DeepSeek V4 vs Claude 4.5 vs GPT-5.2: Complete AI Model Comparison [2026]
Comprehensive comparison of DeepSeek V4, Claude Opus 4.5, and GPT-5.2. Covers benchmarks (SWE-bench, AIME, GPQA), API pricing, coding capabilities, and use case recommendations for January 2026.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

The AI model landscape in January 2026 has fundamentally changed. For the first time since ChatGPT's launch, there is no single "best" AI model—each platform now dominates different use cases. Claude Opus 4.5 leads in coding with an unprecedented 80.9% on SWE-bench. GPT-5.2 achieves perfect scores on mathematical reasoning. And DeepSeek V4, expected in February 2026, promises to challenge both with its revolutionary Engram memory architecture.
This comprehensive comparison examines all three models across benchmarks, pricing, coding capabilities, reasoning performance, and practical API integration. Whether you're a developer choosing your primary coding assistant, an enterprise evaluating AI investments, or simply curious about the state of AI in 2026, this guide provides the data-driven insights you need to make an informed decision.
By the end of this article, you'll understand exactly which model excels in each scenario and how to access all three through unified API endpoints.

Performance Overview: Key Differences at a Glance
Claude Opus 4.5 dominates software engineering tasks, GPT-5.2 leads mathematical reasoning, and DeepSeek V4 aims to revolutionize coding with its upcoming release. Each model has carved out distinct territory in the AI landscape.
Here's what defines each model in January 2026:
Claude Opus 4.5 became the first AI model to exceed 80% on SWE-bench Verified, the industry's most rigorous real-world coding benchmark. It resolves actual GitHub issues with 80.9% accuracy, demonstrating exceptional understanding of complex codebases. Anthropic's focus on "extended thinking" allows Claude to reason through multi-step problems with remarkable consistency.
GPT-5.2 represents OpenAI's most capable release, achieving a perfect 100% on AIME 2025 (American Invitational Mathematics Examination) and 93.2% on GPQA Diamond—a PhD-level science benchmark. The model comes in three tiers: Instant for everyday tasks, Thinking for complex reasoning, and Pro for maximum accuracy. GPT-5.2 was the first model to surpass 90% on ARC-AGI-1.
DeepSeek V4 hasn't been released yet, with an expected launch around mid-February 2026. Based on leaked information and DeepSeek's published research on the Engram memory system, V4 promises context windows exceeding 1 million tokens and superior performance on long-form code generation. If it follows DeepSeek's tradition, it will be released as an open-weight model.
| Model | Status | Key Strength | Top Benchmark |
|---|---|---|---|
| Claude Opus 4.5 | Available | Coding | SWE-bench 80.9% |
| GPT-5.2 | Available | Reasoning | AIME 100% |
| DeepSeek V4 | Feb 2026 | Long-context | Expected 1M+ tokens |
Benchmark Comparison: Coding, Math, and Reasoning
Independent benchmarks tell the clearest story of model capabilities. As of January 2026, no single model dominates all categories—choosing the right model requires understanding where each excels.
SWE-bench Verified measures a model's ability to resolve real GitHub issues. Claude Opus 4.5 leads with 80.9%, followed by GPT-5.2 at approximately 75%. DeepSeek V3.2 scores around 65%, but V4 is expected to significantly improve on this. According to Anthropic's announcement, Opus 4.5 is the first model to exceed 80% on this benchmark.
AIME 2025 (American Invitational Mathematics Examination) tests complex mathematical reasoning. GPT-5.2 achieves a perfect 100% score, demonstrating flawless mathematical problem-solving. Claude Opus 4.5 scores around 80%, while DeepSeek V3.2 reaches approximately 85%.
GPQA Diamond presents PhD-level science questions in biology, chemistry, and physics. GPT-5.2 Pro leads with 93.2%, followed by GPT-5.2 Thinking at 92.4%. Claude Opus 4.5 achieves approximately 82%.
