简报
人工路线适合一次性图、内部汇报、营销草案、销售摘要、活动复盘和初版图表改造。它的优点是快,且人在生成前能检查结论。它的缺点是不可作为无人工复核的生产流程,也不适合需要严格日志和隐私控制的敏感表格。
先把 CSV 或工作簿上传到支持文件分析的 ChatGPT 会话,然后要求模型做窄范围分析,而不是马上生图。一个稳妥请求可以这样写:
hljs text读取这个工作簿,只关注 Revenue 和 Refunds 两个 sheet。 找出适合做成一张高管摘要图的三个视觉结论。 每个结论都列出使用的行列、计算方法,以及必须写在图上的限制条件。
接着只选择一个结论,把它变成图像简报:
hljs text把第二个结论改写成 GPT Image 2 的视觉简报。 最多使用 6 个标签,保留必须出现的精确数字, 说明图表类型、版式、颜色强调,以及读者 3 秒内应该记住的一句话。 现在不要生成图片。
这个中间简报很重要。它把分析、文案、图表设计和图像渲染拆开,让每一步都能被检查。简报里的指标错了,最后图片一定错;简报里的视觉目标含糊,最后图片就会把版式自由发挥到不可控。
对于多图汇报,一个工作簿可以拆出路线图、趋势图、前后对比、风险清单和产品卡片。每张图都应该有独立简报,因为每张图回答的读者问题不同。不要把整张表塞进一个提示词,期待模型同时做分析师、设计师和校对员。
开发路线:表格解析必须在生图之前
需要重复运行时,开发路线更可靠。产品目录图、周报快照、客户报告、广告变体、本地化信息图和财务异常提示,都需要确定性数据层。图片生成是最后一步,不是数据处理器。

一个稳妥实现通常包含五步:第一,使用常规 spreadsheet 工具读取 CSV 或 XLSX;第二,校验必需字段、类型、单位、日期和行数;第三,把数据压缩成很小的视觉载荷;第四,由载荷生成图像简报;第五,调用 GPT Image 2,并把源数据、提示词、响应 ID、图片文件和复核结果绑定保存。
给图像请求的内容应该像结构化图像需求,而不是整张表:
hljs json{
"visual_type": "executive infographic",
"title": "Q4 revenue grew, but refund pressure moved to December",
"must_show": [
"Q4 revenue: $4.8M",
"North America: 44% of revenue",
"APAC: fastest growth at +18%",
"December refunds: 2.3x October"
],
"layout": "16:9 board with one bar chart, one callout, and one caution strip",
"tone": "clean finance report, high contrast, readable labels",
"do_not_invent": [
"Do not add regions not present in the payload",
"Do not change the numbers",
"Do not create a forecast"
]
}
这种载荷短、明确、可追溯。图像模型知道必须显示哪些数字,也知道不能虚构什么。开发者可以把每张图反查到源文件、处理版本和提示词版本。没有这个记录,图片只能算漂亮草稿,不能进入客户报告或生产页面。
批量场景更需要分解。不要每张图都上传完整工作簿;应该一个输出对应一个载荷:一个产品比较、一个地区摘要、一个续费风险板、一个库存预警或一个客户可读图表。小载荷减少歧义,也让人工复核更快。
截图和参考图路线适合视觉改造
有时不需要模型理解整个工作簿,只需要把已有图表或表格截图改成更清晰的视觉资产。这时应把可见内容导出成图片。导出的图片越干净,模型越容易保留正确结构。
先导出 PNG 或 JPG,裁掉无关 sheet 标签、菜单、行号、列字母、批注和空白区域。然后使用图片编辑或参考路线,并给出明确约束:
hljs text使用附件图表作为数据和布局参考。 把它改成干净的 16:9 高管汇报图。 保留地区名称、相对顺序和可见数字。 标签要足够大,适合投影屏幕阅读。 不要增加新数字或预测值。
截图路线适合已有视觉结构明确、只需要增强层级、对比度、可读性或风格统一的场景。它不适合需要隐藏行、复杂公式、筛选条件或精确 workbook 逻辑的场景。需要计算时,回到数据阶段。
复核方式也不同。用截图做参考后,要把生成图和原截图逐项对比:标签、数字、顺序、颜色、单位、遗漏行和额外说明。只要图里有数字或产品结论,就应该像复核图表一样复核,而不是像装饰图一样只看美观。
隐私和交付边界要先定
表格往往包含客户名称、销售金额、员工信息、医疗资料、法律材料或未公开财务数据。路线选择不能只看方便,还要看数据控制。人工上传前要确认是否允许把工作簿放进对应的聊天环境;应用处理前要确认文件存储、访问权限、日志保留、提示词保留和生成图片保留规则。
更稳的模式是先最小化数据。删除无关列,聚合明细行,把姓名替换成类别,把敏感字段移出图像请求。图片如果只需要“亚太增长最快,+18%”,就不需要把每笔亚太交易都交给图像模型。