ARC-AGI-2 measures genuine problem-solving ability on novel challenges. Claude Opus 4.5 scores 37.6% versus Claude Sonnet 4.5's 13.6%—a significant gap indicating Opus's superior reasoning depth. GPT-5.2 was the first model above 90% on ARC-AGI-1.
| Benchmark | Claude Opus 4.5 | GPT-5.2 | DeepSeek V3.2 | Winner |
|---|---|---|---|---|
| SWE-bench | 80.9% | ~75% | ~65% | Claude |
| AIME 2025 | ~80% | 100% | ~85% | GPT-5.2 |
| GPQA Diamond | ~82% | 93.2% | ~75% | GPT-5.2 |
| ARC-AGI-1 | 37.6% | 90%+ | ~70% | GPT-5.2 |
| WebDev Arena | 92% | 88% | ~85% | Claude |
The data reveals a clear pattern: Claude excels at software engineering, GPT-5.2 dominates academic reasoning, and DeepSeek offers competitive performance at lower cost.
Coding Showdown: Which Model Writes Better Code?
For developers, coding performance often determines model choice. Claude Opus 4.5 has established itself as the leading coding model in 2026, but GPT-5.2 Codex and the upcoming DeepSeek V4 present strong alternatives.
Claude Opus 4.5 ranks first on LMArena's WebDev leaderboard with 92% accuracy, ahead of GPT-5.1's 88%. What sets Claude apart is its efficiency: it matches Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens at medium effort. At highest effort, Opus exceeds Sonnet by 4.3 percentage points while using 48% fewer tokens. This token efficiency translates directly to cost savings for high-volume coding tasks.
The model excels particularly at understanding complex codebases. It can trace dependencies across multiple files, suggest refactoring that maintains consistency, and resolve bugs by understanding the broader context of how different components interact.
GPT-5.2 Codex is OpenAI's specialized coding variant, described as "the most advanced agentic coding model yet for complex, real-world software engineering." While it scores slightly lower than Claude on SWE-bench, GPT-5.2 Codex has notably stronger cybersecurity capabilities than any previous OpenAI model. For security-focused development, this makes it a compelling choice.
DeepSeek V4 is expected to target coding dominance specifically. Internal benchmarks reportedly show V4 outperforming both Claude and GPT series in long-context code generation—the ability to understand and modify code across entire repositories rather than single files. DeepSeek's Engram memory system separates static pattern retrieval from dynamic reasoning, potentially enabling more efficient multi-file operations.
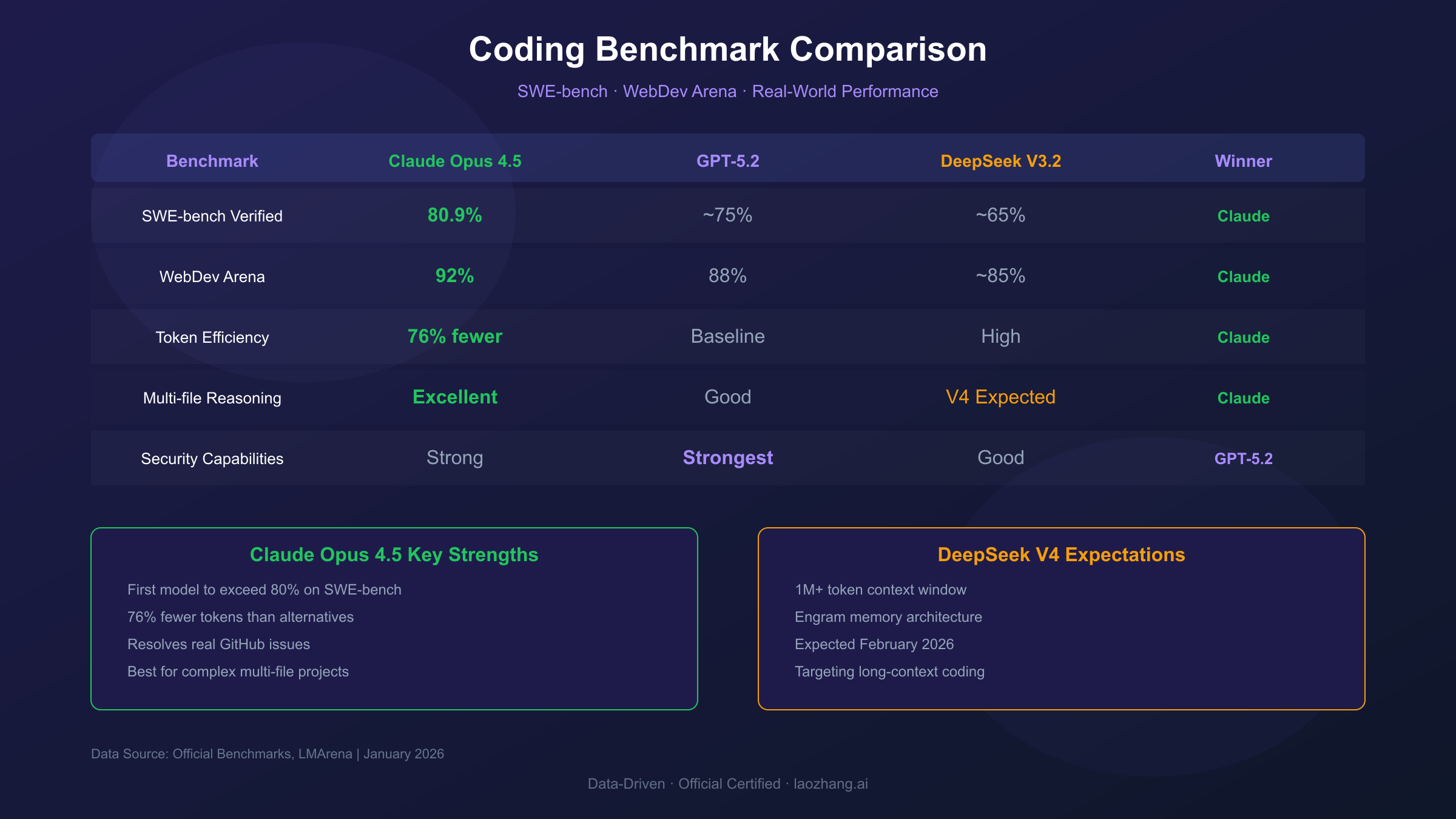
For most coding tasks today, Claude Opus 4.5 is the clear recommendation. However, if DeepSeek V4 delivers on its promises, the landscape may shift significantly after February 2026.
Reasoning and Math: GPT-5.2's Dominance Explained
Mathematical reasoning represents GPT-5.2's strongest capability. OpenAI's latest model achieves benchmarks that seemed impossible just a year ago.
The perfect 100% score on AIME 2025 deserves particular attention. AIME problems require creative mathematical thinking, not just formula application. A model that solves every problem demonstrates genuine mathematical reasoning ability, not pattern matching from training data.
On GPQA Diamond—a benchmark designed to be "Google-proof" where even experts struggle—GPT-5.2 Pro achieves 93.2%. This benchmark includes graduate-level questions in physics, chemistry, and biology that cannot be answered by simple retrieval. The model must genuinely understand and reason through complex scientific concepts.
GPT-5.2's reasoning advantage stems from its architecture. The model supports a reasoning_effort parameter with settings including a max-power "xhigh" option. According to OpenAI's documentation, GPT-5.2 Thinking is designed for "deep work" and takes time to reason through complex problems rather than generating immediate responses.
The three-tier system—Instant, Thinking, and Pro—allows users to trade cost for capability:
- GPT-5.2 Instant: Optimized for speed, suitable for everyday queries
- GPT-5.2 Thinking: Deeper reasoning chains for complex problems
- GPT-5.2 Pro: Maximum accuracy, lowest error rate
For research, scientific analysis, or any task requiring rigorous logical reasoning, GPT-5.2 is currently unmatched. Claude and DeepSeek may eventually close this gap, but as of January 2026, GPT-5.2 sets the standard.
Pricing Breakdown: API Costs and Value Analysis
Understanding pricing is essential for budgeting AI integration projects. The three models span a wide range of costs, with DeepSeek offering the most aggressive pricing.
Claude Opus 4.5 costs $5 per million input tokens and $25 per million output tokens. This represents a 66% price drop compared to Opus 4.1, making advanced AI more accessible. Batch API usage provides an additional 50% discount for non-urgent tasks. Cache read tokens are charged at 0.1× the base input price.
GPT-5.2 pricing varies by tier:
- GPT-5.2 Thinking: $1.75/1M input, $14/1M output
- GPT-5.2 Pro: $21/1M input, $168/1M output
- Cached inputs receive a 90% discount
DeepSeek V3.2 offers the lowest prices in the market:
- Cache hit: $0.028/1M tokens
- Cache miss: $0.28/1M input, $0.42/1M output
- Up to 95% cheaper than GPT-5 and significantly less than Claude
| Model | Input (per 1M) | Output (per 1M) | Notes |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | 50% batch discount |
| GPT-5.2 Thinking | $1.75 | $14.00 | 90% cache discount |
| GPT-5.2 Pro | $21.00 | $168.00 | Highest accuracy |
| DeepSeek V3.2 | $0.28 | $0.42 | Best value |
For developers needing access to multiple models, aggregation platforms can simplify the process by providing unified API endpoints. This eliminates managing separate API keys for each provider and simplifies billing across different models.