交付文件也要分层。用户要求“把 Excel 做成 PPT”时,不是一个生图调用。它至少包含数据分析、视觉资产生成、幻灯片组装、导出和复核。GPT Image 2 可以负责视觉资产,PPTX、PDF 或 XLSX 结构应该由文档或代码层完成。
常见故障和排查顺序
第一类故障是 file_id 捷径。开发者先上传工作簿,拿到文件 ID,然后把它当作图片参考传给 Image API。只有当路线和文件类型都支持时,file_id 才有意义。图片参考需要图片文件;表格文件属于文件分析、检索或预处理。
第二类故障是把原始行粘进提示词。长表格会让图像步骤变得脆弱:模型可能选错行、漏掉限制条件、发明标签、把微小文字画得不可读,或者把总额画成不一致的数字。短视觉载荷通常比长数据粘贴更可靠。
第三类故障是期待原生文件输出。GPT Image 2 输出图像数据。业务用户要 PPT、PDF 或 XLSX 时,流程应该是分析数据、生成图片、组装文件和复核导出,而不是把办公文件生成能力塞进图像模型。
第四类故障是跳过数字复核。图像模型可以生成非常像真图表的画面,但文字、日期和数值仍可能出错。任何包含数字、标签、日期、地区、价格或产品结论的图,都要对照源载荷检查。
第五类故障是问题归类太早。如果真正阻塞是额度或 429,先看 GPT Image 2 usage limits guide。如果问题是选择 ChatGPT 还是 API,先看 ChatGPT Images 2.0。如果问题是成本和供应商路线,再看 cheap GPT Image 2 API guide。CSV/Excel 上传这个场景更窄:表格数据必须先变成图像可执行信息。
还有一种隐蔽故障来自“看起来像表格”的图片。用户把整个 Excel 窗口截屏后,希望模型读出所有单元格并重新设计。截图虽然是图片,但它可能包含滚动条、冻结窗格、筛选箭头、隐藏列提示和很小的数字。图像模型可以参考这种画面,却不能保证像电子表格程序一样读取每个单元格。要提高成功率,应先把需要保留的区域导出为清晰图表,或者把关键数字写进提示词。需要精确数字时,数字来源必须来自解析后的数据载荷,而不是依赖模型从截图中重新读表。
交付前的验收也要按数据资产处理。检查图像是否使用了正确指标、正确单位、正确日期范围、正确地区名称和正确排序;检查图中的警示语是否来自源数据,而不是模型补出的推测;检查图片文件名、源载荷、提示词和复核人是否能对应。只有这些信息能回溯,表格到图像的流程才适合进入客户报告、产品页面或定期自动化任务。
团队协作时,最好把责任边界写进任务单:数据同事确认口径,工程同事确认解析和脱敏,设计或运营同事确认视觉目标,最后再由生成步骤产出图片。这样做会慢一点,但能避免把所有风险压到一个提示词里。对周期性报表而言,这个拆分还能沉淀成模板:同一份字段映射、同一组校验规则、同一种视觉简报格式,每周只替换数据载荷和少量标题,就能得到稳定可复核的图片。
最值得保留的中间件不是某个华丽提示词,而是一份短小、严格、能被审计的视觉载荷。它把“表格里有什么”和“图片应该表达什么”分开,让任何人都能在生图前指出口径问题,也能在生图后判断画面是否忠实。
当流程需要扩展到多语言、多客户或多版本时,这个载荷还能限制漂移:不同语言只重写标题、标签和说明,不重新解释数字;不同客户只替换数据源,不改变校验规则。这样生成图才像一条可运营的生产线,而不是每次重新猜测的创作实验。
常见问题
GPT Image 2 能直接上传 CSV 吗?
不能作为 Image API 生成的直接输入。CSV 应先被解析或人工检查,再把结论、数字和视觉目标写成提示词或视觉简报。
GPT Image 2 能直接上传 Excel 工作簿吗?
不要把 .xlsx 当作图像模型的原生输入。人工路线可用 ChatGPT 数据分析检查工作簿;生产路线应由代码解析,再把压缩后的视觉载荷传给生图步骤。
ChatGPT 能读表格再帮我做图吗?
在支持文件分析的 ChatGPT 环境里,人工上传表格并生成摘要、图表或视觉简报是可行路线。它是产品工作流,不等同于把工作簿直接发送到 Image API。
Responses API 能把文件和生图放进同一流程吗?
可以把文件上下文、工具调用和图像生成放进同一应用流程,但仍要分清楚:文件由周边流程理解,最后生图步骤需要提示词、图像输入或图像可执行说明。
Files API 上传 CSV 后,GPT Image 2 就能读取吗?
不能自动读取。Files API 是存储文件给支持的目的使用,CSV 文件 ID 不会自动变成 Image API 的图片参考或生成输入。
图表截图比原始表格更好吗?
当可见图表已经包含正确数据,只需要视觉改造时,截图更适合。需要隐藏行、计算公式、筛选逻辑或精确汇总时,原始数据应先被解析成载荷。
大表格应该怎么处理?
不要把整张表塞给生图步骤。先过滤、聚合、选择结论,再构造短视觉载荷。敏感或大型文件应在自己的系统里完成解析、脱敏和日志记录。
GPT Image 2 能输出 PPTX、PDF 或 XLSX 吗?
GPT Image 2 输出图像数据。需要办公文件时,先生成图片资产,再用文档、幻灯片或表格工具组装和导出。
file_id 在生图里应该怎么用?
只在图像路线支持的文件类型和参数位置使用。图片文件 ID 可以作为图片参考;表格文件 ID 应留在文件分析、检索或预处理流程里。