API Integration: Code Examples for All Three Models
All three models support OpenAI-compatible API formats, making integration straightforward. Here are practical examples for each.
Claude Opus 4.5 via Official API
hljs pythonfrom anthropic import Anthropic
client = Anthropic(api_key="your-api-key")
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[
{"role": "user", "content": "Explain quantum computing in simple terms."}
]
)
print(response.content[0].text)
GPT-5.2 via OpenAI API
hljs pythonfrom openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-5.2", # or "gpt-5.2-pro" for highest accuracy
messages=[
{"role": "user", "content": "Solve this integral: ∫x²e^x dx"}
],
reasoning_effort="high" # Enable extended reasoning
)
print(response.choices[0].message.content)
DeepSeek V3.2 via DeepSeek API
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="your-deepseek-key",
base_url="https://api.deepseek.com/v1"
)
response = client.chat.completions.create(
model="deepseek-chat", # V3.2 powers this endpoint
messages=[
{"role": "user", "content": "Refactor this code for better performance..."}
]
)
print(response.choices[0].message.content)
Unified Access via Aggregation Platform
For projects requiring access to all three models, using a unified endpoint eliminates the complexity of managing multiple API integrations:
hljs pythonfrom openai import OpenAI
# Example: Single endpoint for multiple models
client = OpenAI(
api_key="your-aggregator-key",
base_url="https://your-aggregator-endpoint/v1"
)
# Switch models by changing the model parameter
models = ["claude-opus-4-5", "gpt-5.2", "deepseek-chat"]
for model in models:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Explain recursion."}]
)
print(f"{model}: {response.choices[0].message.content[:100]}...")
This approach is particularly useful for A/B testing different models or implementing fallback logic when one provider experiences downtime.
DeepSeek V4 Preview: What to Expect in February 2026
DeepSeek V4 is expected to launch around mid-February 2026, coinciding with the Lunar New Year on February 17. While the official release date hasn't been confirmed, The Information reported that people with direct knowledge of the project expect this timeline.
Engram Memory Architecture: DeepSeek published research on January 13, 2026 introducing Engram, a conditional memory system that separates static pattern retrieval from dynamic reasoning. This architecture essentially creates a more efficient filing system—the AI stores basic facts separately from complex calculations, freeing computational resources for harder thinking tasks.
1M+ Token Context Window: DeepSeek's Sparse Attention mechanism enables context windows exceeding 1 million tokens while reducing computational costs by approximately 50% compared to standard attention. This allows V4 to process entire codebases in a single pass, enabling true multi-file reasoning.
Open-Weight Release Expected: Continuing DeepSeek's tradition, V4 is expected to be available as an open-weight model. This means organizations can run V4 entirely within their own infrastructure—critical for industries like finance, healthcare, and defense with strict data governance requirements.
Hardware Requirements: If V4 follows the V3 architecture (671B total parameters, ~37B active per token), the full model will require approximately 350-400GB VRAM. However, distilled versions like "DeepSeek-V4-Lite" are expected shortly after launch, potentially fitting on a single consumer GPU with 24GB VRAM.
Should You Wait? If you're making a major infrastructure decision, waiting until February to evaluate V4 makes sense. However, Claude Opus 4.5 and GPT-5.2 are available now and deliver excellent performance. For immediate needs, there's no reason to delay—you can always adopt V4 after release.
Feature Comparison Table: All Models Side by Side
This comprehensive comparison covers the key technical specifications and capabilities across all three models.
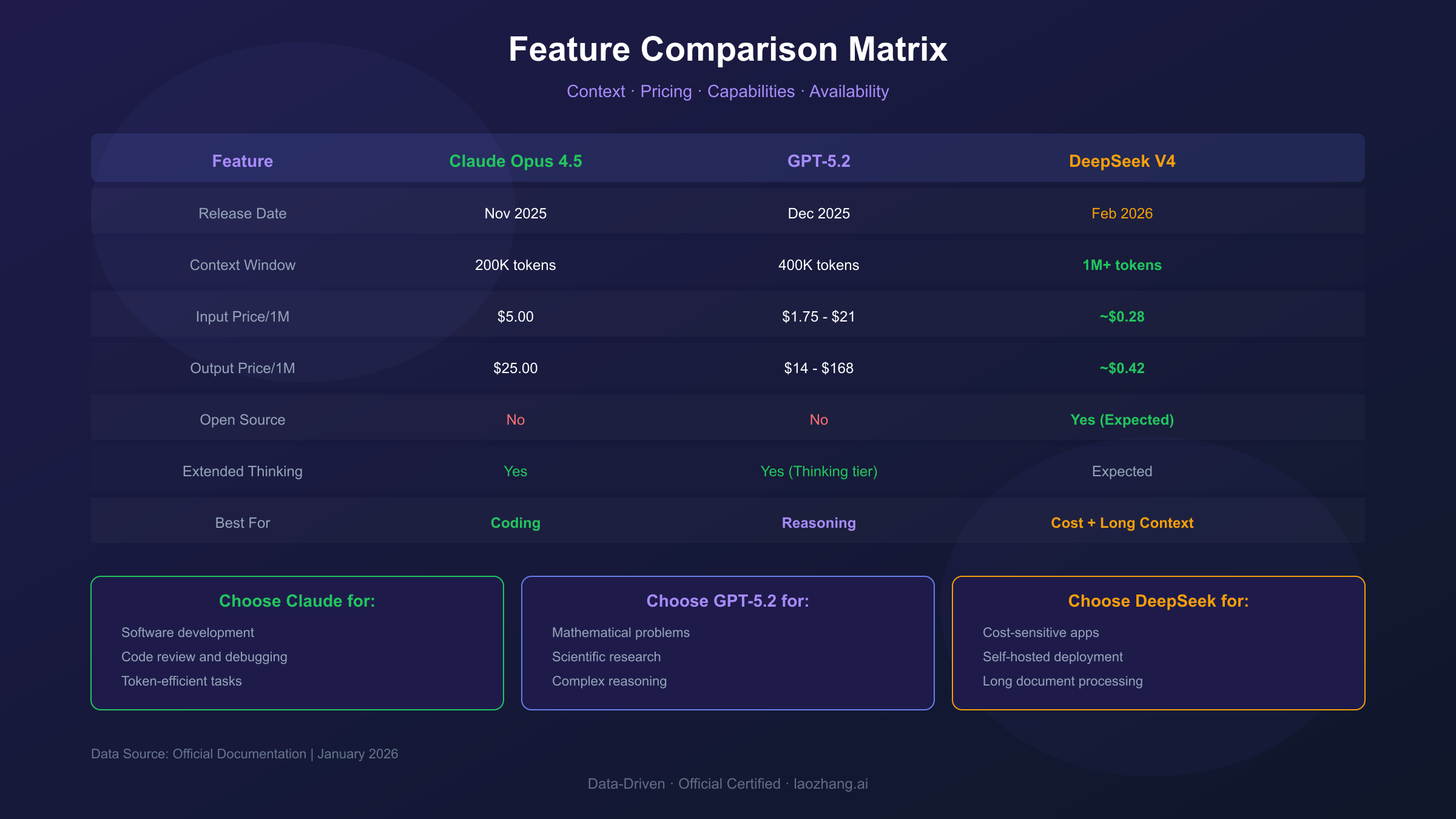
| Feature | Claude Opus 4.5 | GPT-5.2 | DeepSeek V4 (Expected) |
|---|---|---|---|
| Release Date | Nov 2025 | Dec 2025 | Feb 2026 |
| Context Window | 200K tokens | 400K tokens | 1M+ tokens |
| Max Output | 32K tokens | 128K tokens | TBD |
| Pricing (Input) | $5/1M | $1.75-21/1M | TBD |
| Pricing (Output) | $25/1M | $14-168/1M | TBD |
| Open Source | No | No | Expected Yes |
| Knowledge Cutoff | Early 2025 | Aug 2025 | TBD |
| Extended Thinking | Yes | Yes (Thinking tier) | Expected |
| Batch Discount | 50% | Via rate limits | TBD |
Unique Capabilities:
- Claude Opus 4.5: Junie agentic coding integration, 76% token efficiency vs Sonnet
- GPT-5.2: Three-tier system (Instant/Thinking/Pro),
reasoning_effortparameter - DeepSeek V4: Engram memory, Manifold-Constrained Hyper-Connections, local deployment
Which Model Should You Choose? Use Case Recommendations
The "best" model depends entirely on your specific use case. Here are concrete recommendations based on current performance data.
Choose Claude Opus 4.5 for:
- Software development and debugging (SWE-bench leader)
- Code review and refactoring
- Complex multi-file programming projects
- Tasks where token efficiency matters (76% fewer tokens than alternatives)
- Agentic coding workflows
Choose GPT-5.2 for:
- Mathematical problem-solving (100% AIME)
- Scientific research and analysis (93.2% GPQA)
- Complex reasoning tasks requiring deep thinking
- Professional knowledge work across 44 occupations
- When you need the absolute lowest error rate (Pro tier)
Choose DeepSeek V3.2 for (V4 after release):
- Cost-sensitive applications (up to 95% cheaper)
- High-volume inference workloads
- Projects requiring on-premise deployment
- Long-context document processing
- When open-weight models are required
For maximum flexibility, consider using a unified API platform that supports all three models. This allows you to:
- Route different tasks to the most suitable model
- Implement fallback logic for reliability
- Simplify billing and API key management
- A/B test models without code changes
| Use Case | Recommended Model | Reason |
|---|---|---|
| Web development | Claude Opus 4.5 | 92% WebDev accuracy |
| Math tutoring | GPT-5.2 | 100% AIME score |
| Cost-optimized chat | DeepSeek V3.2 | $0.28/1M input |
| Security auditing | GPT-5.2 Codex | Strongest cybersecurity |
| Self-hosted AI | DeepSeek V4 | Open-weight expected |
FAQ: Common Questions About These AI Models
Is DeepSeek V4 better than GPT-5.2?
DeepSeek V4 hasn't been released yet, so direct comparisons aren't possible. Based on leaked benchmarks and DeepSeek's published research, V4 may outperform GPT-5.2 in long-context coding tasks. However, GPT-5.2's mathematical reasoning (100% AIME) and general reasoning capabilities set a very high bar. Wait for independent benchmarks after V4's February 2026 release before making conclusions.
Which model is cheapest for high-volume use?
DeepSeek V3.2 offers by far the lowest pricing at $0.28 per million input tokens—up to 95% cheaper than GPT-5 and significantly less than Claude. For high-volume applications where cost is the primary concern, DeepSeek is the clear winner. However, consider whether the performance difference justifies the cost savings for your specific use case.
Can I run these models locally?
Currently, only DeepSeek models support local deployment. DeepSeek V4 is expected to follow this tradition as an open-weight model. The full model will require substantial hardware (350-400GB VRAM), but distilled versions should run on consumer GPUs with 24GB VRAM. Neither Claude nor GPT models are available for local deployment.
Which has the longest context window?
DeepSeek V4 is expected to exceed 1 million tokens, far surpassing GPT-5.2's 400K and Claude Opus 4.5's 200K (though Claude Sonnet 4.5 supports 1M tokens). For processing extremely large documents or entire codebases in a single context, DeepSeek will likely be the best choice once V4 releases.
How do I switch between models easily?
Use a unified API platform that supports all three models through an OpenAI-compatible endpoint. This allows you to switch models by simply changing the model parameter, with no code changes required. This simplifies testing, fallback logic, and billing management.
Conclusion
The AI model landscape in 2026 rewards specialization over loyalty. Claude Opus 4.5 leads software engineering with its industry-first 80.9% SWE-bench score. GPT-5.2 dominates mathematical reasoning with perfect AIME scores. DeepSeek V4, arriving in February 2026, promises to revolutionize long-context coding with its Engram memory architecture.
For most developers, the practical approach is multi-model access. Different tasks benefit from different models—use Claude for coding, GPT-5.2 for reasoning, and DeepSeek for cost-sensitive applications. Unified API platforms eliminate the complexity of managing separate integrations.
If you need stable API access to all these models, consider exploring laozhang.ai. The platform aggregates multiple model providers with OpenAI-compatible endpoints, transparent pricing, and reliable uptime—suitable for both individual developers and teams.
For deeper technical details, check out our Claude API error troubleshooting guide or our analysis of Gemini API pricing and limits. For information on accessing AI APIs with reliability guarantees, see our stable Claude Code API guide.